Learn more about Search Results Python - Page 195

- You may be interested
- 「AIの誤情報:なぜそれが機能するのか、...
- 将来のアプリケーションを支える大規模言...
- このAI論文は、高度な潜在的一致モデルとL...
- このAIニュースレターは、あなたが必要な...
- 「マシンに思いやりを持たせる:NYU教授が...
- 📱 アップルが不正な認証からのiMessageア...
- 「MLOps をマスターするための5つの無料コ...
- 「30+ AI ツールスタートアップのための(...
- TSMixer グーグルによる最新の予測モデル
- 「RAGAsを使用したRAGアプリケーションの...
- 高度な顔認識のためのDeepFace
- ウェアラブル汗センサーが炎症の分子的特...
- GPUを活用した特徴量エンジニアリングにお...
- KAIST(韓国科学技術院)からの新しいAI研...
- 「Amazon SageMaker JumpStartを使用して...
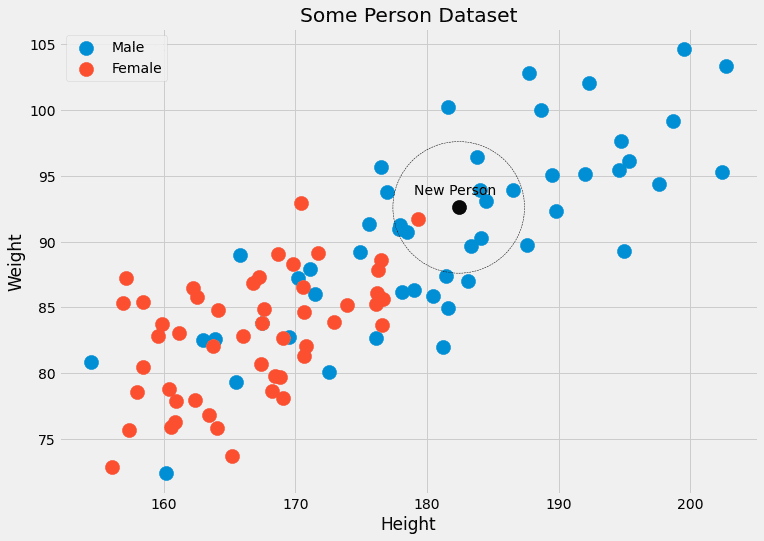
理論から実践へ:k最近傍法分類器の構築
k-最近傍法分類器は、新しいデータポイントを、k個の最も近い隣人の中で最も一般的なクラスに割り当てる機械学習アルゴリズムですこのチュートリアルでは、Pythonでこの分類器を構築および適用する基本的な手順を学びます
DataFrameを効率的に操作するためのloc Pandasメソッドの使い方
データに含まれるカラムや、生データの種類、データの記述統計量を把握することは、今後のデータ処理において正しく取り組むために非常に重要です
Pandas 2.0 データサイエンティストにとってのゲームチェンジャー?
Pandas 2.0の効率的なデータ操作を可能にするトップ5の機能を活用する方法を学び、データサイエンススキルを次のレベルに引き上げましょう!

PyTorchを使った効率的な画像セグメンテーション:パート1
この4部作では、PyTorchを使用して深層学習技術を使った画像セグメンテーションをゼロから段階的に実装しますシリーズを開始するにあたり、必要な基本的なコンセプトとアイデアについて説明します
PyTorchを使用した効率的な画像セグメンテーション:Part 4
この4部構成のシリーズでは、PyTorchを使用した深層学習技術を使って、画像セグメンテーションをゼロからステップバイステップで実装しますこのパートでは、Vision Transformerをベースとしたモデルの実装に焦点を当てます

