Learn more about Search Results で見る - Page 17

- You may be interested
- GPTモデルを活用して、自然言語をSQLクエ...
- 「ジェンAIができることとできないことの5...
- 倫理と社会のニュースレター#1
- 「アメリカで最も優れた5つのデータサイエ...
- NexusRaven-V2をご紹介します:13B LLMは...
- 「人工的な汎用知能(Artificial General ...
- 自律運転アプリケーションのための基本的...
- AIが使われて新しいビートルズの最後の曲...
- 「世界最小のデータパイプラインフレーム...
- 「あなたの顔は近々、あなたのチケットと...
- 「ディープダブのAIによる、ハリウッドか...
- クエリ駆動型データモデリングとは何ですか?
- 他人のPythonコードを簡単に理解する方法は?
- 「Jasper AI vs Copy AI:どちらのAIライ...
- 中国のこのAI論文は、ダイナミックなSLAM...
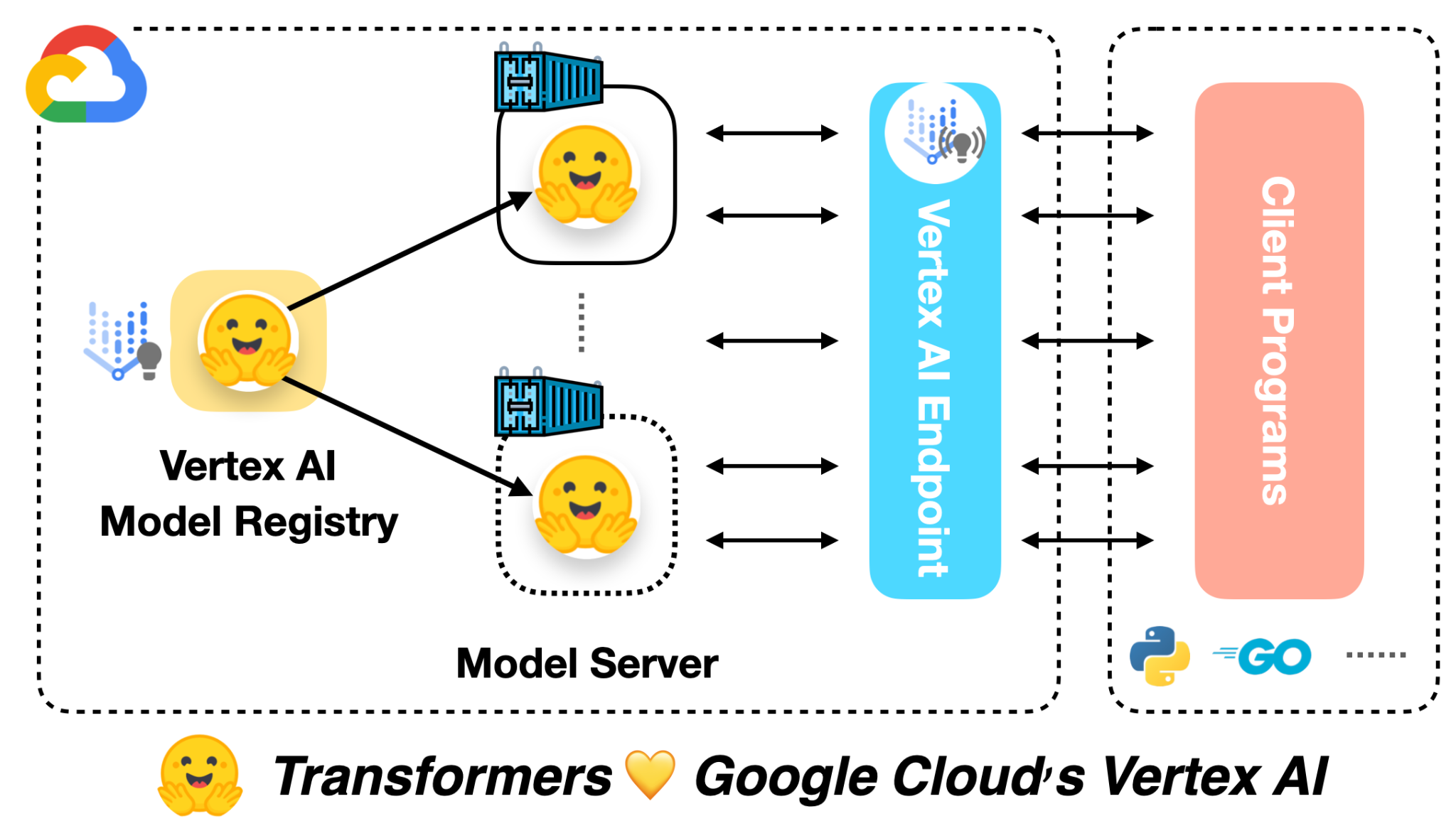
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…

倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ
ミッション:オープンで良い機械学習 私たちのミッションは、良い機械学習(ML)を民主化することです。MLコミュニティの活動を支援することで、潜在的な害の検証と予防も可能になります。オープンな開発と科学は、権力を分散させ、多くの人々が自分たちのニーズと価値観を反映したAIに共同で取り組むことができるようにします。オープンさは研究とAI全体に広範な視点を提供する一方で、リスクコントロールの少ない状況に直面します。 MLアーティファクトのモデレーションには、これらのシステムのダイナミックで急速に進化する性質による独自の課題があります。実際、MLモデルがより高度になり、ますます多様なコンテンツを生成する能力を持つようになると、有害なまたは意図しない出力の可能性も増大し、堅牢なモデレーションと評価戦略の開発が必要になります。さらに、MLモデルの複雑さと処理するデータの膨大さは、潜在的なバイアスや倫理的な懸念を特定し対処する課題を悪化させます。 ホストとして、私たちはユーザーや世界全体に対して潜在的な害を拡大する責任を認識しています。これらの害は、特定の文脈に依存して少数派コミュニティに不公平に影響を与えることが多いです。私たちは、各文脈でプレイしている緊張関係を分析し、会社とHugging Faceコミュニティ全体で議論するアプローチを取っています。多くのモデルが害を増幅する可能性がありますが、特に差別的なコンテンツを含む場合、最もリスクの高いモデルを特定し、どのような対策を取るべきかを判断するための一連の手順を踏んでいます。重要なのは、さまざまなバックグラウンドを持つアクティブな視点が、異なる人々のグループに影響を与える潜在的な害を理解し、測定し、緩和するために不可欠であるということです。 私たちは、オープンソースの科学が個人を力付け、潜在的な害を最小限に抑えるために、ツールや保護策を作成するとともに、ドキュメンテーションの実践を改善しています。 倫理的なカテゴリ 私たちの仕事の最初の重要な側面は、価値観とステークホルダーへの配慮を優先するML開発のツールとポジティブな例を促進することです。これにより、ユーザーは具体的な手順を踏むことで未解決の問題に対処し、ML開発の標準的な実践に代わる可能性のある選択肢を提示することができます。 ユーザーが倫理に関連するMLの取り組みを発見し、関わるために、私たちは一連のタグを編纂しました。これらの6つの高レベルのカテゴリは、コミュニティメンバーが貢献したスペースの分析に基づいています。これらは、倫理的な技術について無専門用語の方法で考えるための設計されています: 厳密な作業は、ベストプラクティスを考慮して開発することに特に注意を払います。MLでは、これは失敗事例の検証(バイアスや公正性の監査を含む)、セキュリティ対策によるプライバシーの保護、および潜在的なユーザー(技術的および非技術的なユーザー)がプロジェクトの制約について知らされることを意味します。 コンセントフルな作業は、これらの技術を使用し、影響を受ける人々の自己決定を支援します。 社会的に意識の高い作業は、技術が社会、環境、科学の取り組みを支援する方法を示しています。 持続可能な作業は、機械学習を生態学的に持続可能にするための技術を強調し、探求します。 包括的な作業は、機械学習の世界でビルドし、利益を享受する人々の範囲を広げます。 探求的な作業は、コミュニティに技術との関係を再考させる不公正さと権力構造に光を当てます。 詳細はhttps://huggingface.co/ethicsをご覧ください。 これらの用語を探してください。新しいプロジェクトで、コミュニティの貢献に基づいてこれらのタグを使用し、更新していきます! セーフガード オープンリリースを「全てか無し」の視点で見ることは、MLアーティファクトのポジティブまたはネガティブな影響を決定する広範な文脈の多様性を無視しています。MLシステムの共有と再利用の方法に対するより多くの制御レバーがあることで、有害な使用や誤用を促進するリスクを減らすことができ、共同開発と分析をサポートします。よりオープンでイノベーションに参加できる環境を提供します。 私たちは、直接貢献者と関わり、緊急の問題に対処してきました。さらに進めるために、私たちはコミュニティベースのプロセスを構築しています。このアプローチにより、Hugging Faceの貢献者と貢献に影響を受ける人々の両方が、プラットフォームで利用可能なモデルとデータに関して制限、共有、追加のメカニズムについて情報提供することができます。私たちは、アーティファクトの起源、開発者によるアーティファクトの取り扱い、アーティファクトの使用状況について特に注意を払います。具体的には、次のような取り組みを行っています: コミュニティがMLアーティファクトやコミュニティコンテンツ(モデル、データセット、スペース、または議論)がコンテンツガイドラインに違反しているかどうかを判断するためのフラッグ機能を導入しました。 ハブのユーザーが行動規範に従っているかを確認するために、コミュニティのディスカッションボードを監視しています。 最もダウンロードされたモデルについて、社会的な影響やバイアス、意図された使用法と範囲外の使用法を詳細に説明するモデルカードを堅牢に文書化しています。…

