Learn more about Search Results huggingface.co - Page 17

- You may be interested
- ハリソン.aiのCEOであるエンガス・トラン...
- 『AWS SageMaker Data Wranglerの新機能で...
- 「ハイパーパラメータのチューニングに関...
- Google Researchがジェネレーティブな無限...
- データサイエンスの誕生:史上初の仮説検...
- 「あなた自身のODSCウエストスケジュール...
- 「トランスフォーマーの単純化:あなたが...
- クレジットカードの取引データを使用した...
- Meet ChatGLM2-6B:オープンソースのバイ...
- 「データサイエンスをマスターするための...
- 「2023年の写真とビデオのための10のAIデ...
- ラストでクロスプラットフォームのTFIDFテ...
- 「浙江大学の研究者がUrbanGIRAFFEを提案...
- 「Googleは、ヘルスケアとライフサイエン...
- AIを使用して、自分の目で直接拡張現実(A...

どのような要素が対話エージェントを有用にするのか?
ChatGPTの技術:RLHF、IFT、CoT、レッドチーミング、およびその他 この記事は、中国語の簡体字で翻訳されています。 数週間前、ChatGPTが登場し、一連の不明瞭な頭字語(RLHF、SFT、IFT、CoTなど)が公衆の議論を巻き起こしました。これらの不明瞭な頭字語は何であり、なぜそれらが重要なのでしょうか?私たちはこれらのトピックに関する重要な論文を調査し、これらの作品を分類し、達成された成果からの要点をまとめ、まだ示されていないことを共有します。 まず、言語モデルに基づく会話エージェントの現状を見てみましょう。ChatGPTは最初ではありません。実際、OpenAIよりも前に、MetaのBlenderBot、GoogleのLaMDA、DeepMindのSparrow、およびAnthropicのAssistant(このエージェントの完璧な帰属なしでの継続的な開発はClaudeとも呼ばれています)など、多くの組織が言語モデルの対話エージェントを公開しています。一部のグループは、オープンソースのチャットボットを構築する計画を発表し、ロードマップを公開しています(LAIONのOpen Assistant)。他のグループも確実に同様の作業を進めており、まだ発表していないでしょう。 以下の表は、これらのAIチャットボットを公開アクセス、トレーニングデータ、モデルアーキテクチャ、および評価方向の詳細に基づいて比較しています。ChatGPTには文書化された情報がないため、代わりにChatGPTの基礎となったと信じられているOpenAIの指示fine-tunedモデルであるInstructGPTの詳細を共有します。 トレーニングデータ、モデル、およびファインチューニングには多くの違いがあることが観察されますが、共通点もあります。これらのチャットボットの共通の目標は、ユーザーの指示に従うことです。たとえば、ChatGPTに詩を書くように指示することなどです。 予測テキストから指示の従属へ 通常、ベースモデルの言語モデリング目標だけでは、モデルがユーザーの指示に対して有益な方法で従うことを学ぶには十分ではありません。モデル開発者は、指示の細かいチューニング(IFT)を使用して、ベースモデルを、感情、テキスト分類、要約などの古典的なNLPタスクのデモンストレーションによって微調整し、非常に多様なタスクセットにおける指示の書かれた方針を学びます。これらの指示のデモンストレーションは、指示、入力、および出力の3つの主要なコンポーネントで構成されています。入力はオプションです。一部のタスクでは、ChatGPTの例のように指示のみが必要です。入力と出力が存在する場合、インスタンスが形成されます。特定の指示に対して複数の入力と出力が存在する場合もあります。以下に[Wang et al.、’22]からの例を示します。 IFTのデータは通常、人間によって書かれた指示と言語モデルを用いた指示のインスタンスのコレクションからなります。