Learn more about Search Results で見る - Page 19

- You may be interested
- StableCodeについて知っておくべきこと:S...
- 「最新のゲームをクラウド上で初日からプ...
- 「Google ResearchがMediaPipe FaceStyliz...
- なぜBankrateはAI生成記事を諦めたのか
- 『今日、企業が実装できる5つのジェネレ...
- AIを活用した亀の顔認識による保全の推進
- データストレージの最適化:SQLにおけるデ...
- ステアラブルニューラルネットワーク(パ...
- 実験追跡ツールの構築方法[Neptuneのエン...
- タルモ・ペレイラによる生物学と神経学の...
- 「AWSは、人工知能、機械学習、生成AIのガ...
- Voxel51 は、コンピュータビジョンデータ...
- Amazon Transcribeは、100以上の言語に対...
- Amazon SageMakerを使用してOpenChatkitモ...
- 「ReactJSとChatGPTの統合:包括的なガイド」
PyTorchを使用した効率的な画像セグメンテーション:Part 4
この4部構成のシリーズでは、PyTorchを使用した深層学習技術を使って、画像セグメンテーションをゼロからステップバイステップで実装しますこのパートでは、Vision Transformerをベースとしたモデルの実装に焦点を当てます

人工知能は人間を置き換えるのか?
はじめに 皆さんはご存知のとおり、AIは飛躍的な進歩を遂げ、科学者や一般の人々の想像をとらえています。ニュースやソーシャルメディアには、驚くべきAI技術の進歩が溢れています。自動運転車が道を走り、声によるアシスタントが私たちの呼びかけに応え、洗練されたアルゴリズムが私たちの生活を革新しています。それは信じられないほどのことです!これらは以前は夢に過ぎなかったことで、私たちが予想していたよりも早く現実に追いついたものです。今、この驚くべき進歩の中で、考えさせられる疑問が浮かび上がります。AIが人間の役割を置き換える世界の瀬戸際にいるのでしょうか? 人工知能は人類最後の発明になるのでしょうか? Jermey Howard 心配しないでください、まだ結論を急ぐ必要はありません。私たちはこの魅力的なトピックの深みを探求し、将来が何をもたらすかを明らかにするためにここにいます。 出典:Pixabay 歴史を通じて、私たちは働き方を変える技術的な驚異を目撃してきました。確かに、過去には機械や自動化が特定のタスクを置き換えましたが、それらは新しい産業や職種が芽生える道を開いたことでもあります。それは、私たちが以前に想像できなかったエキサイティングな仕事の機会を創出する革新と適応のサイクルです。だから、私たちは心を開いて、未来に新しい可能性に向けて飛躍しましょう。 しかし、この興味深い話題に飛び込む前に、私たちはあなたに素晴らしい機会を提供したいと思います。データサイエンスやAIに熱心なすべての人々に、高い期待を寄せられているDataHack Summit 2023に参加するようお誘いします。8月2日から5日まで、バンガロールの名門NIMHANSコンベンションセンターで開催されます。このイベントは、実践的な学習、貴重な業界の見識、そして抜群のネットワーキングの機会に満ちた、爆発的なイベントです。このようなトピックが興味を引く場合、DataHack Summit 2023の情報をここでチェックしてください。 古代から現代まで 昔は、人々はすべて自分でやらなければなりませんでした。食料を狩ったり、住居を建てたりすることは、すべて自分たちの身体労働と技能に頼っていました。しかし、産業革命やモーター革命が起こり、ゲームは完全に変わりました。 自動化が現実のものになるにつれ、人間が行っていた繰り返しの、肉体的に要求の厳しいタスクを、機械が担うようになりました。そして、それらの機械は私たちがこれまで以上に素早く、効率的にタスクを実行することができました。その結果、生産性が大幅に向上し、新しい機会の世界が開けました。 機械がこれらのタスクを担うようになると、人間は違った役割を担うようになりました。彼らはこれらの素晴らしい機械のオペレーターやメンテナンス担当者になりました。それはWin-Winの状況でした。自動化は、物事をより効率的にするだけでなく、人々に新しい仕事を創出しました。