アシストされた生成:低遅延テキスト生成への新たな方向
大規模な言語モデルは最近注目を集めており、多くの企業がそれらを拡大し、新たな機能を開放するために多大なリソースを投資しています。しかし、私たち人間は注意力が減少しているため、彼らの遅い応答時間も嫌いです。レイテンシは良好なユーザーエクスペリエンスにおいて重要であり、低品質なものである場合でも(たとえば、コード補完において)小さいモデルが使用されることがよくあります。 なぜテキスト生成は遅いのでしょうか?破産せずに低レイテンシな大規模な言語モデルを展開する障害物は何でしょうか?このブログ記事では、自己回帰的なテキスト生成のボトルネックを再検討し、レイテンシの問題に対処するための新しいデコーディング手法を紹介します。私たちの新しい手法であるアシスト付き生成を使用することで、コモディティハードウェアでレイテンシを最大10倍まで削減できることがわかります! テキスト生成のレイテンシの理解 現代のテキスト生成の核心は理解しやすいです。中心となる部分であるMLモデルを見てみましょう。その入力には、これまでに生成されたテキストや、モデル固有のコンポーネント(Whisperのようなオーディオ入力もあります)など、テキストシーケンスが含まれます。モデルは入力を受け取り、順番に各層を通って次のトークンの非正規化された対数確率(ログット)を予測します。トークンは、モデルによって単語全体、サブワード、または個々の文字で構成されることがあります。テキスト生成のこの部分について詳しく知りたい場合は、イラスト付きのGPT-2を参照してください。 モデルの順方向パスによって次のトークンのログットが得られますが、これらのログットを自由に操作することができます(たとえば、望ましくない単語やシーケンスの確率を0に設定する)。テキスト生成の次のステップは、これらのログットから次のトークンを選択することです。一般的な戦略は、最も可能性の高いトークンを選ぶことで、これはグリーディデコーディングとして知られています。また、トークンの分布からサンプリングすることも行います。モデルの順方向パスと次のトークンの選択を反復的に連結することで、テキスト生成が行われます。デコーディング手法に関しては、この説明はアイスバーグの一角に過ぎません。詳細な探求のために、テキスト生成に関する当社のブログ記事を参照してください。 上記の説明から、テキスト生成のレイテンシのボトルネックは明確です。大規模なモデルの順方向パスを実行することは遅いため、連続して何百回も実行する必要があります。しかし、さらに詳しく見てみましょう。なぜ順方向パスが遅いのでしょうか?順方向パスは通常、行列の乗算によって支配されます。対応するウィキペディアのセクションを素早く訪れると、この操作における制限はメモリ帯域幅であることがわかります(たとえば、GPU RAMからGPUコンピュートコアへ)。つまり、順方向パスのボトルネックは、デバイスの計算コアにモデルのレイヤーの重みを読み込むことから来ており、計算自体ではありません。 現時点では、テキスト生成の最大の効果を得るために探求できる3つの主な方法がありますが、すべてがモデルの順方向パスのパフォーマンスに対処しています。まず第一に、ハードウェア固有のモデルの最適化があります。たとえば、デバイスがFlash Attentionに対応している場合、操作の並べ替えによってアテンションレイヤーの処理を高速化することができます。また、モデルのウェイトのサイズを削減するINT8量子化もあります。 第二に、同時にテキスト生成のリクエストがあることがわかっている場合、入力をバッチ化し、小さなレイテンシのペナルティを支払いながらスループットを大幅に増加させることができます。デバイスに読み込まれたモデルのレイヤーのウェイトは、複数の入力行で並列に使用されるため、ほぼ同じメモリ帯域幅の負荷でより多くのトークンを出力することができます。バッチ処理の問題は、追加のデバイスメモリが必要であることです(またはメモリをどこかにオフロードする必要があります)-このスペクトルの終端では、レイテンシを犠牲にしてスループットを最適化するFlexGenなどのプロジェクトが見られます。 # バッチ化された生成の影響を示す例。計測デバイス: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model…

