Learn more about Search Results arXiv - Page 18

- You may be interested
- 「Pythonをマスターするための無料の5冊...
- 線形代数4:行列方程式
- 「Med-Flamingoに会ってください:医療分...
- Dynalang エージェント学習における言語理...
- チューリングのミル:AIスーパーコンピュ...
- データサイエンスチームの協力のための5つ...
- 「このタイトルを無視してHackAPrompt:LL...
- 「Excelにおける金融関数の包括的なガイド」
- 「データサイエンスの役割に関するGoogle...
- 人間の理解と機械学習のギャップを埋める...
- LangChain チートシート — すべての秘密を...
- PDFとのチャット | PythonとOpenAIによる...
- 「包括的な時系列探索的分析」
- ChatGPTから独自のプライベートなフランス...
- デジタル変革によって打撃を受ける可能性...

ソースフリーのドメイン適応における壁の破壊:バイオアコースティクスとビジョン領域へのNOTELAの影響
ディープラーニングは、さまざまなアプリケーション領域で重要な進展を遂げています。その一因は、ますます大規模なデータセットとモデルが利用可能になったことです。しかし、この傾向の一方で、最新のモデルをトレーニングすることがますます高価になり、環境への懸念や一部の実践者にとってのアクセス性の問題を引き起こしています。さらに、事前トレーニングされたモデルを直接再利用すると、デプロイメント時の分布の変化に直面した際に性能の低下が生じることがあります。研究者は、ソースフリードメインアダプテーション(SFDA)を探求してこれらの課題に対処しています。この技術は、元のトレーニングデータにアクセスせずに事前トレーニングされたモデルを新しいターゲットドメインに適応させるものです。本記事では、SFDAの問題に焦点を当て、音声ドメイン、特にバイオアコースティクスにおける分布の変化に対処するために設計された新しい手法であるNOTELAを紹介します。 バイオアコースティクスデータセット(XC)は、鳥の種の分類に広く使用されており、次のようなものが含まれています: 主観的な録音。 自然な状況で個々の鳥を対象とする。 全方向性マイクを介して得られたサウンドスケープの録音。 これには、サウンドスケープの録音には信号対雑音比が低く、複数の鳥が同時に発声する、環境ノイズのような重要な妨害要素があるという固有の課題があります。さらに、サウンドスケープの録音は異なる地理的位置から収集されるため、XCには特定の地域にのみ一部の種が出現するという極端なラベルシフトが生じます。さらに、ソースとターゲットのドメインの両方がクラスの不均衡を示しており、1つの録音内に複数の鳥の種が存在するため、問題はマルチラベル分類タスクとなります。 この研究では、Googleの研究者は、エントロピー最小化、疑似ラベリング、ノイズ除去教師生徒、マニフォールド正則化など、バイオアコースティクスデータセットで既存のSFDA手法をいくつか評価しました。評価結果は、これらの手法が伝統的なビジョンタスクで成功を収めた一方で、バイオアコースティクスでは性能が大きく異なることを示しています。一部の場合では、適応を行わない場合よりも悪い結果を示します。