Learn more about Search Results Google Play - Page 18

- You may be interested
- 意味レイヤー:AIパワードデータエクスペ...
- 「ヘルスケア業界における生成型AIは、説...
- 「初心者からニンジャへ:なぜデータサイ...
- Amazon SageMakerのHugging Face LLM推論...
- より速いデータ検索のためのSQLクエリの最...
- トム・ハンクスがAI生成のディープフェイ...
- 「CHARMに会ってください:手術中に脳がん...
- AIモデルが高解像度のコンピュータビジョ...
- スタートアップの創業者が最適なインキュ...
- ワビとトロント大学の研究者が、オートラ...
- 深層強化学習の概要
- 「NLPモデルの正規化に関するクイックガイ...
- 「デジタル時代のユーザーセントリックデ...
- 「Pandasのastype()とto_datetime()の間の...
- LLama Indexを使用してRAGパイプラインを...

AIを活用した言語学習アプリの構築:2つのAIチャットからの学習
新しい言語を学び始めるときは、私は「会話ダイアログ」の本を買うのが好きです私はそのような本が非常に役立つと思っていますそれらは、言語がどのように動作するかを理解するのに役立ちます単に…

事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
はじめに 事前学習済みのViTモデルを使用した画像キャプショニングは、画像の詳細な説明を提供するために画像の下に表示されるテキストまたは書き込みのことを指します。つまり、画像をテキストの説明に翻訳するタスクであり、ビジョン(画像)と言語(テキスト)を接続することで行われます。この記事では、PyTorchバックエンドを使用して、画像のViTを主要な技術として使用して、トランスフォーマーを使用した画像キャプショニングの生成方法を、スクラッチから再トレーニングすることなくトレーニング済みモデルを使用して実現します。 出典: Springer 現在のソーシャルメディアプラットフォームや画像のオンライン利用の流行に対応するため、この技術を学ぶことは、説明、引用、視覚障害者の支援、さらには検索エンジン最適化といった多くの理由で役立ちます。これは、画像を含むプロジェクトにとって非常に便利な技術であります。 学習目標 画像キャプショニングのアイデア ViTを使用した画像キャプチャリング トレーニング済みモデルを使用した画像キャプショニングの実行 Pythonを使用したトランスフォーマーの利用 この記事で使用されたコード全体は、このGitHubリポジトリで見つけることができます。 この記事は、データサイエンスブログマラソンの一環として公開されました。 トランスフォーマーモデルとは何ですか? ViTについて説明する前に、トランスフォーマーについて理解しましょう。Google Brainによって2017年に導入されて以来、トランスフォーマーはNLPの能力において注目を集めています。トランスフォーマーは、入力データの各部分の重要性を異なる重み付けする自己注意を採用して区別されるディープラーニングモデルです。これは、主に自然言語処理(NLP)の分野で使用されています。 トランスフォーマーは、自然言語のようなシーケンシャルな入力データを処理しますが、トランスフォーマーは一度にすべての入力を処理します。注意機構の助けを借りて、入力シーケンスの任意の位置にはコンテキストがあります。この効率性により、より並列化が可能となり、トレーニング時間が短縮され、効率が向上します。 トランスフォーマーアーキテクチャ 次に、トランスフォーマーのアーキテクチャの構成を見てみましょう。トランスフォーマーアーキテクチャは、主にエンコーダー-デコーダー構造から構成されています。トランスフォーマーアーキテクチャのエンコーダー-デコーダー構造は、「Attention Is All You Need」という有名な論文で発表されました。 エンコーダーは、各レイヤーが入力を反復的に処理することを担当し、一方で、デコーダーレイヤーはエンコーダーの出力を受け取り、デコードされた出力を生成します。単純に言えば、エンコーダーは入力シーケンスをシーケンスにマッピングし、それをデコーダーに供給します。デコーダーは、出力シーケンスを生成します。 ビジョン・トランスフォーマーとは何ですか?…

