Learn more about Search Results 構成 - Page 170

- You may be interested
- 「あなたのLLM + Streamlitアプリケーショ...
- 現代の自然言語処理(NLP):詳細な概要パ...
- 「最初のAIエージェントを開発する:Deep ...
- クロード2 APIの使い方をはじめる
- このAI論文は、周波数領域での差分プライ...
- 「新しいアプリが、生成AIを使用してサウ...
- 「大規模な言語モデルとベクトルデータベ...
- ベントMLを使用したHugging Faceモデルの...
- VoAGI ニュース、12月 13日 データサイエ...
- 「GoogleのAI Red Team:AIを安全にするた...
- 「人間の労働が機械学習を可能にする方法」
- 「時系列分析による回帰モデルの堅牢性向...
- GoogleとJohns Hopkins Universityの研究...
- OpenAI GPT(ジェネラル プロダクト トラ...
- ノースウェスタン大学の研究者は、AIのエ...
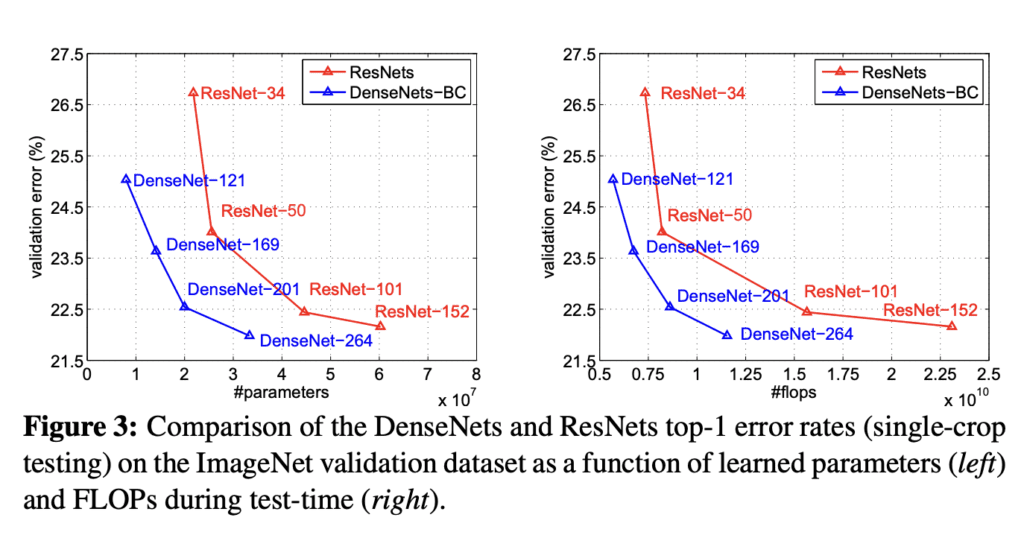
FLOPsとMACsを使用して、Deep Learningモデルの計算効率を計算する
この記事では、その定義、違い、およびPythonパッケージを使用してFLOPsとMACsを計算する方法について学びます

AIのマスタリング:プロンプトエンジニアリングソリューションの力
私と一緒にAIプロンプトエンジニアリングの素晴らしさを発見しましょう!ユーモアのある効果的なプロンプトの制作によって、AIモデルのフルポテンシャルを引き出すことができます

Python におけるカテゴリカル変数の扱い方ガイド
データサイエンスまたは機械学習プロジェクトでのカテゴリ変数の扱いは容易な仕事ではありませんこの種の作業には、アプリケーションの分野の深い知識と幅広い理解が必要です...

プレイヤーの離脱を予測する方法、ChatGPTの助けを借りる
ゲームの世界では、企業はプレイヤーを引きつけるだけでなく、特にゲーム内のマイクロトランザクションに頼る無料のゲームでは、できるだけ長く彼らを保持することを目指していますこれらの...
Amazon SageMaker 上で MPT-7B を微調整する
毎週新しい大規模言語モデル(LLM)が発表され、それぞれが前任者を打ち負かして評価のトップを狙っています最新のモデルの1つはMPT-7Bです
線形回帰と勾配降下法
線形回帰は機械学習に存在する基本アルゴリズムの1つですその内部ワークフローを理解することは、データサイエンスの他のアルゴリズムの主要な概念を把握するのに役立ちます...

