Learn more about Search Results - Page 17

- You may be interested
- 「Nous-Hermes-Llama2-70bを紹介します:3...
- Mistral-7B-v0.1をご紹介します:新しい大...
- 「AIは本当に面接に合格するのを助けてく...
- 元アップル社員が生成型AIをデスクトップ...
- 小さなメモリに大きな言語モデルを適合さ...
- 「Googleは、データの不適切な使用によるL...
- 「AIの透明性を解き放つ:Anthropicのフィ...
- 「MLCommonsがAIモデルを実行するための新...
- 良いニュース!中国とアメリカがAIの危険...
- ローカルLLM推論を10倍速く実行する(244 ...
- 「SQLで移動平均と累積合計をマスターする...
- ChatGPT の機能 観察、ヒント、およびトリ...
- プリンストンの研究者が、構造化プルーニ...
- モデルオプスとは何ですか?
- 文書解析の革命:階層構造抽出のための最...

シンプルな人々が派手なニューラルネットワークを構築するための簡単な考慮事項
写真提供:Henry & Co. (Unsplash) 機械学習が産業のあらゆる分野に浸透するにつれて、ニューラルネットワークの注目度はこれまでにないほど高まっています。たとえば、GPT-3などのモデルは過去数週間でソーシャルメディア上で話題となり、テックニュース以外のメディアでも恐怖心を煽る見出しを掲載されています。 一方で、ディープラーニングのフレームワーク、ツール、特化したライブラリにより、最先端の研究を利用した研究がこれまで以上に簡単に行えるようになり、機械学習の研究が民主化されつつあります。ほとんど魔法のようなプラグアンドプレイのコード5行で(ほぼ)最先端の結果を約束することがよくあります。私自身もHugging Face 🤗で働いているため、その点については一部罪を感じています。 😅 これにより、経験の浅いユーザーはニューラルネットワークがすでに成熟した技術であるかのような誤解を受けることがありますが、実際にはこの分野は常に発展途上にあるのです。 実際には、ニューラルネットワークの構築とトレーニングは非常にイライラする経験になることがしばしばあります : 自分のモデル/コードのバグによるパフォーマンスの問題なのか、モデルの表現力による制約なのかを理解するのが難しいことがあります。 プロセスの各ステップで微小なミスを何度も犯しても最初は気づかず、モデルは依然としてトレーニングされ、まあまあのパフォーマンスを示します。 この記事では、ニューラルネットワークの構築とデバッグ時に考えるべき手順のいくつかを紹介します。「デバッグ」とは、自分が構築したものと自分が考えているものが一致していることを確認することを意味します。また、次のステップが何であるかわからない場合に考慮すべき事項も指摘します。これらは、自然言語処理の研究を通じた経験に基づく考え方の多くですが、ほとんどの原則は他の機械学習の分野にも適用できます。 1. 🙈 機械学習を置いておいて始める 直感に反するかもしれませんが、ニューラルネットワークを構築する最初のステップは、機械学習を一旦置いて、単にデータに焦点を当てることです。例を見て、ラベルを見て、テキストを扱っている場合は語彙の多様性や長さの分布などにも注目してデータに深く入り込んでみてください。モデルが捉えられる可能性のある一般的なパターンを抽出するために、データに没頭することが重要です。数百の例を見ることで、高レベルのパターンを特定することができるでしょう。以下は、自分自身に対して考えるべきいくつかの典型的な質問です: ラベルはバランスしていますか? 自分が同意しないゴールドラベルはありますか? データはどのように取得されましたか?このプロセスでのノイズの可能性のあるソースは何ですか? トークン化、URLやハッシュタグの削除など、自然な前処理ステップはありますか? 例はどれだけ多様ですか? この問題に対してまあまあのパフォーマンスを示すルールベースのアルゴリズムは何ですか?…