ブートストラップのために、LMは(上記の図のように)いくつかの例を使用してフューショット設定でプロンプトされ、新しい指示、入力、および出力を生成するように指示されます。各ラウンドで、モデルは人間によって選択されたサンプルとモデルによって生成されたサンプルの両方からプロンプトを受け取ります。データセットの作成における人間とモデルの貢献の割合はスペクトラムです。以下の図を参照してください。 一方は完全にモデル生成されたIFTデータセットであり、例えばUnnatural Instructions(Honovich et al.、’22)です。もう一方は手作りの指示の大規模な共同作業であり、Super-natural instructions(Wang et al.、’22)などです。これらの間には、Self-instruct(Wang et al.、’22)のような、高品質のシードデータセットを使用してブートストラップする方法もあります。IFTのデータセットを収集するもう1つの方法は、さまざまなタスク(プロンプトを含む)の既存の高品質なクラウドソーシングNLPデータセットを統一スキーマや多様なテンプレートを使用して指示としてキャストすることです。この研究の一環には、T0(Sanh et al.、’22)、自然言語指示データセット(Mishra et…

効率的で安定した拡散微調整のためのLoRAの使用
LoRA:Large Language Modelsの低ランク適応は、Microsoftの研究者によって導入された新しい技術で、大規模言語モデルの微調整の問題に取り組むためのものです。GPT-3などの数十億のパラメータを持つ強力なモデルは、特定のタスクやドメインに適応させるために微調整することが非常に高価です。LoRAは、事前学習済みモデルの重みを凍結し、各トランスフォーマーブロックにトレーニング可能な層(ランク分解行列)を注入することを提案しています。これにより、トレーニング可能なパラメータとGPUメモリの要件が大幅に削減されます。なぜなら、ほとんどのモデルの重みの勾配を計算する必要がないからです。研究者たちは、大規模言語モデルのトランスフォーマーアテンションブロックに焦点を当てることで、LoRAと完全なモデルの微調整と同等の品質を実現できることを発見しました。さらに、LoRAはより高速で計算量が少なくなります。 DiffusersのためのLoRA 🧨 LoRAは、当初大規模言語モデルに提案され、トランスフォーマーブロック上でデモンストレーションされたものですが、この技術は他の場所でも適用することができます。Stable Diffusionの微調整の場合、LoRAは画像表現とそれらを説明するプロンプトとの関連付けを行うクロスアテンションレイヤーに適用することができます。以下の図(Stable Diffusion論文から引用)の詳細は重要ではありませんが、黄色のブロックが画像とテキスト表現の関係を構築する役割を担っていることに注意してください。 私たちの知る限りでは、Simo Ryu(@cloneofsimo)がStable Diffusionに適応したLoRAの実装を最初に考案しました。興味深いディスカッションや洞察がたくさんあるGitHubのプロジェクトをご覧いただくために、彼らのGitHubプロジェクトをぜひご覧ください。 クロスアテンションレイヤーにLoRAトレーニング可能行列を深く注入するために、以前はDiffusersのソースコードを工夫(しかし壊れやすい方法)してハックする必要がありました。Stable Diffusionが私たちに示してくれたことの一つは、コミュニティが常に創造的な目的のためにモデルを曲げて適応する方法を見つけ出すことです。クロスアテンションレイヤーを操作する柔軟性を提供することは、xFormersなどの最適化技術を採用するのが容易になるなど、他の多くの理由で有益です。Prompt-to-Promptなどの創造的なプロジェクトには、これらのレイヤーに簡単にアクセスできる方法が必要です。そのため、ユーザーがこれを行うための一般的な方法を提供することにしました。