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、PaLIなどの大規模なモデルは、数百億のパラメータにスケーリングされ、大規模なテキストおよび画像データセットでトレーニングされると、多大な量の知識を格納する能力を示しました。これらのモデルは、画像キャプション、ビジュアルクエスチョンアンサリング、オープンボキャブラリー認識などのダウンストリームタスクで最先端の結果を達成しています。しかし、これらのモデルはトレーニングに膨大な量のデータを必要とし、数十億のパラメータ(多くの場合)を持ち、著しい計算要件を引き起こします。また、これらのモデルをトレーニングするために使用されるデータは古くなる可能性があり、世界の知識が更新されるたびに再トレーニングが必要になる場合があります。たとえば、2年前にトレーニングされたモデルは、現在のアメリカ合衆国大統領に関する古い情報を提供する可能性があります。 自然言語処理(RETRO、REALM)およびコンピュータビジョン(KAT)の分野では、検索増強モデルを使用してこれらの課題に取り組む研究がなされてきました。通常、これらのモデルは、単一のモダリティ(テキストのみまたは画像のみ)を処理できるバックボーンを使用して、知識コーパスから情報をエンコードおよび取得します。ただし、これらの検索増強モデルは、クエリと知識コーパスのすべての利用可能なモダリティを活用できず、モデルの出力を生成するために最も役立つ情報を見つけられない場合があります。 これらの問題に対処するために、「REVEAL:Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory」(CVPR 2023に掲載予定)では、複数のソースのマルチモーダル「メモリ」を利用して知識集中型クエリに答えることを学ぶビジュアル言語モデルを紹介します。REVEALは、ニューラル表現学習を使用して、さまざまな知識ソースをキー-バリューペアから成るメモリ構造に変換し、エンコードします。キーはメモリアイテムのインデックスとして機能し、対応する値はそれらのアイテムに関する関連情報を格納します。トレーニング中、REVEALは、キーエンベッディング、値トークン、およびこのメモリから情報を取得する能力を学習して、知識集中型クエリに対処します。このアプローチにより、モデルパラメータは暗記に専念するのではなく、クエリに関する推論に焦点を当てることができます。 多様な知識ソースから複数の知識エントリを取得する能力を持つビジュアル言語モデルを拡張することで、生成を支援します。 マルチモーダル知識コーパスからのメモリ構築 私たちのアプローチは、異なるソースからの知識アイテムのキーと値のエンベッディングを事前に計算し、キー-バリューペアにエンコードして統一された知識メモリにインデックスするREALMと似ています。各知識アイテムは、より詳細に表現されたトークンエンベッディングのシーケンスである値としてエンコードされます。以前の研究とは異なり、REVEALは、WikiData知識グラフ、Wikipediaのパッセージと画像、Web画像テキストペア、ビジュアルクエスチョンアンサリングデータなど、多様なマルチモーダル知識コーパスを活用しています。各知識アイテムは、テキスト、画像、両方の組み合わせ(たとえば、Wikipediaのページ)、または知識グラフからの関係または属性(たとえば、バラク・オバマは6’2 “の背丈)の場合があります。トレーニング中、モデルパラメータが更新されるたびに、REVEALはキーと値のエンベッディングを連続的に再計算します。ステップごとにメモリを非同期に更新します。 圧縮を使用したメモリのスケーリング メモリ値をエンコードするための素朴な解決策は、各知識アイテムのトークンのすべてのシーケンスを保持することです。次に、モデルは、すべてのトークンを連結してトランスフォーマーエンコーダーデコーダーパイプラインに送信することで、入力クエリとトップkの取得されたメモリ値を融合することができます。このアプローチには2つの問題があります。1つ目は、数億の知識アイテムをメモリに保持する場合、各メモリ値が数百のトークンから構成されている場合、実用的ではないことです。2つ目は、トランスフォーマーエンコーダーが自己注意のために合計トークン数×kに対して2次の複雑度を持っていることです。