ハギングフェイスの読書会、2021年2月 – Long-range Transformers
Efficient Transformersの分類法(TayらによるEfficient Transformers:サーベイ) 共著者:Teven Le Scao、Patrick Von Platen、Suraj Patil、Yacine Jernite、Victor Sanh 毎月、私たちは特定のトピックに焦点を当て、そのトピックについて最近発表された4つの論文を読みます。それらの研究結果と共通のトレンド、そして読んだ後の追加研究についての質問を短いブログ投稿でまとめます。2021年1月の最初のトピックは「スパース化とプルーニング」であり、2021年2月には「Transformerにおけるロングレンジアテンション」に取り組みました。 イントロダクション 2018年と2019年に大型Transformerモデルが台頭した後、その計算要件を下げるために2つのトレンドが急速に現れました。第一に、条件付き計算、量子化、蒸留、プルーニングにより、計算制約のある環境で大型モデルの推論が可能になりました。私たちは既に前回の読書グループの投稿でこれに触れています。研究コミュニティはその後、事前トレーニングのコストを削減するために動きました。 特に、トランスフォーマーモデルのメモリと時間に関するシーケンス長に対する二次的なコストが問題となっていました。非常に大きなモデルの効率的なトレーニングを可能にするために、2020年には通常のNLPでは512または1024のシーケンス長がデフォルトであった範囲を超えるトランスフォーマーをスケールするための論文が数多く発表されました。 このトピックは私たちの研究討論の中心的な要素であり、私たち自身のPatrick Von PlatenはすでにReformerに4部作を捧げています。この読書グループでは、すべてのアプローチをカバーしようとせずに(アプローチは非常に多いです!)、次の4つの主なアイデアに焦点を当てます: カスタムアテンションパターン(Longformerを使用) 再帰(Compressive Transformerを使用) 低ランク近似(Linformerを使用) カーネル近似(Performerを使用) 詳細な視点については、「Efficient…
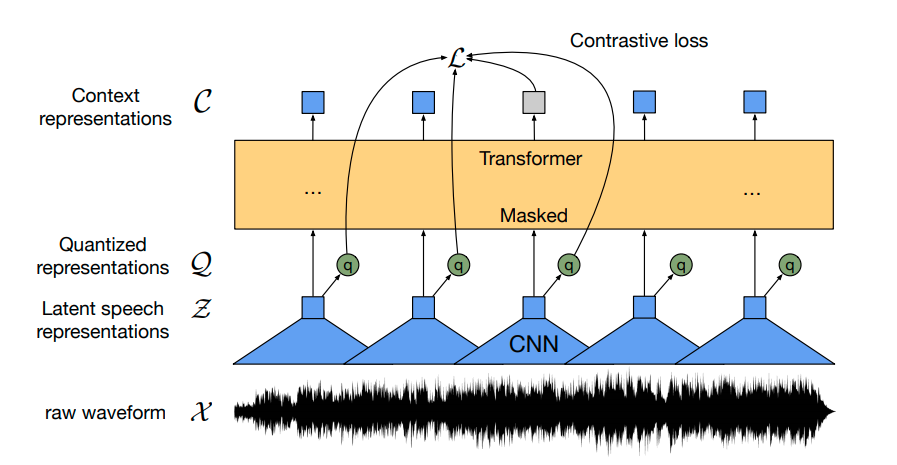
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
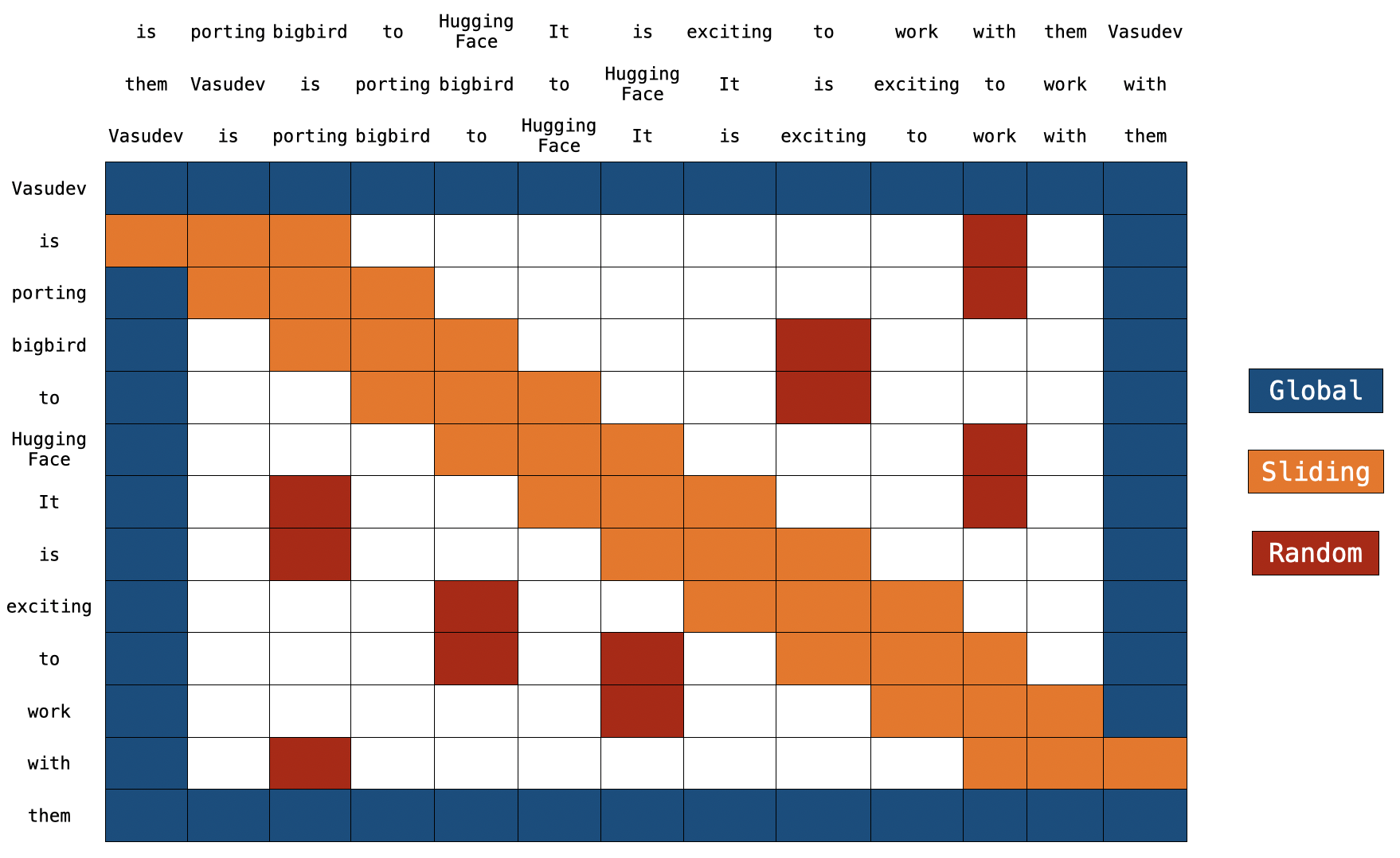
BigBirdのブロック疎な注意機構の理解
