Learn more about Search Results CLIP - Page 18

- You may be interested
- 人工知能の台頭に備えるために、高校生を...
- 「AIによるデータアナリストのテストに挑...
- あなたのLLMアプリケーションは公開に準備...
- 「2つのPandas DataFrameを比較するための...
- データのクレンジングを通じたデジタルト...
- 「チャットボットを使って自動運転車の会...
- Amazon SageMaker JumpStartを使用した対...
- なぜ人々は人工知能AIを恐れているのか?
- ドクトランとLLM:消費者の苦情を分析する...
- あなたが作るものはあなたそのものです:...
- 「ATLAS研究者は、教師なし機械学習を通じ...
- 東京大学の研究者たちは、静的バンディッ...
- ChatGPTと高度なプロンプトエンジニアリン...
- 今日、開発者の70%がAIを受け入れています...
- スタンフォード大学の研究者が、大規模言...

「AIは本当に低品質な画像から顔の詳細を復元できるのでしょうか? DAEFRとは何か:品質向上のためのデュアルブランチフレームワークに出会う」
画像処理の分野では、劣化した顔写真から高精細な情報を回復することは依然として困難な課題です。これらの画像が受ける多くの劣化により、必要な情報の喪失が頻繁に起こるため、これらの活動は本質的に難しいものです。この問題は、低品質の写真と高品質の写真の間の品質の違いを浮き彫りにします。続く問題は、低品質のドメインの固有の特性を利用して、顔の修復プロセスをより良く理解し改善することが可能かどうかということです。 最近のアプローチでは、この問題に対処するためにコードブックの事前知識、オートエンコーダー、高品質の特徴セットが取り入れられています。しかし、これらの手法には依然として重大な弱点があります。それらは通常、高品質のデータのみで訓練された単一のエンコーダーに依存し、低品質の画像が持つ特殊な複雑さを無視します。革新的であるかもしれませんが、このような手法は意図せずにドメインのギャップを広げ、低品質のデータの微妙な側面を見逃す可能性があります。 最近、これらの問題に取り組むために新しい論文が紹介されました。このアプローチでは、ぼやけたまたははっきりしない画像から重要な詳細を引き出し、それらをより明確な画像の詳細と組み合わせて顔画像の修復を改善するための「低品質」のブランチを追加しています。 彼らの研究の特徴は次の通りです: 1. 低品質の画像のユニークな特徴を捉えるための特別なツールを追加し、明確な画像とはっきりしない画像の間のギャップを埋めます。 2. 彼らの手法は、低品質と高品質の画像の詳細を混ぜ合わせます。この混合により、画像の修復における一般的な問題を克服し、より明確で優れた結果を生み出します。 3. 彼らはぼやけたまたははっきりしない顔画像を処理するためのDAEFRという技術を導入しました。 具体的には、彼らの手法は次の重要なステップから構成されます: 離散コードブック学習ステージ:HQおよびLQ画像のためのコードブックを確立します。ベクトル量子化を使用して、ドメイン固有の情報をキャプチャするための自己再構築のためのオートエンコーダーを訓練します。このステージでは、HQおよびLQドメインのためのエンコーダーとコードブックが生成されます。 関連付けステージ:CLIPモデルからのインスピレーションを得て、HQおよびLQドメインの特徴を関連付けます。ドメイン固有のエンコーダーからの特徴はパッチにフラット化され、類似性行列を構成します。この行列は、空間的な位置と特徴レベルの観点でこれらのパッチの近さを測定します。目標は、ドメインのギャップを最小化し、両方のドメインからの情報を統合した関連するエンコーダーを生成することです。 特徴融合とコード予測ステージ:関連するエンコーダーを取得した後、LQ画像は両方のエンコーダーを使用してエンコードされます。マルチヘッドのクロスアテンションモジュールは、これらのエンコーダーからの特徴を統合し、HQおよびLQドメインの情報を包括する融合された特徴を生成します。その後、トランスフォーマーはHQコードブックの関連するコード要素を予測し、それをデコーダーが復元されたHQ画像を生成するために使用します。 著者たちは、自身の手法を一連の実験を通じて評価しました。彼らはPyTorchフレームワークを使用して、70,000枚の高品質の顔画像データセットFFHQでモデルを訓練しました。これらの画像は、トレーニング目的のためにリサイズされ、合成的に劣化させられました。