Learn more about Search Results H3 - Page 193

- You may be interested
- 算術推論問題のための即座のエンジニアリング
- 科学者たちは、AIと迅速な応答EEGを用いて...
- AI倫理の役割:革新と社会的責任のバランス
- ユーザーエクスペリエンスの向上:インタ...
- 「無料ハーバード講座:PythonでのAI入門」
- Google DeepMindの発表
- AIにおける継続的学習の現状について
- AIの環境負荷軽減:アプリを持続可能にす...
- 「Python Pandasを使ったカテゴリカルデー...
- 「テックの専門家たちは、ChatGPTのA.I.『...
- ChatGPTは自己を規制するための法律を作成...
- 「Auto-GPT&GPT-Engineer:今日の主要なA...
- 「Jais アラビア語-英語の大規模言語モデ...
- 「MIT研究者がLILOを導入:プログラム合成...
- ChatGPTで説得力を高めましょう

データサイエンスと機械学習の違いは何ですか?
はじめに 「データサイエンス」と「機械学習」は、25世紀において注目すべき技術的なトピックです。初心者のコンピュータサイエンスの学生からNetflixやAmazonなどの大手企業まで、様々なエンティティによって利用されています。ビッグデータの急増により、ペタバイトやエクサバイト単位で測定される膨大な量のデータを扱う新しい時代が訪れました。過去には、データのストレージには重大な課題がありましたが、現在ではHadoopなどのフレームワークによってこれらの問題が解決され、データ処理に重点が移りました。この文脈において、データサイエンスと機械学習は重要な役割を果たしています。しかし、これら2つの用語の違いは何でしょうか?この記事では、データサイエンスと機械学習の比較を掘り下げ、その違いを探ります。 データサイエンスとは? ビジネスや組織がリポジトリに保持する膨大な量のデータの複雑な分析を行うことです。データのソース、データの主題の分析、そしてデータが将来的にビジネスの成長にどのように役立つかについて、この研究ではすべてカバーされます。常に2つのタイプの組織データがあります。構造化データと非構造化データです。このデータを分析することで、市場やビジネストレンドについて重要なことを学び、データセット内のパターンを特定することにより、企業は効率を向上させ、競合他社と差別化することができます。 機械学習とは? 機械学習という研究分野のおかげで、コンピュータは明示的にプログラムされることなく学習することができるようになりました。機械学習はアルゴリズムを使用してデータを処理し、予測を行うためにトレーニングされます。指示、データ、または観察値が機械学習の入力となります。機械学習の利用は、Facebook、Googleなどの企業で広く行われています。 データサイエンス vs 機械学習 側面 データサイエンス 機械学習 定義 構造化および非構造化データから知識と洞察を抽出するために、科学的な方法、プロセス、アルゴリズム、およびシステムを使用する多様な分野。 明示的にプログラムされることなく、コンピュータシステムが学習し、予測や決定を行うためのアルゴリズムと統計モデルを開発する人工知能(AI)のサブフィールド。 スコープ データ収集、クリーニング、分析、可視化、解釈など、データライフサイクルのさまざまな段階を包括する広い範囲。 データから学習し、予測や決定を行うためのアルゴリズムとモデルの開発に焦点を絞った狭い範囲。 目標 複雑な問題を解決し、データに基づいて意思決定を行うために、データから洞察、パターン、そして知識を抽出すること。 機械がデータから学び、特定のタスクにおいて自動的にパフォーマンスを向上させるためのモデルとアルゴリズムを開発すること。 技術 統計、データマイニング、データ可視化、機械学習、深層学習など、様々な技術やツールを組み合わせています。 教師あり学習、教師なし学習、強化学習、深層学習などの機械学習アルゴリズムの適用に主眼を置いています。…

近接度とコミュニティ:PythonとNetworkXによるソーシャルネットワークの分析—Part 3
PythonとNetworkXを使用して近接中心性を計算し、ネットワークグラフを可視化する方法を学び、社会ネットワーク分析を実施する方法を学びます

メタAIのもう一つの革命的な大規模モデル — 画像特徴抽出のためのDINOv2
Mete AIは、画像から自動的に視覚的な特徴を抽出する新しい画像特徴抽出モデルDINOv2の新バージョンを紹介しましたこれはAIの分野でのもう一つの革命的な進歩です...

