Learn more about Search Results Google Play - Page 17

- You may be interested
- バイデン大統領、優れたアメリカの科学者...
- 「RBIは、Conversational AIとオフライン...
- このAI研究により、チップデザインに適し...
- 拡散モデル:どのように拡散するのでしょ...
- 「ベクトル検索だけでは十分ではありません」
- 研究者たちは、より優れた熱管理のために...
- 新しいAmazon KendraのWebクローラーを使...
- 「AIサービスへの大胆な進出:億万長者ビ...
- 「Pythonでリンゴとオレンジを比較する」
- 大規模な言語モデルによるレッドチーミング
- 「日本政府、行政業務にChatGPT技術を採用...
- リーンで、意味ありげなAI夢マシン:DejaV...
- 「Pythonにおける構造化LLM出力の保存と解...
- ChatGPTと高度なプロンプトエンジニアリン...
- 大規模言語モデルを使用した要約のための...

Twitterでの感情分析を始める
センチメント分析は、テキストデータをその極性(ポジティブ、ネガティブ、ニュートラルなど)に基づいて自動的に分類するプロセスです。企業は、ツイートのセンチメント分析を活用して、顧客が自社製品やサービスについてどのように話しているかを把握し、ビジネスの意思決定に洞察を得ること、製品の問題や潜在的なPR危機を早期に特定することができます。 このガイドでは、Twitterでのセンチメント分析を始めるために必要なすべてをカバーします。コーダーと非コーダーの両方向けに、ステップバイステップのプロセスを共有します。コーダーの場合、Inference APIを使用してツイートのセンチメント分析を簡単なコード数行でスケールして行う方法を学びます。コーディング方法を知らない場合でも心配ありません!Zapierを使用してセンチメント分析を行う方法もカバーします。Zapierはツイートを収集し、Inference APIで分析し、最終的に結果をGoogle Sheetsに送信するためのノーコードツールです⚡️ 一緒に読んで興味があるセクションにジャンプしてください🌟: センチメント分析とは何ですか? コーディングを使用したTwitterセンチメント分析の方法は? コーディングを使用せずにTwitterセンチメント分析を行う方法は? 準備ができたら、楽しんでください!🤗 センチメント分析とは何ですか? センチメント分析は、機械学習を使用して人々が特定のトピックについてどのように話しているかを自動的に識別する方法です。センチメント分析の最も一般的な用途は、テキストデータの極性(つまり、ツイートや製品レビュー、サポートチケットが何かについてポジティブ、ネガティブ、またはニュートラルに話しているかを自動的に識別すること)の検出です。 例として、@Salesforceをメンションしたいくつかのツイートをチェックして、センチメント分析モデルによってどのようにタグ付けされるかを確認してみましょう: “The more I use @salesforce the more I dislike it. It’s…
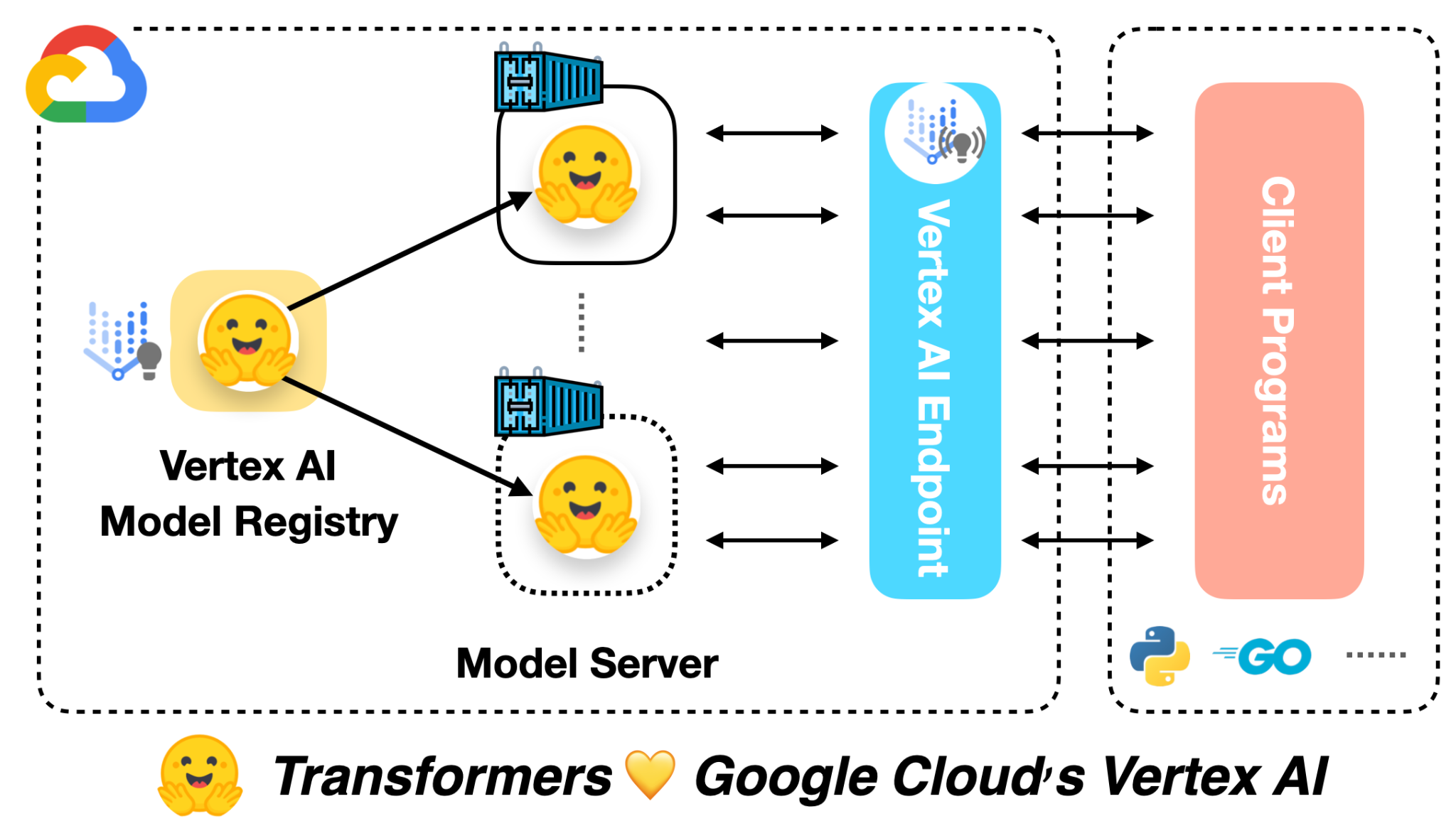
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

