Learn more about Search Results H3 - Page 194

- You may be interested
- 「ICML 2023でのGoogle」
- 「リトリーバルの充実は長文の質問応答に...
- Hugging Face Datasets での作業
- これは本当のマルチモーダル学習ですか?-...
- 「ChatGPT Visionをデータ分析に活用する5...
- 人工知能に投資するのですか? 考慮すべき...
- 「Feature Store Summit 2023 プロダクシ...
- 「プロジェクトRumiにご参加ください:大...
- トップ7の列操作でより効果的にPandasデー...
- AIの脅威:自動化された世界における見え...
- 「GPTCacheとは:LLMクエリセマンティック...
- 私たちはどのように大規模な言語モデルを...
- 中国の研究者たちは、RetriKTと呼ばれる新...
- 最適なテクノロジー/ベンダーを選ぶための...
- ジェネラティブAIをマスターするための5つ...
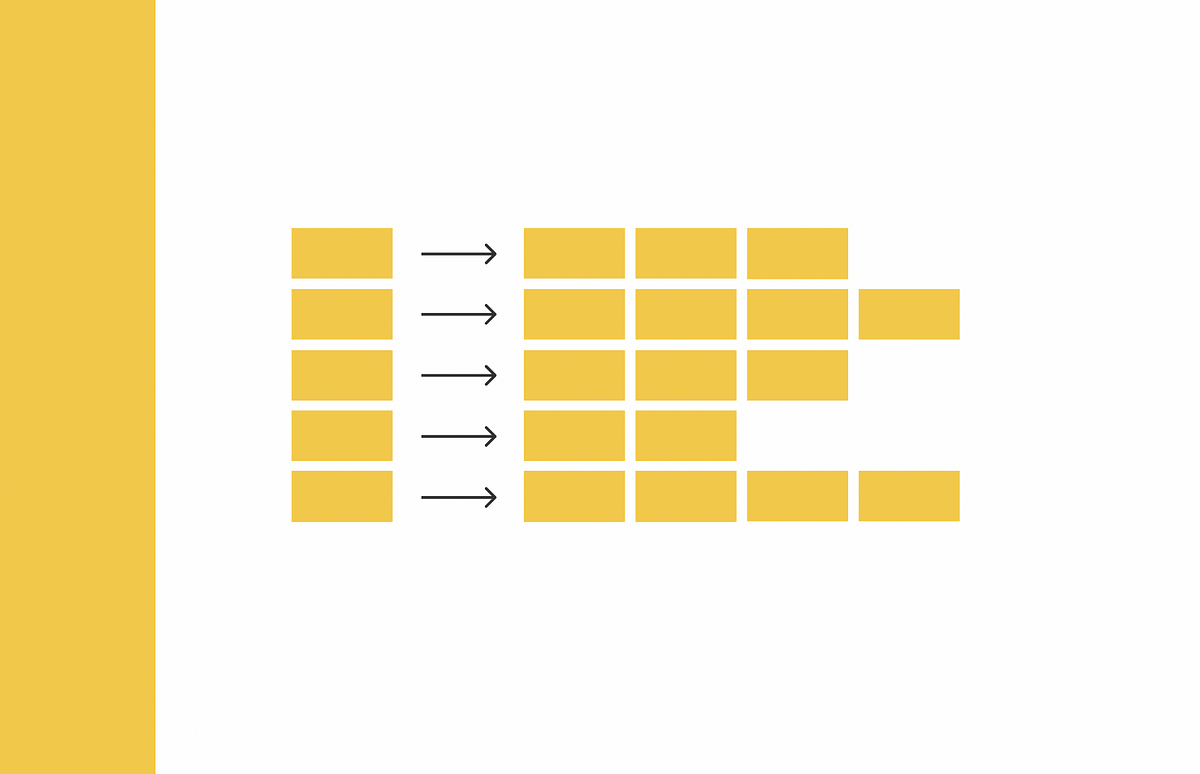
類似検索、パート5:局所性鋭敏ハッシュ(LSH)
類似度検索とは、クエリが与えられたときに、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目的とした問題ですデータサイエンスにおいては、類似度検索はしばしば自然言語処理において現れます...
次回のデータプロジェクトで興味深いデータセットを取得する5つの方法(Kaggle以外)
素晴らしいデータサイエンスプロジェクトの鍵は素晴らしいデータセットですが、素晴らしいデータを見つけることは言うほど簡単ではありません私がデータサイエンス修士課程を勉強していた頃を覚えていますが、それはちょうど...