AutoML – 機械学習モデルを構築するための No Code ソリューション
はじめに AutoMLは自動機械学習としても知られています。2018年、GoogleはクラウドAutoMLを発表し、大きな関心を集め、機械学習と人工知能の分野で最も重要なツールの1つとなりました。この記事では、「Google Cloud AutoML」を使った機械学習モデルを構築するためのノーコードソリューションである「AutoML」について学びます。 AutoMLは、Google Cloud Platform上のVertex AIの一部です。Vertex AIは、クラウド上で機械学習パイプラインを構築および作成するためのエンドツーエンドソリューションです。ただし、Vertex AIの詳細については、別の記事で説明します。AutoMLは、主に転移学習とニューラルサーチアーキテクチャに依存しています。データを提供するだけで、AutoMLはユースケースに最適なカスタムモデルを構築します。 この記事では、Pythonコードを使ったGoogle Cloud Platform上でのAutoMLの利点、使用方法、実践的な実装について説明します。 学習目標 コードを使ったAutoMLの使用方法を読者に知らせること AutoMLの利点を理解すること クライアントライブラリを使用してMLパイプラインを作成する方法 この記事は、Data Science Blogathonの一部として公開されました。 問題の説明 機械学習モデルを構築することは時間がかかり、プログラミング言語の熟練度、数学と統計の良い知識、および機械学習アルゴリズムの理解などの専門知識が必要です。過去には、技術的なスキルを持つ人々だけがデータサイエンスで働き、モデルを構築できました。非技術的な人々にとっては、機械学習モデルを構築することは最も困難なタスクでした。ただし、モデルを構築した技術的な人々にとっても道のりは容易ではありませんでした。モデルを構築した後、メンテナンス、展開、および自動スケーリングには追加の努力、労働時間、およびわずかに異なるスキルセットが必要です。これらの課題を克服するために、グローバル検索大手のGoogleは、2014年にAutoMLを発表しましたが、後に一般に公開されました。 AutoMLの利点 AutoMLは手動の介入を減らし、少しの機械学習の専門知識が必要となります。…