この結果は、バイオアコースティクスドメインの固有の課題を処理するための特殊な手法の必要性を示しています。 この制限に対処するために、研究者はNOisy student TEacher with Laplacian Adjustment(NOTELA)と呼ばれる新しい革新的な手法を提案しています。この新しい手法は、ノイズ除去教師生徒(DTS)手法とマニフォールド正則化(MR)手法の原則を組み合わせています。NOTELAは、学生モデルにノイズを加えるメカニズム(DTSから着想を得たもの)を導入し、特徴空間でのクラスタ前提を強制する(MRに似たもの)ことで、適応プロセスを安定化させ、モデルの汎化性能を向上させます。この手法は、モデルの特徴空間を追加の真実の情報源として活用し、バイオアコースティクスデータセットの難問に成功し、最先端の性能を達成します。 バイオアコースティクスのドメインでは、NOTELAはソースモデルよりも大幅に改善され、他のSFDA手法を超える性能を示しました。多ラベル分類の標準的な指標である平均適合率(mAP)やクラスごとの平均適合率(cmAP)の値も印象的です。S. Nevada(mAP 66.0、cmAP 40.0)、Powdermill(mAP 62.0、cmAP 34.7)、SSW(mAP 67.1、cmAP 42.7)など、さまざまなテストターゲットドメインでの顕著なパフォーマンスは、バイオアコースティクスデータセットの課題に対処する効果を示しています。 ビジョンタスクの文脈では、NOTELAは一貫して強力なパフォーマンスを示し、他のSFDAベースラインを上回りました。CIFAR-10(90.5%)やS. Nevada(73.5%)など、さまざまなビジョンデータセットで注目すべきトップ1の精度結果を収めました。ImageNet-Sketch(29.1%)やVisDA-C(43.9%)ではわずかに性能が低いものの、NOTELAのバイオアコースティクスやビジョンドメインでのSFDA問題への効果と安定性は明らかです。 https://arxiv.org/abs/2302.06658…

「深層学習を用いた深層オブジェクト:ZoeDepthはマルチドメインの深度推定のためのAIモデルです」
画像に子供が大人よりも高くて大きく見える錯覚に出くわしたことはありますか?エームスの部屋の錯視は、台形の形状をした部屋で、部屋の一角が他の角よりも視聴者に近いという有名なものです。特定のポイントから見ると、部屋の中のオブジェクトは正常に見えますが、別の位置に移動すると、サイズと形状が変わり、自分の近くに何があるのか、何がないのかがわかりにくくなります。 ただし、これは私たち人間にとっての問題です。通常、私たちはシーンを見るとき、錯覚のトリックがなければ、オブジェクトの奥行きをかなり正確に推定します。一方、コンピュータは視覚処理の基本的な問題である奥行き推定においてはあまり成功していません。 奥行き推定は、カメラとシーン内のオブジェクトとの距離を決定するプロセスです。奥行き推定アルゴリズムは、画像または画像の連続を入力として受け取り、シーンの対応する奥行きマップまたは3D表現を出力します。これは、ロボット工学、自律型車両、仮想現実、拡張現実など、さまざまなアプリケーションでシーンの奥行きを理解するために重要なタスクです。