テストには、CelebA-Testと3つの実世界のデータセットを選びました。評価メトリックは、グラウンドトゥルースがあるデータセット用にPSNRとSSIM、グラウンドトゥルースがない実世界のデータセット用にFIDとNIQEを使用しました。最先端の手法と比較して、彼らのDAEFRモデルは実世界のデータセットで優れた知覚品質を示し、合成データセットでは競争力のあるパフォーマンスを発揮しました。また、削除研究では、2つのエンコーダーを使用することが最適であり、提案されたマルチヘッドのクロスアテンションモジュールが特徴融合を改善していることが明らかになり、劣化した画像の修復における手法の有効性を強調しています。 結論として、本記事では、特に低品質の顔写真の画像修復の課題に取り組むために公開された新しい論文を紹介しました。研究者たちは、DAEFRという新しい手法を紹介し、高品質および低品質の画像特徴を活用してより明確で洗練された修復画像を生成します。この手法は、高品質の画像と低品質の画像のためにそれぞれ1つのエンコーダーシステムを使用することにより、既存の2つのドメインの間のギャップを埋めることができます。解決策は厳密に評価され、以前の手法に比べて顕著な改善が示されました。この論文の所見は、DAEFRが画像処理の分野を大幅に推進し、より正確な顔画像の修復を可能にする可能性を強調しています。

「フラミンゴとDALL-Eはお互いを理解しているのか?イメージキャプションとテキストから画像生成モデルの相互共生を探る」
テキストとビジュアルのコンピュータ理解を向上させるマルチモーダル研究は、最近大きな進歩を遂げています。DALL-EやStable Diffusion(SD)などのテキストからイメージを生成するモデルや、FlamingoやBLIPのようなイメージからテキストを生成するモデルは、現実の状況からの複雑な言語的記述を高精度のビジュアルに変換することができます。しかし、テキストからイメージを生成するモデルと画像キャプション生成モデルの間には近接性がありながらも、独立して研究されることが多く、これらのモデルの相互作用は探求される必要があります。テキストからイメージを生成するモデルと画像からテキストを生成するモデルがお互いを理解できるかどうかという問題は興味深いものです。 この問題に取り組むために、特定の画像に対してテキストの説明を生成するためにBLIPという画像からテキストのモデルを使用します。このテキストの説明は、SDというテキストからイメージを生成するモデルに供給され、新しい画像が作成されます。彼らは、作成された画像が元の画像に似ている場合、BLIPとSDがコミュニケーションできると主張しています。共有された理解によって、各モデルの基本的なアイデアを理解する能力が向上し、キャプションの作成と画像合成がより良くなる可能性があります。このコンセプトは図1に示されており、上のキャプションは元の画像のより正確な再構成を導き、下のキャプションよりも入力画像をよりよく表現しています。 https://arxiv.org/abs/2212.12249 LMU Munich、Siemens AG、およびUniversity of Oxfordの研究者は、DALL-EがFlamingoが特定の画像に対して生成する説明を使用して新しい画像を合成する再構成タスクを開発しました。この仮定をテストするために、テキスト-イメージ-テキストとイメージ-テキスト-イメージの2つの再構成タスクを作成します(図1を参照)。最初の再構成タスクでは、事前学習済みのCLIPイメージエンコーダで抽出された画像の特徴の距離を計算し、再構成された画像と入力画像の意味がどれだけ似ているかを判断します。次に、生成されたテキストの品質を人間によって注釈付けされたキャプションと比較します。彼らの研究は、生成されたテキストの品質が再構成のパフォーマンスにどのように影響するかを示しています。これにより、彼らの最初の発見が導かれます:生成モデルが元の画像を再構成するための説明は、画像に最も適した説明であるということです。 同様に、SDがテキストの入力から画像を作成し、その作成された画像からBLIPがテキストを作成する逆のタスクを作成します。彼らは、元のテキストを生成した画像がテキストにとって最も優れたイラストであることを発見します。彼らは、再構成プロセス中に入力画像からの情報がテキストの記述に正確に保持されると仮定しています。この意味のある説明は、画像モダリティへの忠実な回復につながります。