イントロダクション トランスフォーマーベースのモデルは、多くの自然言語処理タスクにおいて非常に有用であることが示されています。ただし、トランスフォーマーベースのモデルの主な制限は、O(n^2) の時間とメモリの複雑さ(ここで n はシーケンスの長さです)です。したがって、長いシーケンス n > 512 に対してトランスフォーマーベースのモデルを適用するのは計算上非常に高コストです。最近のいくつかの論文では、Longformer、Performer、Reformer、Clustered attention などが、完全な注意行列を近似することでこの問題を解決しようとしています。これらのモデルについて詳しく知りたい場合は、🤗の最近のブログ記事をチェックしてください。 BigBird(論文で紹介)は、この問題に対処するための最近のモデルの1つです。 BigBird は通常の注意(つまり、BERTの注意)ではなく、ブロックスパースな注意を使用し、BERTよりも低い計算コストで長さ 4096 のシーケンスを処理することができます。 BigBird は、長いドキュメントの要約、長いコンテキストを持つ質問応答など、非常に長いシーケンスを含むさまざまなタスクでSOTAを達成しています。 BigBird RoBERTa-like モデルは現在、🤗Transformersで利用できます。この記事の目的は、読者に 詳細な BigBird の実装の理解を提供し、🤗Transformers…

Hugging FaceモデルをGradio 2.0で使用して混在させる
Gradioブログからの転載。 Hugging Face Model Hubには、ユーザーによって提出された10,000以上の機械学習モデルがあります。フィンランド語と英語の翻訳や中国語の音声認識など、あらゆる種類の自然言語処理モデルが見つかります。最近では、ハブは画像分類や音声処理のためのモデルも含めるように拡大しました。 Hugging Faceは常にモデルをアクセス可能で使いやすくすることに取り組んできました。 transformersライブラリを使用すると、わずか数行のコードでモデルを読み込むことができます。モデルを読み込んだ後、新しいデータに対してプログラム上で予測を行うことができます。しかし、機械学習モデルを使用しているのはプログラマーだけではありません!機械学習におけるますます一般的なシナリオは、異分野のチームにモデルをデモすることや、非プログラマーがモデルを使用すること(バイアスや不具合箇所の発見などのため)です。 Gradioライブラリを使用すると、機械学習開発者は機械学習モデルから簡単にデモやGUIを作成し、Googleドキュメントのリンクを共有するのと同じくらい簡単に共有することができます。そして、Gradio 2.0ライブラリを使用すると、たった1行のコードでほぼどんなHugging FaceモデルでもGUIをロードして使用することができます。以下に例を示します: デフォルトでは、これはHuggingFaceのホステッド推論APIを使用します(独自のAPIキーを提供するか、APIキーなしでパブリックアクセスを使用できます)。また、pip install transformersを実行してモデルの計算をローカルで実行することもできます。 デモをカスタマイズしたいですか?Interfaceクラスのデフォルトパラメータをオーバーライドすることができます。 しかし、まだまだあります!Model Hubには既に10,000以上のモデルがありますが、それらは単体のコードとしてではなく、より洗練されたアプリケーションやデモを作成するためのレゴブロックのようなものと見なしています。 例えば、Gradioを使用すると複数のモデルを並列に読み込むことができます(Hugging Faceの4つの異なるテキスト生成モデルを比較して、使用ケースに最適なモデルを見つけたい場合などを想像してください): また、モデルを直列に配置することもできます。