機械学習における再現性の重要性
どのように、データ管理、バージョン管理、実験トラッキングの改善アプローチが再現可能なMLパイプラインの構築に役立つか

Mojo | 新しいプログラミング言語
はじめに プログラミング言語の世界は常に進化し続けていますが、新たな競合者が現れ、機械学習と人工知能のソフトウェア開発を簡素化し、開発者の生産性を向上させるようになりました。Mojoは、Pythonをルーツに持ち、研究から本番環境へのスムーズな移行を妨げるパフォーマンスとデプロイメントの課題に対処するために戦略的に設計された革新的なプログラミング言語として登場しました。Pythonの制限を改善することにより、Mojoはこれらの2つの重要な領域のギャップを成功裏に埋め合わせます。まだ開発の初期段階ですが、将来的にはPythonのスーパーセットになるように設計されています。このブログ投稿では、Mojoの主要な側面と、コードの書き方を革新する方法を探求します。 Modularは、AIおよびMLアプリケーションのPythonのパフォーマンス問題を解決するためにMojoを作成しました。Pythonは強力で多目的な言語ですが、CおよびC++などの他の言語に比べて1000倍遅くなってしまいます。Modularは、Pythonの使いやすさとCおよびC++のスピードを組み合わせる言語を作成したいと考えており、MojoはPythonに比べて35000倍高速であると主張しています。 出典:https://www.modular.com/mojo ¶ この記事は、Data Science Blogathonの一部として公開されました。 Mojoの特徴 次のような注目すべき機能があり、その機能を強化しています。 プログレッシブ型:Mojoは、型を活用してパフォーマンスとエラーチェックを強化することができます。型注釈を利用することで、開発者はコードを最適化し、コンパイル中に潜在的なエラーをキャッチすることができます。 ゼロコスト抽象化:Mojoは、値を構造体にインライン割り当てすることによって、ストレージを効率的に制御することができます。このアプローチにより、オーバーヘッドを最小限に抑え、最適なパフォーマンスを実現できます。 所有権と借用チェッカー:Mojoは、所有権と借用チェッカーを実装することでメモリの安全性を提供します。この機能により、ダングリングポインターやデータ競合などの一般的な問題を防止し、より堅牢で安全なプログラミング体験を提供します。 ポータブルパラメトリックアルゴリズム:Mojoは、コンパイル時メタプログラミングを活用することで、ハードウェアに依存しないアルゴリズムを書くことができます。このアプローチにより、ボイラープレートコードを減らし、柔軟でポータブルなソリューションを作成することができます。 言語統合自動チューニング:Mojoは、組み込みの自動チューニング機能を提供することで、パラメータの最適化プロセスを簡素化します。ターゲットハードウェア上でのパフォーマンスを最大化するための最適なパラメータ値を自動的に検索し、手動での微調整を必要としません。 さらに、Mojoは以下の機能を備えています。 MLIRのフルパワー:Mojoは、MLIR(Multi-Level Intermediate Representation)の全機能を活用しています。MLIRは、プログラムの効率的な最適化や変換を実現し、パフォーマンスを向上させ、他のMLフレームワークとのシームレスな統合を可能にします。 並列異種ランタイム:Mojoは、異なるハードウェアアーキテクチャ上での並列実行をサポートしています。この機能により、利用可能なリソースを効率的に活用し、マルチデバイスや分散コンピューティングシナリオでのパフォーマンスを向上させることができます。 高速コンパイルタイム:Mojoは、高速なコンパイルを優先し、開発者が素早く反復し、コード変更と実行の間の時間を短縮することができます。この機能により、スムーズな開発体験と迅速なフィードバックループが実現されます。 全体的に、Mojoは、パフォーマンス、安全性、ポータビリティ、および開発者の生産性に優れたプログラミング言語を提供するためにこれらの機能を組み合わせています。 パフォーマンス パフォーマンスに関しては、Mojoは、複数のコア、ベクトルユニット、専用アクセラレータユニットを含むハードウェアの潜在能力を最大限に活用することで、Pythonの能力を大幅に向上させています。これは、最新のコンパイラと異種ランタイムシステムを統合することによって実現されています。Mojoを使用することで、開発者は、現代のハードウェアアーキテクチャで利用可能な膨大な処理能力を引き出すことができます。…

プリンストン大学の研究者が、自然界の写実的な3Dシーンの手続き生成器であるInfinigenを紹介しました
プリンストン大学の研究チームは、「プロシージャルジェネレーションを使用した無限の写実的な世界」という最近の論文で、画期的なプロシージャルジェネレーターであるInfinigenを紹介しました。この研究は、多様性が限られ、現実世界のオブジェクトの複雑さを捉えることができない既存の合成データセットの制限に対処しています。 Infinigenは完全にプロシージャルなシステムであり、形状、テクスチャ、材料、およびシーンの構成を0から生成することができます。Infinigenの主要な特徴は、粗いおよび細かいジオメトリとテクスチャの詳細をプロシージャルに生成することによって高い写実性を生み出す能力にあります。Infinigenは分離されているため、生成されるすべてのジオメトリ情報は現実世界の参照に基づいており、合成されたシーンの真正性を高めています。 Infinigenのアーキテクチャは、プロシージャルジェネレーションの能力で知られている広く使用されているグラフィックスシステムであるBlenderに基づいて構築されています。研究チームは、自然物体やシーンのカバレッジを拡大するためのプロシージャルルールのライブラリを設計および実装しました。これらのルールはBlenderで利用可能な便利なプリミティブを活用しています。さらに、チームは、BlenderノードグラフをPythonコードに変換する自動変換ツールを含む、プロシージャルルールの作成を簡素化するユーティリティを開発しました。さらに、オブジェクトの深度、遮蔽境界、バウンディングボックス、光学フロー、表面法線、オブジェクトカテゴリ、およびインスタンスセグメンテーションなどの情報を提供するグラウンドトゥルーラベルで合成画像をレンダリングするユーティリティも開発されました。 Infinigenによって生成された合成データの品質を評価するために、チームは広範な実験を実施し、既存の合成データセットおよびジェネレーターと比較しました。これらの実験の結果、Infinigenは外部ソースに頼らずに写実的でオリジナルなアセットやシーンを生成する驚異的な能力を持っていることが示され、現実世界の複雑さをより正確に反映する多様で広範なトレーニングデータセットを生成する可能性を示しています。 Infinigenは、研究者がより広いコミュニティとの協力によって育成することを意図しているオープンソースプロジェクトです。彼らは、すべての現実世界の要素を包括するようにカバレッジを拡大し、その継続的な開発と成長を確保することにコミットしています。Infinigenを無料で提供することで、研究チームは協力を促進し、プロシージャルジェネレーションのさらなる進歩をインスパイアすることを望んでいます。 全体的に、Infinigenの導入は、コンピュータビジョンタスクのための合成データを生成するための重大な進歩を示しています。そのプロシージャルアプローチと写実的なシーンを生成する能力は、既存の合成データセットと現実世界のオブジェクトの複雑さのギャップを埋めることを約束し、さまざまなコンピュータビジョンアプリケーションでモデルをトレーニングするための貴重なツールとなります。