彼らの研究は、テキストからイメージやイメージからテキストのモデルがお互いとコミュニケーションするのを容易にする独自のフレームワークを示唆しています。 具体的には、彼らのパラダイムでは、生成モデルは再構成損失と人間のラベルからトレーニング信号を受け取ります。1つのモデルは、他のモダリティの特定の画像またはテキストの入力の表現を最初に作成し、異なるモデルはこの表現を入力モダリティに戻します。再構成コンポーネントは、初期モデルの微調整を指示する正則化損失を作成します。このようにして、彼らは自己および人間の監督を得て、生成がより正確な再構成に結果をもたらす可能性を高めます。たとえば、画像キャプションモデルは、ラベル付きの画像テキストのペアに対応するだけでなく、信頼性のある再構成につながるキャプションを好む必要があります。 エージェント間の通信は彼らの仕事と密接に関連しています。エージェント間の主要な情報交換手段は言語です。しかし、最初のエージェントと2番目のエージェントが猫や犬の定義を同じく持っていることを確信することはできますか?この研究では、最初のエージェントに画像を調査し、それを説明する文を生成するように求めます。テキストを受け取った後、2番目のエージェントはそれに基づいて画像をシミュレーションします。後者の段階は具現化プロセスです。彼らの仮説によれば、通信は効果的である場合、2番目のエージェントの入力画像のシミュレーションが最初のエージェントが受け取った入力画像に近い場合です。本質的には、彼らは人間の主要なコミュニケーション手段である言語の有用性を評価しています。特に、新たに確立された大規模な事前学習済みの画像キャプションモデルと画像生成モデルが彼らの研究で使用されています。さまざまな生成モデルに対して、トレーニングフリーおよび微調整の状況の両方で彼らの提案されたフレームワークの利点が証明されました。特に、トレーニングフリーのパラダイムでは、キャプションと画像の作成が大幅に改善されました。一方、微調整では、両方の生成モデルに対してより良い結果が得られました。 以下は彼らの主な貢献の要点です: • フレームワーク:従来の単独の画像からテキストへの生成モデルとテキストから画像への生成モデルが、簡単に理解できるテキストと画像の表現を介して通信する方法について初めて調査したと彼らは最もよく知っています。一方、同様の研究ではテキストと画像の作成を埋め込み空間を介して暗黙的に統合します。 • 結果:彼らは、テキストから画像へのモデルによって作成された画像の再構成を評価することが、キャプションの品質を判断するのに役立つことを発見しました。元の画像の最も正確な再構成を可能にするキャプションが、その画像に使用すべきキャプションです。同様に、元のテキストの最も正確な再構成を可能にするキャプションが最良のキャプション画像です。 • 改善:彼らの研究に基づいて、テキストから画像へのモデルと画像からテキストへのモデルの両方を改善する包括的なフレームワークを提案しました。テキストから画像へのモデルによって計算された再構成損失は、画像からテキストへのモデルの微調整に正則化として使用され、画像からテキストへのモデルによって計算された再構成損失は、テキストから画像へのモデルの微調整に使用されます。彼らは自身のアプローチの有効性を調査し、確認しました。

「Amazon SageMaker JumpStart上で、生成型AIベースのコンテンツモデレーションソリューションを構築する」
この記事では、マルチモーダルな事前学習と大規模な言語モデル(LLM)を使用した画像データのコンテンツモデレーションの新しい手法を紹介しますマルチモーダルな事前学習により、興味のある質問のセットに基づいて直接画像のコンテンツをクエリすることができ、モデルはこれらの質問に答えることができますこれにより、ユーザーは画像とチャットして、組織のポリシーに違反するような不適切なコンテンツが含まれているかを確認することができますLLMの強力な生成能力を利用して、安全/危険なラベルやカテゴリータイプを含む最終的な意思決定を生成しますさらに、プロンプトを設計することで、LLMに指定された出力形式(JSON形式など)を生成させることができます設計されたプロンプトテンプレートにより、LLMは画像がモデレーションポリシーに違反しているかどうかを判断し、違反のカテゴリーを特定し、なぜ違反しているのかを説明し、構造化されたJSON形式で出力を提供することができます
自然言語処理:BERTやGPTを超えて
技術の世界は常に進化しており、その中でも特に進歩が見られる分野の一つが自然言語処理(NLP)です数年前には、BERTとGPTという画期的なモデルが登場しました...

