Learn more about Search Results お知らせ - Page 17

- You may be interested
- 🤗変換器を使用した確率的な時系列予測
- 弁護士には、ChatGPTを使用したことについ...
- NVIDIA NeMoを使ったスタートアップが生成...
- アデプトAIラボは、Persimmon-8Bという強...
- このAI論文では、マルチビューの冗長性を...
- 情報とエントロピー
- Google Gemini APIを使用してLLMモデルを...
- 「2023年の機械学習モデルにおけるトップ...
- 最近の人類学的研究によれば、クロード2.1...
- 「AIが秘密のメッセージをミームに隠し込...
- 「ChatGPTのリリースはオープンデータの生...
- フォトグラメトリとは何ですか?
- XGBoost 最終ガイド(パート1)
- 「学生が手頃な価格で使える消防ロボット...
- ChatGPTのためのエニグマ:PUMAは、LLM推...
Hugging Faceがフランスのデータ保護機関の強化サポートプログラムに選ばれました
このブログ投稿は元々LinkedInで2023年05月15日に公開されました。 お知らせです。Hugging Faceは、CNIL(フランスのデータ保護機関)によってそのエンハンストサポートプログラムの対象に選ばれました!この新しいプログラムは、40社以上の候補者の中から「経済的発展の強いポテンシャルを持つ」と評価された3社を選出し、データ保護に関する義務の理解と実装においてサポートを受けることができます。このようなサポートは、急速に進化する人工知能の分野において、データ保護に関する困難で必要不可欠な取り組みです。 個人のプライバシー権を尊重するという点では、機械学習と人工知能の最近の進展は新たな問題を提起し、新たな課題をもたらしています。Hugging Faceの取り組みや協力関係において、これらの課題に特に敏感であることを認識しています。私たちが主催するBigScienceワークショップは、多くの異なる国や機関からの数百人の研究者との協力により、データ選択とガバナンス、データ処理、モデル共有をカバーした、プライバシーを中心に置いた初の大規模な言語モデルトレーニングの取り組みでした。また、ServiceNowと共同主催した最近のBigCodeプロジェクトも、プライバシーのリスクに対処するための重要なリソースを割り当て、他のプロジェクトにも恩恵をもたらす擬名化をサポートする新しいツールの開発に注力しました。これらの取り組みにより、AI開発プロセスのさまざまなレベルで技術的に必要で実現可能なことをより良く理解し、個人データに関連する法的要件とリスクに対処することができます。 CNILからの支援プログラムは、フランスのデータ保護機関としての専門知識と役割を活かし、GDPRの順守を前進させるための私たちの広範な取り組みをサポートする上で重要な役割を果たします。また、プライバシーやデータ保護に関するユーザーコミュニティの質問に対して明確な回答を提供することも期待しています。より先見の目を持ってこれらの問題に取り組み、個人のデータ権利を尊重する素晴らしい新しい機械学習技術の開発に貢献できることを楽しみにしています!

