Learn more about Search Results huggingface.co - Page 16

- You may be interested
- 「NVIDIAのCEO、ジェンソン・ホアン氏がSI...
- 「6つの人工知能の神話を解明:事実とフィ...
- Pythonにおけるオブジェクト指向プログラ...
- 拡散モデルの利点と制約
- 「マイクロソフトが、自社の新しい人工知...
- 報告書:OpenAIがGPT-Visionというマルチ...
- 大規模な言語モデルにおけるコンテキスト...
- ChatGPTの振る舞いは時間の経過と共に変化...
- あなたの特徴は重要ですか?それが良いと...
- 「CRISPRツールがウイルスを撃ち破るのに...
- 製品の特徴が保持率にどのような影響を与...
- スタンフォード大学の新しい人工知能研究...
- 『Google Vertex AI Search&Conversation...
- 「Muybridge Derby AIによる動物の運動写...
- マシンラーニングにおいて未分類データを...
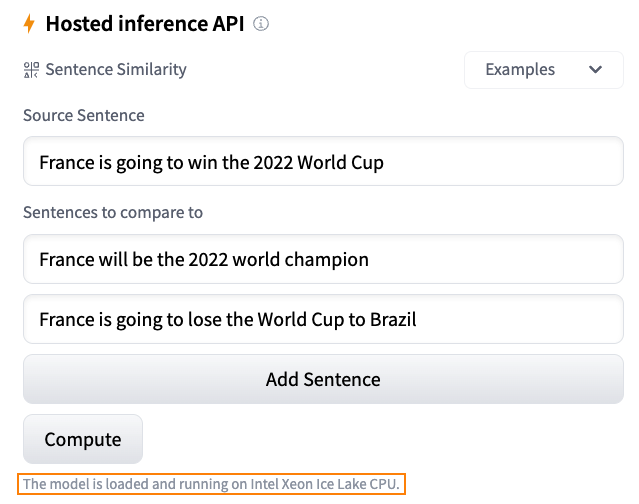
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

オーディオデータセットの完全ガイド
イントロダクション 🤗 Datasetsは、あらゆるドメインのデータセットをダウンロードして準備するためのオープンソースライブラリです。そのミニマリスティックなAPIにより、ユーザーはたった1行のPythonコードでデータセットをダウンロードして準備することができます。効率的な前処理を可能にするための一連の関数も提供されています。利用可能なデータセットの数は類を見ないものであり、ダウンロードできる最も人気のある機械学習データセットがすべて揃っています。 さらに、🤗 Datasetsにはオーディオ特化の機能も備わっており、研究者や実践者にとってもオーディオデータセットの取り扱いを容易にするものです。このブログでは、これらの機能をデモンストレーションし、なぜ🤗 Datasetsがオーディオデータセットのダウンロードと準備のためのベストな場所なのかをご紹介します。 目次 The Hub オーディオデータセットのロード ロードが簡単、処理も簡単 ストリーミングモード:銀の弾丸 The Hubのオーディオデータセットのツアー まとめ The Hub The Hugging Face Hubは、モデル、データセット、デモをホストするプラットフォームであり、すべてがオープンソースで公開されています。さまざまなドメイン、タスク、言語にわたるオーディオデータセットの成長するコレクションがあります。🤗 Datasetsとの緊密な統合により、Hubのすべてのデータセットを1行のコードでダウンロードすることができます。 Hubに移動して、タスクでデータセットをフィルタリングしましょう: Hubの音声認識データセット…

機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。 これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。 このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください! 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択 目次: 機械バイアスについて 機械バイアス:機械学習システムからリスクへ バイアスをコンテキストに置く ツールと推奨事項 機械学習開発全体でのバイアスの対処 タスクの定義 データセットのキュレーション モデルのトレーニング 🤗のバイアスツールの概要 機械バイアス:機械学習システムから個人および社会的なリスクへ 機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。 しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます: 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。…

モデルカード