私たちは昨年12月末からそのプルリクエストをテストしており、昨日のdiffusersリリースと共に公式にローンチしました。 私たちは@cloneofsimoと協力して、Dreamboothと完全な微調整方法の両方でLoRAトレーニングサポートを提供しています!これらの技術は次の利点を提供します: 既に議論されているように、トレーニングがはるかに高速です。 計算要件が低くなります。11 GBのVRAMを持つ2080 Tiで完全な微調整モデルを作成できました! トレーニングされた重みははるかに小さくなります。元のモデルが凍結され、新しいトレーニング可能な層が注入されるため、新しい層の重みを1つのファイルとして保存できます。そのサイズは約3 MBです。これは、UNetモデルの元のサイズの約1000分の1です。 私たちは特に最後のポイントに興奮しています。ユーザーが素晴らしい微調整モデルやドリームブーストモデルを共有するためには、最終モデルの完全なコピーを共有する必要がありました。それらを試すことを望む他のユーザーは、お気に入りのUIで微調整された重みをダウンロードする必要があり、膨大なストレージとダウンロードコストがかかります。現在、Dreamboothコンセプトライブラリには約1,000のDreamboothモデルが登録されており、おそらくさらに多くのモデルがライブラリに登録されていません。 LoRAを使用することで、他の人があなたの微調整モデルを使用できるようにするためのたった1つの3.29 MBのファイルを公開することができるようになりました。 (@mishig25への感謝、普通の会話で「dreamboothing」という動詞を使った最初の人です)。…

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

ビジョン-言語モデルへのダイブ
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。 2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。 このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。 目次 はじめに 学習戦略 コントラスティブラーニング PrefixLM クロスアテンションを用いたマルチモーダル融合 MLM / ITM トレーニングなし データセット 🤗 Transformersでのビジョン言語モデルのサポート 研究の新たな展開 結論 はじめに モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか? これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。 たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。 この猫と犬の画像はここから取得しました。…

⚔️AI vs. AI⚔️は、深層強化学習マルチエージェント競技システムを紹介します
私たちは新しいツールを紹介するのを楽しみにしています: ⚔️ AI vs. AI ⚔️、深層強化学習マルチエージェント競技システム。 このツールはSpacesでホストされており、マルチエージェント競技を作成することができます。以下の3つの要素で構成されています: マッチメイキングアルゴリズムを使用してモデルの戦いをバックグラウンドタスクで実行するスペース。 結果を含むデータセット。 マッチ履歴の結果を取得し、モデルのELOを表示するリーダーボード。 ユーザーが訓練済みモデルをHubにアップロードすると、他のモデルと評価およびランキング付けされます。これにより、マルチエージェント環境で他のエージェントとの評価が可能です。 マルチエージェント競技をホストする有用なツールであるだけでなく、このツールはマルチエージェント環境での堅牢な評価技術でもあると考えています。多くのポリシーと対戦することで、エージェントは幅広い振る舞いに対して評価されます。これにより、ポリシーの品質を良く把握することができます。 最初の競技ホストであるSoccerTwos Challengeでどのように機能するか見てみましょう。 