Learn more about Search Results - Page 18

- You may be interested
- キャルレールの最高製品責任者、ライアン...
- DORSalとは 3Dシーンの生成とオブジェクト...
- 『ゴミ科学者にならない方法』
- 「OpenAIがユーザーエクスペリエンスを革...
- 知識グラフ:AIとデータサイエンスのゲー...
- Relume AIによって生成されたワイヤーフレ...
- AWSを使った生成AIを活用したクラウド上の...
- 「LinkedInプロフィールでコールバック率...
- 機械学習、イラストで解説:インクリメン...
- 「機械学習におけるデータの重要性:AI革...
- エンドトゥエンドの実験設計をA/Bテストを...
- 「NASAがAIを利用して、特定できない異常...
- 「人工知能と画像生成の美学」
- 「AIサイバーセキュリティのスタートアッ...
- 化学エンティティ認識の自動化:ChemNERモ...

GradioがHugging Faceに参加します!
GradioはHugging Faceに参加します! Gradioは機械学習のスタートアップを買収することにより、Hugging Faceはユーザー、開発者、データサイエンティストが高いレベルの結果を得て、より良いモデルとツールを作成するために必要なツールを提供することができるようになります… えーと、上記のような買収に関する段落は非常に一般的であり、アルゴリズムがそれらを書くことができます。 実際、そうです!この最初の段落はAcquisition Post Generatorという、Hugging Face Spaces上の機械学習デモで書かれました。 あなた自身のブラウザで実行することができます。任意の2つの会社の名前を提供すれば、買収を発表する記事の始まりとして妥当なサウンディングを得ることができます! Acquisition Post Generatorは、私たちのオープンソースのGradioライブラリを使用して構築されました。これは、Hugging Faceとの最近のコラボレーションの1つにすぎません。そして、私は興奮して発表します…🥁 Hugging FaceがGradioを買収 することを(はい、最初の段落はアルゴリズムによって書かれたかもしれませんが、それは本当です!) Gradioの創設者の1人として、私たちの旅の次のステップについてはもっと興奮していることはありません。私は2019年にどのように始まったかをはっきりと覚えています。スタンフォード大学の博士課程生として、医師である私の1人の共同研究者と医療コンピュータビジョンモデルを共有するのに苦労しました。私は彼に私の機械学習モデルをテストしてもらう必要がありましたが、彼はPythonを知らず、独自の画像で簡単にモデルを実行することができませんでした。私は、機械学習エンジニアがコンピュータビジョンモデルのデモを簡単に構築して共有できるツールを想像しました。それによって、フィードバックが向上し、信頼性の高いモデルが生まれることになるのです🔁 私は才能あるルームメイトのAli Abdalla、Ali Abid、Dawood Khanを募集して、2019年に最初のバージョンのGradioをリリースしました。私たちはテキスト、音声、ビデオなど、さらなる機械学習の領域をカバーするように徐々に拡大しました。研究者だけでなく、スタートアップから公開企業まで、業界の異なる分野のチームが機械学習モデルを共有する必要があることがわかりました。Gradioはその両方に役立つことができます。私たちが最初にライブラリをリリースして以来、30万以上のデモがGradioで作成されました。私たちは、コントリビュータのコミュニティ、サポートしてくれる投資家、そして今年私たちの会社に参加した素晴らしいAhsen Khaliqの存在なしでは、これを実現することはできませんでした。…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…