イントロダクション モデルカードは、機械学習モデルの理解、共有、改善のための重要なドキュメンテーションフレームワークです。適切に行われた場合、モデルカードは境界オブジェクトとして機能し、異なるバックグラウンドや目標を持つ人々(開発者、学生、政策立案者、倫理学者、機械学習モデルに影響を受ける人々など)がモデルを理解するためにアクセスできる単一のアーティファクトとなります。 今日、私たちはモデルカードの作成ツールとモデルカードガイドブックを発表しました。モデルカードの記入方法、ユーザースタディ、MLドキュメンテーションの最先端について詳しく説明しています。この作業は、他の多くの人々や組織によるものを基にしており、異なるバックグラウンドや役割を持つ人々の包括的な参加を重視しています。私たちは、これが改善されたMLドキュメンテーションの道筋となることを願っています。 要約すると、今日は以下のリリースを発表します: プログラムを必要とせずにカード作成を容易にするモデルカードクリエーターツール。さらに、異なるセクションの作業をチームで共有するための支援をします。 huggingface_hubライブラリでリリースされた更新されたモデルカードテンプレート。学界や業界全体でのモデルカードの作業をまとめています。 カードの記入方法を詳しく説明した注釈付きモデルカードテンプレート。 Hugging Faceでのモデルカードの使用に関するユーザースタディ。 モデルドキュメンテーションの最先端に関するランドスケープ分析と文献レビュー。 現在までのモデルカード モデルカードは、Mitchellらによって提案され、自然言語処理のデータステートメント(Bender&Friedman、2018)やデータセットのデータシート(Gebruら、2018)といった主要なドキュメンテーションフレームワークの努力に触発されています。機械学習ドキュメンテーションの領域は拡大し進化しており、データ、モデル、およびMLシステムのためのさまざまなドキュメンテーションツールやテンプレートが提案され、開発されてきました。これには、何百もの研究者、関係者、提唱者などの信じられないほどの研究成果が反映されています。また、MLドキュメンテーションと責任あるAIの変革理論との関係について重要な議論も、MLドキュメンテーションエコシステムの発展に影響を与えています。 ML内のドキュメンテーションにおけるこれまでの取り組みは、さまざまな対象に対応しています。私たちは、今日共有する作業でこれらのアイデアの多くを取り入れています。 私たちの取り組み 私たちの作業は、モデルカードの現在の状況と将来の展望を示しています。私たちは、成長するMLドキュメンテーションツールのランドスケープを広範に分析し、Hugging Face内でユーザーインタビューを行い、モデルカードに関する多様な意見を補完しました。また、Hugging Face HubのMLモデルに対してモデルカードを作成または更新し、これらの経験を基に新しいモデルカードのテンプレートを提案しています。 モデルカードの標準化 ガイドブックでさらに詳しく説明されている背景調査やユーザースタディを通じて、一般の人々が理解する「モデルカード」の新しい標準を確立することを目指しました。 これらの調査結果に基づいて、HFモデルカードの構造と内容を標準化するだけでなく、デフォルトのプロンプトテキストも提供する新しいモデルカードテンプレートを作成しました。このテキストは、モデルカードのセクションの執筆を支援するためのものであり、特にバイアス、リスク、制限のセクションに焦点を当てています。 アクセシビリティと包括性 モデルカードの作成における参加のハードルを下げるために、モデルカード作成ツールを設計しました。これは、グラフィカルユーザーインターフェース(GUI)を備えたツールであり、コーディングやマークダウンの使用を必要とせずに、さまざまなスキルセットや役割を持つ人々やチームが簡単に協力してモデルカードを作成できるようにします。 この作成ツールは、モデルカードをまだ作成していない人々に簡単に作成するように促し、以前にモデルカードを作成したことがある人々にはプロンプトされた情報を追加するように促します。同時に、倫理的な要素を重視します。…

CLIPSegによるゼロショット画像セグメンテーション