FMOps / LLMOps:生成型AIの運用化とMLOpsとの違い
最近、私たちのほとんどの顧客は、大規模な言語モデル(LLM)に興味を持ち、生成型AIが彼らのビジネスを変革する可能性を考えていますしかし、このようなソリューションやモデルを通常の業務に取り入れることは容易ではありませんこの記事では、MLOpsの原則を使って生成型AIアプリケーションを運用化する方法について説明しますこれにより、基盤モデル運用(FMOps)が実現されますさらに、私たちはテキストからテキストへの生成型AIの一般的な使用例であるテキスト生成(LLMOps)とFMOpsのサブセットであるLLM運用(LLMOps)について詳しく掘り下げます以下の図は、私たちが話し合うトピックを示しています
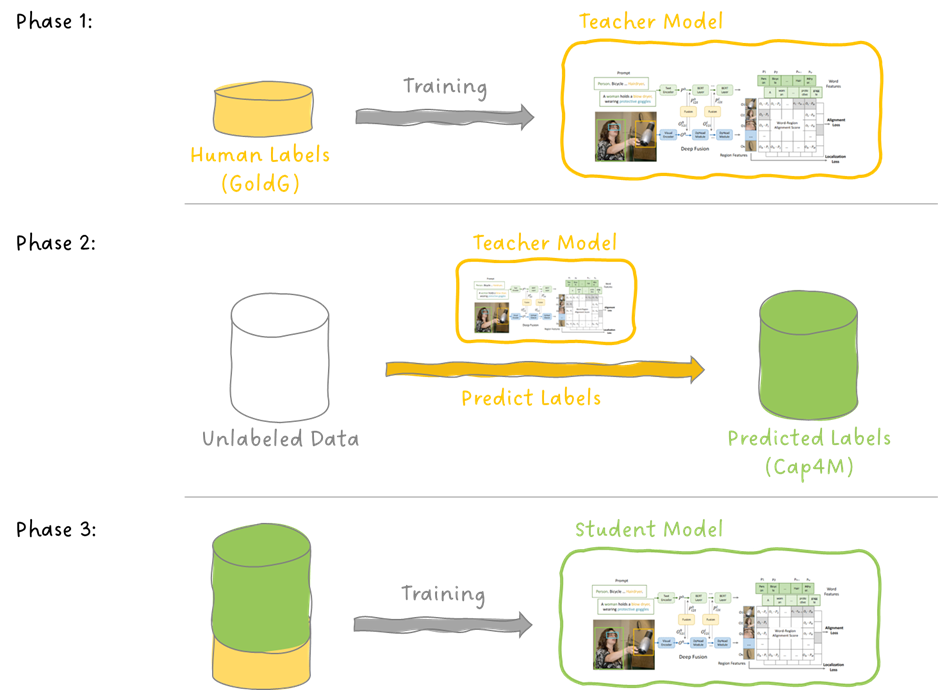
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げます...