Ludwig – より「フレンドリーな」ディープラーニングフレームワーク
産業用途の深層学習については、私は避ける傾向があります興味がないわけではなく、むしろ人気のある深層学習フレームワークが扱いづらいと感じています私はPyTorchとTensorFlowを高く評価しています

ゼロから学ぶアテンションモデル
はじめに アテンションモデル、またはアテンションメカニズムとも呼ばれるものは、ニューラルネットワークの入力処理技術に使用されるものです。これにより、ネットワークは複雑な入力の異なる側面に集中し、全データセットを分類するまでに個別に処理できます。目標は、複雑なタスクを順次処理される注目の小さな範囲に分解することです。このアプローチは、人間の心が新しい問題をより簡単なタスクに分解し、ステップバイステップで解決する方法に類似しています。アテンションモデルは、特定のタスクにより適応し、パフォーマンスを最適化し、関連情報に注意を払う能力を向上することができます。 NLPにおけるアテンションメカニズムは、過去10年間でディープラーニングにおける最も価値のある発展の1つです。TransformerアーキテクチャやGoogleのBERTなどの自然言語処理(NLP)は、最近の進歩をもたらしています。 学習目標 ディープラーニングにおけるアテンションメカニズムの必要性、機能、モデルのパフォーマンスを向上させる方法を理解する。 アテンションメカニズムの種類や使用例を知る。 あなたのアプリケーションとアテンションメカニズムの使用のメリットとデメリットを探究する。 アテンションの実装例に従ってハンズオンでの経験を得る。 この記事はData Science Blogathonの一部として公開されました。 アテンションフレームワークを使用するタイミング アテンションフレームワークは、元々エンコーダー・デコーダー型のニューラル機械翻訳システムやコンピュータビジョンでのパフォーマンス向上に使用されました。従来の機械翻訳システムは、大規模なデータセットと複雑な機能を処理して翻訳を行っていましたが、アテンションメカニズムはこのプロセスを簡素化しました。アテンションメカニズムは、単語ごとに翻訳する代わりに、固定長のベクトルを割り当てて入力の全体的な意味と感情を捉え、より正確な翻訳を実現します。アテンションフレームワークは、エンコーダー・デコーダー型の翻訳モデルの制限に対処するのに特に役立ちます。入力のフレーズや文の正確なアラインメントと翻訳を可能にします。 アテンションメカニズムは、入力シーケンス全体を単一の固定コンテンツベクトルにエンコードするのではなく、各出力に対してコンテキストベクトルを生成することで、より効率的な翻訳が可能になります。アテンションメカニズムは翻訳の精度を向上させますが、常に言語的な完璧さを実現するわけではありません。しかし、オリジナルの入力の意図と一般的な感情を効果的に捉えることができます。要約すると、アテンションフレームワークは、従来の機械翻訳モデルの制限を克服し、より正確でコンテキストに対応した翻訳を実現するための貴重なツールです。 アテンションモデルはどのように動作するのか? 広い意味では、アテンションモデルは、クエリと一連のキー・バリューペアをマップする関数を使用して出力を生成します。これらの要素、クエリ、キー、値、および最終出力はすべてベクトルとして表されます。出力は、クエリと対応するキーの類似性を評価する互換性関数によって決定される重み付き平均値を取ることによって計算されます。 実践的な意味では、アテンションモデルは、人間が使用する視覚的アテンションメカニズムに近いものをニューラルネットワークで近似することを可能にします。人間が新しいシーンを処理する方法に似て、モデルは画像の特定の点に集中し、高解像度の理解を提供し、周囲の領域を低解像度で認識します。ネットワークがシーンをより良く理解するにつれて、焦点を調整します。 NumPyとSciPyを使用した一般的なアテンションメカニズムの実装 このセクションでは、PythonライブラリNumPyとSciPyを利用した一般的なアテンションメカニズムの実装を調べます。 まず、4つの単語のシーケンスのための単語埋め込みを定義します。単純化のために、単語埋め込みを手動で定義しますが、実際にはエンコーダーによって生成されます。 import numpy as np…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.