Learn more about Search Results Adam - Page 17

- You may be interested
- ヒットパウ写真エンハンサーレビュー:最...
- トランスフォーマーによるOCRフリーの文書...
- 「世界最大の広告主がAIの力を受け入れる...
- スタンフォード大学とFAIR Metaの研究者が...
- データを中心に:Srikanth Velamakanniと...
- 2023年のコード生成/コーディングにおける...
- Middleware.ioは、生成AIを搭載したクラウ...
- 「PolarsによるEDA:集計と分析関数のステ...
- ダックAIは、DuckTrackを紹介します:マル...
- 「ニューラルネットワークの探索」
- バイデン大統領、優れたアメリカの科学者...
- 検索増強視覚言語事前学習
- なぜBankrateはAI生成記事を諦めたのか
- 「AIは個人の知識管理をどのように変革し...
- 「英国の選挙登録簿に対するサイバー攻撃...

Hugging FaceとFlowerを使用したフェデレーテッドラーニング
このチュートリアルでは、Hugging Faceを使用して、Flowerを介して複数のクライアント上で言語モデルのトレーニングをフェデレートする方法を紹介します。具体的には、IMDBの評価データセットを使用して、事前トレーニングされたTransformerモデル(distilBERT)をシーケンス分類のために微調整します。最終的な目標は、映画の評価がポジティブかネガティブかを検出することです。 ノートブックはこちらでご利用いただけますが、複数のクライアントで実行する代わりに、Google Colab内でフェデレーテッド環境をエミュレートするためにFlowerのシミュレーション機能(flwr['simulation'])を使用します(これはまた、start_serverを呼び出す代わりにstart_simulationを呼び出す必要があり、その他の変更が必要です)。 依存関係 このチュートリアルに従うためには、以下のパッケージをインストールする必要があります:datasets、evaluate、flwr、torch、およびtransformers。これはpipを使用して行うことができます: pip install datasets evaluate flwr torch transformers 標準的なHugging Faceのワークフロー データの処理 IMDBデータセットを取得するために、Hugging Faceのdatasetsライブラリを使用します。その後、データをトークン化し、PyTorchのデータローダーを作成する必要があります。これはすべてload_data関数で行われます: import random import torch from datasets…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...
実験追跡ツールの構築方法[Neptuneのエンジニアの学びから]
あなたのチームのMLOpsエンジニアとして、よくMLプラットフォームに機能を追加したり、データサイエンティストが利用するためのスタンドアロンツールを構築することで、彼らのワークフローを改善するように依頼されることがあります実験トラッキングはそのような機能の一つですそして、この記事を読んでいるのであれば、あなたがサポートしているデータサイエンティストはおそらく...

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...

JAXを使用して研究を加速化する
DeepMindのエンジニアは、ツールの構築、アルゴリズムのスケーリングアップ、そして人工知能(AI)システムのトレーニングとテストのための挑戦的な仮想および物理世界の作成により、私たちの研究を加速させていますこの取り組みの一環として、私たちは常に新しい機械学習ライブラリやフレームワークの評価を行っています
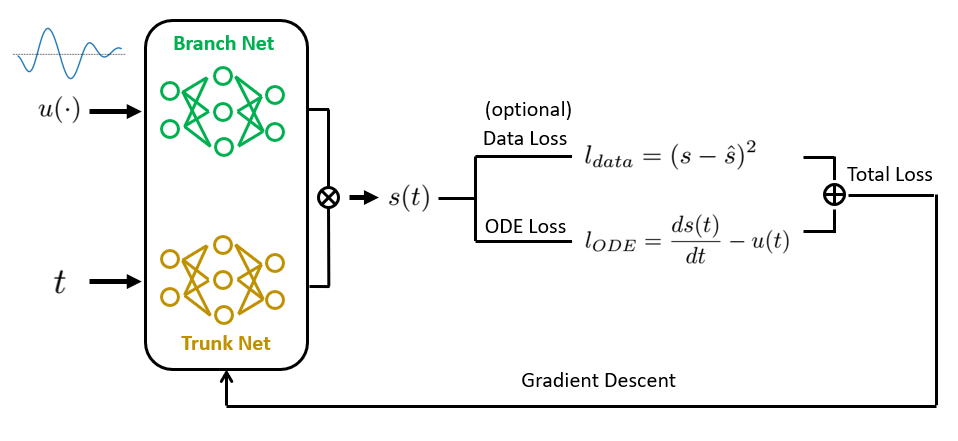
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...