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

データサイエンスの求人探し:就職への道を導いてくれた5冊の本
大変だとわかっています!この困難な時期において、私たちは大きな苦難に直面していることは否定できませんCNNの2023年の解雇追跡データは、現在の状況を鮮明に示しています...
実験追跡ツールの構築方法[Neptuneのエンジニアの学びから]
あなたのチームのMLOpsエンジニアとして、よくMLプラットフォームに機能を追加したり、データサイエンティストが利用するためのスタンドアロンツールを構築することで、彼らのワークフローを改善するように依頼されることがあります実験トラッキングはそのような機能の一つですそして、この記事を読んでいるのであれば、あなたがサポートしているデータサイエンティストはおそらく...

MLモデルの最適化とデバッグにSHAP値を使用する方法
こんな状況を想像してください数え切れないほどの時間を費やして、モデルのトレーニングと微調整に取り組み、山ほどのデータを入念に分析しましたしかし、予測に影響を与える要因に明確な理解が欠けており、その結果、さらに改善することが難しいと感じていますもし過去にこうした状況に陥ったことがあるなら、…

FermiNet(フェルミネット):第一原理に基づく量子物理学と化学
最近Physical Review Researchに掲載された論文では、ディープラーニングが現実世界のシステムの量子力学の基礎方程式を解くのにどのように役立つかを示していますこれは重要な基礎科学的な問題だけでなく、将来的には実用的な用途につながる可能性がありますこれにより、研究者は実験室で作る前に、シリコン上で新しい材料や化学合成を試作することができます本日、この研究からのコードも公開される予定ですこれにより、計算物理学や化学のコミュニティは私たちの研究を基にさまざまな問題に応用することができます私たちは、大きな電子の集合体である化学結合の量子状態をモデル化するのに適した新しいニューラルネットワークアーキテクチャ、Fermionic Neural NetworkまたはFermiNetを開発しましたFermiNetは、原子や分子のエネルギーを最初の原理から計算するためのディープラーニングの最初のデモンストレーションであり、これまでで最も正確なニューラルネットワーク手法ですDeepMindのAI研究で開発されたツールやアイデアが自然科学の基本的な問題の解決に役立ち、FermiNetはタンパク質の折りたたみ、ガラス状のダイナミクス、格子量子色力学などのプロジェクトとともに、そのビジョンを実現するための取り組みに加わります

スケールにおける言語モデリング:Gopher、倫理的考慮事項、および情報の検索
言語とその役割は、人間であることの基本的な要素であり、理解や知性を示すことと促進することにおいて重要ですそれは人々に思考や概念を伝え、アイデアを表現し、記憶を創り、相互理解を築く能力を与えますこれらは社会的知性の基盤的な要素ですDeepMindのチームは、言語処理とコミュニケーションの側面を人工エージェントと人間の両方で研究しているのはそのためです
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.