Learn more about Search Results A - Page 192

- You may be interested
- RedPajamaプロジェクト:LLMの民主化を目...
- 「2023年の最高のAIアバタージェネレータ...
- 「初心者のためのイメージ分類」
- AIを活用してホームレスを防ぐ:ロサンゼ...
- 『UC BerkeleyがAIフィードバックから強化...
- インテルの研究者たちは、CPU上でLLMs(La...
- 「GoogleがCloud TPU v5pとAIハイパーコン...
- AIが使われて新しいビートルズの最後の曲...
- XGBoost 最終ガイド(パート2)
- クラウドセキュリティの未来:トレンドと予測
- エッジでのビジュアル品質検査のためのエ...
- 「マルチラベル分類:PythonのScikit-Lear...
- 「脳に触発された人工知能についての意見...
- 「10 個の最高の AI スケジューリングアシ...
- 「データパイプラインについての考え方が...

「Juliaプログラミング言語の探求 ユニットテスト」
エンドツーエンドの機械学習プロジェクトを開発するためのJuliaプログラミング言語の探索シリーズへようこそ👋今回はユニットテストについて詳しく見ていきますユニットテストは重要な役割を果たします...

なぜNASAが国家の秘密を月に送っているのか
「NASAは、スタートアップ企業のLonestarとマン島と協力し、アルテミス計画の一環として、来年2月にデータペイロードを月に送り、月ベースのバックアップストレージを評価する予定です」

「Amazon SageMakerを使用して、Llama 2モデルのスループット性能を向上させる」
機械学習(ML)の普及において、私たちは興奮する転換点にいます私たちは、ほとんどの顧客の体験やアプリケーションが生成型AIによって再発明されると信じています生成型AIは、会話、物語、画像、ビデオ、音楽などの新しいコンテンツやアイデアを作成することができます生成型AIは、非常に大きなモデルによって駆動されています(...)

「包括的な革新:Amazon SageMakerでのHack.The.Bias」
この投稿は、ETH ZürichのAWS学生ハッカソンチームのメンバーであるDaniele Chiappalupiと共同で執筆されましたAmazon SageMaker JumpStartを使用して、誰でも簡単に機械学習(ML)を始めることができますこの投稿では、大学のハッカソンチームがSageMaker JumpStartを使用して、ユーザーが識別して削除するのを支援するアプリケーションを迅速に構築した方法を紹介します

ChatGPTと仮想アシスタントの未来 💻
「それほど遠くない過去に、仮想アシスタントを持つというアイデアは純粋なSFの題材でしたしかし、今日ではChatGPTのようなAIパワーを持つ助手が私たちのドアをノックしています...」