AIが開発者の生活を簡単にする10の方法
AIは、テストやバグ修正などの繰り返しのタスクを自動化し、開発者がより創造的で戦略的な作業に集中することができるようにします

市民データサイエンティストとは誰で、何をするのでしょうか?
イントロダクション 今日のデータ駆動の世界において、データサイエンティストの役割は不可欠となっています。しかし、広大なデータセットに隠された謎を解くためには、データサイエンスのPh.D.を持つ必要はないと言ったらどうでしょうか?自己研鑽によって、正式な訓練を受けていないにもかかわらず、価値ある洞察を見出すスキルとツールを持つ新しいタイプの人材である「市民データサイエンティスト」の時代が到来しました。市民データサイエンティストは、形式的な訓練を受けていない普通の人々でありながら、データを行動可能な知識に変換する非凡な能力を持っており、組織が意思決定を行う方法を革新しています。本記事では、市民データサイエンティストの台頭、ビジネスへの影響、および彼らがもたらすエキサイティングな可能性について探求します。 市民データサイエンティストとは何か? 市民データサイエンティストとは、正式なデータサイエンスの訓練を受けていない個人でありながら、データを分析し洞察を導き出すスキルとツールを持っています。自己サービス型の分析プラットフォームや直感的なツールを活用して、データを探索し、モデルを構築し、データに基づく意思決定を行うことで、組織内でデータの力を民主化しています。 組織が彼らを雇うべき理由 データサイエンスは組織に著しい利益をもたらす広大な分野であり、市民データサイエンティストはデータの力を活用する上で重要な役割を担っています。以下は、企業が彼らを必要とする理由のいくつかです。 データ分析を簡素化する: 市民データサイエンティストは、さまざまな部門やチームに統合されており、特定のビジネスの課題に取り組み、それに関連するデータを探索することができます。これにより、より深い理解とより良い意思決定が可能になります。 ギャップを埋める: 彼らはドメインの専門知識とデータサイエンスの確固たる理解を持っており、技術的なスキルと業界知識をつなぐことができます。これにより、データ分析に文脈と洞察をもたらすことができます。 リアルタイムの洞察: 彼らはドメインの専門知識と自動分析ツールへのアクセス権を持っているため、リアルタイムでデータを分析し、意思決定者に迅速な洞察を提供することができます。これにより、組織は素早く対応し、機会をつかみ、リスクを効果的に軽減することができます。 フォースマルチプライヤー: 彼らはルーティンのデータ分析タスクを担当することで、データサイエンティストがより複雑な課題や戦略的なイニシアチブに注力できるようになります。彼らはフォースマルチプライヤーとして機能し、複数のチームをサポートし、全体的な生産性を向上させます。 ユニークな視点: 彼らは、データ分析に自分たちの多様な経験と専門知識をもたらし、新鮮な視点や革新的な問題解決アプローチを生み出すことができます。彼らのユニークな洞察は、しばしば新しい発見や改善された意思決定につながります。 アジャイルな実験: 市民データサイエンティストは、さまざまな分析手法を試行し、モデルを修正し、仮説をテストする柔軟性を持っています。彼らの適応力は、異なる分析手法を実験することでイノベーションを促進し、各自の分野での進歩を推進します。 必要な主要なスキル 市民データサイエンティストとして成功するために必要なスキルセットには、以下のような分析技術、技術的スキル、および専門的スキルが含まれます。 市民データサイエンティストは、Tableau、Power BI、またはMatplotlibやSeabornなどのPythonライブラリなどのプログラムを使用して、データを視覚的に解釈し、提示することができるようになっている必要があります。 彼らはデータを扱い、統計的手法を適用し、単純な機械学習モデルを開発するための基本的なプログラミングスキルを持っている必要があります。PythonやRなどのプログラミング言語に精通していることが有利です。 彼らはまた、統計学、データモデリング、データ可視化などのいくつかの分野に精通しており、データを評価・解釈し、より有用で効果的な洞察を生み出すことができます。…