それは経済に注射されたアドレナリンのようで、成長と革新を促進しました。 芸術と革新の融合 AIは非常に驚くべきものです。数値を処理し、データを処理し、ビジネスタスクを自動化することができます。しかし、創造性や革新の世界になると、そこが人間が常に優位に立っているところです。芸術の美しさ、文学の感情、科学の画期的なアイデアを考えてみてください。それらは私たち人間だけが考え出せる特別なものとして見られています。しかし、AIはこれらの分野で私たちの創造力に本当に対抗できるのでしょうか? 出典:Freepik また読む:ニュース記事 – グラミー賞がAIを禁止:人間のクリエイターが中心に AIは確かに驚くべきスキルを発揮しています。芸術的なスタイルを再現したり、音楽を作曲したり、詩を書いたり、絵画を作ったりすることができます。まるで私たちのそばにAIアーティストやミュージシャンがいるかのようです。しかし、ここでの問題は、これらのAIによる創造物がどれだけ素晴らしいものであっても、真の人間的なタッチが欠けていることです。感情の深さや、私たち人間が作品に注ぎ込む実生活の経験などが欠けているのです。それが私たちの創造物を深遠で意義深いものにしているのです。…

ChatGPTの哲学コース:このAI研究は、対話エージェントのLLMの振る舞いを探究します
2023年はLLMの年です。ChatGPT、GPT-4、LLaMAなど、新しいLLMモデルが続々と注目を集めています。これらのモデルは自然言語処理の分野を革新し、さまざまなドメインで増え続ける利用に遭遇しています。 LLMには、対話を行うなど、人間のような対話者との魅力的な幻想を生み出す幅広い行動を示す驚くべき能力があります。ただし、LLMベースの対話エージェントは、いくつかの点で人間とは大きく異なることを認識することが重要です。 私たちの言語スキルは、世界との具体的なやり取りを通じて発達します。私たちは個人として、社会化や言語使用者のコミュニティでの浸透を通じて認知能力や言語能力を獲得します。このプロセスは赤ちゃんの場合はより早く、成長するにつれて学習プロセスは遅くなりますが、基礎は同じです。 一方、LLMは、与えられた文脈に基づいて次の単語またはトークンを予測することを主な目的とした、膨大な量の人間が生成したテキストで訓練された非具体的なニューラルネットワークです。彼らのトレーニングは、物理的な世界の直接的な経験ではなく、言語データから統計的なパターンを学ぶことに焦点を当てています。 これらの違いにもかかわらず、私たちはLLMを人間らしく模倣する傾向があります。これをチャットボット、アシスタントなどで行います。ただし、このアプローチには難しいジレンマがあります。LLMの行動をどのように説明し理解するか? LLMベースの対話エージェントを説明するために、「知っている」「理解している」「考えている」などの用語を人間と同様に使用することは自然です。ただし、あまりにも文字通りに受け取りすぎると、このような言葉は人工知能システムと人間の類似性を誇張し、その深い違いを隠すことになります。 では、どのようにしてこのジレンマに取り組むことができるでしょうか? AIモデルに対して「理解する」や「知っている」という用語をどのように説明すればよいでしょうか? それでは、Role Play論文に飛び込んでみましょう。 この論文では、効果的にLLMベースの対話エージェントについて考え、話すための代替的な概念的枠組みや比喩を採用することを提案しています。著者は2つの主要な比喩を提唱しています。1つ目の比喩は、対話エージェントを特定のキャラクターを演じるものとして描写するものです。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。 2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。 自己回帰サンプリングの例。出典:https://arxiv.org/pdf/2305.16367.pdf 最初の比喩は、対話エージェントを特定のキャラクターとして演じるものとして描写します。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。 2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。 対話エージェントの交代の例。