Learn more about Search Results Claude - Page 18

- You may be interested
- モデルの精度にだまされない方法
- 「慢性腎臓病の予測:新しい視点」
- わかりやすいYOLOv8 Eigen-CAMを使ったYOL...
- 「独自のLLMモデルを所有することの重要性...
- 「研究者たちが量子エレクトロニクスの切...
- 「グローバル人工知能市場は31%の急成長...
- マイクロソフトの研究者がPromptTTS 2を発...
- 「Llama 2によるトピックモデリング」
- 「A.I.言語モデルの支援を受けて、Google...
- 「アマゾンベッドロックを使った商品説明...
- 「医療における説明可能なAIの実装の重要性」
- Active Directoryグループ固有のIAMロール...
- 「機械学習リスク管理のための文化的な能力」
- どのような要素が対話エージェントを有用...
- 「生成モデルを本番環境に展開する際の3つ...

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
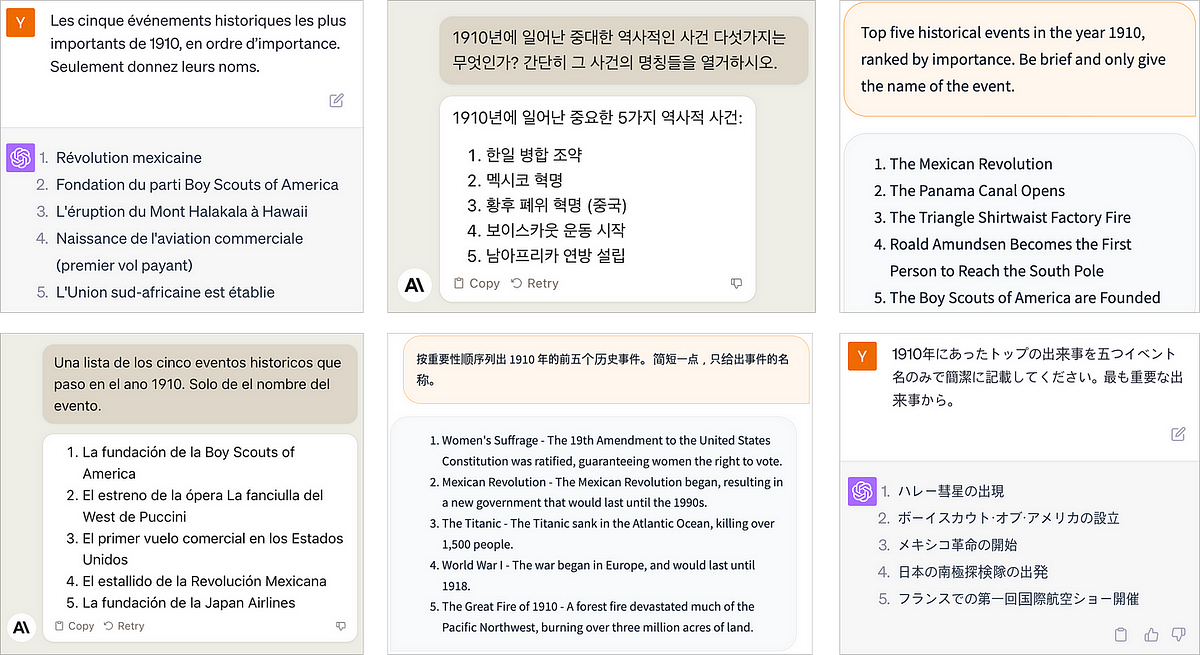
AIのレンズを通じた世界の歴史
人工知能の進歩、特に大規模な言語モデルにより、歴史研究や教育においては興奮すべき可能性が広がっていますしかし、その方法については慎重に検証することが重要です...

トップの投稿 6月26日から7月2日:GPT-4に無料でアクセスする3つの方法
無料でGPT-4にアクセスするための3つの方法 • データランドスケープの進化 • データサイエンティストのためのAI Chrome拡張機能チートシート • ChatGPTがあなたのコーディングをより良く、より速くする7つの方法 • PythonとRでの機械学習アルゴリズムの比較

VoAGIニュース、6月28日:データサイエンスのチートシートのための10のChatGPTプラグイン • データ分析を自動化するChatGPTプラグイン
データサイエンスのチートシートのための10のChatGPTプラグイン • Noteableプラグイン:データ分析を自動化するChatGPTプラグイン • 無料でClaude AIにアクセスする方法は3つあります • ベクトルデータベースとは何か、なぜLLMにとって重要なのか • データサイエンティストのための探索的データ分析の必須ガイド
トップ投稿6月19日〜25日:無料でGPT-4にアクセスする3つの方法
無料でGPT-4にアクセスする3つの方法 • データ分析を自動化するChatGPTプラグインの注目すべき点 • 無料でClaude AIにアクセスする3つの方法 • データサイエンティストのための探索的データ分析の必須ガイド • ベクトルデータベースとは何か、そしてLLMにとってなぜ重要なのか?
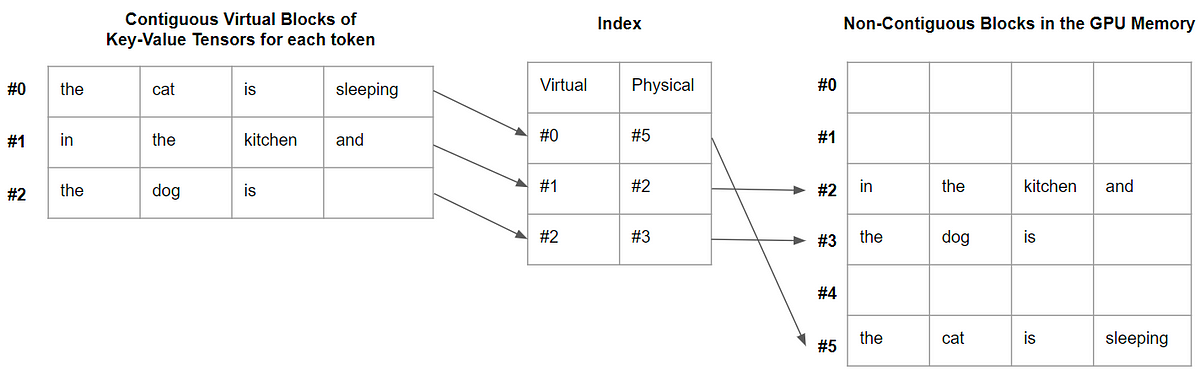
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します