そのため、Perceiverアーキテクチャを使用して知識アイテムをエンコードおよび圧縮することを提案しています。Perceiverモデルは、トランスフォーマーデコーダーを使用して、フルトークンシーケンスを任意の長さに圧縮します。これにより、kが100にもなるトップkメモリエントリを取得できます。 以下の図は、メモリのキー-バリューペアを構築する手順を示しています。各知識項目は、マルチモーダル視覚言語エンコーダを介して処理され、画像とテキストのトークンのシーケンスに変換されます。キー・ヘッドはこれらのトークンをコンパクトな埋め込みベクトルに変換します。バリュー・ヘッド(パーセプター)は、これらのトークンを少なくし、知識項目に関する適切な情報を保持します。 異なるコーパスからの知識エントリを統一されたキーとバリューの埋め込みペアにエンコードし、キーはメモリのインデックスに使用され、値にはエントリに関する情報が含まれます。…
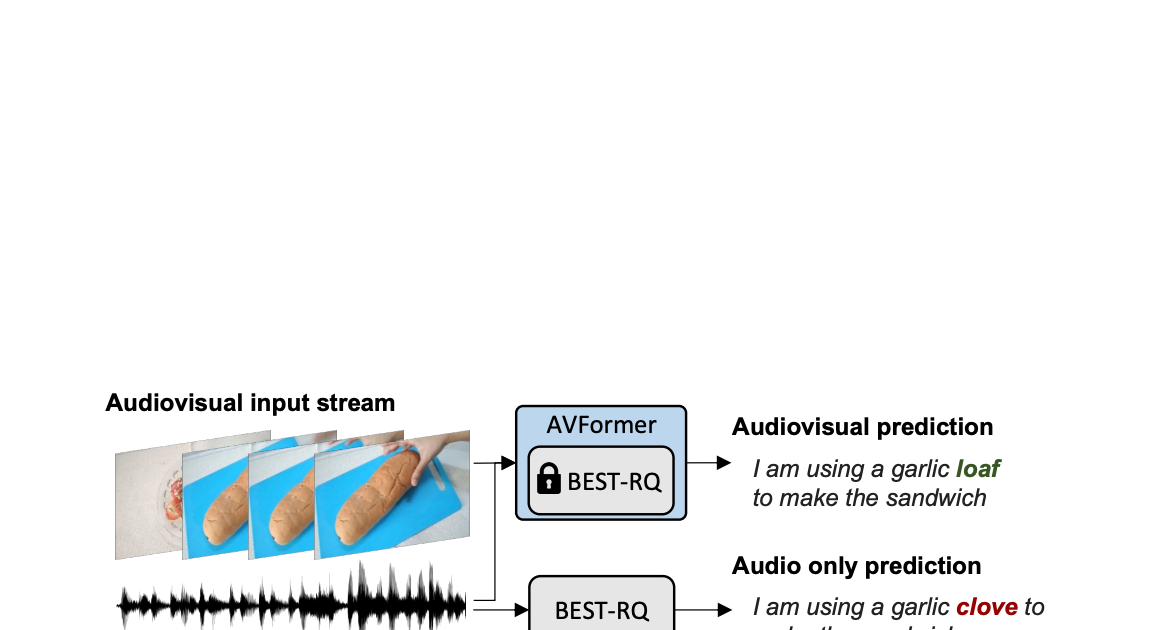
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビデオの転写、音声コマンドなど、さまざまなアプリケーションで広く採用されている確立された技術です。この技術の課題は、ノイズのあるオーディオ入力に集中していますが、マルチモーダルビデオ(テレビ、オンライン編集ビデオなど)の視覚ストリームはASRシステムの堅牢性を向上させる強力な手がかりを提供することができます。これをオーディオビジュアルASR(AV-ASR)と呼びます。 唇の動きは音声認識に強力な信号を提供し、AV-ASRの最も一般的な焦点であるが、野外のビデオで口が直接見えないことがよくあります(例えば、自己中心的な視点、顔のカバー、低解像度など)ため、新しい研究領域である拘束のないAV-ASR(AVATARなど)が誕生し、口の領域だけでなく、ビジュアルフレーム全体の貢献を調査しています。 ただし、AV-ASRモデルをトレーニングするためのオーディオビジュアルデータセットを構築することは困難です。How2やVisSpeechなどのデータセットはオンラインの教育ビデオから作成されていますが、サイズが小さいため、モデル自体は通常、ビジュアルエンコーダーとオーディオエンコーダーの両方から構成され、これらの小さなデータセットで過剰適合する傾向があります。それにもかかわらず、オーディオブックから取得した大量のオーディオデータを用いた大規模なトレーニングによって強く最適化された最近リリースされた大規模なオーディオモデルがいくつかあります。LibriLightやLibriSpeechなどがあります。これらのモデルには数十億のパラメータが含まれ、すぐに利用可能であり、ドメイン間で強い汎化性能を示します。 上記の課題を考慮して、私たちは「AVFormer:ゼロショットAV-ASRの凍結音声モデルにビジョンを注入する」と題した論文で、既存の大規模なオーディオモデルにビジュアル情報を付加するシンプルな方法を提案しています。同時に、軽量のドメイン適応を行います。AVFormerは、軽量のトレーニング可能なアダプタを使用して、視覚的な埋め込みを凍結されたASRモデルに注入します(Flamingoが大規模な言語モデルに視覚テキストタスクのためのビジュアル情報を注入する方法と似ています)。これにより、最小限の追加トレーニング時間とパラメータで弱くラベル付けられた少量のビデオデータでトレーニング可能です。トレーニング中のシンプルなカリキュラムスキームも紹介し、オーディオとビジュアルの情報を効果的に共同処理できるようにするために重要であることを示します。その結果、AVFormerモデルは、3つの異なるAV-ASRベンチマーク(How2、VisSpeech、Ego4D)で最新のゼロショットパフォーマンスを達成し、同時に伝統的なオーディオのみの音声認識ベンチマーク(LibriSpeechなど)のまともなパフォーマンスを保持しています。 拘束のないオーディオビジュアル音声認識。軽量モジュールを使用して、ビジョンを注入して、オーディオビジュアルASRのゼロショットを実現するために、Best-RQ(灰色)の凍結音声モデルにビジョンを注入します。AVFormer(青)というパラメーターとデータ効率の高いモデルが作成されます。