GPT-3がMLOpsの将来に与える意味とは?デビッド・ハーシーと共に
この記事は元々MLOps Liveのエピソードであり、ML実践者が他のML実践者からの質問に答えるインタラクティブなQ&Aセッションです各エピソードは特定のMLトピックに焦点を当てており、このエピソードではGPT-3とMLOpsの特徴についてDavid Hersheyと話しましたYouTubeで視聴することができます Or...

大規模データ分析のエンジンとしてのゲーム理論
現代のAIシステムは、画像内のオブジェクトを認識したり、タンパク質の3D構造を予測したりするタスクに取り組む際、熱心な学生が試験の準備をするようなアプローチを取ります多くの例題に基づいてトレーニングを行うことで、彼らは時間とともにミスを最小限に抑え、成功を達成しますしかし、これは孤独な取り組みであり、既知の学習の形態の一つに過ぎません学習はまた、他の人々との相互作用や遊びによっても行われます非常に複雑な問題を一人で解決できる個人は稀です問題解決をゲームのような特性で行うことにより、以前のDeepMindの取り組みではAIエージェントがCapture the Flagをプレイしたり、Starcraftでグランドマスターレベルを達成したりすることが可能になりましたこれは、ゲーム理論に基づいたこのような視点が他の基本的な機械学習の問題を解決するのに役立つのではないかと考えさせられます
もし、口頭および書面によるコミュニケーションが人間の知能を発展させたのであれば… 言語モデルは一体どうなっているのでしょうか?
人間の知能は、その非凡な認知能力によって、他の種に比べて比類のない存在ですこの知的優位性の原動力は、言語の出現に遡ることができます...
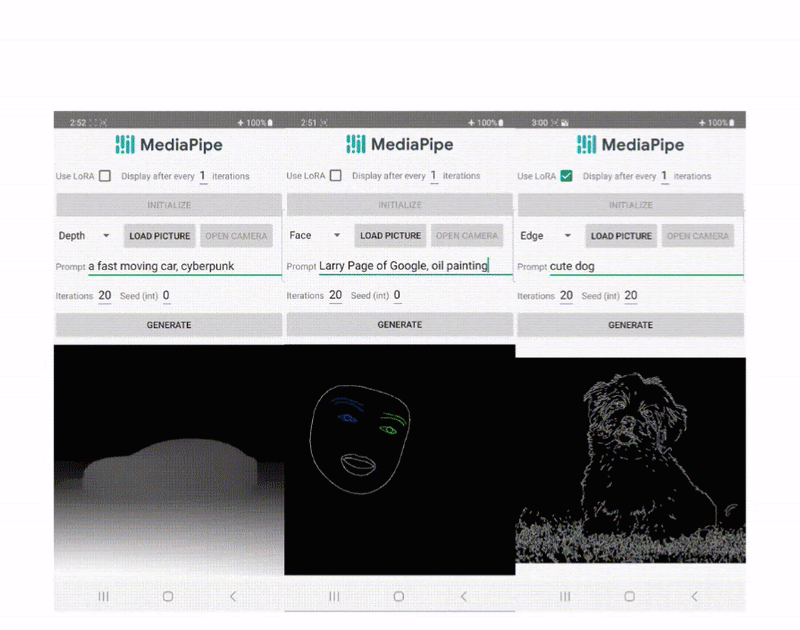
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.