Learn more about Search Results [3] - Page 17

- You may be interested
- 「大規模な言語モデルとベクトルデータベ...
- ディープマインドのこの機械学習研究は、...
- 「データの必要量はどのくらいですか? 機...
- チャットアプリ開発の主要な柱
- 「オートエンコーダを用いたMNIST画像の再...
- グラフ機械学習の概要
- ReLoRa GPU上で大規模な言語モデルを事前...
- UCバークレーの研究者たちは、ビデオ予測...
- 「強化学習の実践者ガイド」
- ランウェイの新しい「モーションブラシ」...
- 『GenAI:より良い結果と低コストでデータ...
- 「Llama 2:ChatGPTに挑むオープンソース...
- エラスティックサーチでシノニムを便利に...
- 「MindGPTとは、fMRI信号から察知された視...
- 「英語のアクセント分類のための機械学習...
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…
AWS Inferentia2を使用してHugging Face Transformersを高速化する
過去5年間、Transformerモデル[1]は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声など、多くの機械学習(ML)タスクのデファクトスタンダードとなりました。今日、多くのデータサイエンティストやMLエンジニアは、BERT[2]、RoBERTa[3]、Vision Transformer[4]などの人気のあるTransformerアーキテクチャ、またはHugging Faceハブで利用可能な130,000以上の事前学習済みモデルを使用して、最先端の精度で複雑なビジネス問題を解決するために頼っています。 しかし、その優れた性能にもかかわらず、Transformerは本番環境での展開には困難を伴うことがあります。モデル展開に通常関連するインフラストラクチャの設定に加えて、我々はInference Endpointsサービスで大部分の問題を解決しましたが、Transformerは通常、数ギガバイトを超える大きなモデルです。GPT-J-6B、Flan-T5、Opt-30Bなどの大規模言語モデル(LLM)は数十ギガバイトであり、BLOOMなどの巨大なモデルは350ギガバイトもあります。 これらのモデルを単一のアクセラレータに適合させることは非常に困難ですし、会話型アプリケーションや検索のようなアプリケーションが必要とする高スループットと低推論レイテンシを実現することはさらに難しいです。MLの専門家たちは、大規模モデルをスライスし、アクセラレータクラスタに分散させ、レイテンシを最適化するために複雑な手法を設計してきました。残念ながら、この作業は非常に困難で時間がかかり、多くのMLプラクティショナーには到底手の届かないものです。 Hugging Faceでは、MLの民主化を進めるとともに、すべての開発者と組織が最先端のモデルを利用できるようにすることを目指しています。そのため、今回はAmazon Web Servicesと提携し、Hugging Face TransformersをAWS Inferentia 2に最適化することに興奮しています!これは、前例のないスループット、レイテンシ、パフォーマンス、スケーラビリティを提供する新しい特別な推論アクセラレータです。 AWS Inferentia2の紹介 AWS Inferentia2は、2019年に発売されたInferentia1の次世代です。Inferentia1のパワーにより、Amazon EC2 Inf1インスタンスは、NVIDIA A10G GPUをベースとしたG5インスタンスと比較して、スループットが25%向上し、コストが70%削減されました。そして、Inferentia2により、AWSは再び限界を em>押し広げています。 新しいInferentia2チップは、Inferentiaと比較してスループットが4倍向上し、レイテンシが10倍低下します。同様に、新しいAmazon…

より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