「10 個の最高の AI スケジューリングアシスタント(2023 年 9 月)」
デジタル時代の急速な進化の中で、時間が貴重な資産となる中、人工知能(AI)によるスケジュール管理アシスタントの流入は、時間管理を革新していますこれらのAIパワードツールは、スケジューリングに関連するロジスティックの手間を取り除き、プロフェッショナルが自らのコアタスクに集中できるようにシームレスに統合されています[…]
PySparkでのランダムフォレスト回帰の実装方法
PySparkは、Apache Sparkの上に構築された強力なデータ処理エンジンであり、大規模なデータ処理に適していますスケーラビリティ、速度、多機能性、他のツールとの統合、使いやすさを提供します...
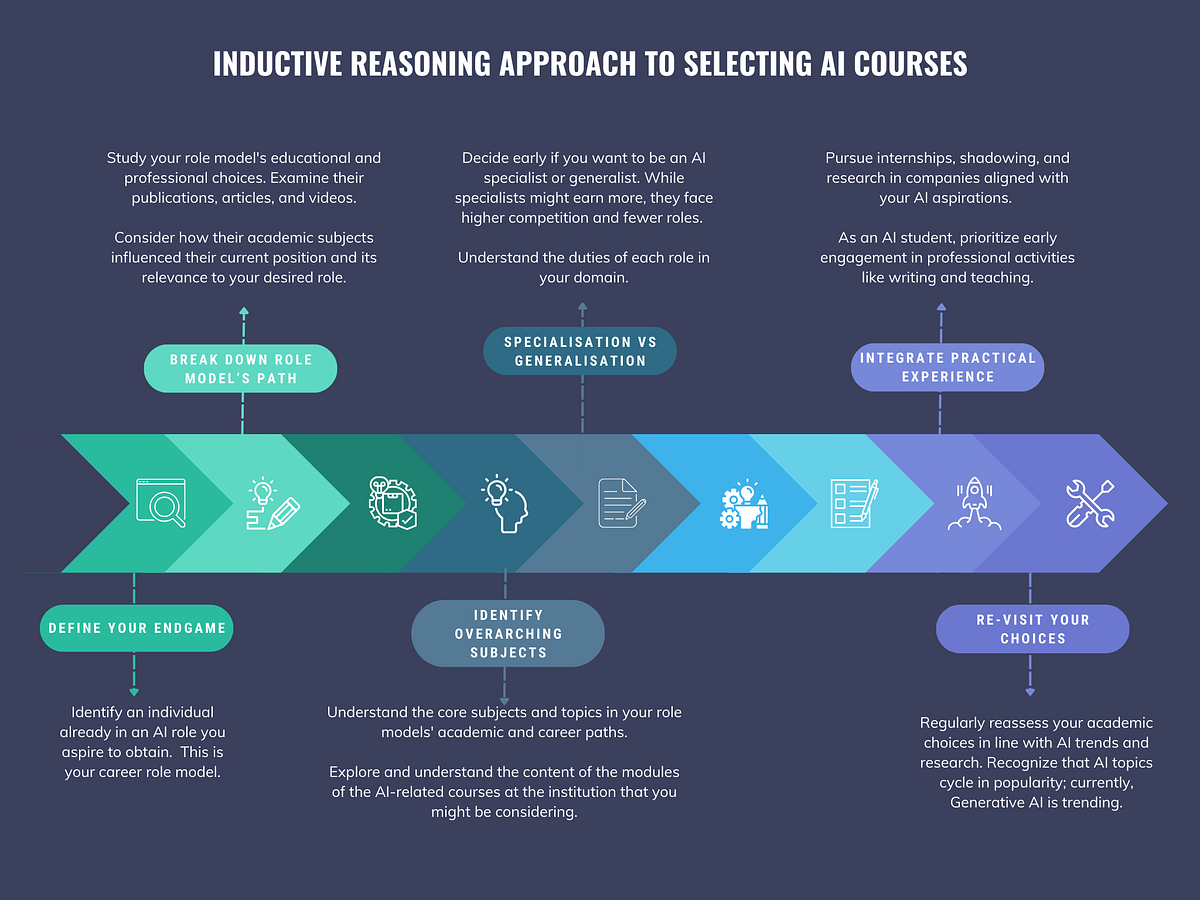
大学でAIプログラム/コースを選ぶ方法
「大学で人工知能(AI)を学ぶための適切な学位コースやプログラムを選ぶことが簡単であるならば、この記事はここで終わるでしょうしかし、そうではありませんつまり、さらに続きがあるということです...」

「AIセキュリティへの6つのステップ」
ChatGPTの登場に伴い、すべての企業がAI戦略を考えようとしており、その作業にはすぐにセキュリティの問題が浮かび上がります。新しい技術のセキュリティを確保することに圧倒されるかもしれませんが、現在のポリシーとプラクティスは優れた出発点を提供しています。 実際には、エンタープライズとクラウドセキュリティの既存の基盤を拡張することが前進の道です。以下の6つのステップで要約できる旅です: 脅威の分析を拡大する 対応メカニズムを広げる データ供給チェーンを保護する AIを使用して取り組みを拡大する 透明性を持たせる 持続的な改善を作り出す AIセキュリティは、企業が既に頼りにしている保護策を基に構築されます。 展望を広げる 最初のステップは、新しい状況に慣れることです。 セキュリティは、AIの開発ライフサイクルもカバーする必要があります。これには、トレーニングデータ、モデル、それらを使用する人々とプロセスなど、新しい攻撃対象が含まれます。 既知の脅威のタイプから推測し、新たに現れる脅威を特定するために展開します。たとえば、攻撃者は、クラウドサービスでモデルのトレーニング中にデータにアクセスしてAIモデルの振る舞いを変更しようとするかもしれません。 過去に脆弱性を調査したセキュリティ研究者やレッドチームは、再び素晴らしいリソースとなります。彼らはAIシステムとデータへのアクセスが必要であり、新たな脅威を特定し対処するだけでなく、データサイエンススタッフとの堅固な協力関係の構築にも役立ちます。 防御を広げる 脅威の全体像が明確になったら、それに対抗する方法を定義します。 AIモデルのパフォーマンスを密接にモニタリングします。それはドリフトする可能性があり、新たな攻撃対象を開く可能性があることを前提として、従来のセキュリティ防御が侵害されることも前提としています。 また、既に存在するPSIRT(製品セキュリティインシデント対応チーム)のプラクティスを基に構築します。 たとえば、NVIDIAはAIポートフォリオを包括する製品セキュリティポリシーを公開しました。Open Worldwide Application Security Projectなどのいくつかの組織は、従来のITの脅威を特定するために使用される共通脆弱性列挙法など、主要なセキュリティ要素のAI向け実装をリリースしています。 ネットワークの制御とデータプレーンを分離する…