たとえば、安全な自動運転車を持ちたい場合、前方の車までの距離を理解して運転速度を調整することが重要です。 奥行き推定アルゴリズムには、メトリック奥行き推定(MDE)と、シーン内のオブジェクトの相対距離を推定する相対奥行き推定(RDE)の2つの分野があります。 MDEモデルは、マッピング、計画、ナビゲーション、オブジェクト認識、3D再構築、画像編集に役立ちます。ただし、MDEモデルのパフォーマンスは、特に画像の奥行きスケールに大きな差がある場合(たとえば、室内と屋外の画像など)に、複数のデータセットをまたがって単一のモデルをトレーニングする場合に低下することがあります。その結果、現在のMDEモデルは、特定のデータセットにオーバーフィットし、他のデータセットに対してうまく汎化しません。 一方、RDEモデルは、視差を監督手段として使用します。RDEの深さ予測は、画像フレーム間で互いに一貫しているだけで、スケールファクターは不明です。これにより、RDEメソッドは、3D映画を含むさまざまなシーンとデータセットでトレーニングすることができ、モデルの汎用性を向上させるのに役立ちます。ただし、トレードオフとして、RDEで予測される深さにはメトリックな意味がないため、その応用範囲が制限されます。 これらの2つのアプローチを組み合わせたらどうなるでしょうか?私たちは、さまざまなドメインにうまく汎化できる同時に正確なメトリックスケールを保持する奥行き推定モデルを持つことができます。これがZoeDepthが達成したことです。 ZoeDepthの概要。出典:https://arxiv.org/pdf/2302.12288.pdf ZoeDepthは、MDEとRDEのアプローチを組み合わせた2ステージのフレームワークです。第1ステージは、相対的な深さを推定するためにトレーニングされたエンコーダーデコーダー構造で構成されています。このモデルはさまざまなデータセットでトレーニングされており、汎化性能が向上しています。第2ステージでは、メトリックな深さを推定するためのコンポーネントが追加されます。 このアプローチで使用されるメトリックヘッドのデザインは、単一の深さ値ではなく、各ピクセルに対して一連の深さ値を推定するメトリックビンズモジュールと呼ばれる手法に基づいています。これにより、モデルは各ピクセルに対して可能な深さ値の範囲を捉えることができ、その精度と頑健性を向上させることができます。これにより、シーン内のオブジェクト間の物理的な距離を考慮した正確な深度測定が可能になります。これらのヘッドはメトリックな深度データセットでトレーニングされ、第1ステージと比べて軽量です。 推論においては、分類モデルがエンコーダーの特徴を使用して各画像に適切なヘッドを選択します。これにより、モデルは特定のドメインやシーンのタイプに対して深度推定に特化することができ、相対的な深度の事前トレーニングからも恩恵を受けることができます。最終的に、複数の構成で使用できる柔軟なモデルが得られます。
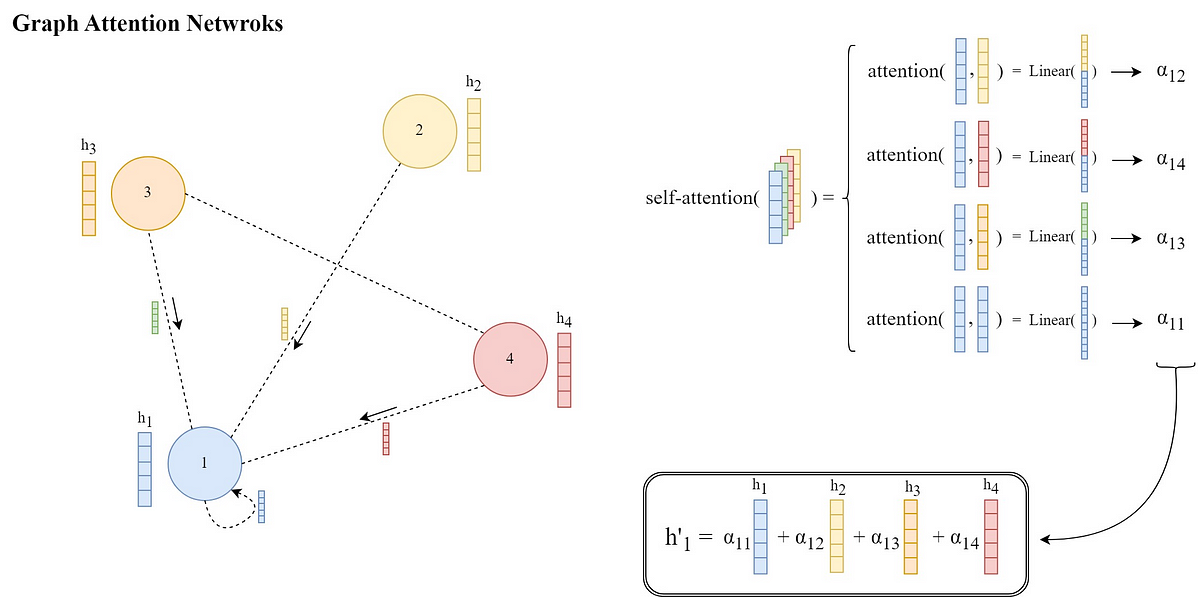
「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
グラフニューラルネットワーク(GNN)は、グラフ構造のデータに作用する強力なニューラルネットワークの一種ですノードのローカルな情報を集約することによって、ノードの表現(埋め込み)を学習します...