オープンソースAIゲームジャムを発表します 🎮
AIツールを活用して創造力を解放し、週末にゲームを作ろう! 世界初のオープンソースAIゲームジャムをお知らせできることを大変嬉しく思います。このゲームジャムでは、AIツールを使用してゲームを作成します。 AIの可能性によって、ゲームの体験やワークフローが向上することに期待しています。例えば、Stable Diffusionなどの生成型AIツールをゲームやワークフローに取り入れて、新しい機能を開放し、開発プロセスを加速させることができます。 テクスチャ生成からリアルなNPC、現実的なテキスト読み上げまで、選択肢は無限です。 📆 ゲームジャムは7月7日から9日の金曜日から日曜日まで開催されます。 ゲームジャムの無料参加枠を確保しましょう 👉 https://itch.io/jam/open-source-ai-game-jam なぜこのイベントを開催しているのか 一部の人気ゲームジャムがAIツールの使用を制限している時代に、私たちはゲーム開発者がAIが提供する信じられない可能性を紹介するために、特にオープンで透明性のある利用可能なプラットフォームを提供することが重要だと考えています。 私たちはこれらのジャムが繁栄し、インディーゲーム開発者が生産性を向上させ、その可能性を最大限に引き出すためのツールを持つことを望んでいます。 AIツールとは何ですか 特にStable Diffusionなどの生成型AIツールは、ゲーム開発において全く新しい可能性を開拓します。 加速されたワークフローからゲーム内の機能まで、AIの力を使ってテクスチャ生成、リアルなAI非プレイヤーキャラクター(NPC)、現実的なテキスト読み上げ機能を活用することができます。 ゲームジャムの無料参加枠を確保しましょう 👉 https://itch.io/jam/open-source-ai-game-jam 誰が参加できますか オープンソースAIゲームジャムには、スキルレベルや場所に関係なく、誰でも参加できます。 一人で参加することも、任意の人数でチームを組むこともできます。 参加に必要なものは何ですか…

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…

Hugging FaceとAMDは、CPUおよびGPUプラットフォーム向けの最先端モデルの高速化に関するパートナーシップを結んでいます
言語モデル、大規模な言語モデル、または基盤モデル、トランスフォーマーは、事前学習、微調整、および推論において大量の計算を必要とします。Hugging Faceは、開発者や組織が最大のパフォーマンスを得るために、ハードウェア企業と協力して、各チップのアクセラレーション機能を活用してきました。 本日、私たちはAMDが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。私たちのCEOであるClement Delangueが、サンフランシスコで行われたAMDのデータセンターおよびAIテクノロジープレミアで基調講演を行い、このエキサイティングな新しい協力関係を発表しました。 AMDとHugging Faceは、AMDのCPUおよびGPU上で最先端のトランスフォーマーパフォーマンスを提供するために協力しています。このパートナーシップは、Hugging Faceコミュニティ全体にとって非常に良いニュースであり、近々、最新のAMDプラットフォームをトレーニングおよび推論に活用することができるようになります。 長年にわたり、ディープラーニングハードウェアの選択肢は限られており、価格と供給は懸念事項となっています。この新しいパートナーシップは、競争に対抗するだけでなく、市場の動向を緩和するのに役立ちます。さらに、新しいコストパフォーマンスの基準を設定することも期待されます。 サポートされるハードウェアプラットフォーム GPU側では、AMDとHugging Faceはまず、エンタープライズグレードのInstinct MI2xxおよびMI3xxファミリー、次に、カスタマーグレードのRadeon Navi3xファミリーで協力します。AMDの最近のテストでは、MI250が直接競合他社よりもBERT-Largeを1.2倍、GPT2-Largeを1.4倍高速にトレーニングすることを報告しています。 CPU側では、両社はクライアントRyzenおよびサーバーEPYC CPUの推論の最適化に取り組みます。いくつかの以前の投稿で議論したように、CPUはトランスフォーマーの推論において優れたオプションになり得ます。特に、量子化などのモデル圧縮技術と組み合わせた場合です。 最後に、この協力関係には、低い電力要件で驚異的なパフォーマンスを発揮するAlveo V70 AIアクセラレータも含まれます。 サポートされるモデルアーキテクチャとフレームワーク 私たちは、自然言語処理、コンピュータビジョン、音声などの最先端のトランスフォーマーアーキテクチャ(BERT、DistilBERT、ROBERTA、Vision Transformer、CLIP、Wav2Vec2など)をサポートする予定です。もちろん、生成型AIモデル(GPT2、GPT-NeoX、T5、OPT、LLaMAなど)、私たち自身のBLOOMおよびStarCoderモデルも利用可能です。最後に、ResNetやResNextのようなより伝統的なコンピュータビジョンモデル、そして深層学習の推薦モデルにも初めて対応します。 これらのモデルをPyTorch、TensorFlow、およびONNX Runtime向けに上記のプラットフォームでテストおよび検証するために最善を尽くします。すべてのモデルが、すべてのフレームワークまたはすべてのハードウェアプラットフォームでトレーニングおよび推論に利用可能であるわけではないことを覚えておいてください。 今後の展望…

SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
ChatGPTや他のLLM(Language Model)を使用してSQLクエリを生成しようとしたことがある方は手を挙げてください私は試してみましたし、現在も試しています!しかし、新しいオープンソースのファミリーが登場したことをお伝えできるのがとても嬉しいです...