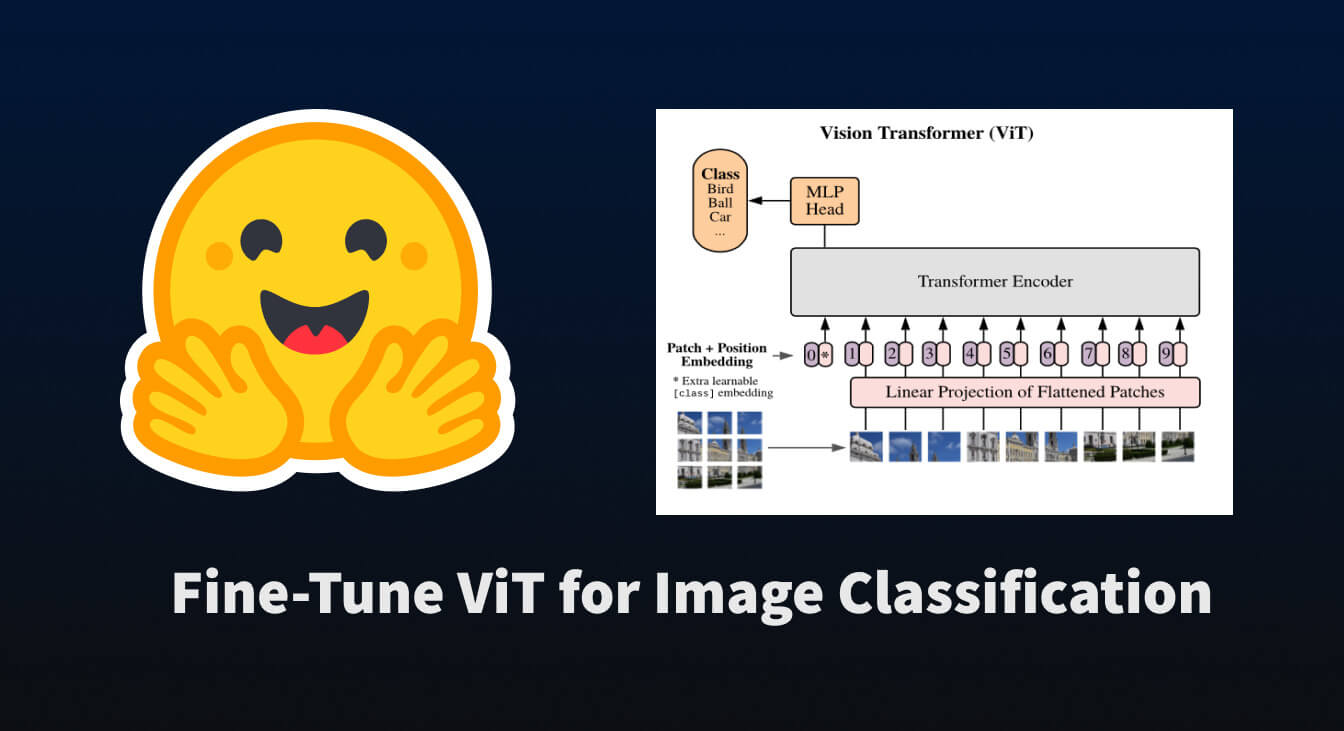
🤗 Transformersを使用して、画像分類のためにViTを微調整する
トランスフォーマーベースのモデルがNLPを革命化したように、我々は今、それらを他のさまざまな領域に適用する論文の爆発を目撃しています。その中でも最も革命的なものの一つが「Vision Transformer(ViT)」です。これは、Google Brainの研究チームによって2021年6月に紹介されました。 この論文では、文をトークン化するように画像をトークン化する方法を探求しており、それによってトランスフォーマーモデルにトレーニング用のデータとして渡すことができます。実際には非常にシンプルな概念です… 画像をサブ画像パッチのグリッドに分割する 各パッチを線形変換で埋め込む 各埋め込まれたパッチがトークンとなり、埋め込まれたパッチのシーケンスがモデルに渡される 上記の手順を実行すると、NLPのタスクと同様にトランスフォーマーを事前学習および微調整することができることがわかります。かなり便利です 😎。 このブログポストでは、🤗 datasets を使用して画像分類データセットをダウンロードおよび処理し、それを使用して事前学習済みの ViT を 🤗 transformers を使用して微調整する方法について説明します。 まずは、それらのパッケージをインストールしましょう。 pip install datasets transformers データセットの読み込み まずは、小規模な画像分類データセットを読み込んで、その構造を確認しましょう。…

🤗 Transformersにおいて制約付きビームサーチを用いたテキスト生成のガイド
イントロダクション このブログ投稿では、トランスフォーマーを使用した言語生成のための異なるデコーディング方法について説明したブログ投稿「テキスト生成方法: トランスフォーマーを使用した異なるデコーディング方法」で説明されているように、読者がビームサーチの異なるバリアントを使用したテキスト生成方法に精通していることを前提としています。 通常のビームサーチとは異なり、制約付きビームサーチではテキスト生成の出力に対して制御を行うことができます。これは、出力内に正確に何を含めたいかを知っている場合に役立ちます。たとえば、ニューラル機械翻訳のタスクでは、辞書検索を使用して最終的な翻訳に含まれる必要がある単語を知っているかもしれません。言語モデルにとってほぼ同じくらい可能性がある生成出力でも、特定の文脈においてエンドユーザーにとっては同じくらい望ましくない場合があります。これらの状況は、ユーザーがモデルに最終出力に含まれる必要のある単語を指示することで解決できます。 なぜ難しいのか しかし、これは非常に非自明な問題です。これは、生成されたテキストの最終出力のどこかで、特定の部分文字列の生成を強制する必要があるからです。 例えば、トークン t 1 , t 2 t_1, t_2 t 1 , t 2 を順番に含む文 S を生成したいとします。予測される文…