オーディオ信号がノイズの場合、視覚的なパンの生成トランスクリプトでオンリーミステイク「クローブ」を「ローフ」に修正するのに役立つ視覚的なパンが役立つ場合があります。 軽量モジュールを使用してビジョンを注入する 私たちの目標は、既存のオーディオのみのASRモデルにビジュアル理解能力を追加しながら、その汎化性能を各ドメイン(AVおよびオーディオのみのドメイン)に維持することです。 このために、既存の最新のASRモデル(Best-RQ)に次の2つのコンポーネントを追加します:(i)線形ビジュアルプロジェクター、および(ii)軽量アダプター。前者は、オーディオトークン埋め込みスペースにおける視覚的な特徴を投影します。このプロセスにより、別々に事前トレーニングされたビジュアル機能とオーディオ入力トークン表現を適切に接続することができます。後者は、その後最小限の変更で、ビデオのマルチモーダル入力を理解するためにモデルを変更します。その後、これらの追加モジュールを、HowTo100Mデータセットからのラベル付けされていないWebビデオとASRモデルの出力を擬似グラウンドトゥルースとして使用してトレーニングし、Best-RQモデルの残りを凍結します。このような軽量モジュールにより、データ効率と強力なパフォーマンスの汎化が可能になります。 我々は、AV-ASRベンチマークにおいて、モデルが人手で注釈付けされたAV-ASRデータセットで一度もトレーニングされていないゼロショット設定で、拡張モデルを評価しました。 ビジョン注入のためのカリキュラム学習 初期評価後、私たちは経験的に、単純な一回の共同トレーニングでは、モデルがアダプタとビジュアルプロジェクタの両方を一度に学習するのが困難であることがわかりました。この問題を緩和するために、私たちは、これら2つの要因を分離し、ネットワークを順序良くトレーニングする2段階のカリキュラム学習戦略を導入しました。最初の段階では、アダプタパラメータが全くフィードされずに最適化されます。アダプタがトレーニングされたら、ビジュアルトークンを追加し、トレーニング済みのアダプタを凍結したまま第2段階でビジュアルプロジェクションレイヤーのみをトレーニングします。 最初の段階は、音声ドメイン適応に焦点を当てています。第2段階では、アダプタが完全に凍結され、ビジュアルプロジェクタは、ビジュアルトークンをオーディオ空間に投影するためのビジュアルプロンプトを生成することを学習する必要があります。このように、私たちのカリキュラム学習戦略は、モデルがAV-ASRベンチマークでビジュアル入力を統合し、新しい音声ドメインに適応することを可能にします。私たちは、交互に適用する反復的な適用では性能が低下するため、各段階を1回だけ適用します。 AVFormerの全体的なアーキテクチャとトレーニング手順。アーキテクチャは、凍結されたConformerエンコーダー・デコーダーモデル、凍結されたCLIPエンコーダー(グレーのロックシンボルで示される凍結層を持つ)、および2つの軽量トレーニング可能なモジュールで構成されています。-(i)ビジュアルプロジェクションレイヤー(オレンジ)およびボトルネックアダプタ(青)を有効にし、多モーダルドメイン適応を可能にします。私たちは、2段階のカリキュラム学習戦略を提案しています。最初に、アダプタ(青)をビジュアルトークンなしでトレーニングします。その後、ビジュアルプロジェクションレイヤー(オレンジ)を調整し、他のすべての部分を凍結したままトレーニングします。 下のプロットは、カリキュラム学習なしでは、AV-ASRモデルがすべてのデータセットでオーディオのみのベースラインよりも劣っており、より多くのビジュアルトークンが追加されるにつれてその差が拡大することを示しています。一方、提案された2段階のカリキュラムが適用されると、AV-ASRモデルは、オーディオのみのベースラインよりも遥かに優れたパフォーマンスを発揮します。 カリキュラム学習の効果。赤と青の線はオーディオビジュアルモデルであり、ゼロショット設定で3つのデータセットに表示されます(WER%が低い方が良いです)。カリキュラムを使用すると、すべての3つのデータセットで改善します(How2(a)およびEgo4D(c)では、オーディオのみのパフォーマンスを上回るために重要です)。4つのビジュアルトークンまで性能が向上し、それ以降は飽和します。 