Learn more about Search Results Clean Code - Page 18

- You may be interested
- 「AIオートメーションエージェンシーのリ...
- 「フリーノイズ」にご挨拶:複数のテキス...
- 「Meta AIは、社会的な具現化されたAIエー...
- 「Gensimを使ったWord2Vecのステップバイ...
- 🤗 ViTをVertex AIに展開する
- XGen-Image-1の内部:Salesforce Research...
- 焼け落ちた炎:スタートアップが生成AI、...
- 「Googleのジェミニは私たちが期待してい...
- 「データサイエンスのベストプラクティス...
- 「AIの誤情報:なぜそれが機能するのか、...
- ナノスケールで3Dプリントされた光学用グラス
- 「50 ミッドジャーニーノーリングのヒント...
- PythonでのZeroからAdvancedなPromptエン...
- セルンでの1エクサバイトのディスクストレ...
- 「長い尾が犬に振り回される:AIの個別化...

創造力を解き放つ:ジェネレーティブAIとAmazon SageMakerがビジネスを支援し、AWSを活用したマーケティングキャンペーンの広告クリエイティブを生み出します
広告代理店は、生成AIとテキストから画像を生成する基礎モデルを使用して、革新的な広告クリエイティブとコンテンツを作成することができますこの記事では、Amazon SageMakerを使用して既存のベース画像から新しい画像を生成する方法を示しますAmazon SageMakerは、スケーラブルなMLモデルを構築、トレーニング、展開するための完全な管理サービスですこのソリューションを使用することで、大規模なビジネスでも[…]

「Amazon SageMakerを使用したヘルスケアの要約オプションの探索」
現在の急速に進化する医療の現場では、医師は介護者のメモ、電子健康記録、画像報告書など、さまざまな情報源から大量の臨床データに直面しています患者のケアには不可欠なこの情報の富は、医療専門家にとっても圧倒的で時間のかかるものになります効率的に要約し、抽出することは、
テキストのポテンシャルを引き出す:プリエンベッドテキストクリーニング方法の詳細な調査
テキストクリーニングの方法のデモンストレーションには、Kaggleから取得した「メタモルフォーシス」という名前のテキストデータセットを使用します上記のコードセルが機能するためには、ローカルディレクトリパスを指定する必要があります...
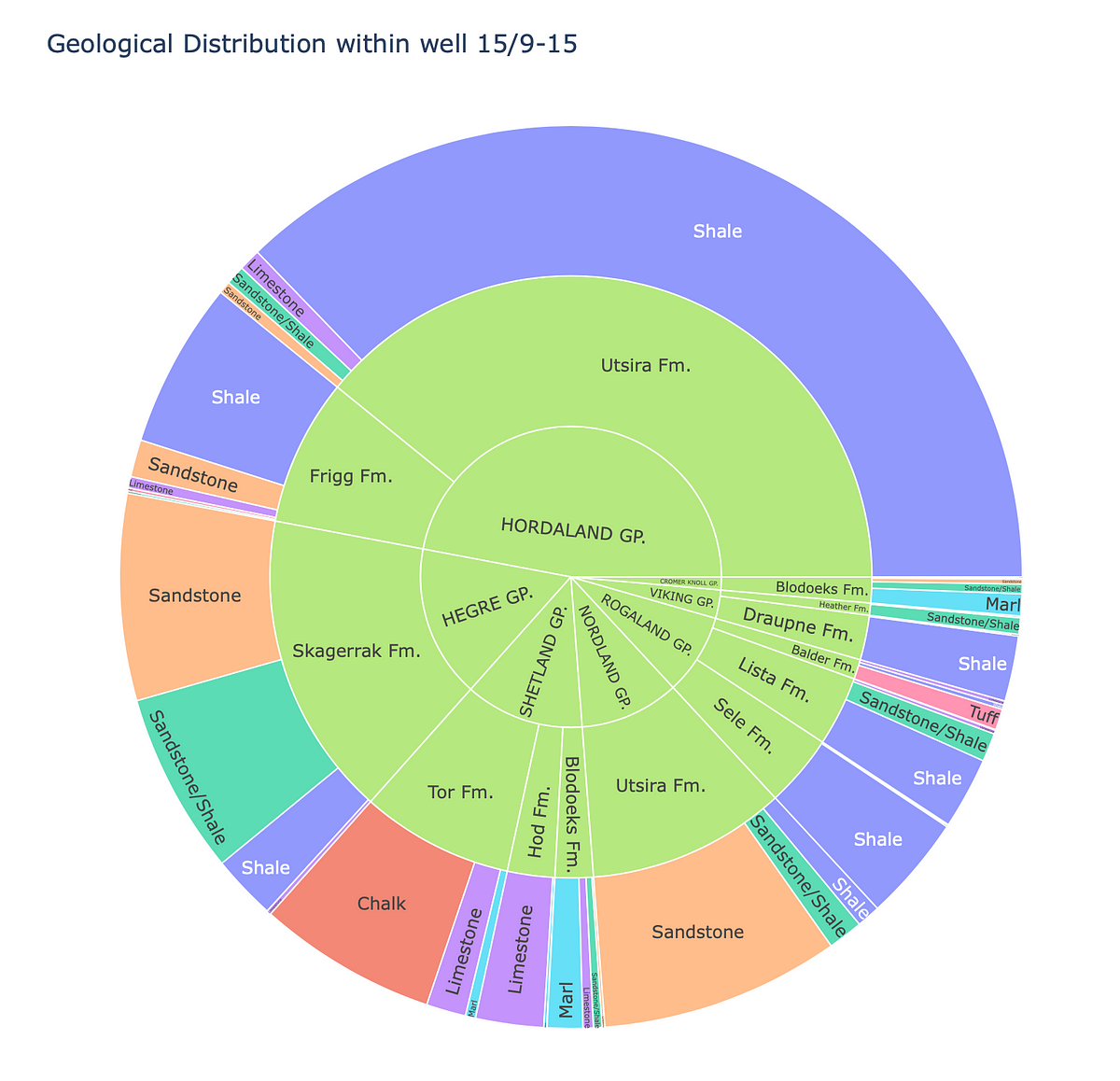
「Plotly Expressのサンバーストチャートを使用して地質データを探索する」
「データの可視化は、地球科学やデータサイエンスの領域において重要な役割を果たしますこれにより、地下構造や階層的な地質構造の理解を深めることができます...」