CO2排出量と🤗ハブ:リーディング・ザ・チャージ
CO2排出量とは何であり、なぜ重要なのか? 気候変動は私たちが直面している最大の課題の一つであり、二酸化炭素(CO2)などの温室効果ガスの排出削減はこの問題に取り組む上で重要な役割を果たします。 機械学習モデルのトレーニングとデプロイメントには、コンピューティングインフラストラクチャのエネルギー使用によりCO2が排出されます。GPUからストレージまで、すべてが機能するためにエネルギーを必要とし、その過程でCO2を排出します。 写真:最近のTransformerモデルとそのCO2排出量 CO2の排出量は、実行時間、使用されるハードウェア、エネルギー源の炭素密度など、さまざまな要素に依存します。 以下に説明するツールを使用することで、自身の排出量を追跡および報告することができます(これは私たちのフィールド全体の透明性を向上させるために重要です!)また、モデルを選択する際にはそのCO2排出量に基づいて選択することができます。 Transformersを使用して自動的に自分のCO2排出量を計算する方法 始める前に、システムに最新バージョンのhuggingface_hubライブラリがインストールされていない場合は、以下を実行してください: pip install huggingface_hub -U Hugging Face Hubを使用して低炭素排出モデルを見つける方法 モデルがハブにアップロードされたことを考慮して、エコ意識を持ってハブ上のモデルを検索する方法はありますか?それには、huggingface_hubライブラリに新しい特別なパラメータemissions_thresholdがあります。最小または最大のグラム数を指定するだけで、その範囲内に含まれるすべてのモデルが検索されます。 たとえば、最大100グラムで作成されたすべてのモデルを検索できます: from huggingface_hub import HfApi api = HfApi()…

教育のためのHugging Faceをご紹介します 🤗
機械学習がソフトウェア開発の圧倒的な割合を占めること、非技術的な人々がますますAIシステムに触れることを考えると、AIの主な課題の1つは従業員のスキルを適応・向上させることです。また、AIの倫理的および重要な問題を積極的に考慮するために教育スタッフをサポートする必要があります。 Hugging Faceは機械学習を民主化するオープンソース企業として、世界中のあらゆるバックグラウンドの人々に教育を提供することが重要だと考えています。 私たちは2022年3月にMLデモクラタイゼーションツアーを開始し、Hugging Faceの専門家が16カ国の1000人以上の学生に対して実践的な機械学習クラスを教えました。新しい目標は、「2023年末までに500万人に機械学習を教える」ことです。 このブログ記事では、教育に関する目標達成方法の概要を提供します。 🤗 すべての人のための教育 🗣️ 私たちの目標は、機械学習の可能性と限界を誰にでも理解してもらうことです。これによって、これらの技術の応用が社会全体にとって正味の利益につながる方向へ進化すると信じています。 私たちの既存の取り組みの一部の例: 私たちはMLモデルのさまざまな使い方(要約、テキスト生成、物体検出など)を非常にわかりやすく説明しています。 モデルページのウィジェットを通じて、誰でも直接ブラウザでモデルを試すことができるようにしています。そのため、それを行うための技術的なスキルの必要性を低下させています(例)。 システムで特定された有害なバイアスについてドキュメント化し、警告しています(GPT-2など)。 誰でも1クリックでMLの潜在能力を理解できるオープンソースのMLアプリを作成するためのツールを提供しています。 🤗 初心者向けの教育 🗣️ 私たちは、オンラインコース、実践的なワークショップ、その他の革新的な技術を提供することで、機械学習エンジニアになるためのハードルを下げたいと考えています。 私たちは自然言語処理(NLP)やその他のドメインについての無料コースを提供しています(近日中に)。これらのコースでは、Hugging Faceエコシステムの無料ツールやライブラリを使用して学ぶことができます。このコースの最終目標は、(ほぼ)どんな機械学習の問題にもTransformerを適用する方法を学ぶことです! 私たちはDeep Reinforcement Learningについての無料コースを提供しています。このコースでは、理論と実践でDeep…