2023年に知っておくべきトップ10のパワフルなデータモデリングツール
イントロダクション データ駆動型の意思決定の時代において、競争力を維持するために正確なデータモデリングツールを持つことは企業にとって不可欠です。新しい開発者として、堅牢なデータモデリングの基礎は、データベースを効果的に扱うために重要です。適切に構成されたデータ構造は、スムーズなワークフローを確保し、データの損失や誤配置を防止します。 大規模で複雑なタスクに取り組むために、データモデリングツールを利用することがますます重要になっています。これらのツールは時間を節約するだけでなく、データモデリングのプロセスを簡素化することができます。 トランスフォーメーションに寄与するトップ10のデータモデリングツールを発見してください。効率性を求める経験豊富なプロフェッショナルから、ユーザーフレンドリーなソリューションを求める初心者まで、あなたのニーズに合わせて提供します。データの真のポテンシャルを引き出し、自信を持って賢い決定をする旅に出ましょう! データモデリングツールとは何ですか? データモデルは、UML図を使用してしばしば視覚的にデータ仕様を表します。データはSQLまたはNoSQLデータベースに格納され、データモデリングにはどの情報を収集し、どのように格納するかを決定することが含まれます。 データモデリングツールは、データモデリングプロセスを効率化するために使用されます。これらのツールは、データとその複数のモデル層との間のギャップを埋めます。これらのツールは、既存のデータベースをリバースエンジニアリングし、スキーマとモデルを比較およびマージし、自動的にデータベーススキーマまたはDTDを生成することができます。 効果的なデータモデリングソフトウェアは、魅力的な視覚的表現とデータベースとのシームレスな統合を提供します。ユーザーフレンドリーなデータモデリングツールは、概念的なデータモデリングをよりアクセスしやすくします。 データモデリングツールを選ぶ際に考慮すべきことは何ですか? データモデリングツールを選ぶ際には、特定のニーズを決定することが重要です。必須要件と望ましい要件を分類し、後者を優先させます。この決定は長期的な影響を持つ可能性があるため、組織内のさまざまな視点からの意見を考慮してください。 すべてのデータモデリングツールが物理モデルと論理モデルの作成、リバースエンジニアリング、およびフォワードエンジニアリングなどの基本的なタスクを処理できますが、追加の要因も考慮する必要があります。これには、チームベースのモデリング機能、バージョニング、図のカスタマイズオプション、モデルリポジトリの機能、概念的なデータモデルのサポート、エンタープライズメタデータリポジトリとの統合、および異なるモデルレベル(概念的、論理的、物理的)にわたるオブジェクトラインの維持のためのデータ合理化が含まれます。これらの要因は、あなたのデータモデリングニーズについての情報を提供し、適切な選択をするのに役立ちます。 トップ10のデータモデリングツール 1. ER/Studio Embarcadero Technologiesが開発したER/Studioは、データアーキテクト、モデラー、DBA、ビジネスアナリストにとって有用であり、データベース設計とデータ再利用を管理するために役立ちます。ツールによって、データベースコードを自動的に生成することができます。 属性と定義の完全なドキュメントを備えたツールは、ビジネスコンセプトをモデリングするのに役立ちます。 特徴 論理モデルと物理モデルの両方をサポート ツールによって、新しいデータベースの変更に対する影響分析が実施されます。 自動化とスクリプトのサポート サポートされるプレゼンテーションファイルの種類には、HTML、PNG、JPEG、RTF、XML、Schema、DTDが含まれます。 ER/Studioによって、モデルとデータベースの一貫性が保証されます。 価格…

AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
機械学習研究の最新リリースで、ビジョン言語事前学習(VLP)とその多様なタスクへの応用について、研究チームが深く掘り下げています。この論文は、単一モーダルトレーニングのアイデアを探究し、それがマルチモーダル適応とどのように異なるかを説明しています。そして、VLPの5つの重要な領域である特徴抽出、モデルアーキテクチャ、事前トレーニング目標、事前トレーニングデータセット、およびダウンストリームタスクを示しています。研究者たちは、既存のVLPモデルとその異なる側面での適応をレビューしています。 人工知能の分野は常に、モデルを人間と同じように知覚、思考、そしてパターンや微妙なニュアンスを理解する方法でトレーニングしようとしてきました。ビジュアル、オーディオ、テキストなど、可能な限り多くのデータ入力フィールドを組み込もうとする試みがいくつか行われてきました。ただし、これらのアプローチのほとんどは、単一モーダル意味で「理解」の問題を解決しようとしたものです。 単一モーダルアプローチは、1つの側面のみを評価するアプローチであり、例えばビデオの場合、音声またはトランスクリプトに焦点を絞っており、マルチモーダルアプローチでは、可能な限り多くの利用可能な特徴をターゲットにしてモデルに組み込もうとします。たとえば、ビデオを分析する際に、音声、トランスクリプト、スピーカーの表情をとらえて、文脈を本当に「理解」することができます。 マルチモーダルアプローチは、リソースが豊富であり、訓練に必要な大量のラベル付きデータを取得することが困難であるため、課題があります。Transformer構造に基づく事前トレーニングモデルは、自己教師あり学習と追加タスクを活用して、大規模な非ラベルデータからユニバーサルな表現を学習することで、この問題に対処しています。 NLPのBERTから始まり、単一モーダルの方法でモデルを事前トレーニングすることで、限られたラベル付きデータでダウンストリームタスクを微調整することができることが示されています。研究者たちは、同じ設計哲学をマルチモーダル分野に拡張することで、ビジョン言語事前学習(VLP)の有効性を探究しました。VLPは、大規模なデータセットで事前トレーニングモデルを使用して、モダリティ間の意味的な対応関係を学習します。 研究者たちは、VLPアプローチの進歩について、5つの主要な領域を検討しています。まず、VLPモデルが画像、ビデオ、テキストを前処理して表現する方法、使用されるさまざまなモデルを強調して説明しています。次に、単一ストリームの観点とその使用可能性、デュアルストリームフュージョンとエンコーダのみ対エンコーダデコーダ設計の観点を探究しています。 論文では、VLPモデルの事前トレーニングについてさらに探求し、完了、マッチング、特定のタイプに分類しています。これらの目標は、ユニバーサルなビジョン言語表現を定義するのに役立ちます。研究者たちは、2つの主要な事前トレーニングデータセットのカテゴリである画像言語モデルとビデオ言語モデルについて概説しました。論文では、マルチモーダルアプローチが文脈を理解し、より適切にマッピングされたコンテンツを生成するためにどのように役立つかを強調しています。最後に、記事は、事前トレーニングモデルの有効性を評価する上での重要性を強調しながら、VLPのダウンストリームタスクの目標と詳細を提示しています。 https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf この論文では、SOTA(State-of-the-Art)のVLPモデルについて詳細な概要が提供されています。これらのモデルをリストアップし、その主要な特徴やパフォーマンスを強調しています。言及されているモデルは、最先端の技術開発の堅固な基盤であり、将来の開発のベンチマークとして役立ちます。 研究論文に基づくと、VLPアーキテクチャの将来は有望で信頼性があります。彼らは、音響情報の統合、知識と認知学習、プロンプトチューニング、モデル圧縮と加速、およびドメイン外の事前学習など、様々な改善の領域を提案しています。これらの改善領域は、新しい研究者たちがVLPの分野で前進し、画期的なアプローチを打ち出すためにインスピレーションを与えることを目的としています。