このガイドでは、🤗 transformersを使用して、ゼロショットの画像セグメンテーションモデルであるCLIPSegを使用する方法を紹介します。CLIPSegは、ロボットの知覚、画像補完など、さまざまなタスクに使用できるラフなセグメンテーションマスクを作成します。より正確なセグメンテーションマスクが必要な場合は、Segments.aiでCLIPSegの結果を改善する方法も紹介します。 画像セグメンテーションは、コンピュータビジョンの分野でよく知られたタスクです。これにより、コンピュータは画像内の物体を知るだけでなく(分類)、画像内の物体の位置を知ることもできます(検出)、さらには物体の輪郭も知ることができます。物体の輪郭を知ることは、ロボット工学や自動運転などの分野では重要です。たとえば、ロボットは物体の形状を正しく把握するために、その形状を知る必要があります。セグメンテーションは、画像補完と組み合わせることもでき、ユーザーが画像のどの部分を置き換えたいかを説明することができます。 ほとんどの画像セグメンテーションモデルの制限の1つは、固定されたカテゴリのリストでのみ機能するということです。たとえば、オレンジでトレーニングされたセグメンテーションモデルを使用して、リンゴをセグメント化することはできません。セグメンテーションモデルに追加のカテゴリを教えるには、新しいカテゴリのデータをラベル付けし、新しいモデルをトレーニングする必要があります。これは費用と時間がかかる場合があります。しかし、さらなるトレーニングなしにほとんどどのような種類のオブジェクトでもセグメント化できるモデルがあったらどうでしょうか?それがCLIPSeg、ゼロショットのセグメンテーションモデルが達成するものです。 現時点では、CLIPSegにはまだ制限があります。たとえば、モデルは352 x 352ピクセルの画像を使用するため、出力はかなり低解像度です。したがって、モダンなカメラの画像を使用すると、ピクセルパーフェクトな結果を期待することはできません。より正確なセグメンテーションを必要とする場合、前のブログ記事で示したように、最新のセグメンテーションモデルを微調整することができます。その場合、CLIPSegを使用してラフなラベルを生成し、Segments.aiなどのラベリングツールでそれらを調整することができます。それについて説明する前に、まずCLIPSegの動作を見てみましょう。 CLIP: CLIPSegの背後にある魔法のモデル CLIP(Contrastive Language–Image Pre-training)は、OpenAIが2021年に開発したモデルです。CLIPに画像またはテキストの一部を与えると、CLIPは入力の抽象的な表現を出力します。この抽象的な表現、または埋め込みとも呼ばれるものは、実際にはベクトル(数値のリスト)です。このベクトルは、高次元空間のポイントと考えることができます。CLIPは、似たような画像とテキストの表現も似たようにするようにトレーニングされています。つまり、画像とそれに合致するテキストの説明を入力すると、画像とテキストの表現が似ている(つまり、高次元のポイントが近くにある)ことになります。 最初はあまり役に立たないように思えるかもしれませんが、実際には非常に強力です。例えば、CLIPを使用して訓練されたことがないタスクで画像を分類する方法を簡単に見てみましょう。画像を分類するには、画像と選択肢となる異なるカテゴリをCLIPに入力します(例えば、画像と「りんご」、「オレンジ」などの単語を入力します)。CLIPは、画像と各カテゴリの埋め込みを返します。今、画像の埋め込みに最も近いカテゴリの埋め込みを確認するだけです。これで完了です!まるで魔法のようですね。 CLIPを使用した画像分類の例(出典)。 さらに、CLIPは分類だけでなく、画像検索(これが分類と似ていることがわかりますか?)、テキストから画像への変換モデル(DALL-E 2はCLIPで動作します)、物体検出(OWL-ViT)などにも使用できます。そして、私たちにとって最も重要なのは、画像セグメンテーションです。これでCLIPが機械学習において本当に画期的なものである理由がお分かりいただけるでしょう。 CLIPが非常にうまく機能する理由は、モデルがテキストのキャプション付きの膨大なデータセットでトレーニングされたからです。そのデータセットには、インターネットから取得した4億枚の画像テキストペアが含まれています。これらの画像にはさまざまなオブジェクトや概念が含まれており、CLIPはそれぞれのオブジェクトに対して表現を生成するのに優れています。 CLIPSeg: CLIPによる画像セグメンテーション CLIPSegは、CLIPの表現を使用して画像セグメンテーションマスクを作成するモデルです。Timo LüddeckeさんとAlexander Eckerさんによって公開されました。彼らは、CLIPモデルを凍結したまま、TransformerベースのデコーダをCLIPモデルの上にトレーニングすることで、ゼロショット画像セグメンテーションを達成しました。デコーダは、画像のCLIP表現とセグメンテーションしたい対象のCLIP表現を入力として受け取り、これらの2つの入力を使用して、CLIPSegデコーダは2値のセグメンテーションマスクを作成します。より詳しく言うと、デコーダはセグメンテーションしたい画像の最終的なCLIP表現だけでなく、CLIPのいくつかのレイヤーの出力も使用します。 ソース デコーダは、PhraseCutデータセットでトレーニングされています。このデータセットには、340,000以上のフレーズと対応する画像セグメンテーションマスクが含まれています。著者たちはまた、データセットのサイズを拡大するためにさまざまな拡張方法も試みました。ここでの目標は、データセットに存在するカテゴリだけでなく、未知のカテゴリもセグメンテーションできるようにすることです。実験の結果、デコーダは未知のカテゴリにも対応できることが示されています。…