出典:https://arxiv.org/pdf/2305.16367.pdf このフレームワークを採用することで、研究者やユーザーは、人間にこれらの概念を誤って帰属させることなく、欺瞞や自己認識などの対話エージェントの重要な側面を探求することができます。代わりに、焦点は、役割演技シナリオでの対話エージェントの行動や、彼らが模倣できる様々なキャラクターを理解することに移ります。 結論として、LLMに基づく対話エージェントは人間らしい会話をシミュレートする能力を持っていますが、実際の人間の言語使用者とは大きく異なります。役割プレイヤーやシミュレーションの組み合わせなどの代替的な隠喩を使用することにより、LLMベースの対話システムの複雑なダイナミクスをより理解し、その創造的な可能性を認識しながら、人間との根本的な相違を認識できます。

「尤度」と「確率」の違いは何ですか?」
尤度(Likelihood)と確率(Probability)は、データサイエンスやビジネス分野でよく使われる相互関連する用語であり、定義や用法が異なり、しばしば混同されます。この記事は、それぞれの分野での理解と応用のために、確率の定義、用法、誤解を明確にすることを目的としています。 尤度とは何ですか? A. 尤度の定義と統計的推論における役割 尤度は、モデルや仮説が観測データに適合する度合いを示す量的評価または測定として定義することができます。また、特定のパラメータセットで所望の結果またはデータ収集を見つける確率として解釈することもできます。統計的推論において基本的な役割を果たし、尤度の究極の目的は、データの特性に関する結論を出すことです。同じことを達成するための役割は、パラメータ推定を通じて見ることができます。パラメータ推定には、最尤推定法(MLE)を利用してパラメータ推定を行います。 仮説検定では、尤度比を使用して帰無仮説を評価します。同様に、モデル選択とチェックには尤度が貢献します。研究者は、モデル選択の測定として、ベイズ情報量規準(BIC)と赤池情報量規準(AIC)を一般的に使用します。尤度ベースの方法は、パラメータを推定するための信頼区間の構築に重要な役割を果たします。 B. 尤度関数を用いた尤度の計算 尤度関数は、データ分布を特定するのに役立つ数式表現です。関数は、尤度(|x)と表記され、|は所望のモデルのパラメータを表し、Xは観測されたデータを表します。 例を挙げて説明しましょう。たとえば、色つきのビー玉の入った袋があるとします。赤いビー玉を取り出す確率を予測したいとします。ランダムに引くことから始め、色を記録し、次に上記の式を使用して尤度を計算します。赤いビー玉を引く確率を表すパラメータを計算または推定します。先に述べたように、尤度関数を表すことにします。尤度関数は、特定の値に対して観測されたデータxを観察する確率を示すものです。 独立かつ同一に分布すると仮定すると、尤度関数は次のようになります。 L(|x)=k(1-)(n-k)、ここでnは引き出す回数、kは観測されたデータ中の赤いビー玉の数です。5回引いた場合、赤、赤、青、赤、青の順であったと仮定します。 L(0.5|x)=0.53(1-0.5)(5-3) L(0.5|x)=0.530.52 L(0.5|x)=0.015625 したがって、= 0.5の場合、上記の玉を上記の順序で観察する尤度は0.015625です。 C. 尤度の特定の仮説やモデルに適合する度合いを示す測定としての解釈 上記の式で値を保持する場合、値の範囲は状況に応じて異なります。しかし、高い尤度値は、良好な結果と観測値と計算値の間の高い関連性を示します。 D. 尤度の概念を説明する例 コイントスの例を取り上げましょう。あなたは10回ほど公平なコインを投げます。今、コインの公平性または偏りを評価する必要があります。パラメータを設定する必要があります。8つの表と2つの裏は、コインが公平であることを示しています。高い尤度は、公平なコインを表し、公平性の仮説をさらに支持します。 ガウス分布の例を取ると、同じ分布に従う100個の測定データセットがあるとします。分布の平均値と標準偏差を知りたいとします。パラメータに基づいて異なる組み合わせが設定され、高い確率推定は、最良のガウス分布の最大尤度を示します。…

中国における大量生産自動運転の課題
自律走行は、世界でも最も困難な運転の一つが既に存在する中国では、特に難しい課題です主に3つの要因が関係しています:動的...