このAI研究では、LayoutNUWAというAIモデルを提案していますこのモデルは、レイアウト生成をコード生成のタスクとして扱い、セマンティック情報を向上させ、大規模言語モデル(LLM)の隠れたレイアウトの専門知識を活用します
LLMの成長に伴い、LLMのあらゆる側面について徹底的な研究が行われてきました。そのため、グラフィックレイアウトについても研究が行われています。グラフィックレイアウトとは、デザイン要素がどのように配置され、配置されることでユーザーが情報を相互作用し、認識するかに大きな影響を与えます。新たな研究領域としてレイアウト生成があります。これは、開発オブジェクトの簡略化を図るためにさまざまな現実的なレイアウトを提供することを目指しています。 現在のレイアウト作成の方法は、主に数値最適化を行い、レイアウトの数量的側面に焦点を当てており、各レイアウトコンポーネント間の接続などのレイアウトの意味情報を無視しています。しかし、レイアウトの数値要素(位置やサイズなど)を収集することに重点を置くため、各数値の属性などの意味情報を省いてしまうため、この方法ではレイアウトを数値のタプルとして表現する必要があるかもしれません。 レイアウトはその部分間の論理リンクを特徴とするため、プログラミング言語はレイアウトに適したオプションです。コード言語を使用して各レイアウトを説明する整理されたシーケンスを開発することができます。これらのプログラミング言語は、論理的な概念と情報や意味を組み合わせることで、現行のアプローチとより徹底的な表現の需要とのギャップを埋めることができます。 その結果、研究者たちはLayoutNUWAを開発しました。この最初のモデルは、レイアウトの開発をコード生成の問題としてアプローチし、大規模言語モデル(LLM)の隠れたレイアウトの専門知識を活用し、意味情報を向上させることを目指しています。 コードインストラクトチューニング(CIT)は、3つの相互に連結したコンポーネントで構成されています。コード初期化(CI)モジュールは、数値的な状況を定量化し、それをHTMLコードに変換します。このHTMLコードには、レイアウトの可読性と統一性を向上させるために特定の位置に配置されたマスクが含まれています。次に、HTMLコードのマスクされた領域を埋めるために、コード補完(CC)モジュールは、大規模言語モデル(LLM)のフォーマットに関するノウハウを使用します。生成されたレイアウトの精度と一貫性を向上させるために、これにはLLMが使用されます。最後に、コードレンダリング(CR)モジュールはコードを最終的なレイアウト出力にレンダリングします。生成されたレイアウトの精度と一貫性を向上させるために、これにはLLMが使用されます。 Magazine、PubLayNet、RICOの3つの頻繁に使用される公開データセットを使用してモデルのパフォーマンスを評価しました。RICOデータセットは、約66,000個のUIレイアウトを含み、25の要素種類に分けられており、モバイルアプリケーションのユーザーインターフェースデザインに焦点を当てています。一方、PubLayNetは360,000以上のレイアウトを含む大規模なライブラリで、数多くのドキュメントに分類され、5つの要素グループに分けられています。マガジンデータセットは雑誌のレイアウト研究のための低リソースリソースであり、6つの主要な要素クラスに分けられた4,000以上の注釈付きレイアウトを含んでいます。これらの3つのデータセットは、LayoutDMフレームワークを使用して一貫性を保つために前処理され、調整されました。これにより、元の検証データセットはテストセットとして指定され、25以上のコンポーネントを持つレイアウトはフィルタリングされ、洗練されたデータセットはトレーニングセットと新しい検証セットに分割され、データセットの95%が前者に、5%が後者に割り当てられました。 彼らはコードと数値表現を使用してモデルの結果を徹底的に評価するために実験を行いました。数値の出力形式に特化したコードインフィリングタスクを開発しました。このタスクでは、完全なコードシーケンスを予測するのではなく、大規模言語モデル(LLM)に対して数列内の隠れた値のみを予測するように求めました。その結果、数値形式で生成された場合、モデルのパフォーマンスが著しく低下し、モデル開発の試行の失敗率が上昇することがわかりました。例えば、この方法では場合によっては繰り返しの結果が生じました。この効率の低下は、条件付きレイアウト生成タスクが一貫したレイアウトの作成を目指していることに起因するとされています。 研究者はまた、マスクされたビットの予測にのみ注目すると、別々で論理的でない数値が生成される可能性があると述べています。さらに、これらの傾向は、より多くの非表示値を持つレイアウトを示す場合に特にモデルがデータを生成できない可能性を増加させるかもしれません。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.