ノイズ除去オートエンコーダの公開
はじめに デノイジングオートエンコーダーは、ノイズの混入したデータまたはノイズのあるデータから元のデータを再構築することを学習することで、ノイズを除去するニューラルネットワークモデルです。モデルを訓練して元のデータと再構築されたデータの差異を最小化します。これらのオートエンコーダーをスタックしてディープネットワークを形成することで、パフォーマンスを向上させることができます。 さらに、画像、音声、テキストなど、さまざまなデータ形式に対応するためにこのアーキテクチャをカスタマイズすることもできます。また、ソルトアンドペッパーやガウシアンノイズなどのノイズを自由にカスタマイズすることもできます。DAEがイメージを再構築するにつれて、入力特徴の学習を効果的に行い、潜在表現の抽出を向上させます。通常のオートエンコーダーと比較して、デノイジングオートエンコーダーは恒等関数の学習の可能性を低減させることを強調することが重要です。 学習目標 デノイジングオートエンコーダー(DAE)の概要と、ノイズの種類から元のデータを再構築することで低次元表現を得るための使用方法についての概要。 エンコーダーとデコーダーなど、DAEアーキテクチャの構成要素についても説明します。 DAEの性能を検証することで、ノイズの混入したデータから元のデータを再構築する役割について洞察を得ることができます。 さらに、デノイジング、圧縮、特徴抽出、表現学習など、DAEのさまざまな応用について考えます。イメージデノイジングを行うためのDAEの実装に焦点を当てた具体的な例として、Kerasデータセットを使用します。 この記事はData Science Blogathonの一環として公開されました。 デノイジングオートエンコーダーとは何ですか? デノイジングオートエンコーダーは、データ表現やエンコーディングの非教示学習を可能にする特定のタイプのニューラルネットワークです。主な目的は、ノイズで破損した入力信号の元のバージョンを再構築することです。この能力は、画像認識や詐欺検出などの問題で、ノイズの混入した形式から元の信号を回復することが目標となります。 オートエンコーダーは、次の2つの主要なコンポーネントで構成されています: エンコーダー:このコンポーネントは、入力データを低次元表現またはエンコーディングにマッピングします。 デコーダー:このコンポーネントは、エンコーディングを元のデータ空間に戻します。 訓練フェーズでは、オートエンコーダーにクリーンな入力例とそれに対応するノイズの混入したバージョンのセットを提供します。目的は、エンコーダー-デコーダーアーキテクチャを使用して、ノイズの入力をクリーンな出力に効率的に変換するタスクを学習することです。 DAEのアーキテクチャ デノイジングオートエンコーダー(DAE)のアーキテクチャは、標準的なオートエンコーダーと似ています。次の2つの主要なコンポーネントで構成されています: エンコーダー エンコーダーは、1つまたは複数の隠れ層を備えたニューラルネットワークを作成します。 その目的は、ノイズの入力データを受け取り、データの低次元表現であるエンコーディングを生成することです。 エンコーダーは、入力データよりも少ないパラメータを持つエンコーディングを持つ圧縮関数として理解します。 デコーダー…
ドメイン適応:事前に学習済みのNLPモデルの微調整
ドメイン適応のために事前学習済みNLPモデルの微調整方法を学びましょう特定の文脈でのパフォーマンスと精度を向上させますステップバイステップのガイドと実践的な例を提供します
7月号 データサイエンティストのための気候リソース
多くの人にとって、夏の訪れは以前は単純な興奮の原因でした:学校が終わる、仕事のスケジュールは少し忙しくないことが多い、ビーチでののんびりした午後や...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.