ゲーム開発のためのAI:5日間で農業ゲームを作成するパート1
AIゲーム開発へようこそ! このシリーズでは、AIツールを使用してわずか5日間で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに組み込む方法を学ぶことができます。以下のようにAIツールを使用する方法を示します: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが必要ですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細をお読みください! 注意:このチュートリアルは、Unity開発とC#に精通している読者を対象としています。これらの技術に初めて触れる場合は、続ける前に「初心者向けUnityシリーズ」をご覧ください。 Day 1: アートスタイル ゲーム開発プロセスの最初のステップはアートスタイルを決定することです。農業ゲームのアートスタイルを決定するために、Stable Diffusionというツールを使用します。Stable Diffusionは、テキストの説明に基づいて画像を生成するオープンソースのモデルです。このツールを使用して、ゲームのビジュアルスタイルを作成します。 Stable Diffusionのセットアップ Stable Diffusionを実行するためのいくつかのオプションがあります:ローカルまたはオンラインです。デスクトップで十分なGPUを搭載しており、完全な機能を備えたツールセットを使用したい場合は、ローカルをお勧めします。それ以外の場合は、オンラインソリューションを実行できます。 ローカル Stable Diffusionをローカルで実行するためには、Automatic1111 WebUIを使用します。これは、Stable…
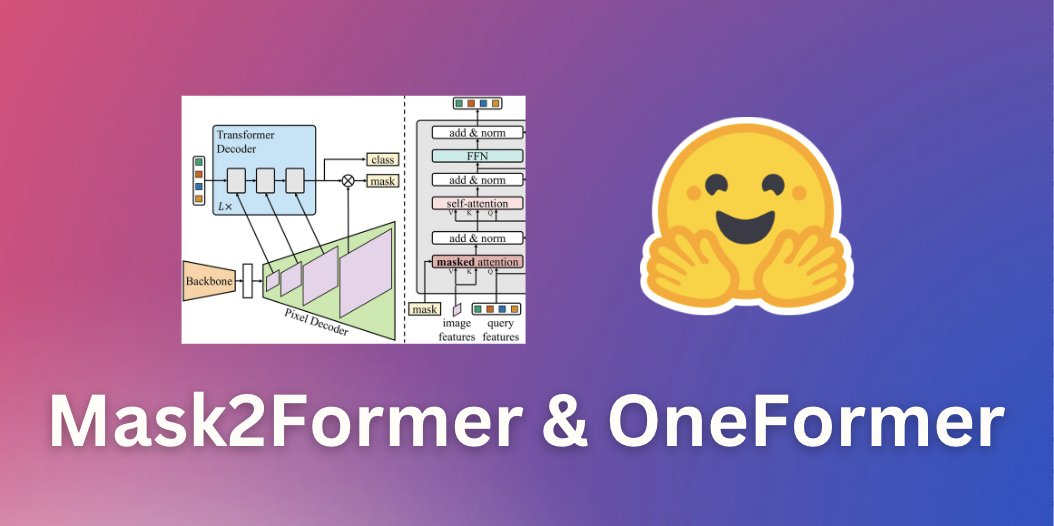
マスク2フォーマーとワンフォーマーによるユニバーサル画像セグメンテーション
このガイドでは、画像セグメンテーションのための最先端のニューラルネットワークであるMask2FormerとOneFormerを紹介します。これらのモデルは、最先端モデルの簡単な実装を提供するオープンソースのライブラリである🤗 transformersで利用できます。途中で、さまざまな形式の画像セグメンテーションの違いについて学びます。 画像セグメンテーション 画像セグメンテーションは、人や車などの画像内の異なる「セグメント」を識別するタスクです。より具体的には、画像セグメンテーションは異なる意味を持つピクセルをグループ化するタスクです。詳細については、Hugging Faceのタスクページを参照してください。 画像セグメンテーションは、主に3つのサブタスクに分割できます。それぞれのサブタスクを実行するための多数の方法とモデルアーキテクチャがあります。 インスタンスセグメンテーションは、画像内の個々の人物などの異なる「インスタンス」を識別するタスクです。インスタンスセグメンテーションは、オブジェクト検出と非常に似ていますが、境界ボックスではなく、対応するクラスラベルとともに一連のバイナリセグメンテーションマスクを出力したいという点が異なります。インスタンスはしばしば「オブジェクト」や「事物」とも呼ばれます。ただし、個々のインスタンスは重なる場合があります。 意味セグメンテーションは、画像の各ピクセルの「人」や「空」などの異なる「意味カテゴリ」を識別するタスクです。インスタンスセグメンテーションとは異なり、与えられた意味カテゴリの個々のインスタンスの区別はありません。たとえば、「人」のカテゴリのマスクを作成するだけであり、個々の人物のマスクを作成するわけではありません。対象カテゴリに個別のインスタンスがない「空」や「草」などの意味カテゴリは、しばしば「物」と呼ばれます(素晴らしい名前ですね)。ピクセルごとのカテゴリには重なりがないことに注意してください。 