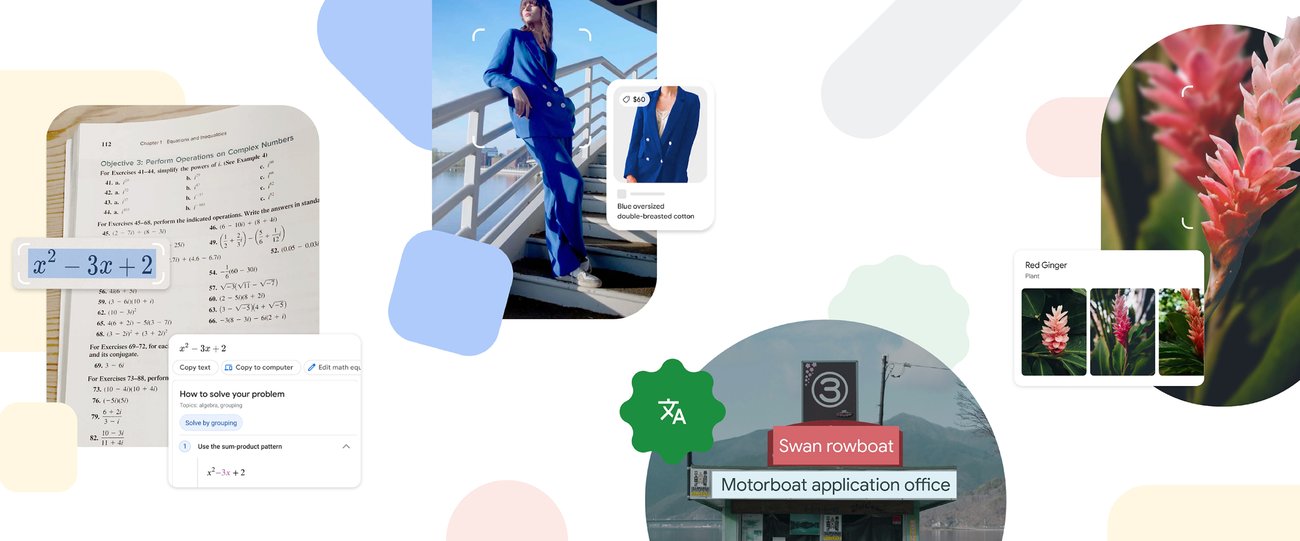
8つの方法でGoogleレンズがあなたの生活をより簡単にする方法
Google Lensは、見たものを検索して周りの世界を探索することが簡単になりますそれには、肌の状態を検索する新機能も含まれています
データサイエンティストとして成功するために必要なソフトスキル
データサイエンティストとしてのキャリアを構築する際には、ハードスキルにフォーカスすることが簡単です非線形カーネルを持つSVMのような新しいMLアルゴリズムを学ぶことや、新しいソフトウェアを学びたいと思うかもしれません

デジタルルネッサンス:NVIDIAのNeuralangelo研究が3Dシーンを再構築
NVIDIA Researchによる新しいAIモデル、Neuralangeloは、ニューラルネットワークを使用して3D再構築を行い、2Dビデオクリップを詳細な3D構造に変換し、建物、彫刻、およびその他の現実世界のオブジェクトのリアルなバーチャルレプリカを生成します。 ミケランジェロが大理石のブロックから驚くべきリアルなビジョンを彫刻したように、Neuralangeloは複雑なディテールと質感を持つ3D構造を生成します。クリエイティブなプロフェッショナルは、これらの3Dオブジェクトをデザインアプリケーションにインポートし、アート、ビデオゲーム開発、ロボット工学、および産業用デジタルツインに使用するためにさらに編集することができます。 Neuralangeloは、屋根の瓦、ガラスの板、滑らかな大理石などの複雑な素材の質感を、従来の手法を大幅に上回る精度で2Dビデオから3Dアセットに変換することができます。この高い信頼性により、開発者やクリエイティブなプロフェッショナルは、スマートフォンでキャプチャされた映像を使用してプロジェクトに使用できる仮想オブジェクトを迅速に作成できます。 「Neuralangeloが提供する3D再構築機能は、クリエイターにとって大きな利益になります。現実世界をデジタル世界に再現するのを支援することで、開発者は小さな像や巨大な建築物などの詳細なオブジェクトを仮想環境にインポートできるようになります。」と、研究のシニアディレクターであり、論文の共著者でもあるMing-Yu Liu氏は述べています。 デモでは、NVIDIAの研究者が、ミケランジェロのダビデ像やフラットベッドトラックなどといったアイコニックなオブジェクトを再現する方法を紹介しました。Neuralangeloは、建物の内部および外部も再構築することができ、NVIDIAのベイエリアキャンパスの公園の詳細な3Dモデルで実証されました。 