CoDiに会おう:任意対任意合成のための新しいクロスモーダル拡散モデル
ここ数年、テキストからテキスト、画像、音声など、別の情報を生成する堅牢なクロスモーダルモデルが注目されています。注目すべき例としては、入力プロンプトによって期待される結果を説明することで、素晴らしい画像を生成できるStable Diffusionがあります。 実際にリアルな結果を出すにもかかわらず、これらのモデルは複数のモダリティが共存し相互作用する場合には実用上の制限があります。たとえば、「かわいい子犬が革製のソファで寝ている」というテキストの説明から画像を生成したいとしましょう。しかしそれだけでは不十分です。テキストから画像へのモデルから出力画像を受け取った後、子犬がソファで鼾をかいているという状況にどのような音がするかも聞きたいと思うでしょう。この場合、テキストまたは出力された画像を音に変換する別のモデルが必要になります。したがって、多数の特定の生成モデルをマルチステップの生成シナリオで接続することは可能ですが、このアプローチは手間がかかり遅くなる可能性があります。また、独立して生成された単一のストリームは、ビデオとオーディオを同期させるように、後処理的な方法で組み合わせた場合に一貫性とアラインメントが欠けることがあります。 包括的かつ多目的なany-to-anyモデルは、一貫したビデオ、オーディオ、およびテキストの説明を同時に生成し、全体的な体験を向上させ、必要な時間を減らすことができます。 この目標を達成するため、Composable Diffusion(CoDi)が開発され、任意のモダリティの組み合わせを同時に処理し生成することができるようになりました。 アーキテクチャの概要は以下に示されています。 https://arxiv.org/abs/2305.11846 任意のモダリティの混合物を処理し、さまざまな出力の組み合わせを柔軟に生成するモデルをトレーニングすることは、大きな計算量とデータ要件を必要とします。 これは、入力と出力のモダリティの可能性の指数関数的な成長に起因します。さらに、多数のモダリティグループの整列されたトレーニングデータを取得することは非常に限られており、存在しないため、すべての可能な入力-出力の組み合わせを使用してモデルをトレーニングすることは不可能です。この課題に対処するために、入力条件付けと生成散布ステップで複数のモダリティを整列させる戦略が提案されています。さらに、対照的な学習のための「ブリッジアライメント」戦略を導入することで、指数関数的な入力-出力の組み合わせを線形数のトレーニング目的で効率的にモデル化できます。 高品質な生成を維持し、任意の組み合わせを生成する能力を持ったモデルを実現するには、多様なデータリソースを活用した包括的なモデル設計とトレーニングアプローチが必要です。研究者たちは、CoDiを構築するために統合的なアプローチを採用しました。まず、テキスト、画像、ビデオ、音声など、各モダリティのために潜在的な散乱モデル(LDM)をトレーニングします。これらのLDMは、利用可能なモダリティ固有のトレーニングデータを使用して、各個別のモダリティの優れた生成品質を保証するために独立して並列にトレーニングできます。このデータには、1つ以上のモダリティを持つ入力と出力モダリティが含まれます。 音声や言語のプロンプトを使用して画像を生成するなど、モダリティの組み合わせが関わる条件付きクロスモダリティ生成の場合、入力モダリティは共有特徴空間に投影されます。