これにより、複数の機械学習モデルから構築された複雑なアプリケーションを簡単に構築することができます。例えば、次のようなアプリケーションを3行のコードで作成することができます:フィンランドのニュース記事を翻訳して要約するアプリケーションです。 さらに、複数のモデルを並列に比較しながらシリーズに混ぜることもできます(ぜひ試してみてください!)。これらのいずれかを試すには、Gradioをインストール(pip install gradio)し、試したいHugging Faceモデルを選択してください。GradioとHugging…

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

スケールにおけるトランスフォーマーの最適化ツールキット、Optimumをご紹介します
この投稿は、Hugging Faceが最先端の機械学習プロダクションパフォーマンスを民主化するための旅の第一歩です。目指すところに到達するために、私たちはハードウェアパートナーと手を組んで取り組む予定です。以下のIntelと協力しています。この旅に参加して、新しいオープンソースライブラリであるOptimumをフォローしてください! なぜ 🤗 Optimum なのか? 🤯 Transformersのスケーリングは難しい Tesla、Google、Microsoft、Facebook、これらの企業に共通するものは何でしょうか?もちろんいくつかありますが、その1つは毎日数十億のTransformerモデルの予測を実行していることです。TeslaのAutoPilotのためのTransformer、Gmailの文章補完のためのTransformer、Facebookの投稿のリアルタイム翻訳のためのTransformer、Bingの自然言語クエリに対する回答のためのTransformerなど、さまざまな用途で使用されています。 Transformerは機械学習モデルの精度を飛躍的に向上させ、NLPを征服し、SpeechやVisionなどの他のモダリティにも広がっています。しかし、これらの巨大なモデルを本番環境に持ち込み、スケールで高速に実行することは、どの機械学習エンジニアリングチームにとっても大きな課題です。 上記の企業のように、数百人の高度に熟練した機械学習エンジニアを雇っていない場合はどうでしょうか?私たちの新しいオープンソースライブラリであるOptimumを通じて、Transformerのプロダクションパフォーマンスのための究極のツールキットを構築し、特定のハードウェア上でモデルをトレーニングおよび実行するための最大の効率性を実現することを目指しています。 🏭 OptimumがTransformerを活用します 最適なパフォーマンスでモデルをトレーニングおよび提供するためには、モデルのアクセラレーション技術は対象のハードウェアと互換性が必要です。各ハードウェアプラットフォームは、パフォーマンスに大きな影響を与える特定のソフトウェアツール、機能、ノブを提供しています。同様に、スパース化や量子化などの高度なモデルアクセラレーション技術を活用するためには、最適化されたカーネルがシリコン上の演算子と互換性があり、モデルアーキテクチャから派生したニューラルネットワークグラフに特化している必要があります。この3次元の互換性行列やモデルアクセラレーションライブラリの使用方法について詳しく調査するのは、ほとんどの機械学習エンジニアにとって困難な作業です。 Optimumはこの作業を簡単にすることを目指し、効率的なAIハードウェアを対象としたパフォーマンス最適化ツールを提供し、ハードウェアパートナーとの共同開発で機械学習エンジニアをML最適化の魔術師に変えます。 