「GeForce NOWが大いに盛り上がり、9月には24本の新作ゲームが登場しますその中でも『Party Animals』が一番注目されています」
そうして、夏は9月になり、今年最も期待されているゲームのいくつか、Cyberpunk 2077:Phantom Libertyの拡張版、PAYDAY 3、そしてParty Animalsが、今月のローンチと共にGeForce NOWライブラリに追加されます。 これらは9月にクラウドゲーミングサービスに追加される24の新しいゲームの一部です。そして、次のGame PassタイトルであるSea of Starsが、今週の13の新しいゲームの一部としてローンチ時にクラウドに参加します。 GFN Thursdayでは、今月クラウドに参加する次のMicrosoftタイトル(Quake II、Gears Tactics、Halo Infiniteなど)を見るために目を光らせてください。 さらに、NVIDIAはGoogleと連携して、Chromebookの所有者にGeForce NOW Priorityメンバーシップの3か月無料オファーを提供します。GeForce NOWクラウドゲーミングは、最大1,600pの解像度と120Hz以上のディスプレイを提供するChromebookと完全に組み合わせることができます。 クラウドでパーティーハード クラウドが大騒ぎになります。 Recreate GamesとSource Technologyによる、笑えるほどおかしい物理ベースのパーティーバトラー、Party…

「S-LabとNTUの研究者が、シーニメファイ(Scenimefy)を提案しましたこれは、現実世界の画像から自動的に高品質なアニメシーンのレンダリングを行うための画像対画像翻訳フレームワークであり、セミスーパーバイズド(半教師付き)手法を採用しています」
アニメの風景は創造力と時間を大量に必要とするため、自動的なシーンのスタイル化のための学習ベースの手法の開発には明らかな実用的かつ経済的な意義があります。自動スタイル化は、最近の生成的対抗ネットワーク(GAN)の発展により、大幅に改善されていますが、この研究のほとんどは主に人間の顔に焦点を当てています。複雑な現実世界のシーン写真から高品質なアニメの風景を作成するプロセスは、その莫大な研究価値にもかかわらず、まだ研究が必要です。現実のシーン写真をアニメスタイルに変換するには、いくつかの要素が関与して多くの作業が必要です。 1) シーンの構成:図1は、シーン内の前景と背景部分の階層関係を示しており、これらの部分はしばしば複雑な方法で接続された複数のアイテムで構成されています。 2) アニメの特徴:図1は、草、木、雲などの自然環境で事前に設計された筆触が使用されることで、アニメを定義する特異なテクスチャと正確なディテールが作成される様子を示しています。これらのテクスチャの有機的で手描きの性質は、以前の実験で示された鮮明なエッジと均一な色のパッチよりも模倣がはるかに困難です。 3) データの不足とドメインのギャップ:高品質なアニメのシーンデータセットは、背景の風景とは異なる美的を持つ多くの人間の顔や他の前景アイテムのため、現実とアニメのシーンの間のギャップを埋める上で重要です。既存のデータセットは低品質です。 図1:アニメのシーンの特徴。手描きの筆触(前景の草や石)や木や雲(背景)の存在が、新海誠監督の2011年の映画「星を追う子ども」のシーンフレームで見ることができます。 対称的な画像変換は、対になったトレーニングデータがない場合に複雑なシーンのスタイル化に使用される人気のある方法です。アニメスタイルに焦点を当てた既存の技術は、有望な結果を示しているにもかかわらず、いくつかの分野で追いつく必要があります。まず、複雑な風景ではピクセルごとの相関が欠如しているため、現在のアプローチでは明らかなテクスチャのスタイル化を実行するのが困難であり、意外な出力や目立つアーティファクトを含む可能性があります。2つ目に、一部の方法ではアニメのシーンの微細なディテールを生成しません。これは、エッジや表面のなめらかさを強制する構築されたアニメ固有の損失や事前抽出された表現に起因しています。 上記の問題を解決するために、南洋理工大学のS-Labの研究者は、高品質なアニメスタイルのシーン写真の表現を作成するためのユニークな半教師ありイメージ間変換(I2I)パイプラインであるScenimefyを提案しています。彼らの主な提案は、疑似対応データを使用して、教師なしフレームワークに新しい教師ありトレーニングブランチを導入し、教師なしトレーニングの欠点に対処することです。