Learn more about Search Results A - Page 198

- You may be interested
- 「検索強化生成の力:BaseとRAG LLMs with...
- 「機械学習の探求」
- 「Huggingface 🤗を使用したLLMsのためのR...
- 「タイムシリーズの拡張」
- 事前学習された拡散モデルを用いた画像合成
- 「Dockerが「Docker AI」を発表:コンテキ...
- 「人工知能(AI)とWeb3:どのように関連...
- 「推薦システムにおける二つのタワーモデ...
- 「シャッターストックがNVIDIAピカソとと...
- Pythonを使用したビデオ内の深さに配慮し...
- 「エアガーディアンと出会ってください:...
- 「Transformerモデルの実践的な導入 BERT」
- 「’Acoustic Touch’テクノロ...
- GPTと人間の心理学
- X / Twitterでお金を稼ぐ方法

MAmmoTHとは、一般的な数学問題解決に特化したオープンソースの大規模言語モデル(LLM)シリーズです
現代の大規模言語モデル(LLM)は、数学的な推論に大きく依存しており、それがこの研究の主な焦点です。最近の進歩にもかかわらず、クローズドソースのモデル(GPT-4、PaLM-2、Claude 2など)は、GSM8KやMATHなどの人気のある数学的な推論のベンチマークを支配しており、オープンソースのモデル(Llama、Falcon、OPTなど)は遠く及ばない状況があります。 このギャップを埋めるためには、2つの主要なアプローチがあります: GalacticaやMINERVAなどの継続的な事前学習:この方法では、数学に関連するウェブデータの100Bトークン以上を用いてLLMをトレーニングしています。計算コストが高いですが、この方法によりモデルの科学的推論能力が一般的に向上します。 RFT(rejection sampling fine-tuning)やWizardMathなどのデータセットごとに特化したファインチューニング手法:これらの手法は、それぞれのドメイン内では効果的ですが、推論が必要な数学の他の領域には適用できません。 ウォータールー大学、オハイオ州立大学、HKUST、エディンバラ大学、IN.AIの最近の研究は、軽量かつ汎用性のある数学の指導調整技術を採用し、LLMの数学的推論能力を向上させる方法を模索しています(ファインチューニングタスクだけでなく一般的に)。 現在のアプローチは、Chain-of-Thought(CoT)の方法論に大いに依存しており、数学の問題を自然言語のステップで解決する方法を説明しています。しかし、この方法は計算精度や難しい数学的・アルゴリズム的推論手法には対応しきれません。PoTやPALのようなコードベースの手法では、数学問題の解決手順を効率化するためにサードパーティのリソースを使用します。 この方法では、計算量の多いタスク(例:sympyを使用した二次方程式の解法やnumpyを使用した行列の固有値の計算など)を別のPythonインタプリタに委任することが推奨されます。一方、PoTはより抽象的な推論シナリオ(常識的な推論、形式論理、抽象代数など)を扱う際にはいくつかの制限があります、特に事前存在しないAPIの場合には。 CoTとPoTの両方の利点を活かすために、研究チームは数学のための新しいハイブリッドな指導調整データセット「MathInstruct」を提案しています。その主な特徴は次のとおりです: さまざまな数学的領域と複雑度レベルの包括的なカバレッジ ハイブリッドなCoT&PoTの根拠 6つの新たに選択されたデータセットと7つの既存のデータセットがMathInstructの数学的な正当化の基盤を提供しています。モデリングの観点から、研究者たちは入出力形式とデータソースの変動の影響を調べるために、約50のユニークなモデルをトレーニングおよび評価しています。 結果として得られたモデルは数学的な一般化能力において非常に優れています。 研究者たちは、MAmmoTHをGSM8K、MATH、AQuA-RAT、NumGLUEなどの様々なデータセットに対してテストしました。これらのモデルは、オープンソースのLLMの数学的な推論の効率を大幅に向上させ、最新のアプローチよりもOOD(ドメイン外)データセットに対してより一般化された性能を示します。人気のあるコンペティションレベルのMATHデータセットでの7Bモデルの結果は、WizardMath(オープンソースのMATHの最先端技術)よりも3.5倍(35.2%対10.7%)優れており、34BのMAmmoTH-Coder(Code Llamaで調整)の結果はCoTを使用したGPT-4よりも優れています。MAmmoTHとMAmmoTH-Coderの両方のモデルは、以前のオープンソースモデルよりも大幅に精度が向上しています。

『George R.R.マーティン氏と他の作家がOpenAIを訴える』
火曜日、ジョージ・R・R・マーティン、ジョディ・ピコールト、ジョン・グリシャムを含む他の14人の著者が、OpenAIに対して「大規模な盗難行為」と呼ばれるものについての訴訟を提起しました関連報道によると、この訴訟は有害な侵害行為を主張しています数か月前、著者たちはOpenAIに対して要求を出しました...