高度なグラフニューラルネットワークを使用した交通予測
Googleと提携することで、DeepMindはAIの恩恵を世界中の数十億の人々にもたらすことができます言語障害を持つユーザーが元の声を取り戻すことから、ユーザーが個別のアプリを発見する手助けまで、私たちはGoogleのスケールで画期的な研究を即座に現実の問題に適用することができます今日、私たちは最新のパートナーシップの結果を共有できることを喜んでお知らせしますこれにより、Google Mapsを利用する10億人以上に真にグローバルな影響をもたらします

アルファフォールドの力を世界の手に
昨年12月にAlphaFold 2を発表した際、それは50年間のタンパク質折りたたみ問題の解決策として称賛されました先週、私たちはこの非常に革新的なシステムを作成する方法についての科学論文とソースコードを公開しましたそして、本日は人体のすべてのタンパク質の形状に関する高品質な予測を共有していますさらに、科学者が研究に頼る20の追加の生物のタンパク質の形状についても予測を行っています
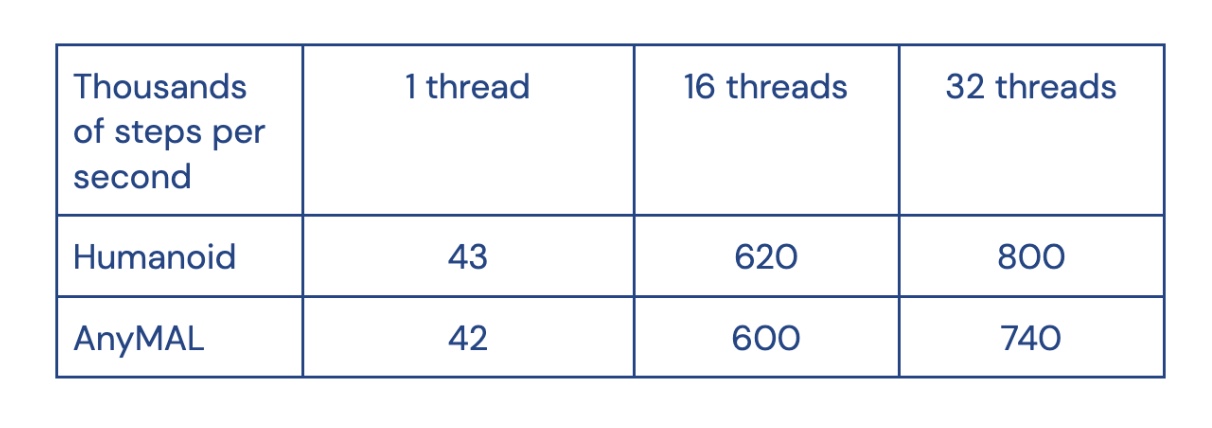
MuJoCoをオープンソース化
2021年10月、私たちはMuJoCo物理シミュレータを取得し、研究をサポートするために誰でも自由に利用できるようにしましたことを発表しましたまた、MuJoCoを最高水準の能力を持つフリーでオープンソースのコミュニティ主導のプロジェクトとして開発・維持することを約束しました本日、喜ばしいお知らせですが、オープンソース化が完了し、コードベース全体がGitHub上にあります!ここでは、なぜMuJoCoがオープンソースの協力プラットフォームとして優れているのかを説明し、今後のロードマップのプレビューを共有します
OpenAIのモデレーションAPIを使用してコンテンツのモデレーションを強化する
プロンプトエンジニアリングの台頭や、言語モデルの大規模な成果により、私たちの問いに対する応答を生成する際の大変な成果を上げたLarge Language Modelsの注目すべき成果により、ChatGPTのようなチャットボットは私たちの日常生活の重要な一部となりつつあります...