「AIの画像をどのように保存すべきか?Googleの研究者がスコアベースの生成モデルを使用した画像圧縮方法を提案」
1年前、AIによるリアルな画像生成は夢でした。ほとんどの出力が3つの目や2つの鼻などを持つものであるにもかかわらず、実際の顔に似た生成された顔を見ることに感動しました。しかし、拡散モデルのリリースにより、状況は非常に急速に変化しました。現在では、AIによって生成された画像と本物の画像を区別することが困難になりました。 高品質な画像を生成する能力は方程式の一部です。それらを適切に利用するためには、効率的に圧縮することが、コンテンツ生成、データ保存、伝送、および帯域幅の最適化などのタスクにおいて重要な役割を果たします。しかし、画像の圧縮は、変換符号化や量子化技術などの伝統的な手法に主に依存しており、生成モデルの探索は限定的でした。 画像生成の成功にもかかわらず、拡散モデルやスコアベースの生成モデルは、画像圧縮の主要な手法としてまだ台頭していません。彼らは、高解像度の画像に関しては、HiFiCなどのGANベースの手法に劣るか同等の結果を示すことが多いです。また、テキストから画像へのモデルを画像圧縮に再利用しようとする試みも、元の入力から逸脱した再構成や望ましくないアーティファクトを含む結果に終わっています。 画像生成のタスクにおけるスコアベースの生成モデルの性能と、画像圧縮の特定のタスクにおけるGANを上回ることができないというギャップは、興味深い疑問を提起し、さらなる調査を促しています。高品質な画像を生成できるモデルが、画像圧縮の特定のタスクでGANを上回ることができなかったことは驚きです。この相違点は、スコアベースの生成モデルを圧縮タスクに適用する際に、固有の課題と考慮事項が存在し、その全ポテンシャルを引き出すために専門のアプローチが必要であることを示唆しています。 したがって、スコアベースの生成モデルを画像圧縮に使用する可能性があることがわかりました。問題は、どのようにしてそれを実現するかということです。それでは、その答えに入ってみましょう。 Googleの研究者は、標準のオートエンコーダを使用し、平均二乗誤差(MSE)に最適化された拡散プロセスと組み合わせて、オートエンコーダによって破棄された微細なディテールを復元し追加する方法を提案しました。画像のエンコードのビットレートは、拡散プロセスでは追加のビットは必要としないため、オートエンコーダによってのみ決定されます。画像圧縮のために拡散モデルを特に微調整することで、画像の品質に関していくつかの最近の生成アプローチを凌駕することが示されています。 提案された方法は、最先端のアプローチと比較して、詳細をより良く保存することができます。出典:https://arxiv.org/pdf/2305.18231.pdf この方法は、拡散モデルと直接関連している2つのアプローチを探求しています。拡散モデルは、サンプリングステップの数が多いほど優れた性能を発揮しますが、サンプリングステップが少ない場合には、修正フローの方が優れたパフォーマンスを発揮します。 この2ステップのアプローチは、まずMSEに最適化されたオートエンコーダを使用して入力画像をエンコードし、その後、拡散プロセスまたは修正フローを適用して再構成のリアリズムを高めることで構成されています。拡散モデルは、テキストから画像へのモデルとは逆の方向にシフトされたノイズスケジュールを使用し、グローバルな構造よりも詳細を優先します。一方、修正フローモデルは、オートエンコーダから提供されるペアリングを利用して、オートエンコーダの出力を非圧縮画像に直接マッピングします。 提案されたHFDモデルの概要。出典:https://arxiv.org/pdf/2305.18231.pdf さらに、この研究では、この領域での将来の研究に役立つ具体的な詳細が明らかにされました。たとえば、ノイズスケジュールや画像生成時に注入されるノイズの量が結果に大きな影響を与えることが示されています。興味深いことに、高解像度の画像をトレーニングする際には、テキストから画像へのモデルはノイズレベルの増加によって利益を得る一方で、拡散プロセス全体のノイズを減らすことが圧縮に有利であることがわかっています。この調整により、モデルは細部により注力することができ、粗い詳細は既にオートエンコーダの再構築によって十分に捉えられています。
CleanLabを使用してデータセットのラベルエラーを自動的に検出する
数週間前、私は個人のプロジェクトを開発するためのデータセットを通常の検索している最中に、ブラジル下院オープンデータポータルに出会いましたこのポータルには多くのデータが含まれています

「現代の自然言語処理:詳細な概要パート3:BERT」
「トランスフォーマーとGPTについての以前の記事では、NLPのタイムラインと開発の体系的な分析を行ってきましたシーケンス対シーケンスモデリングからドメインがどのように進化したかを見てきました...」