Amazon SageMaker Data WranglerのSnowflakeへの直接接続でビジネスインサイトまでの時間を短縮してください
Amazon SageMaker Data Wranglerは、1つのビジュアルインターフェイスで、コードを書くことなく機械学習(ML)ワークフローでデータの選択とクリーニング、特徴量エンジニアリングの実行に必要な時間を週から分単位に短縮することができ、データの準備を自動化することができますSageMaker Data Wranglerは、人気のあるSnowflakeをサポートしています
線形回帰の理論的な深堀り
多くのデータサイエンス志望のブロガーが行うことがあります 線形回帰に関する入門的な記事を書くことですこれは、この分野に入る際に最初に学ぶモデルの1つであるため、自然な選択肢です...
Pythonの依存関係管理:どのツールを選ぶべきですか?
あなたのデータサイエンスプロジェクトが拡大するにつれて、依存関係の数も増えますプロジェクトの環境を再現可能かつメンテナンス可能に保つために、効率的な依存関係を使用することが重要です...

GPTとBERT:どちらが優れているのか?
生成AIの人気の高まりに伴い、大規模言語モデルの数も増加していますこの記事では、GPTとBERTの2つのモデルを比較しますGPT(Generative...

LLMsによる非構造化データから構造化データへの変換
大規模な言語モデルを使用して、文書から洞察を抽出して分析と大規模な機械学習に活用する方法を学びましょうこのウェビナーとライブチュートリアルに参加して、始め方を学びましょう

Btech卒業後に何をすべきですか?
Btechの後に何をすべきですか?このよくある質問は、最終学年や最近卒業した学生にとって悩みの種です。多くの人々が従来のキャリアパスを選ぶ一方、一部の人々は新しい分野でのキャリアを研究し探求することを決めます。より多くの選択肢を探索し、スキル開発に重点を置き、継続的な学習、進化する技術について常に最新情報を得ることにより、個人は速いペースのBtechの後の旅で成功することができます。この記事では、Btechの後の最良のキャリアオプションについて説明しています。 Btech卒業生の従来のキャリアパス エンジニアの仕事 ソフトウェアエンジニア/開発者: コンピューターサイエンスのBTechを持つソフトウェアエンジニアは、オンラインやモバイルアプリ、データベース管理、ソフトウェアアーキテクチャの開発に参加します。 ハードウェアエンジニア: ハードウェアエンジニアは、コンピューターハードウェアコンポーネントを作成、開発、テストし、最適な動作を確保します。 機械エンジニア: 製品設計、ロボット、産業機械など多様な産業で機械システムを開発、分析、構築します。 電気エンジニア: 電力発電、エレクトロニクス、通信、再生可能エネルギーシステムを計画、開発、維持します。 土木エンジニア: 建設、構造の安全性、環境持続性を維持しながら、インフラプロジェクトの計画、設計、構築、維持を行います。 宇宙航空エンジニア: 航空機、宇宙船、関連技術の設計、開発、テストの責任を担います。 化学エンジニア: 石油化学、医薬品、環境工学、材料科学など、幅広い産業でプロセスを作成、管理します。 環境エンジニア: 環境保護、持続可能性、廃棄物管理のソリューションを提供し、規制に適合します。 大学院研究と研究 MTechまたはME: BTech卒業生は、MTechまたはMEなどの大学院課程を追求することができます。これらには研究の可能性、高度なコースワーク、エンジニアリングの専門分野が含まれます。 MS: BTech卒業生は、研究、コースワーク、協力、論文の達成に焦点を当てた工学のMaster…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.