ChatGPTの哲学コース:このAI研究は、対話エージェントのLLMの振る舞いを探究します
2023年はLLMの年です。ChatGPT、GPT-4、LLaMAなど、新しいLLMモデルが続々と注目を集めています。これらのモデルは自然言語処理の分野を革新し、さまざまなドメインで増え続ける利用に遭遇しています。 LLMには、対話を行うなど、人間のような対話者との魅力的な幻想を生み出す幅広い行動を示す驚くべき能力があります。ただし、LLMベースの対話エージェントは、いくつかの点で人間とは大きく異なることを認識することが重要です。 私たちの言語スキルは、世界との具体的なやり取りを通じて発達します。私たちは個人として、社会化や言語使用者のコミュニティでの浸透を通じて認知能力や言語能力を獲得します。このプロセスは赤ちゃんの場合はより早く、成長するにつれて学習プロセスは遅くなりますが、基礎は同じです。 一方、LLMは、与えられた文脈に基づいて次の単語またはトークンを予測することを主な目的とした、膨大な量の人間が生成したテキストで訓練された非具体的なニューラルネットワークです。彼らのトレーニングは、物理的な世界の直接的な経験ではなく、言語データから統計的なパターンを学ぶことに焦点を当てています。 これらの違いにもかかわらず、私たちはLLMを人間らしく模倣する傾向があります。これをチャットボット、アシスタントなどで行います。ただし、このアプローチには難しいジレンマがあります。LLMの行動をどのように説明し理解するか? LLMベースの対話エージェントを説明するために、「知っている」「理解している」「考えている」などの用語を人間と同様に使用することは自然です。ただし、あまりにも文字通りに受け取りすぎると、このような言葉は人工知能システムと人間の類似性を誇張し、その深い違いを隠すことになります。 では、どのようにしてこのジレンマに取り組むことができるでしょうか? AIモデルに対して「理解する」や「知っている」という用語をどのように説明すればよいでしょうか? それでは、Role Play論文に飛び込んでみましょう。 この論文では、効果的にLLMベースの対話エージェントについて考え、話すための代替的な概念的枠組みや比喩を採用することを提案しています。著者は2つの主要な比喩を提唱しています。1つ目の比喩は、対話エージェントを特定のキャラクターを演じるものとして描写するものです。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。 2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。 自己回帰サンプリングの例。出典:https://arxiv.org/pdf/2305.16367.pdf 最初の比喩は、対話エージェントを特定のキャラクターとして演じるものとして描写します。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。 2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。 対話エージェントの交代の例。出典:https://arxiv.org/pdf/2305.16367.pdf このフレームワークを採用することで、研究者やユーザーは、人間にこれらの概念を誤って帰属させることなく、欺瞞や自己認識などの対話エージェントの重要な側面を探求することができます。代わりに、焦点は、役割演技シナリオでの対話エージェントの行動や、彼らが模倣できる様々なキャラクターを理解することに移ります。 結論として、LLMに基づく対話エージェントは人間らしい会話をシミュレートする能力を持っていますが、実際の人間の言語使用者とは大きく異なります。役割プレイヤーやシミュレーションの組み合わせなどの代替的な隠喩を使用することにより、LLMベースの対話システムの複雑なダイナミクスをより理解し、その創造的な可能性を認識しながら、人間との根本的な相違を認識できます。
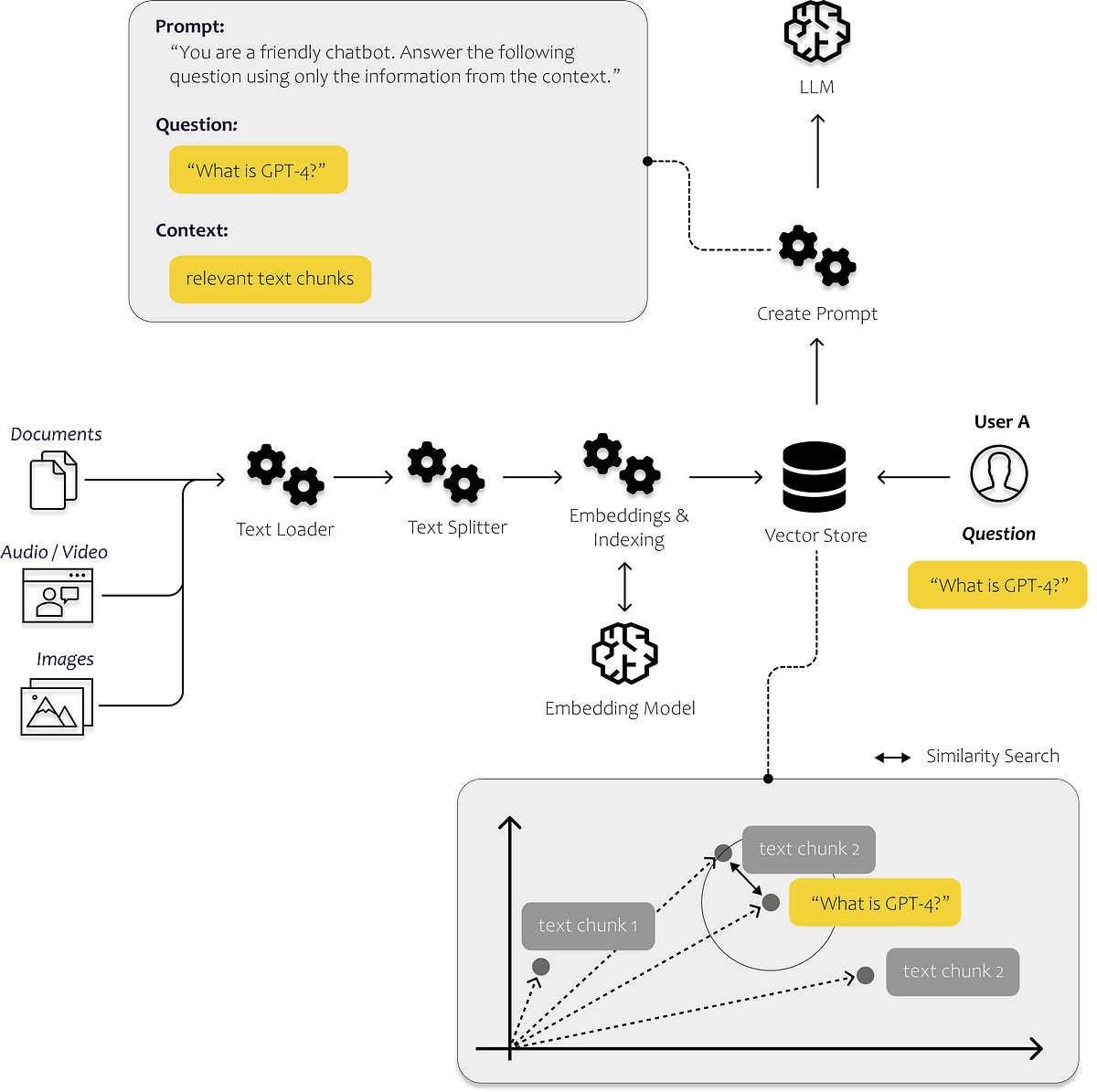
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