「Amazon SageMaker StudioでAmazon SageMaker JumpStartを使用して安定したDiffusion XLを利用する」
「今日、私たちはお知らせすることを喜んでいますStable Diffusion XL 1.0(SDXL 1.0)がAmazon SageMaker JumpStartを通じて顧客に利用可能ですSDXL 1.0は、Stability AIからの最新の画像生成モデルですSDXL 1.0の改良点には、さまざまなアスペクト比でのネイティブな1024ピクセルの画像生成が含まれていますプロフェッショナルな使用を目的としており、高解像度に合わせてキャリブレーションされています...」
「スパースなデータセットの扱い方に関する包括的ガイド」
はじめに ほとんどがnull値で構成されたデータセットを見たことがありますか?もしそうなら、あなたは一人ではありません。機械学習の中で最も頻繁に起こる問題の一つが、スパースなデータセットです。不適切な調査、欠損値のあるセンサーデータ、または欠損単語のあるテキストなど、いくつかの要因がこれらの存在を引き起こすことがあります。 スパースなデータセットで訓練された機械学習モデルは、比較的低い精度で結果を出力することがあります。これは、機械学習アルゴリズムがすべてのデータが利用可能であるという前提で動作するためです。欠損値がある場合、アルゴリズムは特徴間の相関関係を正しく判断できない可能性があります。欠損値のない大規模なデータセットで訓練すると、モデルの精度が向上します。したがって、スパースなデータセットにはランダムな値ではなく、おおよそ正しい値を埋めるために、特別な注意が必要です。 このガイドでは、スパースなデータセットの定義、理由、および取り扱いの技術について説明します。 学習目標 スパースなデータセットの理解とデータ分析におけるその影響を総合的に把握する。 欠損値を含むスパースなデータセットの処理に関するさまざまな技術、イミュータ、および高度な手法を探求する。 スパースなデータセット内に潜む隠れた洞察を明らかにするために、探索的データ分析(EDA)の重要性を発見する。 実際のデータセットとコード例を組み合わせたPythonを使用したスパースなデータセットの取り扱いに対する実用的なソリューションを実装する。 この記事はData Science Blogathonの一部として公開されました。 スパースなデータセットとは何ですか? 多くの欠損値を含むデータセットは、スパースなデータセットと言われます。欠損値の割合だけでデータセットをスパースと定義する具体的な閾値や固定の割合はありません。ただし、欠損値の割合が高い(通常50%以上)データセットは比較的スパースと見なされることがあります。このような大量の欠損値は、データ分析と機械学習において課題を引き起こす可能性があります。 例 オンライン小売業者からの消費者の購買データを含むデータセットがあると想像してみてください。データセットには2000行(消費者を表す)と10列(製品カテゴリ、購入金額、クライアントのデモグラフィックなどを表す)があるとします。 この例では、データセットのエントリの40%が欠損していると仮定しましょう。つまり、各クライアントごとに10の属性のうち約4つに欠損値があるということです。顧客がこれらの値を入力しなかった可能性があるか、データ収集に問題があったかもしれません。 明確な基準はありませんが、大量の欠損値(40%)があることで、このデータセットを非常にスパースと分類することができます。このような大量の欠損データは、分析とモデリングの信頼性と精度に影響を及ぼす可能性があります。 スパースなデータセットが課題となる理由 多くの欠損値が発生するため、スパースなデータセットはデータ分析とモデリングにいくつかの困難をもたらします。スパースなデータセットを取り扱う際に以下のような要素が課題となります: 洞察の不足:スパースなデータセットでは多くのデータが欠損しているため、モデリングに役立つ意味のある洞察が失われます。 バイアスのある結果:モデルがバイアスのある結果を出力すると、問題が生じます。スパースなデータセットでは、欠損データのためにモデルが特定の特徴カテゴリに依存する場合があります。 モデルの精度への大きな影響:スパースなデータセットは、機械学習モデルの精度に悪影響を与えることがあります。欠損値のある場合、モデルは誤ったパターンを学習する可能性があります。 スパースなデータセットの考慮事項…