このマルチモーダル調整メカニズムにより、特定の設定の直接トレーニングを必要とせずに、CoDiは任意のモダリティまたはモダリティの組み合わせに対して条件を付けることができます。出力LDMは、結合された入力特徴に注意を払い、クロスモダリティ生成を可能にします。このアプローチにより、CoDiはさまざまなモダリティの組み合わせを効果的に処理し、高品質な出力を生成することができます。 CoDiのトレーニングの第2段階は、多数の多対多生成戦略を処理できるモデルの能力を促進し、異なるLDMからの潜在変数を共有潜在空間に投影する環境エンコーダVと、各散布器にクロスアテンションモジュールを導入することで実現されます。現在の知識の範囲では、CoDiはこの能力を持つ最初のAIモデルとして立ち上がっています。 このステージでは、LDMのパラメーターは固定され、クロスアテンションパラメーターとVのみがトレーニングされます。環境エンコーダーが異なるモダリティの表現を整列させるため、LDMはVを使用して出力表現を補間することで、任意の共同生成モダリティのセットとクロスアテンドできます。このシームレスな統合により、CoDiは可能な生成組み合わせすべてでトレーニングする必要がなく、任意のモダリティの任意の組み合わせを生成できます。その結果、トレーニング目的の数は指数関数から線形関数に削減され、トレーニングプロセスの効率が大幅に向上します。 モデルによって生成されたいくつかの出力サンプルは、各生成タスクについて以下に報告されています。 https://arxiv.org/abs/2305.11846 これがCoDiの概要であり、最先端の品質を持つ任意の生成に対する効率的なクロスモーダル生成モデルです。興味がある場合は、以下のリンクでこの技術について詳しく学ぶことができます。

データエンジニアが本当にやっていること?
データ主導の世界では、データエンジニアのような裏方のヒーローたちは、スムーズなデータフローを確保するために重要な役割を果たしています。突然不適切なおすすめを受け取ったオンラインショッパーを想像してみてください。データエンジニアは問題を調査し、電子商取引プラットフォームのデータファンネルに欠陥があることを特定し、スムーズなデータパイプラインを迅速に実装します。データサイエンティストやアナリストに注目が集まる一方で、データエンジニアの執念深い努力によって、組織内の情報に基づく意思決定に必要なアクセスしやすく、よく準備されたデータが保証されています。データエンジニアは具体的に何をするのでしょうか?彼らはどのようにビジネスの成功に貢献しているのでしょうか?彼らの世界に飛び込んで、データエンジニアの職務内容、役割、責任、そしてあなたの燃えるような疑問に答えましょう。 データエンジニアの職務内容 データエンジニアは、生データを貴重な洞察に変換し、ビジネスアナリストやデータサイエンティストが活用できるように、データを収集、管理、変換することで重要な役割を果たします。彼らの主な目的は、データのアクセシビリティを確保し、企業がパフォーマンスを最適化し、情報に基づいた意思決定を行うことを可能にすることです。彼らはアルゴリズムを設計し、統計を分析し、ビジネス目標に応じてデータシステムを整合させ、効率を最大化します。データエンジニアには強力な分析スキル、多様なソースからデータを統合する能力、プログラミング言語の熟練度、および機械学習技術の知識が必要です。データエンジニアの職務内容は広範であり、組織のデータ主導の成功に貢献する多くの役割と責任を包括しています。 データエンジニアの役割と責任 データエンジニアの役割と責任は、要件に基づいて会社によって異なる場合があります。ただし、一般的なデータエンジニアの責任には、以下が含まれます: 完璧なデータパイプライン設計の開発および維持。 