Learn more about Search Results ドキュメンテーション - Page 18

- You may be interested
- 「NExT-GPT あらゆるモダリティに対応した...
- ChatGPTによるカスタムMatplotlibウェルロ...
- 「Nvidiaの画期的なAIイメージパーソナラ...
- 「MLの学習に勇気を持つ:L1&L2正則化の...
- 「Javaを使用した脳コンピュータインター...
- ディープラーニングが深く掘り下げる:AI...
- 最近の人類学的研究によれば、クロード2.1...
- 「LLaSMと出会う:音声と言語の指示に従う...
- グーグルサーチは、Googleサーチで文法チ...
- 人間の脳プロジェクトによるマッピングは...
- エンターテイメントデータサイエンス:ス...
- このAI論文は、実世界の網膜OCTスキャンを...
- 『アウトラインを使った信頼性の高いLLMシ...
- 「Pythonのタイピングに関するデータサイ...
- フリーランサーが真の自由を達成するため...
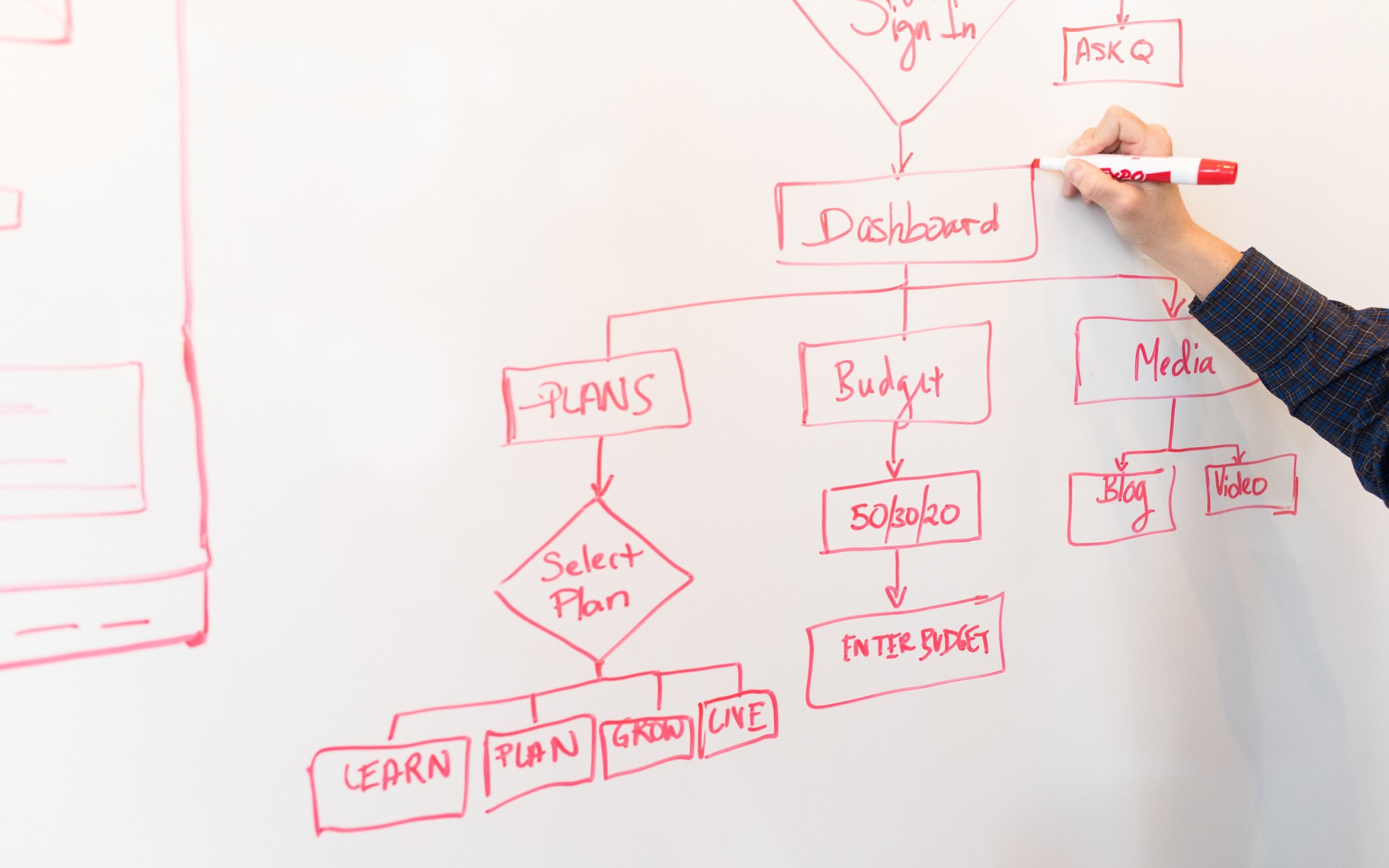
開発者の皆さんへ:ダイアグラムはそんなに複雑である必要はありません
「図表は有用な情報を含んでいるだけでなく、読みやすいものでなければなりませんそして、作成するのも簡単で、楽しいことが望ましいです!」