「夢を先に見て、後で学ぶ:DECKARDは強化学習(RL)エージェントのトレーニングにLLMsを使用するAIアプローチです」
強化学習(RL)は、環境との相互作用によって複雑なタスクを実行することを学ぶことができる自律エージェントの訓練手法です。RLにより、エージェントは異なる状況で最適な行動を学び、報酬システムを使用して環境に適応することができます。 RLにおける主な課題は、多くの現実世界の問題の広範な状態空間を効率的に探索する方法です。この課題は、RLにおいてエージェントが探索を通じて環境との相互作用によって学習するために生じます。マインクラフトをプレイしようとするエージェントを考えてみてください。以前に聞いたことがある場合、マインクラフトのクラフトツリーがどれだけ複雑であるかを知っているはずです。数百のクラフト可能なオブジェクトがあり、一つを作るためには別のものを作る必要があるかもしれません。つまり、非常に複雑な環境です。 環境が多数の可能な状態と行動を持つ場合、ランダムな探索だけでは最適な方策を見つけることが困難になることがあります。エージェントは、現在の最適な方策を活用することと、状態空間の新しい部分を探索してより良い方策を見つけることとのバランスを取る必要があります。探索と活用をバランス良く行う効果的な探索方法を見つけることは、RLの研究の活発な分野です。 実用的な意思決定システムは、タスクに関する事前知識を効果的に利用する必要があることが知られています。タスク自体に関する事前情報を持つことにより、エージェントは方策を適応させることができ、サブオプティマルな方策に陥るのを回避することができます。しかし、現在のほとんどの強化学習手法は、事前のトレーニングや外部の知識なしで訓練されています。 では、なぜそうなのでしょうか?近年、大規模な言語モデル(LLM)を使用してRLエージェントを探索のために支援することに関心が高まっています。このアプローチは有望な結果を示していますが、環境におけるLLMの知識の具体化やLLMの出力の正確さといった多くの課題がまだ残されています。 では、RLエージェントの支援にLLMを使用するのを諦めるべきでしょうか?もしそうでない場合、どのようにしてこれらの問題を解決し、再びLLMを使用してRLエージェントをガイドすることができるのでしょうか?その答えは名前があり、それはDECKARDです。 DECKARDの概要。出典: https://arxiv.org/abs/2301.12050 DECKARDは、マインクラフト向けに訓練されています。マインクラフトで特定のアイテムを作成することは、ゲームの専門知識がなければ難しい課題となり得ます。これは、ゲーム内の目標を達成することが、密な報酬や専門家のデモンストレーションを使用することで容易になることを示した研究によって実証されています。その結果、マインクラフトにおけるアイテムの作成は、AIの分野において持続的な課題となっています。 DECKARDは、大規模な言語モデル(LLM)に対してフューショットプロンプティング技術を使用してサブゴールのための抽象的なワールドモデル(AWM)を生成します。LLMを使用して、タスクとその解決手順について仮説を立てます。その後、実際の環境でモジュラーポリシーを学習し、夢見る間に生成されたサブゴールのポリシーを生成します。これにより、DECKARDは仮説を検証することができます。AWMは起床フェーズで修正され、発見されたノードは将来再利用するために検証済みとマークされます。 実験によれば、LLMのガイダンスはDECKARDの探索において重要であり、LLMのガイダンスなしのバージョンのエージェントは、オープンエンドの探索中にアイテムを作るのに2倍以上の時間がかかります。特定のタスクを探索する際、DECKARDは比較可能なエージェントと比べて数桁以上のサンプル効率を改善し、LLMをRLに堅牢に適用する可能性を示しています。

「拡散を支配するための1つの拡散:マルチモーダル画像合成のための事前学習済み拡散モデルの調節」
画像生成AIモデルは、ここ数ヶ月でこの領域を席巻しています。おそらく、midjourney、DALL-E、ControlNet、またはStable dDiffusionなどについて聞いたことがあるかもしれません。これらのモデルは、与えられたプロンプトに基づいて写真のようなリアルな画像を生成することができます。与えられたプロンプトがどれほど奇妙であっても、ピカチュウが火星を走り回るのを見たいですか?これらのモデルのいずれかに依頼してみてください。きっと手に入るでしょう。 既存の拡散モデルは、大規模なトレーニングデータに依存しています。大規模と言っても本当に大きいです。たとえば、Stable Diffusion自体は、25億以上の画像キャプションのペアでトレーニングされました。