大規模言語モデル(LLM)は、機械学習の世界を席巻しています。Transformerアーキテクチャのおかげで、LLMはテキスト、画像、ビデオ、オーディオなどの大量の非構造化データから学習する驚異的な能力を持っています。テキスト分類のような抽出型のタスクや、テキスト要約、テキストから画像生成などの生成型のタスクでも非常に優れたパフォーマンスを発揮します。 その名前からもわかるように、LLMは一般的に100億パラメータを超える大規模なモデルです。BLOOMモデルのように1000億パラメータ以上のものもあります。LLMは、検索や対話型アプリケーションなどの低遅延のユースケースで十分に高速な予測を行うために、高性能なGPUに典型的に見られる大量の計算能力を必要とします。残念ながら、多くの組織にとっては関連するコストが高く、最先端のLLMをアプリケーションに使用することが困難になります。 この記事では、Intel CPU上で効率的に実行するために、LLMのサイズと推論レイテンシを減らす最適化技術について説明します。 量子化の基礎 通常、LLMは16ビットの浮動小数点パラメータ(FP16/BF16)でトレーニングされます。したがって、単一の重みまたはアクティベーション値の値を保存するためには2バイトのメモリが必要です。さらに、浮動小数点の演算は整数の演算よりも複雑で遅く、追加の計算能力が必要です。 量子化は、モデルパラメータが取ることができるユニークな値の範囲を縮小することで、両方の問題を解決するモデルの圧縮技術です。たとえば、モデルを8ビット整数(INT8)のような低精度に量子化して、モデルを縮小し、複雑な浮動小数点演算をより単純で高速な整数演算に置き換えることができます。 要するに、量子化はモデルパラメータをより小さな値範囲に再スケーリングします。成功すると、モデルのサイズが少なくとも2倍に縮小され、モデルの精度には影響しません。 量子化は、通常、トレーニング中に適用することができます。これを量子化対応トレーニング(QAT)と呼びますが、一般的に最良の結果が得られます。既存のモデルを量子化する場合は、非常に少ない計算能力を必要とする高速なテクニックであるポストトレーニング量子化(PTQ)を適用することもできます。 さまざまな量子化ツールが利用可能です。たとえば、PyTorchには量子化の組み込みサポートがあります。また、QATおよびPTQのための開発者向けのAPIを備えたHugging Face Optimum Intelライブラリを使用することもできます。 LLMの量子化 最近の研究[1][2]によると、現在の量子化技術はLLMとはうまく機能しません。特に、LLMはすべてのレイヤーとトークンで特定のアクティベーションチャネルに大きな値の外れ値を示します。以下はOPT-13Bモデルの例です。すべてのトークンで、アクティベーションの1つのチャネルが他のすべてのチャネルよりもはるかに大きな値を持っていることがわかります。この現象はモデルのすべてのTransformerレイヤーで見られます。 *出典: SmoothQuant* 現在の最良の量子化技術は、トークン単位でアクティベーションを量子化し、切り捨てられた外れ値または低いマグニチュードのアクティベーションを引き起こします。いずれの解決策もモデルの品質に大きな影響を与えます。さらに、量子化対応トレーニングには追加のモデルトレーニングが必要であり、計算リソースとデータの不足のため、ほとんどの場合には実用的ではありません。 SmoothQuant[3][4]は、この問題を解決する新しい量子化技術です。それは重みとアクティベーションに共同の数学的変換を適用し、アクティベーションの外れ値と非外れ値の比率を減らすことで、Transformerのレイヤーを「量子化に適した」状態にします。これにより、モデルの品質に影響を与えずに8ビットの量子化が可能となります。その結果、SmoothQuantはIntel CPUプラットフォーム上で優れたパフォーマンスを発揮する、より小さく、高速なモデルを生成します。 *出典: SmoothQuant* それでは、SmoothQuantを人気のあるLLMに適用した場合の動作を見てみましょう。 SmoothQuantを使用したLLMの量子化…

大規模なネアデデュープリケーション:BigCodeの背後に