彼らはStyleGANの有利な特性を使用して、実際のアニメまたは偽の対応データ間の粗い対応データを提供するためにそれを微調整するというメインの提案を行っています。 図2は、Scenimefyによるアニメのシーンのレンダリングを示しています。上段:翻訳された画像;下段:翻訳の結果。 彼らは、CLIPやVGGなどの豊富な事前学習モデルの先行知識を使用して、StyleGANが複雑なシーンの詳細を捉え、過学習を減らすようにするための新しい意味制約型微調整手法を提供しています。低品質のデータをフィルタリングするために、彼らはセグメンテーションに基づいたデータ選択手法も提供しています。疑似対応データとユニークなパッチごとの対照的なスタイル損失を使用することで、Scenimefyは2つのドメイン間の微細な詳細を作成し、効果的なピクセルごとの対応を学習します。彼らの半教師ありフレームワークは、シーンのスタイル化の忠実さと正確さ、教師なしトレーニングブランチの間で望ましいトレードオフを試みます。 彼らはまた、トレーニングを支援するために純粋なアニメシーンの高品質なデータセットを収集しました。彼らは広範なテストを実施し、Scenimefyの有効性を示し、知覚品質と数量評価の業界基準を上回りました。以下は彼らの主な貢献の概要です: • 彼らは、実際の写真を洗練されたアニメシーンの優れた品質の画像に変換する新しい準教師付きシーンスタイライゼーションフレームワークを提供しています。彼らのシステムは、スタイライゼーションと細部を向上させるために独自のパッチ単位の対比的なスタイル損失を追加します。 • 豊富な事前トレーニングのガイダンスに続いて、セグメンテーションによるデータ選択スキームによって構造一貫性のある擬似ペアデータが生成される、新しく開発された意味制約付きStyleGAN微調整技術があります。これはトレーニングの監督の基礎となります。 • 彼らは、将来のシーンスタイライゼーションの研究に役立つ高解像度のアニメシーンのコレクションを収集しました。

ワシントン大学とAI2の研究者が、VQAを介してAIが生成した画像の忠実度を測定する自動評価指標であるTIFAを紹介します
テキストから画像を生成するモデルは、人工知能の進歩の最も良い例の一つです。研究者たちの持続的な進歩と努力により、これらのモデルは長い道のりを歩んできました。テキストから画像を生成するモデルの大幅な進歩があるにもかかわらず、これらのシステムは通常、提供された書かれた説明と正確に一致する画像を生成することができません。既存のモデルでは、画像内の複数のアイテムを正しく組み合わせるための支援、適切なオブジェクトに特性を割り当てるための支援、および視覚的なテキストの生成が必要です。 研究者たちは、生成モデルがこれらの困難を処理する能力を向上させるために、言語構造を導入して画像の作成を指示することを試みてきました。CLIPScoreなどの手法では、作成された画像がテキスト入力とどれだけ似ているかを評価するためにCLIP埋め込みを使用しますが、事物を正確にカウントしたり合成的に推論する能力に制約があるため、信頼性のあるメトリックではありません。画像のキャプションを使用する方法もありますが、画像がテキストで説明され、元の入力と比較されます。しかし、このアプローチでは、ラベリングモデルが画像の重要な側面を見落としたり、無関係な領域に集中したりする可能性があるため、不十分です。 これらの問題を解決するために、ワシントン大学とAI2の研究者チームは、TIFA(Text-to-Image Faithfulness evaluation with Question Answering)を導入しました。TIFAは、視覚的な質問応答(VQA)を利用して、画像が関連するテキスト入力とどれだけ一致するかを判断するための自動評価メトリックです。チームは、言語モデルを使用して与えられたテキスト入力からさまざまな質問と回答のペアを生成しました。作成された画像を使用してよく知られたVQAモデルがこれらのクエリに正しく応答できるかどうかを調べることにより、画像の信憑性を評価することができます。 TIFAは、出力画像の品質の徹底的かつ簡単な評価を可能にする無参照メトリックとして際立っています。他の評価メトリックと比較して、TIFAは人間の判断とより強い関連性を示しました。この手法を基礎として、チームはTIFA v1.0も発表しており、これには4Kのテキスト入力と12の異なるカテゴリ(オブジェクトやカウントなど)に分割された合計25Kの質問が含まれています。TIFA v1.0を使用して、既存のテキストから画像へのモデルを包括的に評価し、現在の問題と困難を明らかにしました。 色や材料の表現などの面で優れているにもかかわらず、TIFA v1.0を使用したテストでは、現代のテキストから画像へのモデルは、空間関係や複数のオブジェクトを正確に描写することにまだ問題があります。研究チームは、彼らのベンチマークを導入することで、テキストから画像への合成の分野での進歩を評価するための正確な基準の構築を目指しています。彼らは貴重な洞察を提供することにより、指摘された制約を克服し、この技術のさらなる発展を促進するためのすべての将来の研究を導くことを望んでいます。 結論として、TIFAは画像とテキストの整合性を測定するための優れた手法であり、まずLLMによって質問のリストを生成し、次に画像に対して視覚的な質問応答を行い、正確性を計算します。