ゼロショットAV-ASRでの結果 私たちは、How2、VisSpeech、Ego4Dの3つのAV-ASRベンチマークで、zero-shotパフォーマンスのために、BEST-RQ、私たちのモデルの音声バージョン、およびAVATARを比較しました。AVFormerは、すべてのベンチマークでAVATARとBEST-RQを上回り、BEST-RQでは600Mパラメータをトレーニングする必要がありますが、AVFormerはわずか4Mパラメータしかトレーニングせず、トレーニングデータセットのわずか5%しか必要としません。さらに、音声のみのLibriSpeechでのパフォーマンスも評価し、AVFormerは両方のベースラインを上回ります。 AV-ASRデータセット全体におけるゼロショット性能に対する最新手法との比較。音声のみのLibriSpeechのパフォーマンスも示します。結果はWER%(低い方が良い)として報告されています。 AVATARとBEST-RQはHowTo100Mでエンドツーエンド(すべてのパラメータ)で微調整されていますが、AVFormerは微調整されたパラメータの少ないセットのおかげで、データセットの5%でも効果的に機能します。…

Imagen EditorとEditBench:テキストによる画像補完の進展と評価
グーグルリサーチの研究エンジニアであるスー・ワンとセズリー・モンゴメリーによる投稿 過去数年間、テキストから画像を生成する研究は、画期的な進展(特に、Imagen、Parti、DALL-E 2など)を見ており、これらは自然に関連するトピックに浸透しています。特に、テキストによる画像編集(TGIE)は、完全にやり直すのではなく、生成された物と撮影された視覚物を編集する実践的なタスクであり、素早く自動化されたコントロール可能な編集は、視覚物を再作成するのに時間がかかるか不可能な場合に便利な解決策です(例えば、バケーション写真のオブジェクトを微調整したり、ゼロから生成されたかわいい子犬の細かいディテールを完璧にする場合)。さらに、TGIEは、基礎となるモデルのトレーニングを改良する大きな機会を表しています。マルチモーダルモデルは、適切にトレーニングするために多様なデータが必要であり、TGIE編集は高品質でスケーラブルな合成データの生成と再結合を可能にすることができ、おそらく最も重要なことに、任意の軸に沿ってトレーニングデータの分布を最適化する方法を提供できます。 CVPR 2023で発表される「Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting」では、マスクインペインティングの課題に対する最先端の解決策であるImagen Editorを紹介します。つまり、ユーザーが、編集したい画像の領域を示すオーバーレイまたは「マスク」(通常、描画タイプのインターフェイス内で生成されるもの)と共にテキスト指示を提供する場合のことです。また、画像編集モデルの品質を評価する方法であるEditBenchも紹介します。EditBenchは、一般的に使用される粗い「この画像がこのテキストに一致するかどうか」の方法を超えて、モデルパフォーマンスのより細かい属性、オブジェクト、およびシーンについて詳細に分析します。特に、画像とテキストの整合性の信頼性に強い重点を置きつつ、画像の品質を見失わないでください。 Imagen Editorは、指定された領域にローカライズされた編集を行います。モデルはユーザーの意図を意味を持って取り入れ、写真のようなリアルな編集を実行します。 Imagen Editor Imagen Editorは、Imagenでファインチューニングされた拡散ベースのモデルで、編集を行うために改良された言語入力の表現、細かい制御、および高品質な出力を目的としています。Imagen Editorは、ユーザーから3つの入力を受け取ります。1)編集する画像、2)編集領域を指定するバイナリマスク、および3)テキストのプロンプトです。これら3つの入力は、出力サンプルを誘導します。 Imagen Editorは、高品質なテキストによる画像インペインティングを行うための3つの核心技術に依存しています。まず、ランダムなボックスとストロークマスクを適用する従来のインペインティングモデル(例:Palette、Context…

NeRFを使用して室内空間を再構築する