AI vs. AIはどのように機能しますか? AI vs. AIは、Hugging Faceで開発されたオープンソースのツールで、マルチエージェント環境での強化学習モデルの強さをランク付けするためのものです。 アイデアは、モデルを継続的に互いに対戦させ、その結果を使用して他のすべてのモデルと比較してパフォーマンスを評価し、ポリシーの品質を把握するための相対的なスキルの尺度を得ることです。従来のメトリクスを必要とせずに。 エージェントが特定のタスクや環境に提出される数が増えるほど、ランキングはより代表的になります。 競争環境での試合結果に基づいて評価を生成するために、私たちはELOレーティングシステムを基にランキングを作成することにしました。…

パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
動機 トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。 しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました! PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。 また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。 つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。 本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です: LoRA:LORA:大規模言語モデルの低ランク適応 Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力 P-Tuning:GPTも理解しています ユースケース ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です: Google Colabで、Nvidia GeForce RTX…
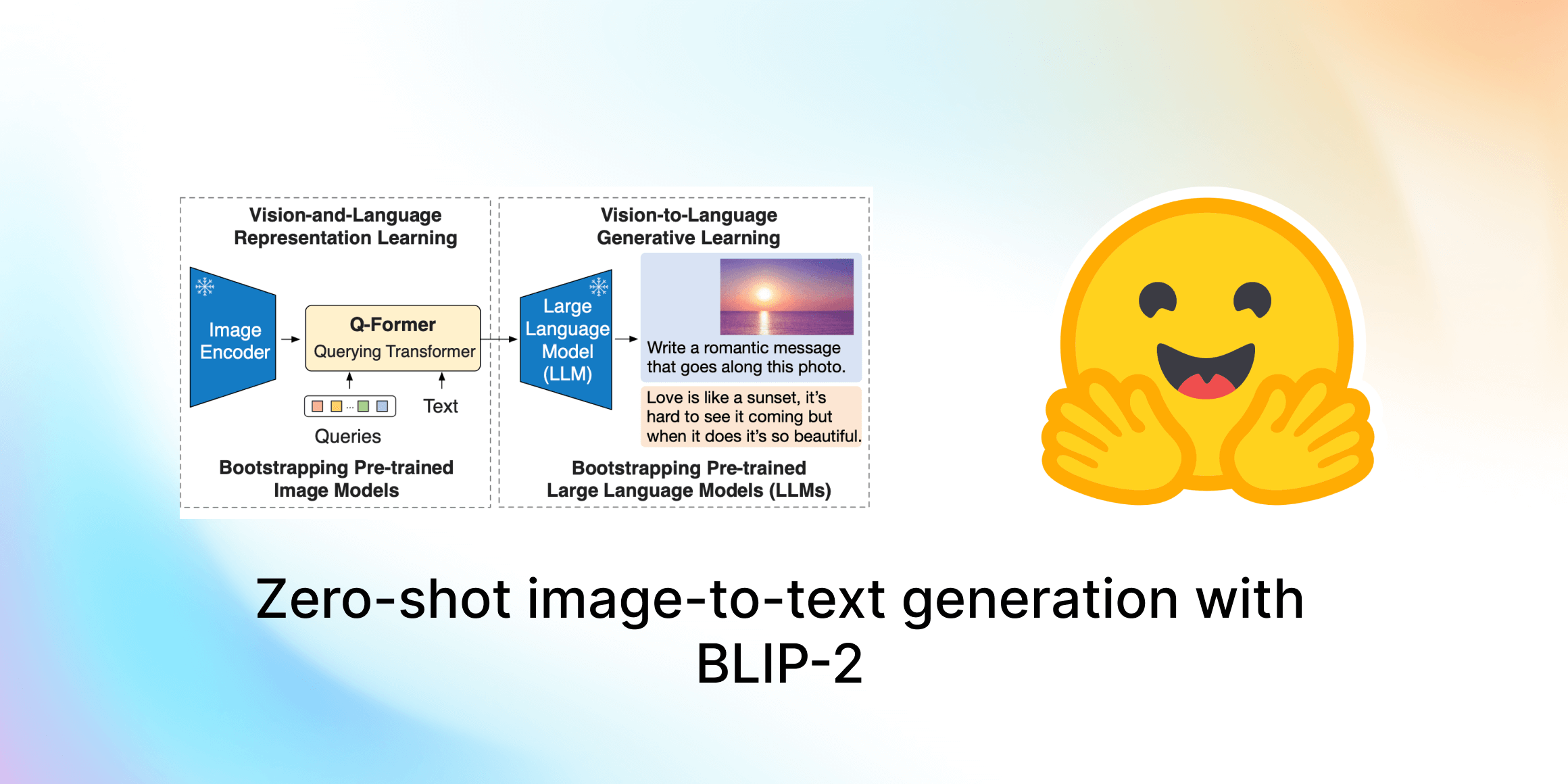
ゼロショット画像からテキスト生成 BLIP-2
このガイドでは、Salesforce ResearchのBLIP-2を紹介します。これは最先端のビジュアル言語モデルのスイートで、現在は🤗 Transformersで利用可能です。画像キャプショニング、プロンプト付き画像キャプショニング、ビジュアルな質問応答、チャットベースのプロンプトに使用する方法を紹介します。 目次 はじめに BLIP-2の内部構造は? Hugging Face TransformersでのBLIP-2の使用 画像キャプショニング プロンプト付き画像キャプショニング ビジュアルな質問応答 チャットベースのプロンプト 結論 謝辞 はじめに 近年、コンピュータビジョンと自然言語処理の分野で急速な進歩がありました。しかし、多くの現実世界の問題は本質的にマルチモーダルです。つまり、画像やテキストなど、複数の異なる形式のデータを含みます。ビジュアル言語モデルは、異なるモダリティを組み合わせることで、さまざまなアプリケーションの可能性を広げるという課題に直面しています。ビジュアル言語モデルが取り組むことができる画像からテキストへのタスクには、画像キャプショニング、画像テキスト検索、ビジュアルな質問応答などがあります。画像キャプショニングは視覚障害者の支援、有用な商品説明の作成、テキスト以外の不適切なコンテンツの特定などに役立ちます。画像テキスト検索はマルチモーダルな検索や自動運転などのアプリケーションに適用することができます。ビジュアルな質問応答は教育に役立ち、マルチモーダルなチャットボットを可能にし、さまざまなドメイン固有の情報検索アプリケーションを支援します。 現代のコンピュータビジョンと自然言語モデルは、より優れた性能を持つ一方で、以前のモデルと比べて大幅にサイズが増えています。