予測の作成:Pythonにおける線形回帰の初心者ガイド
最も人気のある機械学習アルゴリズムである線形回帰について、その数学的直感とPythonによる実装をすべて学びましょう
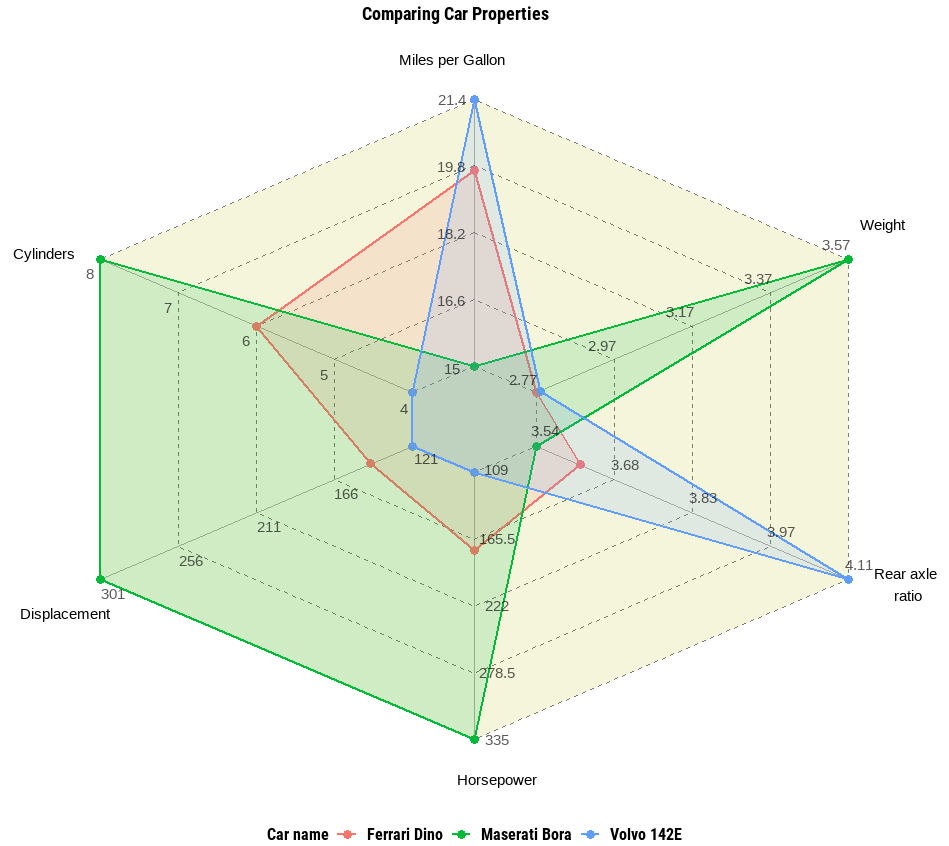
Rのggvancedパッケージを使用したスパイダーチャートと並列チャート
ggplot2パッケージの上に、スパイダーチャートや平行チャートなどの高度な多変数データ可視化を生成するためのパッケージ

AIによって設計されたカードゲーム、I/O FLIPをプレイしましょう
Google I/O 2023に間に合うように、生成AIで構築されたオンラインカードゲームI/O FLIPをお試しください

プレイヤーの離脱を予測する方法、ChatGPTの助けを借りる
ゲームの世界では、企業はプレイヤーを引きつけるだけでなく、特にゲーム内のマイクロトランザクションに頼る無料のゲームでは、できるだけ長く彼らを保持することを目指していますこれらの...

データサイエンティストのための10のJupyter Notebookのヒントとトリック
専門家のヒントやテクニックを使ってJupyter Notebookの全ポテンシャルを引き出し、時間を節約するショートカット、強力なマジック関数、高度な機能などを活用して生産性を向上させましょう
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.