「OceanBaseを使用して、ゼロからLangchainの代替を作成する」
「オーシャンベースとAIの統合からモデルのトレーニングやチャットボットの作成まで、興味深い旅を通じてこのトピックを探求します」

『AI入門』
「ここでは、AIの学び方についての私の以前の記事を読んでいることを前提としています再度お伝えしますが、機械学習を学ぶ際には、ドキュメンテーション以外の複数の情報源を参照することを強くお勧めします...」
「ジェネラティブAIを使用した7つのプロジェクト」
ジェネラティブAIを利用した個人プロジェクトで強力なポートフォリオを作り方を学びましょうこれにより、あなたは他の人と差をつけることができます!

「マイクロソフトのAzureとGoogleのCloud Platformの比較」
導入 Microsoft AzureとGoogle Cloud Platformは、クラウドコンピューティングの2大巨頭です。この2つの中で、Microsoft Azureは最も効果的かつ適応性のあるソフトウェアソリューションを提案している一方、Google Cloud Platform(GCP)は高度なビッグデータ分析ソリューションを提供し、他のベンダー製品とのシンプルな統合を可能にしています。2023年初めの時点で、Azureは世界で2番目に大きなクラウドサービスとなる23%の市場シェアを獲得し、同時にGoogle Cloudは11%の市場シェアを持っていました。それでは、Microsoft AzureとGoogle Cloud Platformの違いを詳しく探って、最適な選択肢を理解してみましょう。 Azure vs GCP:概要 以下の比較表は、AzureとGCPの間のいくつかの主な特徴の違いを示しています。 特徴 Microsoft Azure Google Cloud Platform(GCP) 設立 2010年に開始…
素晴らしい応用(データ)科学の仕事
データサイエンスを素晴らしくするメタスキル:ビジネス要件から結果の説得力のあるプレゼンテーションまで、問題を終始解決するのに役立つもの