Marcos Seefelder、ソフトウェアエンジニア、およびDaniel Duckworth、リサーチソフトウェアエンジニア、Google Research 場所を選ぶ際、私たちは次のような疑問を持ちます。このレストランは、デートにふさわしい雰囲気を持っているのでしょうか?屋外にいい席はありますか?試合を見るのに十分なスクリーンがありますか?これらの質問に部分的に答えるために、写真やビデオを使用することがありますが、実際に訪れることができない場合でもそこにいるような感覚には代わりがありません。 インタラクティブでフォトリアルな多次元の没入型体験は、このギャップを埋め、スペースの感触や雰囲気を再現し、ユーザーが必要な情報を自然かつ直感的に見つけることができるようにすることができます。これを支援するために、Google MapsはImmersion Viewを開発しました。この技術は、機械学習(ML)とコンピュータビジョンの進歩を活用して、Street Viewや航空写真など数十億の画像を融合して世界の豊富なデジタルモデルを作成します。さらに、天気、交通、場所の混雑度などの役立つ情報を上に重ねます。Immersive Viewでは、レストラン、カフェ、その他の会場の屋内ビューが提供され、ユーザーが自信を持ってどこに行くかを決めるのに役立ちます。 今日は、Immersion Viewでこれらの屋内ビューを提供するために行われた作業について説明します。私たちは、写真を融合してニューラルネットワーク内で現実的な多次元の再構成を生成するための最先端の手法であるニューラル輝度場(NeRF)に基づいています。私たちは、DSLRカメラを使用してスペースのカスタム写真キャプチャ、画像処理、およびシーン再現を含むNeRFの作成パイプラインについて説明します。私たちは、Alphabetの最近の進歩を活用して、視覚的な忠実度で以前の最先端を上回るか、それに匹敵する方法を設計しました。これらのモデルは、キュレーションされたフライトパスに沿って組み込まれたインタラクティブな360°ビデオとして埋め込まれ、スマートフォンで利用可能になります。 アムステルダムのThe Seafood Barの再構築(Immersive View内)。 写真からNeRFへ 私たちの作業の中核にあるのは、最近開発された3D再構成および新しいビュー合成の方法であるNeRFです。シーンを説明する写真のコレクションがある場合、NeRFはこれらの写真をニューラルフィールドに凝縮し、元のコレクションに存在しない視点から写真をレンダリングするために使用できます。 NeRFは再構成の課題を大部分解決したものの、実世界のデータに基づくユーザー向け製品にはさまざまな課題があります。たとえば、照明の暗いバーから歩道のカフェ、ホテルのレストランまで、再構成品質とユーザー体験は一貫している必要があります。同時に、プライバシーは尊重され、個人を特定する可能性のある情報は削除される必要があります。重要なのは、シーンを一貫してかつ効率的にキャプチャし、必要な写真を撮影するための労力を最小限に抑えたまま、高品質の再構成が確実に得られることです。最後に、すべてのモバイルユーザーが同じ自然な体験を手に入れられるようにすることが重要です。 Immersive View屋内再構築パイプライン。 キャプチャ&前処理 高品質なNeRFを生成するための最初のステップは、シーンを注意深くキャプチャすることです。3Dジオメトリーとカラーを派生させるための複数の異なる方向からの密な写真のコレクションを作成する必要があります。オブジェクトの表面に関する情報が多いほど、モデルはオブジェクトの形状やライトとの相互作用の方法を発見する際により優れたものになります。 さらに、NeRFモデルはカメラやシーンそのものにさらなる仮定を置きます。たとえば、カメラのほとんどのプロパティ(ホワイトバランスや絞りなど)は、キャプチャ全体で固定されていると仮定されます。同様に、シーン自体は時間的に凍結されていると仮定されます。ライティングの変更や動きは避ける必要があります。これは、キャプチャに必要な時間、利用可能な照明、機器の重さ、およびプライバシーなどの実用上の問題とのバランスを取る必要があります。プロの写真家と協力して、DSLRカメラを使用して会場写真を迅速かつ信頼性の高い方法でキャプチャする戦略を開発しました。このアプローチは、現在までのすべてのNeRF再構築に使用されています。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.