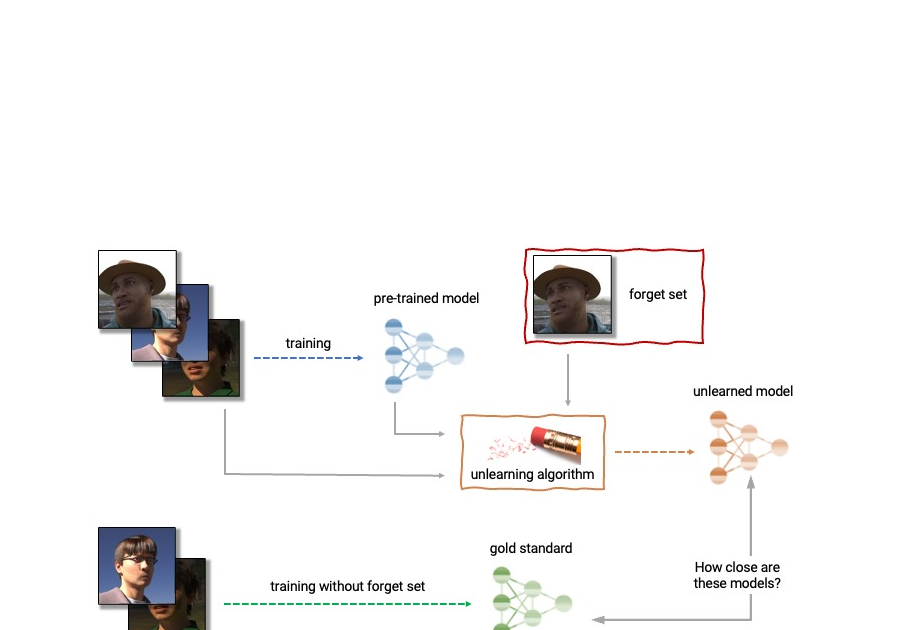
最初のマシンアンラーニングチャレンジを発表します
Googleの研究科学者であるFabian PedregosaとEleni Triantafillouによって投稿されました。 深層学習は最近、現実的な画像生成や印象的な検索システムから、人間のように会話をすることができる言語モデルまで、さまざまなアプリケーションで大きな進歩を遂げています。この進歩は非常に興味深いものですが、深層ニューラルネットワークモデルの広範な使用には注意が必要です。GoogleのAI原則に従って、私たちはフェアなバイアスの伝播と増幅、ユーザーのプライバシーの保護などの潜在的なリスクを理解し、軽減することにより、責任を持ってAI技術を開発することを目指しています。 削除されるデータの影響を完全に消去することは難しいです。データが保存されているデータベースから単純に削除するだけでなく、そのデータがトレーニングされた機械学習モデルに与える影響も消去する必要があります。さらに、最近の研究 [1, 2] は、メンバーシップ推論攻撃(MIA)を使用して、例が機械学習モデルのトレーニングに使用されたかどうかを非常に高い精度で推論することが可能であることを示しています。これはプライバシー上の懸念を引き起こす可能性があります。つまり、個人のデータがデータベースから削除されたとしても、その個人のデータがモデルのトレーニングに使用されたかどうかを推測することができる可能性があるということです。 上記の理由から、機械学習のサブフィールドである機械アンラーニングは、トレーニング例の特定のサブセットである「忘れるセット」の影響をトレーニング済みのモデルから除去することを目指しています。さらに、理想的なアンラーニングアルゴリズムは、特定の例の影響を除去する一方で、トレーニングセットの残りの部分における精度と保持例への一般化など、他の有益な特性を維持することができるようになっています。このアンラーニングされたモデルを生成するための直接的な方法は、忘れるセットのサンプルを除外した調整されたトレーニングセットでモデルを再トレーニングすることです。しかし、これは常に実行可能なオプションではありません。なぜなら、深層モデルの再トレーニングは計算コストが高いからです。理想的なアンラーニングアルゴリズムは、既にトレーニングされたモデルを出発点として使用し、要求されたデータの影響を効率的に除去するために調整を行うことができるでしょう。 今日、私たちは幅広い学術研究者と産業研究者のグループと協力して、初のマシンアンラーニングチャレンジを開催することを発表できて大変嬉しく思っています。このコンテストは、トレーニング後に特定のトレーニングイメージのサブセットを忘れる必要がある現実的なシナリオを考慮しています。コンテストはKaggleで開催され、忘れる品質とモデルの有用性の両方に関して自動的にスコアリングされます。このコンテストがマシンアンラーニングの最先端の技術の発展に貢献し、効率的で効果的かつ倫理的なアンラーニングアルゴリズムの開発を促進することを願っています。 マシンアンラーニングの応用 マシンアンラーニングは、ユーザーのプライバシー保護以外にも応用があります。