「DenseDiffusionとの出会い:テキストから画像生成における密なキャプションとレイアウト操作に対処するためのトレーニング不要のAI技術」
テキストから画像を生成するモデルの最近の進歩により、短いシーンの説明に基づいて高品質の画像を生成することができる洗練されたシステムが生まれました。しかし、これらのモデルは複雑なキャプションに直面すると困難に直面し、しばしば異なるオブジェクトに関連する視覚的属性の省略や混合が生じます。この文脈での「dense」の用語は、個々のフレーズが画像内の特定の領域を説明するために使用されるdense captioningの概念に根ざしています。さらに、テキストのプロンプトのみを使用して生成された画像内の要素の配置を正確に指示することにユーザーは課題に直面しています。 最近のいくつかの研究では、ユーザーにレイアウトに基づいた空間制御を提供する解決策を提案しています。特定のアプローチ(「Make-aScene」や「Latent Diffusion Models」など)では、テキストとレイアウトの条件の両方でモデルを構築しますが、他の同時的な方法(「SpaText」や「ControlNet」など)では、既存のテキストから画像へのモデルに補足的な空間制御を導入するために微調整を行います。残念ながら、モデルのトレーニングや微調整は計算量が多くかかることがあります。さらに、モデルは新しいユーザー条件、ドメイン、またはベースのテキストから画像へのモデルごとに再トレーニングを必要とします。 上記の問題に基づいて、dense captionsを収容しレイアウト操作を提供するための新しいトレーニングフリーのテクニックであるDenseDiffusionが提案されています。 メインのアイデアを提示する前に、拡散モデルがどのように機能するかについて簡単に説明します。拡散モデルは、ランダムノイズから始まり、連続的なノイズ除去ステップを通じて画像を生成します。ノイズ予測ネットワークは追加されたノイズを推定し、各ステップでより鮮明な画像をレンダリングしようとします。最近のモデルでは、生成された画像を大幅に犠牲にすることなく、より速い結果を得るために、ノイズ除去ステップの数を減らしています。 最先端の拡散モデルには、自己注意と交差注意の2つの重要なブロックがあります。 自己注意層では、中間特徴がコンテキスト特徴として機能します。これにより、さまざまな領域にわたる画像トークンの間の接続を確立することで、グローバルに一貫した構造を作成することができます。同時に、交差注意層は、入力テキストキャプションから得られたテキスト特徴に基づいて適応し、エンコードにCLIPテキストエンコーダーを使用します。 前述のように、DenseDiffusionのメインのアイデアは、生成された画像のレイアウトと自己注意と交差注意マップの間の大きな相関関係を明らかにするために、事前にトレーニングされたテキストから画像への拡散モデルの中間特徴を検証することです。この洞察から、中間の注意マップはレイアウト条件に基づいて動的に調整されます。さらに、このアプローチでは、各セグメントの領域に基づいて元の注意スコア範囲を考慮し、調整の範囲を微調整する必要があります。この研究では、DenseDiffusionの性能を「Stable Diffusion」モデルの性能向上に活用し、dense captions、テキストとレイアウトの条件、および画像の品質において複数の構成拡散モデルを凌駕する能力を示しています。 研究から選択されたサンプルの結果は、以下の画像で示されています。これらの視覚的な比較は、DenseDiffusionと最先端の手法の間の概要を提供します。 これは、DenseDiffusionという新しいAIのトレーニングフリーテクニックについての要約であり、dense captionsを収容し、テキストから画像への合成においてレイアウト操作を提供します。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.