単一のモダリティモデルの事前学習はリソースを消費し、高コストですが、ビジョンと言語のエンドツーエンドの事前学習のコストはますます高くなっています。BLIP-2は、事前学習済みのビジョンエンコーダとLLMの組み合わせを活用し、アーキテクチャ全体をエンドツーエンドで事前学習する必要なく、新しいビジュアル言語の事前学習パラダイムを導入することで、この課題に取り組んでいます。これにより、複数のビジュアル言語タスクで最先端の結果を実現しながら、訓練可能なパラメータの数と事前学習コストを大幅に削減することができます。さらに、この手法はマルチモーダルなChatGPTのモデルへの道を切り拓きます。 BLIP-2の内部構造は? BLIP-2は、既製の凍結された事前学習済み画像エンコーダと凍結された大規模言語モデルの間に、軽量なクエリングトランスフォーマ(Q-Former)を追加することで、ビジョンと言語モデルのモダリティのギャップを埋めます。Q-FormerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルは凍結されたままです。 Q-Formerは、2つのサブモジュールからなるトランスフォーマモデルであり、同じセルフアテンションレイヤを共有しています: 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。 テキストトランスフォーマは、テキストエンコーダおよびテキストデコーダとして機能することができます。 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。…

Swift 🧨ディフューザー – Mac用の高速安定拡散
Diffusers for Macを使用して、最新の拡散モデルによってテキストを美しい画像に簡単に変換できます。このネイティブアプリは、Hugging Face Hubへのコミュニティの貢献によって提供された最先端のテキストから画像へのモデルを活用し、高速なパフォーマンスのためにCore MLに変換されています。最新バージョンの1.1は、Mac App Storeで利用可能であり、パフォーマンスの大幅なアップグレードと使いやすいインターフェースの調整が行われています。これは将来の機能アップデートのための堅牢な基盤となっています。さらに、このアプリは完全にオープンソースであり、許容されるライセンスであるため、あなた自身でも構築することができます!詳細については、https://github.com/huggingface/swift-coreml-diffusers でGitHubリポジトリをご覧ください。 Diffusers for Macとは具体的には何ですか? Diffusersアプリ(App Store、ソースコード)は、Mac版の 🧨 diffusers ライブラリの対応アプリです。このライブラリはPythonとPyTorchで書かれており、モジュラーな設計を使用して拡散モデルのトレーニングと実行を行います。多くの異なるモデルとタスクをサポートし、高度に構成可能で最適化されています。Macでも実行できます。Apple Siliconでは、PyTorchの mps アクセラレータを使用します。 では、なぜネイティブのMacアプリを実行したいのでしょうか?その理由はいくつかあります: オリジナルのPyTorchモデルではなく、Core MLモデルを使用します。これは、Appleハードウェアの特定の最適化に対応する追加の最適化を可能にし、Core MLモデルはシステム内のすべての計算デバイス(CPU、GPU、ニューラルエンジン)で実行できます。PyTorchの…

大規模な言語モデルによるレッドチーミング