「AutoGPTQとtransformersを使ってLLMsを軽量化する」
大規模な言語モデルは、人間のようなテキストの理解と生成能力を示し、さまざまなドメインでのアプリケーションを革新しています。しかし、訓練と展開における消費者ハードウェアへの要求は、ますます困難になっています。 🤗 Hugging Faceの主なミッションは、良い機械学習を民主化することであり、これには大規模モデルを可能な限りアクセスしやすくすることも含まれます。bitsandbytesコラボレーションと同じ精神で、私たちはTransformersにAutoGPTQライブラリを統合しました。これにより、ユーザーはGPTQアルゴリズム(Frantar et al. 2023)を使用して8、4、3、または2ビット精度でモデルを量子化して実行できるようになりました。4ビットの量子化ではほとんど精度の低下はなく、推論速度は小規模なバッチサイズの場合にはfp16ベースラインと比較可能です。GPTQメソッドは、校正データセットのパスを必要とする点で、bitsandbytesによって提案された事後トレーニング量子化手法とは若干異なります。 この統合はNvidiaのGPUとRoCm-powered AMDのGPUの両方で利用可能です。 目次 リソース GPTQ論文の簡潔な要約 AutoGPTQライブラリ – LLMの効率的なGPTQの活用のためのワンストップライブラリ 🤗 TransformersでのGPTQモデルのネイティブサポート Optimumライブラリを使用したモデルの量子化 テキスト生成推論を介したGPTQモデルの実行 PEFTを使用した量子化モデルの微調整 改善の余地 サポートされているモデル 結論と最終的な言葉 謝辞…
「データエンジニアリングの役割に疲れましたか?」
数年前、私は自分のキャリアに満足していないと感じる時期にいました私はデータエンジニアリングの仕事を3年間しており、テクノロジーの世界でのスタートの興奮も初めの頃には…

「Declarai、FastAPI、およびStreamlitを使用してLLMチャットアプリケーションを展開する」
2022年10月、私が大規模言語モデル(LLM)の実験を始めたとき、最初の傾向はテキストの補完、分類、NER、およびその他のNLP関連の領域を探索することでしたしかし、...
「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
はじめに Pandasとは、名前だけではありません – それは「パネルデータ」の略です。では、それが具体的に何を意味するのでしょうか?経済学や統計学におけるPandasのデータ形式を使用します。それは、異なるエンティティや主体に対して複数の期間にわたる観察を保持する構造化されたデータセットを指します。 現代では、人々はさまざまなファイル形式でデータを保存し、アクセス可能な形式に変換する必要があります。これは、データサイエンスプロジェクトの最初のステップであり、この記事の主な話題になります。 この記事は、データサイエンスブログマラソンの一環として公開されました。 Pandasのデータサイエンスの成功の要素 簡単なデータ処理: pandasの特筆すべき機能の一つは、複雑なデータタスクを簡単に処理できることです。以前は複雑なコードだったものが、pandasの簡潔な関数によってスムーズに処理されるようになりました。 完璧なデータの調和: pandasは、NumPy、Matplotlib、SciPy、Scikit Learnなどの高度なライブラリとシームレスに組み合わさり、より大規模なデータサイエンスの一部として効率的に機能します。 データ収集の適応性: pandasは、さまざまなソースからデータを収集する柔軟性を持っています。CSVファイル、Excelシート、JSON、またはSQLデータベースであっても、pandasはすべて対応します。この適応性により、データのインポートが簡素化され、形式変換の頭痛から解放されます。 要するに、pandasの成功は、ユーザーフレンドリーな構造、データの管理能力、他のツールとの統合、さまざまなデータソースの処理能力から生まれています。これにより、データ愛好家はデータセットに隠された潜在能力を引き出し、データサイエンスの景観を再構築することができます。 Pandasはデータをきれいに整理する方法 pandasをデータ整理のオーガナイザーとして想像してみてください。pandasは、「Series」と「DataFrame」という2つのすばらしい構造を使用してデータを処理します。それらはデータストレージのスーパーヒーローのようなものです! Series: Seriesは、データが配置される直線のようなものです。それは数字から単語まで、あらゆるものを保持することができます。各データには、インデックスと呼ばれる特別なラベルが付いています。それは名札のようなものです – データを簡単に見つけるのに役立ちます。Seriesは、単一の列のデータを扱うときに非常に便利です。計算や分析などのトリックを実行することができます。 DataFrame: DataFrameは、ミニスプレッドシートまたはファンシーテーブルのようなものです。Excelで見るような行と列があります。各列はSeriesです。したがって、「Numbers」列、 「Names」列などが持てます。DataFrameは完全なパッケージのようなものです。数値、単語など、さまざまなデータを処理するのに非常に優れています。さらに、探索やデータの整理、データの変更などの便利な機能を備えています。DataFrameの各列はSeriesです!…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.