対象読者 大規模な文書レベルの近似除去に興味があり、ハッシュ、グラフ、テキスト処理のいくつかの理解を持つ人々。 動機 モデルにデータを供給する前にデータをきちんと扱うことは重要です。古い格言にあるように、ゴミを入れればゴミが出てきます。データ品質があまり重要ではないという幻想を作り出す見出しをつかんでいるモデル(またはAPIと言うべきか)が増えるにつれて、それがますます難しくなっています。 BigScienceとBigCodeの両方で直面する問題の1つは、ベンチマークの汚染を含む重複です。多くの重複がある場合、モデルはトレーニングデータをそのまま出力する傾向があることが示されています[1](ただし、他のドメインではそれほど明確ではありません[2])。また、重複はモデルをプライバシー攻撃に対しても脆弱にする要因となります[1]。さらに、重複除去の典型的な利点には以下があります: 効率的なトレーニング:トレーニングステップを少なくして、同じかそれ以上のパフォーマンスを達成できます[3][4]。 データ漏洩とベンチマークの汚染を防ぐ:ゼロでない重複は評価を信用できなくし、改善という主張が偽りになる可能性があります。 アクセシビリティ:私たちのほとんどは、何千ギガバイトものテキストを繰り返しダウンロードまたは転送する余裕がありません。固定サイズのデータセットに対して、重複除去は研究、転送、共同作業を容易にします。 BigScienceからBigCodeへ 近似除去のクエストに参加した経緯、結果の進展、そして途中で得た教訓について最初に共有させてください。 すべてはBigScienceがすでに数ヶ月前に始まっていたLinkedIn上の会話から始まりました。Huu Nguyenは、私のGitHubの個人プロジェクトに気付き、BigScienceのための重複除去に取り組むことに興味があるかどうか私に声をかけました。もちろん、私の答えは「はい」となりましたが、データの膨大さから単独でどれだけの努力が必要になるかは全く無知でした。 それは楽しくも挑戦的な経験でした。その大規模なデータの研究経験はほとんどなく、みんながまだ信じていたにもかかわらず、何千ドルものクラウドコンピュート予算を任せられるという意味で挑戦的でした。はい、数回マシンをオフにしたかどうかを確認するために寝床から起きなければならなかったのです。その結果、試行錯誤を通じて仕事を学びましたが、それによってBigScienceがなければ絶対に得られなかった新しい視点が開かれました。 さらに、1年後、私は学んだことをBigCodeに戻して、さらに大きなデータセットで作業をしています。英語向けにトレーニングされたLLMに加えて、重複除去がコードモデルの改善につながることも確認しました[4]。さらに、はるかに小さなデータセットを使用しています。そして今、私は学んだことを、親愛なる読者の皆さんと共有し、重複除去の視点を通じてBigCodeの裏側で何が起こっているかを感じていただければと思います。 興味がある場合、BigScienceで始めた重複除去の比較の最新バージョンをここで紹介します: これはBigCodeのために作成したコードデータセット用のものです。データセット名が利用できない場合はモデル名が使用されます。 MinHash + LSHパラメータ( P , T , K…
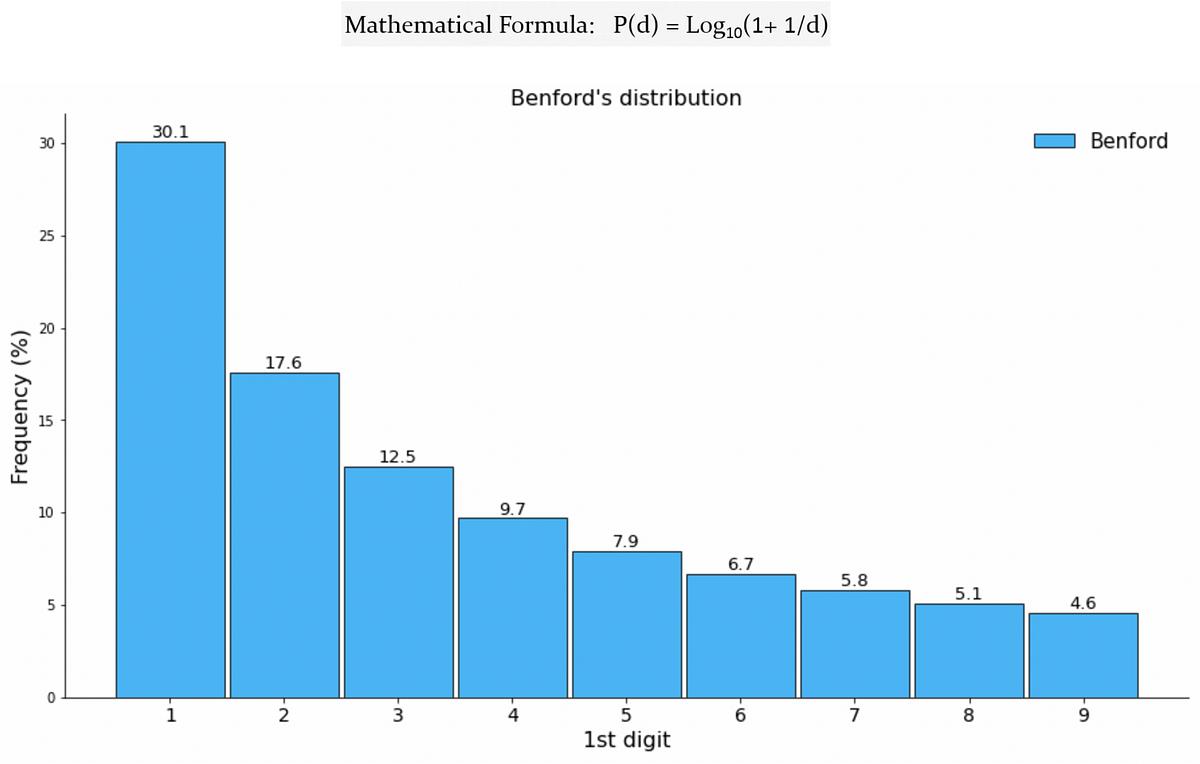
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...
Pythonを使った感情分析(Sentiment Analysis)のFlair
シリーズ記事の次のブログへようこそ!今日は、感情分析のためのPythonライブラリで使用される方法の1つであるFlairを探求しますFlairは、NLP(自然言語処理)ライブラリです...
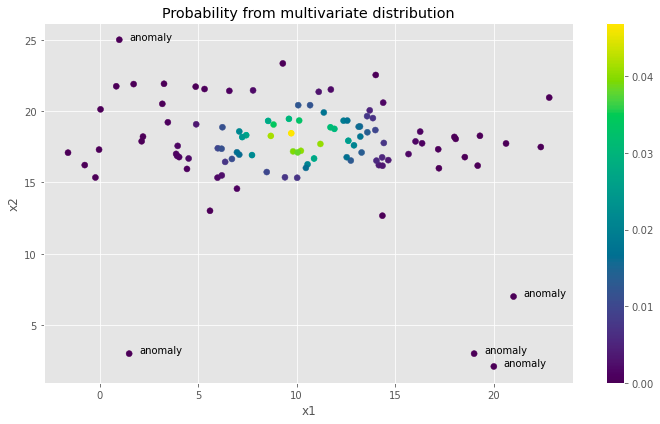
多変量ガウス分布による異常検知の基本
私たちの生まれつきのパターン認識能力によって、私たちはこのスキルを使って抜け落ちた部分を埋めたり、次に何が起こるかを予測したりすることができますしかし時折、私たちの予測に合わないことが起こります...

T5 テキストからテキストへのトランスフォーマー(パート2)
BERT [5] の提案により、自然言語処理(NLP)のための転移学習手法の普及がもたらされましたインターネット上での未ラベル化されたテキストの広範な利用可能性により、私たちは...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.