手動操作の自動化、データ配信の改善、スケーラビリティの向上のためのインフラ再設計など、内部プロセスの改善を特定し、計画し、実行する。 SQLおよびAWSビッグデータ技術を利用して、幅広いデータソースからの効果的なデータ抽出、変換、およびロードに必要なインフラの作成。 機能的および非機能的なビジネス目標を満たす膨大で複雑なデータセットの作成。 データファンネルを利用した分析ソリューションの構築により、新しい顧客獲得、業務効率改善、およびその他の重要な企業パフォーマンス指標に対する具体的な洞察を提供する。 エグゼクティブ、プロダクト、データ、およびデザインチームなどのステークホルダーがデータインフラ関連の課題に直面した場合に、彼らのデータインフラ要件を満たすために支援する。 複数のデータセンターやAWSリージョンを利用することで、国際境界を越えたデータのプライバシーとセキュリティを維持する。 データおよび分析プロフェッショナルと協力して、データシステムの運用を改善する。 さらに読む:ジョブ比較-データサイエンティストvsデータエンジニアvs統計学者 データエンジニアに必要なスキル データエンジニアになりたい場合、ある程度の技術的およびソフトスキルに精通している必要があります。 技術的スキル 自分たちの役割で優れた成果を出すために、データエンジニアは以下の技術的スキルを持っている必要があります。 コーディング Python、Java、SQL、NoSQL、Ruby、Perl、MatLab、R、SAS、C and C++、Scala、Golangなどのプログラミング言語の熟練度は、ほとんどの企業で高く評価されます。コーディングの堅牢な基盤は、データエンジニアのポジションにおいて不可欠です。 オペレーティングシステムの理解 データエンジニアは、Microsoft…

あなたのポケットにアーティストの相棒:SnapFusionは、拡散モデルのパワーをモバイルデバイスにもたらすAIアプローチです
拡散モデル。AI領域の進歩に注目している場合、この用語については多く聞いたことがあるでしょう。それらは生成型AI手法の革命を可能にした鍵でした。我々は今や、テキストプロンプトを使用して数秒で写真のような逼真的な画像を生成するモデルを持っています。それらは、コンテンツ生成、画像編集、スーパーレゾリューション、ビデオ合成、3Dアセット生成を革新しました。 しかし、この印象的なパフォーマンスには高いコンピューテーション要件が伴います。つまり、それらを完全に活用するには本当に高性能のGPUが必要です。はい、それらをローカルコンピュータで実行する試みもありますが、それでも高性能なものが必要です。一方、クラウドプロバイダを使用することも代替解決策となりますが、その場合はプライバシーを危険にさらす可能性があります。 そして、考えなければならないのは、移動中に使用することです。ほとんどの人々は、コンピュータよりもスマートフォンで時間を過ごしています。拡散モデルをモバイルデバイスで使用したい場合、デバイス自体の限られたハードウェアパワーにとって要求が高すぎるため、うまくいく可能性はほぼありません。 拡散モデルは次の大きな流行ですが、実用的なアプリケーションに適用する前にその複雑さに対処する必要があります。モバイルデバイスでの推論の高速化に焦点を当てた複数の試みが行われていますが、シームレスなユーザーエクスペリエンスや定量的な生成品質を達成していませんでした。それは今までの話であり、新しいプレイヤーがフィールドに登場しているのです。SnapFusionと名付けられたこのプレイヤーです。 SnapFusionは、モバイルデバイスで2秒以下で画像を生成する最初のテキストから画像への拡散モデルです。UNetアーキテクチャを最適化し、ノイズ除去ステップ数を減らすことで推論速度を向上させています。さらに、進化するトレーニングフレームワークを使用し、データ蒸留パイプラインを導入し、ステップ蒸留中に学習目標を強化しています。 