Transformerライブラリでは、最先端のモデルを研究者やエンジニアが簡単に使用できるようにし、フレームワーク、アーキテクチャ、パイプラインの複雑さを抽象化しました。 Optimumライブラリでは、エンジニアが利用可能なすべてのハードウェア機能を活用し、ハードウェアプラットフォーム上でのモデルアクセラレーションの複雑さを抽象化することで、エンジニアに簡単になります。 🤗 Optimumの実践:Intel Xeon CPU向けのモデルの量子化方法 🤔 量子化の重要性と正しい方法 BERTなどの事前学習済み言語モデルは、さまざまな自然言語処理タスクで最先端の結果を達成しており、ViTやSpeech2Textなどの他のTransformerベースのモデルも、コンピュータビジョンや音声タスクで最先端の結果を達成しています。Transformerは機械学習の世界で広く使われており、今後も使われ続けます。…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…
1Bのトレーニングペアで文埋め込みモデルをトレーニングする
文の埋め込みは、文を実数のベクトルにマッピングする手法です。理想的には、これらのベクトルは文の意味を捉え、高度に汎用的であるべきです。そのような表現は、クラスタリング、テキストマイニング、質問応答など、多くの下流アプリケーションで使用することができます。 私たちは、「1Bのトレーニングペアで最高の文埋め込みモデルをトレーニングするプロジェクト」として、最先端の文埋め込みモデルを開発しました。このプロジェクトは、Hugging Faceによって主催されたCommunity week using JAX/Flax for NLP & CVの一環として行われました。このプロジェクトでは、GoogleのFlax、JAX、およびCloudチームのメンバーから、効率的なディープラーニングフレームワークに関するガイダンスを受けました! トレーニング手法 モデル 単語とは異なり、有限の文の集合を定義することはできません。したがって、文の埋め込み手法では、内部の単語を組み合わせて最終的な表現を計算します。たとえば、SentenceBertモデル(Reimers and Gurevych, 2019)では、多くのNLPアプリケーションの基盤であるTransformerを使用し、コンテキスト化された単語ベクトルに対してプーリング操作を行います(以下の図を参照)。 マルチプルネガティブランキングロス 構成モジュールのパラメータは通常、自己教師ありの目的関数を使用して学習されます。このプロジェクトでは、以下の図で説明されているコントラスティブトレーニング方法を使用しました。文のペア(a_i, p_i)が意味的に近いペアであるデータセットを構成します。たとえば、(クエリ、回答パッセージ)、(質問、重複質問)、(論文タイトル、引用論文タイトル)などのペアを考慮します。その後、モデルは、ペア(a_i, p_i)を埋め込み空間で近いベクトルにマッピングするようにトレーニングされます。一方、非一致のペア(a_i, p_j)、i ≠ jは、埋め込み空間で遠いベクトルにマッピングされます。このトレーニング方法は、インバッチネガティブ、InfoNCE、またはNTXentLossとも呼ばれます。 形式的には、トレーニングサンプルのバッチが与えられた場合、モデルは以下の損失関数を最適化します:…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.