警告: この記事はレッドチーミングについてであり、そのためモデル生成の例が不快または不快なものである可能性があります。 大量のテキストデータで訓練された大規模な言語モデル(LLM)は、現実的なテキストを生成するのに非常に優れています。しかし、これらのモデルは、個人情報(社会保障番号など)の公開や誤情報、偏見、憎悪、有害なコンテンツの生成など、望ましくない振る舞いをしばしば示します。たとえば、GPT3の以前のバージョンは、性差別的な振る舞い(以下参照)やムスリムに対する偏見を示すことが知られていました。 LLMを使用する際にこのような望ましくない結果を発見した場合、Generative Discriminator Guided Sequence Generation(GeDi)やPlug and Play Language Models(PPLM)などの戦略を開発してそれらからそれを逸らすことができます。以下は、同じプロンプトを使用してGPT3の生成を制御するためにGeDiを使用した例です。 最近のGPT3のバージョンでも、プロンプトインジェクションによる攻撃を受けると同様に不快なテキストが生成され、その結果、下流のアプリケーションのセキュリティ上の懸念となる可能性があります。このブログで説明されています。 レッドチーミングは、望ましくない振る舞いを引き起こす可能性のあるモデルの脆弱性を引き出す評価の形式です。ジェイルブレイキングは、LLMがそのガードレールから逸脱するように操作されるレッドチーミングの別の言葉です。MicrosoftのチャットボットTay(2016年)やより最近のBingのチャットボットシドニーは、レッドチーミングを使用して基礎となるMLモデルの徹底的な評価の欠如がどれほど壊滅的な結果をもたらすかの実際の例です。レッドチームのアイデアの起源は、軍隊によって実施された対抗者シミュレーションやウォーゲームに遡ることができます。 レッドチーミングの目標は、モデルが有害なテキストを生成する可能性が高いテキストを生成するようにするプロンプトを作成することです。レッドチーミングは、MLのより一般的に知られた評価形式である敵対的攻撃といくつかの類似点と相違点を共有しています。その類似点は、レッドチーミングと敵対的攻撃が実際のユースケースで望ましくないコンテンツを生成するためにモデルを「攻撃」または「だます」という共通の目標を持っていることです。ただし、敵対的攻撃は人間には理解しにくい場合があります。たとえば、各プロンプトに「aaabbbcc」という文字列を接頭辞として付けると、モデルのパフォーマンスが低下するためです。Wallace et al.、’19では、さまざまなNLP分類および生成タスクにおけるそのような攻撃の多くの例が議論されています。一方、レッドチーミングのプロンプトは通常、通常の自然言語のプロンプトと似ています。 レッドチーミングは、ユーザーの不快な体験を引き起こしたり、悪意を持つユーザーによる暴力やその他の違法な活動を支援する可能性があるモデルの制限を明らかにすることができます。レッドチーミングからの出力(敵対的攻撃と同様)は、一般にモデルを訓練して、有害な結果を引き起こす可能性を低くするか、またはそれから逸らすために使用されます。 レッドチーミングは、可能なモデルの障害物の創造的な考えを必要とするため、リソースを消費する問題です。回避策として、与えられたプロンプトにオフェンシブな生成を引き起こす可能性のあるトピックやフレーズを予測するために訓練された分類器をLLMに追加することができます。このような戦略は慎重な方向に進むでしょう。しかし、それは非常に制限的であり、モデルを頻繁に回避的にする原因となります。したがって、モデルが役立つこと(指示に従うこと)と無害であること(少なくとも有害な行動を引き起こしにくいこと)の間には緊張があります。 レッドチームは、ハードループ内の人間または有害な出力をテストするために別のLMをテストしているLMです。安全性とアライメントのためにファインチューニングされたモデルに対してレッドチーミングプロンプトを作成するには、Ganguli et al.、’22で説明されているような悪意のあるキャラクターとして振る舞うようにLLMに指示する役割プレイ攻撃の形で創造的な思考が必要です。モデルに自然言語の代わりにコードで応答するように指示することも、モデルの学習バイアスを明らかにすることができます。 さらなる例については、このツイートスレッドをご覧ください。 ChatGPT自体によるLLMのジェイルブレイキングのアイデアのリストは次のとおりです。…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.