新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
研究者たちは、AlphaGo Zeroと同様に、明確に定義されたルールで競争的なゲームに反復的に参加することによってAIエージェントが自己発展する場合、多くの大規模言語モデル(LLM)が人間の関与がほとんどない交渉ゲームでお互いを高め合う可能性があるかどうかを調査しています。この研究の結果は、遠い影響を与えるでしょう。エージェントが独立に進歩できる場合、少数の人間の注釈で強力なエージェントを構築することができるため、今日のデータに飢えたLLMトレーニングに対して対照的です。それはまた、人間の監視がほとんどない強力なエージェントを示唆しており、問題があります。この研究では、エジンバラ大学とAIアレン研究所の研究者が、顧客と売り手の2つの言語モデルを招待して購入の交渉を行うようにしています。 図1:交渉ゲームの設定。彼らは2つのLLMエージェントを招待して、値切りのゲームで売り手と買い手をプレイさせます。彼らの目標は、より高い値段で製品を販売または購入することです。彼らは第三のLLMであるAI批評家に、ラウンド後に向上させたいプレイヤーを指定してもらいます。その後、批判に基づいて交渉戦術を調整するようにプレイヤーに促します。これを数ラウンド繰り返すことで、モデルがどんどん上達するかどうかを確認します。 顧客は製品の価格を下げたいと思っていますが、売り手はより高い価格で販売するように求められています(図1)。彼らは第三の言語モデルに批評家の役割を担ってもらい、取引が成立した後にプレイヤーにコメントを提供させます。次に、批評家LLMからのAI入力を利用して、再度ゲームをプレイし、プレイヤーにアプローチを改善するように促します。彼らは交渉ゲームを選んだ理由は、明確に定義されたルールと、戦術的な交渉のための特定の数量化目標(より低い/高い契約価格)があるためです。ゲームは最初は単純に見えますが、モデルは次の能力を持っている必要があります。 交渉ゲームのテキストルールを明確に理解し、厳密に遵守すること。 批評家LLMによって提供されるテキストフィードバックに対応し、反復的に改善すること。 長期的にストラテジーとフィードバックを反映し、複数のラウンドで改善すること。 彼らの実験では、モデルget-3.5-turbo、get-4、およびClaude-v1.3のみが交渉ルールと戦略を理解し、AIの指示に適切に合致している必要があるという要件を満たしています。その結果、彼らが考慮したモデルすべてがこれらの能力を示さなかったことが示されています(図2)。初めに、彼らはボードゲームやテキストベースのロールプレイングゲームなど、より複雑なテキストゲームもテストしましたが、エージェントがルールを理解して遵守することがより困難であることが判明しました。彼らの方法はICL-AIF(AIフィードバックからのコンテキスト学習)として知られています。 図2:私たちのゲームで必要な能力に基づいて、モデルは複数の階層に分けられます(C2-交渉、C3-AIフィードバック、C4-継続的な改善)。私たちの研究は、gpt-4やclaude-v1.3などの堅牢で適切に合致したモデルだけが反復的なAI入力から利益を得て、常に発展することができることを明らかにしています。 彼らは、AI批評家のコメントと前回の対話履歴ラウンドをコンテキストに応じたデモンストレーションとして利用しています。これにより、プレイヤーの前回の実際の開発と批評家の変更アイデアが、次のラウンドの交渉のためのフューショットキューに変換されます。2つの理由から、彼らはコンテキストでの学習を使用しています:(1)強化学習を用いた大規模な言語モデルの微調整は、高額であるため、(2)コンテキストでの学習は、勾配降下に密接に関連していることが最近示されたため、モデルの微調整を行う場合には、彼らが引き出す結論がかなり一般的になることが期待されます(資源が許される場合)。 人間からのフィードバックによる強化学習(RLHF)の報酬は通常スカラーですが、ICL-AIFでは、フィードバックが自然言語で提供されます。これは、2つのアプローチの注目すべき違いです。各ラウンド後に人間の相互作用に依存する代わりに、よりスケーラブルでモデルの進歩に役立つAIのフィードバックを検討しています。 異なる責任を負うときにフィードバックを与えられた場合、モデルは異なる反応を示します。バイヤー役のモデルを改善することは、ベンダー役のモデルよりも難しい場合があります。過去の知識とオンライン反復的なAIフィードバックを利用して、get-4のような強力なエージェントが常に意味のある開発を続けることができるとしても、何かをより高く売る(またはより少ないお金で何かを購入する)ことは、全く取引が成立しないリスクがあります。彼らはまた、モデルがより簡潔であるがより綿密(そして最終的にはより成功する)交渉に従事できることを証明しています。全体的に、彼らは自分たちの仕事がAIフィードバックのゲーム環境での言語モデルの交渉を向上させる重要な一歩になると期待しています。コードはGitHubで利用可能です。

クロードAIに無料でアクセスする3つの方法
定期購読料なしで、主要な対話型AIモデルの1つを体験してください
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.