「Numexprの探索:Pandasの背後にある強力なエンジン」
この記事では、Numpy配列の計算パフォーマンスを向上させるツールであるPythonライブラリNumexprを紹介しますPandasのevalメソッドとqueryメソッドもこのライブラリに基づいています...
「GPU インスタンスに裏打ちされた SageMaker マルチモデルエンドポイントを利用して、数百の NLP モデルをホストします」
「以前、私たちはSageMaker Multi-Model Endpoints(MME)を調査し、複数のモデルを単一のエンドポイントの背後にホストするための費用効果の高いオプションとして検討しましたMME上で小さなモデルをホストすることは可能ですが、...」

「ABBYYインテリジェントオートメーションレポートによると、AIの予算は80%以上増加していることが明らかになりました」
経済状況が企業支出に影響を与える中でも、AIへの投資の急増はゲームチェンジャーとなっていますABBYYの最新のインテリジェントオートメーション報告書によれば、IT幹部の82%がその影響を認めていますこの報告書は、AIの優先事項に与える経済的な影響に焦点を当てており、アメリカ、イギリスなどでITを指導している人々の洞察を集めました
「AI for All 新しい民主化された知能の時代を航海する」
「メガモデル、OpenAI、HuggingFaceなどと共にAI革命を探求しましょう最先端のAIツールがすべての人に利用可能な世界に飛び込んでみましょうこの運動に参加しましょう!」

GoogleのPaLM 2:言語モデルの革命化
イントロダクション 人工知能の急速な進化の中で、テック企業は世界に有意義な貢献をする高効率なAIモデルの開発を競っています。この競争において重要な役割を果たすGoogleは、AIが達成できる可能性の限界を押し広げるために、幅広い研究に積極的に投資しています。彼らの努力の成果は、最新の画期的な言語モデルであるPaLM 2など、革新的な製品の中に明らかに現れています。PaLM 2の進化により、AIとの対話やAIの活用方法が革新される可能性があります。この記事では、GoogleのPaLM 2が何であり、それが未来をどのように形作るかについて詳しく調べていきます。 Bardの理解:Googleの以前の言語モデル PaLM 2について詳しく説明する前に、まずその前身であるBardについて理解しましょう。Google AIが開発したBardは、コードやテキストを含む広範なデータセットで訓練されたチャットボットです。言語翻訳、テキスト生成、コンテンツ作成、情報の質問応答など、多様なスキルを持っています。BardはWebコンテンツの要約に優れ、オープンエンドや複雑な会話中にさらなる探求のためのリンクを提供することさえ可能です。 Bardの影響は特に教育分野で顕著であり、個別の学習、創造的な文章作成、研究、およびカスタマーサービスに役立っています。ただし、Bardには制限があり、不完全または曖昧なクエリに対して不正確またはバイアスのある情報を生成することがあります。これらの制限は、安全性と透明性の向上が必要であることを示しています。 また読む:Chatgpt-4対Google Bard:ヘッド・トゥ・ヘッドの比較 PaLM 2の紹介 Googleは、機械学習とAIの内部研究を基に、次世代の大規模言語モデルであるPaLM 2を発表しました。PaLM 2は、技術的な言語理解、多言語翻訳、自然言語生成の能力が向上した、言語モデル技術の大きな飛躍を表しています。 PaLM 2は5400億のパラメータを持ち、幅広い機能を実現し、より正確で情報豊かな応答を生成することができます。Bardを凌ぐ多様性を持ち、コードの生成、数学の問題の解決、デバッグ、多様なテキストコンテンツの作成などの能力を備えています。また、PaLM 2は20の異なるプログラミング言語でコーディングが可能であり、他のGoogle製品とシームレスに統合することができます。これにより、開発者やユーザーにとって無限の可能性が開けます。 言語理解の向上 PaLM 2の素晴らしい多言語能力は、それを特筆する要素です。PaLM 2は100以上の言語に対応し、グローバルなユーザーにとって貴重なツールとなります。アラビア語、ドイツ語、ヒンディー語、スペイン語、中国語、日本語など、多様な言語で翻訳、質問応答、コード生成、コンテンツ作成などで優れたパフォーマンスを発揮します。その言語の習熟度は、教育から医療、法律、ソフトウェア開発、メディアやエンターテイメントなど、さまざまな分野で有用なリソースとなります。…

「AlphaFold 2の2億モデルによって明らかにされたタンパク質の宇宙を詳細に分析する2つの新論文」
DeepMindのAlphaFold 2と欧州バイオインフォマティクス研究所の共同で、最近2億以上の予測されたタンパク質構造が公開され、タンパク質の新たな時代が幕を開けました

「ヌガットモデルを使用した研究論文の生成AI」
最近の大規模言語モデル(LLM)の進展(例:GPT-4)は、一貫したテキストの生成能力において印象的な成果を示していますしかし、研究論文の解析と理解は依然として…
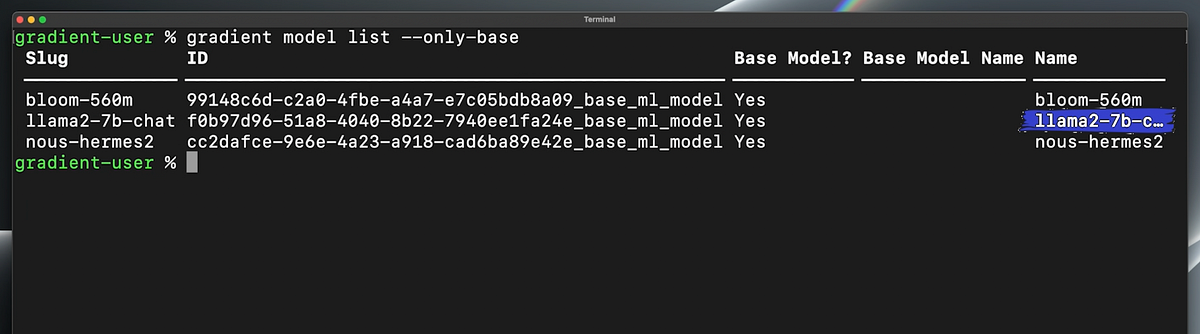
「ファインチューニングでAIのパフォーマンスを向上させる」
私たちは大規模な言語モデルを自分たちの望むように適応させることができますそれはあなたの個人的なアシスタントになり、すべてのメールに返信したり、将来の弁護士になることもできますあなたが望むことを何でもさせることができますしかし、どうやって...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.