例えば、トレーニングされたモデルから不正確な情報や古い情報を消去するためにアンラーニングを使用することができます(例えば、ラベリングのエラーや環境の変化によるもの)。また、有害な、操作された、または外れ値のデータを削除することもできます。 機械アンラーニングの分野は、ディファレンシャルプライバシーやライフロングラーニング、フェアネスなどの機械学習の他の分野と関連しています。ディファレンシャルプライバシーは、特定のトレーニング例がトレーニングされたモデルに与える影響が大きすぎないことを保証することを目指しています。これはアンラーニングの目標と比較して強い目標です。ライフロングラーニングの研究は、以前に習得したスキルを維持しながら連続的に学習できるモデルを設計することを目指しています。アンラーニングの研究が進展するにつれて、不公正なバイアスや異なるグループ(人口統計、年齢層など)のメンバーへの不公平な扱いを修正することによって、モデルのフェアネスを向上させる追加の方法も開かれるかもしれません。 アンラーニングの解剖学。アンラーニングアルゴリズムは、事前にトレーニングされたモデルとトレーニングセットから1つ以上のサンプル(「忘れるセット」)を入力として受け取ります。アンラーニングアルゴリズムは、モデル、忘れるセット、保持セットから更新されたモデルを生成します。理想的なアンラーニングアルゴリズムは、忘れるセットなしでトレーニングされたモデルと区別できないモデルを生成します。 機械のアンラーニングの課題 アンラーニングの問題は複雑で多面的であり、いくつかの相反する目標を含んでいます。要求されたデータを忘れること、モデルの有用性(保持および保留データの正確さ)を維持すること、効率性を維持することなどです。そのため、既存のアンラーニングのアルゴリズムは異なるトレードオフを行います。たとえば、完全な再学習はモデルの有用性を損なうことなく忘却を達成しますが、効率は低くなります。一方、重みにノイズを追加することで、有用性を犠牲にして忘却を達成します。 さらに、文献での忘却アルゴリズムの評価はこれまでに非常に一貫性がありませんでした。一部の研究では、忘れるサンプルの分類精度を報告しているものもありますが、他の研究では完全再学習モデルへの距離やメンバーシップ推論攻撃のエラーレートなど、忘却の品質を評価するための指標が異なります [4, 5, 6]。 私たちは、評価指標の一貫性の欠如と標準化されたプロトコルの欠如が、この分野の進歩に深刻な障害であると考えています。文献中の異なるアンラーニング手法を直接比較することができません。これにより、異なるアプローチの相対的な利点と欠点、および改良されたアルゴリズムの開発のためのオープンな課題と機会に対する狭い視野に取り残されます。このような評価の一貫性の問題に対処し、機械のアンラーニングの最先端を推進するために、私たちは広範な学術および産業の研究者グループと協力して、最初のアンラーニングチャレンジを開催することにしました。 最初のマシンアンラーニングチャレンジの発表 NeurIPS 2023…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.