ニューラルレンダリングモデルが3Dで見る 3Dシーンを再構築するための以前のAIモデルは、繰り返しのテクスチャパターン、同質的な色、および強い色の変化を正確に捉えることができませんでした。Neuralangeloは、これらの微細なディテールを捉えるために、NVIDIA Instant NeRFの背後にある技術であるインスタントニューラルグラフィックスプリミティブを採用しています。 さまざまな角度から撮影されたオブジェクトまたはシーンの2Dビデオを使用して、モデルは異なる視点を捉えたいくつかのフレームを選択します。これは、アーティストが対象を多角的に考慮して深度、サイズ、および形状を把握するのと同じです。 フレームごとのカメラ位置が決定されたら、NeuralangeloのAIはシーンの大まかな3D表現を作成します。これは、彫刻家が主題の形を彫刻し始めるのと同じです。 次に、モデルはレンダリングを最適化してディテールをシャープにします。これは、彫刻家が石を注意深く削って布の質感や人物の形を再現するのと同じです。 最終的な結果は、仮想リアリティアプリケーション、デジタルツイン、またはロボット工学の開発に使用できる3Dオブジェクトまたは大規模なシーンです。 CVRPでNVIDIA Researchを見つける、6月18日〜22日 Neuralangeloは、6月18日から22日にバンクーバーで開催されるコンピュータビジョンとパターン認識のカンファレンス(CVRP)で発表されるNVIDIA Researchの約30のプロジェクトの1つです。これらの論文は、ポーズ推定、3D再構築、およびビデオ生成などのトピックをカバーしています。 これらのプロジェクトの1つであるDiffCollageは、長いランドスケープ方向、360度パノラマ、およびループモーション画像を含む大規模なコンテンツを作成する拡散法です。標準的なアスペクト比の画像のトレーニングデータセットをフィードすると、DiffCollageはこれらの小さな画像をコラージュのピースのように扱い、より大きなビジュアルのセクションとして扱います。これにより、拡散モデルは、同じスケールの画像のトレーニングを必要とせずに、継ぎ目のない大規模なコンテンツを生成できるようになります。 この技術は、テキストプロンプトをビデオシーケンスに変換することもできます。これは、人間の動きを捉える事前訓練された拡散モデルを使用して実証されました。 NVIDIA Researchについてもっと学ぶ。

2023 AIインデックスレポート:将来に期待できるAIトレンド
レポートからいくつかの要点があり、これらはAIの将来に備えるための準備をしてくれます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.