Amazon SageMaker JumpStartを使用して、インターネット接続がないVPCモードで、生成AIの基礎モデルを利用します
最近の生成AIの進歩により、さまざまな業界で特定のビジネス問題を解決するために生成AIをどのように活用するかについての議論が盛んに行われています生成AIは、会話、物語、画像、動画、音楽などの新しいコンテンツやアイデアを作成することができるAIの一種ですこれらはすべて非常に大きなモデルに裏打ちされています

「Amazon EC2 Inf1&Inf2インスタンス上のFastAPIとPyTorchモデルを使用して、AWS Inferentiaの利用を最適化する」
「ディープラーニングモデルを大規模に展開する際には、パフォーマンスとコストのメリットを最大限に引き出すために、基盤となるハードウェアを効果的に活用することが重要です高スループットと低レイテンシーを必要とするプロダクションワークロードでは、Amazon Elastic Compute Cloud(EC2)インスタンス、モデルの提供スタック、展開アーキテクチャの選択が非常に重要です効率の悪いアーキテクチャは[…]」
1時間以内に初めてのディープラーニングアプリを作成しましょう
私はもう10年近くデータ分析をしています時折、データから洞察を得るために機械学習の技術を使用しており、クラシックな機械学習を使うことにも慣れています

「Gensimを使ったWord2Vecのステップバイステップガイド」
はじめに 数か月前、Office Peopleで働き始めた当初、私は言語モデル、特にWord2Vecに興味を持ちました。ネイティブのPythonユーザーとして、私は自然にGensimのWord2Vecの実装に集中し、論文やオンラインのチュートリアルを探しました。私は複数の情報源から直接コードの断片を適用し、複製しました。私はさらに深く探求し、自分の方法がどこで間違っているのかを理解しようとしました。Stackoverflowの会話、GensimのGoogleグループ、およびライブラリのドキュメントを読みました。 しかし、私は常にWord2Vecモデルを作成する上で最も重要な要素の一つが欠けていると考えていました。私の実験の中で、文をレンマ化することやフレーズ/バイグラムを探すことが結果とモデルのパフォーマンスに重要な影響を与えることを発見しました。前処理の影響はデータセットやアプリケーションによって異なりますが、この記事ではデータの準備手順を含め、素晴らしいspaCyライブラリを使って処理することにしました。 これらの問題のいくつかは私をイライラさせるので、自分自身の記事を書くことにしました。完璧だったり、Word2Vecを実装する最良の方法だったりすることは約束しませんが、他の多くの情報源よりも良いと思います。 学習目標 単語の埋め込みと意味的な関係の捉え方を理解する。 GensimやTensorFlowなどの人気のあるライブラリを使用してWord2Vecモデルを実装する。 Word2Vecの埋め込みを使用して単語の類似度を計測し、距離を算出する。 Word2Vecによって捉えられる単語の類推や意味的関係を探索する。 Word2Vecを感情分析や機械翻訳などのさまざまな自然言語処理のタスクに適用する。 特定のタスクやドメインに対してWord2Vecモデルを微調整するための技術を学ぶ。 サブワード情報や事前学習された埋め込みを使用して未知語を処理する。 Word2Vecの制約やトレードオフ、単語の意味の曖昧さや文レベルの意味について理解する。 サブワード埋め込みやWord2Vecのモデル最適化など、高度なトピックについて掘り下げる。 この記事はData Science Blogathonの一部として公開されました。 Word2Vecについての概要 Googleの研究チームは2013年9月から10月にかけて2つの論文でWord2Vecを紹介しました。研究者たちは論文とともにCの実装も公開しました。Gensimは最初の論文の後すぐにPythonの実装を完了しました。 Word2Vecの基本的な仮定は、文脈が似ている2つの単語は似た意味を持ち、モデルからは似たベクトル表現が得られるというものです。例えば、「犬」、「子犬」、「子犬」は似た文脈で頻繁に使用され、同様の周囲の単語(「良い」、「ふわふわ」、「かわいい」など)と共に使用されるため、Word2Vecによると似たベクトル表現を持ちます。 この仮定に基づいて、Word2Vecはデータセット内の単語間の関係を発見し、類似度を計算したり、それらの単語のベクトル表現をテキスト分類やクラスタリングなどの他のアプリケーションの入力として使用することができます。 Word2vecの実装 Word2Vecのアイデアは非常にシンプルです。単語の意味は、それが関連する単語と共に存在することによって推測できるという仮定をしています。これは「友だちを見せて、君が誰かを教えてあげよう」という言葉に似ています。以下はword2vecの実装例です。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.