SnapFusionの概要。出典:https://arxiv.org/pdf/2306.00980.pdf SnapFusionの構造に変更を加える前に、SD-v1.5のアーキテクチャの冗長性を調査して、効率的なニューラルネットワークを得ることが最初に行われました。しかし、SDに従来のプルーニングやアーキテクチャサーチ技術を適用することは、高いトレーニングコストのために困難でした。アーキテクチャの変更は性能の低下につながる可能性があり、大規模な計算リソースを必要とする厳密な微調整が必要となります。そのため、その道は閉ざされ、彼らは、事前にトレーニングされたUNetモデルのパフォーマンスを維持しながら効果を徐々に向上させる代替方法を開発する必要がありました。 推論速度を向上させるために、SnapFusionは、条件付き拡散モデルのボトルネックであるUNetアーキテクチャを最適化することに焦点を当てています。既存の作品は主にトレーニング後の最適化に焦点を当てていますが、SnapFusionはアーキテクチャの冗長性を特定し、元のStable Diffusionモデルを上回る進化するトレーニングフレームワークを提案することで、推論速度を大幅に向上させています。また、イメージデコーダーを圧縮して高速化するためのデータ蒸留パイプラインを導入しています。 SnapFusionには、各クロスアテンションとResNetブロックを一定の確率で実行する確率的フォワード伝播が適用される堅牢なトレーニングフェーズが含まれています。この堅牢なトレーニング拡張機能により、ネットワークがアーキテクチャの変化に対して耐性があることが保証され、各ブロックの正確な評価と安定したアーキテクチャの進化が可能になります。 効率的なイメージデコーダーは、チャネル削減によって得られたデコーダーを使用して合成データを使用して蒸留パイプラインを介して達成されます。この圧縮デコーダは、SD-v1.5のものよりもはるかに少ないパラメータを持ち、より速くなっています。蒸留プロセスには、テキストプロンプトを使用してSD-v1.5のUNetから潜在表現を取得することで、効率的なデコーダーから1つ、SD-v1.5から1つの画像を生成することが含まれます。 提案されたステップ蒸留アプローチには、バニラ蒸留損失目的が含まれており、これは、生徒のUNetの予測と教師のUNetのノイズのある潜在表現との不一致を最小化することを目的としています。さらに、CFG-aware蒸留損失目的が導入され、CLIPスコアを改善します。CFGガイドされた予測は、教師モデルと生徒モデルの両方で使用され、CFGスケールはトレーニング中にFIDスコアとCLIPスコアのトレードオフを提供するためにランダムにサンプリングされます。 SnapFusionによって生成されたサンプル画像。出典: https://arxiv.org/pdf/2306.00980.pdf 改善されたステップ蒸留とネットワークアーキテクチャの開発のおかげで、SnapFusionは、モバイルデバイス上のテキストプロンプトから512×512の画像を2秒未満で生成することができます。生成された画像は、最先端のStable Diffusionモデルと同様の品質を示しています。
ベイジアンマーケティングミックスモデルの理解:事前仕様に深く入り込む
ベイジアン・マーケティング・ミックス・モデリングは、特にLightweightMMM(Google)やPyMC Marketing(PyMC Labs)などのオープンソースツールの最近のリリースにより、ますます注目を集めています...
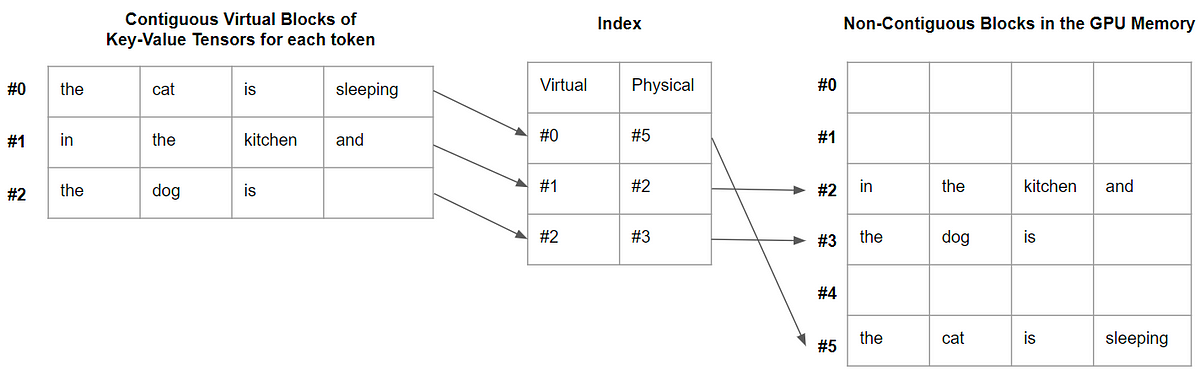
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.