深層強化学習の概要
Hugging FaceとのDeep Reinforcement Learningクラスの第1章 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 人工知能の最も魅力的なトピックへようこそ: Deep Reinforcement Learning(深層強化学習) Deep RLは、エージェントが行動を実行し、結果を観察することで、環境内でどのように振る舞うかを学習する機械学習の一種です。…

私たちは、オープンかつ協力的な機械学習のために1億ドルを調達しました 🚀
今日は、素晴らしいニュースをお伝えします!Hugging Faceは、Lux CapitalをリードとするシリーズCの資金調達で1億ドルを調達しました🔥🔥🔥。Sequoia、Coatue、そして既存の投資家であるAddition、a_capital、SV Angel、Betaworks、AIX Ventures、Kevin Durant、Thirty Five VenturesのRich Kleiman、Datadogの共同設立者兼CEOであるOlivier Pomelなどが主要な出資者となっています。 2018年にPyTorch BERTをオープンソース化して以来、私たちは長い道のりを歩んできましたが、まだ始まったばかりです!🙌 機械学習は、技術を構築するためのデフォルトの方法になりつつあります。1日の平均を考えてみると、機械学習はあらゆるところにあります:Zoomの背景、Googleでの検索、Uberの利用、オートコンプリート機能を使用したメールの作成など、すべてが機械学習です。 Hugging Faceは、現在最も急成長しているコミュニティであり、機械学習のための最も使用されているプラットフォームです!自然言語処理、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などのための100,000以上の事前学習モデルと10,000以上のデータセットをホストしており、Hugging Face Hubは、最先端のモデルを作成、共同作業、展開するための機械学習のホームとなっています。 10,000以上の企業がHugging Faceを使用して機械学習による技術を構築しています。彼らの機械学習科学者、データサイエンティスト、機械学習エンジニアは、私たちの製品とサービスの助けを借りて、数え切れないほどの時間を節約し、機械学習のロードマップを加速させています。 私たちはAI分野にポジティブな影響を与えたいと考えています。より責任あるAIの進展は、モデル、データセット、トレーニング手順、評価指標をオープンに共有し、問題を解決するために協力することを通じて実現されると考えています。オープンソースとオープンサイエンスは、信頼性、堅牢性、再現性、継続的なイノベーションをもたらします。これを念頭に、私たちはBigScienceをリードしています。これは、1,000人以上の研究者が集まり、非常に大きな言語モデルの研究と作成を行う協力的なワークショップです。そして、私たちは現在、世界最大のオープンソースの多言語言語モデルのトレーニングを行っています🌸 ⚠️ しかし、まだ大量の作業が残されています。 Hugging Faceでは、機械学習にはバイアス、プライバシー、エネルギー消費などの重要な制約と課題があることを認識しています。オープンさ、透明性、協力を通じて、これらの課題を緩和するための責任ある包括的な進歩、理解、および説明責任を促進することができます。…

学生アンバサダープログラムの応募受付が開始されました!
オープンソースの企業であり、機械学習の民主化を目指すHugging Faceは、世界中のさまざまなバックグラウンドを持つ人々にオープンソースの機械学習を教えることが不可欠だと考えています。 2023年までに500万人に機械学習を教えることを目指しています。 あなたは機械学習を勉強していますか、または既にコミュニティで機械学習を普及させていますか? Hugging Faceと一緒に機械学習の民主化の取り組みに参加し、キャンパスコミュニティにHugging Faceを使用したMLモデルの構築方法を紹介したいですか? もしもそうであれば、私たちはあなたの取り組みをサポートするために、初の学生アンバサダープログラムを立ち上げます 🤗 🥳 以下のことをしたい場合は、学生アンバサダープログラムは素晴らしい機会です。 仲間をサポートして彼らの機械学習の道を手助けする 無料でオープンソースの技術を学び使う 繁栄するエコシステムに貢献する コミュニティの価値観を共有しながらコミュニティを育てることに熱心である 学生アンバサダープログラムはあなたにとって絶好の機会です。応募期限は2022年6月13日までです! プログラムへの参加のメリットは何ですか? 🤩 選ばれたアンバサダーは以下のリソースとサポートを受けることができます: 🎎 コラボレーションできる仲間のネットワーク。 🧑🏻💻 Hugging Faceチームからのワークショップとサポート!…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.