ですので、自宅で独自の拡散モデルをトレーニングする予定がある場合は、計算リソースに関して非常に高額な費用がかかるため、再考することをお勧めします。 一方、既存のモデルは通常、非条件付きまたはテキストプロンプトのような抽象的な形式に基づいています。これは、画像を生成する際に1つの要素のみを考慮に入れることを意味し、セグメンテーションマップなどの外部情報を渡すことはできません。これは、大規模なデータセットに依存していることと組み合わさると、大規模な生成モデルがトレーニングされていないドメインでは、その適用範囲が制限されることを意味します。 この制限を克服するためのアプローチの1つは、特定のドメインに対して事前にトレーニングされたモデルを微調整することです。しかし、これにはモデルのパラメータへのアクセスと、フルモデルの勾配を計算するための膨大な計算リソースが必要です。さらに、フルモデルを微調整すると、その適用範囲と拡張性が制限されるため、新しいフルサイズのモデルが新しいドメインやモダリティの組み合わせごとに必要となります。また、これらのモデルのサイズが大きいため、微調整されたデータの小さなサブセットにすぐにオーバーフィットする傾向があります。 また、選択したモダリティに基づいてモデルをゼロからトレーニングすることも可能です。しかし、これはトレーニングデータの入手可能性によって制限され、モデルをゼロからトレーニングするのは非常に高価です。一方、推論時に事前にトレーニングされたモデルを目的の出力に向かってガイドする試みもあります。これには事前にトレーニングされた分類器やCLIPネットワークからの勾配を使用しますが、このアプローチは推論中に多くの計算を追加するため、モデルのサンプリングを遅くします。 では、非常に高価なプロセスを必要とせずに、既存のモデルを利用して条件を適用することはできないでしょうか?拡散モードを変更する手間のかかる時間のかかるプロセスに入る必要はありませんか?それでも条件を付けることは可能でしょうか?その答えは「はい」であり、それを紹介します。 多モーダルコンディショニングモジュールのユースケース。出典: https://arxiv.org/pdf/2302.12764.pdf 提案されたアプローチ、多モーダルコンディショニングモジュール(MCM)は、既存の拡散ネットワークに統合できるモジュールです。これは、元の拡散ネットワークの予測を各サンプリングタイムステップで調整するためにトレーニングされた小規模の拡散のようなネットワークを使用します。これにより、生成された画像が提供された条件に従うようになります。 MCMは、元の拡散モデルを何らかの方法でトレーニングする必要はありません。トレーニングは、モジュレーションネットワークに対してのみ行われ、小規模でトレーニングコストがかからないです。このアプローチは計算的に効率的であり、大規模な拡散ネットワークの勾配を計算する必要がないため、拡散ネットワークをゼロからトレーニングするか既存の拡散ネットワークを微調整するよりも少ない計算リソースを必要とします。 さらに、MCMは、トレーニングデータセットが大規模でない場合でも、一般化能力があります。勾配の計算が必要ないため、推論プロセスを遅くすることはありません。唯一の計算オーバーヘッドは、小規模な拡散ネットワークの実行によるものです。 提案されたモジュレーションパイプラインの概要。出典: https://arxiv.org/pdf/2302.12764.pdf マルチモーダル調整モジュールの組み込みにより、セグメンテーションマップやスケッチなどの追加のモダリティによる条件付き画像生成に対して、より多くの制御が加わります。このアプローチの主な貢献は、マルチモーダル調整モジュールの導入です。これは、元のモデルのパラメータを変更せずに事前学習済みの拡散モデルを条件付き画像合成に適応させるための手法であり、ゼロからのトレーニングや大規模なモデルの微調整よりも安価でメモリ使用量も少なく、高品質かつ多様な結果を実現します。 論文とプロジェクトをチェックしてください。この研究に関しては、このプロジェクトの研究者に全てのクレジットがあります。また、最新のAI研究ニュース、素晴らしいAIプロジェクトなどを共有している26k+のML SubReddit、Discordチャンネル、メールニュースレターにもぜひ参加してください。 Tensorleapの説明可能性プラットフォームでディープラーニングの秘密を解き放つ この投稿は「One Diffusion to Rule Diffusion:…

「人工知能の炭素足跡」
AIの使用に起因する温室効果ガスの排出を削減する方法を探していますが、その使用は非常に増加する可能性があります

「3DモデリングはAIに基づいています」
人工知能は、3次元グラフィックスにおいて速度と品質の向上を実現することができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.