パノプティックセグメンテーションは、Kirillov et al.によって2018年に導入され、モデルが対応するバイナリマスクとクラスラベルのセットを単に識別することで、インスタンスセグメンテーションと意味セグメンテーションを統一することを目指しています。セグメントは「物」または「物」のどちらでもなります。インスタンスセグメンテーションとは異なり、異なるセグメント間の重なりはありません。 以下の図は、3つのサブタスクの違いを示しています(このブログ投稿から取得)。 ここ数年、研究者たちは通常、インスタンスセグメンテーション、意味セグメンテーション、パノプティックセグメンテーションのいずれかに特化したいくつかのアーキテクチャを提案してきました。インスタンスセグメンテーションとパノプティックセグメンテーションは、通常、オブジェクトインスタンスごとにバイナリマスクと対応するラベルのセットを出力することによって解決されました(インスタンス検出と非常に似ていますが、インスタンスごとに境界ボックスの代わりにバイナリマスクを出力します)。これは通常「バイナリマスク分類」と呼ばれます。一方、意味セグメンテーションは、モデルがピクセルごとに1つの「セグメンテーションマップ」を出力することで解決されることが一般的でした。したがって、意味セグメンテーションは「ピクセルごとの分類」の問題として扱われました。このパラダイムを採用する人気のある意味セグメンテーションモデルには、SegFormer(詳細なブログ投稿を書いた)とUPerNetなどがあります。 ユニバーサル画像セグメンテーション 幸いなことに、2020年ごろから、インスタンスセグメンテーション、意味セグメンテーション、およびパノプティックセグメンテーションのすべてのタスクを統一されたアーキテクチャで解決できるモデルが登場し始めました。これは最初にDETRが行ったものであり、”物”クラスと”物”クラスを統一的な方法で扱うことによってパノプティックセグメンテーションを解決した最初のモデルでした。キーイノベーションは、トランスフォーマーデコーダが並列的に一連のバイナリマスクとクラスを生成することでした。これはMaskFormerの論文で改善され、”バイナリマスク分類”のパラダイムが意味セグメンテーションにも非常にうまく適用されることが示されました。 Mask2Formerは、ニューラルネットワークアーキテクチャをさらに改善することで、インスタンスセグメンテーションにも拡張します。したがって、個別のアーキテクチャから、研究者たちが現在「ユニバーサル画像セグメンテーション」と呼んでいる、すべての画像セグメンテーションタスクを解決できるアーキテクチャに進化しました。興味深いことに、これらのユニバーサルモデルはすべて「マスク分類」のパラダイムを採用しており、完全に「ピクセルごとの分類」のパラダイムを廃止しています。Mask2Formerのアーキテクチャを示す図は、以下に示されています(オリジナルの論文から取得)。 要するに、画像はまずバックボーン(この論文ではResNetまたはSwin Transformerのどちらか)に送信されて、低解像度の特徴マップのリストを取得します。次に、これらの特徴マップは、ピクセルデコーダモジュールを使用して高解像度の特徴に改善されます。最後に、トランスフォーマーデコーダは一連のクエリを受け取り、ピクセルデコーダの特徴に基づいて一連のバイナリマスクとクラスの予測を行います。 Mask2Formerは、最先端の結果を得るために、各タスクごとにトレーニングする必要があることに注意してください。これは、OneFormerモデルによって改善されました。OneFormerモデルは、データセットのパノプティックバージョンのみをトレーニングすることで、すべての3つのタスクで最先端のパフォーマンスを実現します。さらに、テキストエンコーダを追加してモデルを「インスタンス」、「セマンティック」、または「パノプティック」の入力に条件付けることで、これをさらに改善しました。このモデルは、今日でも🤗 transformersで利用できます。Mask2Formerよりも精度が高くなっていますが、追加のテキストエンコーダにより遅延が大きくなります。OneFormerの概要については、以下の図を参照してください。Swin Transformerまたは新しいDiNATモデルをバックボーンとして使用しています。 TransformersでのMask2FormerとOneFormerの推論 Mask2FormerとOneFormerの使用法は非常に簡単であり、前身であるMaskFormerと非常に似ています。COCOパノプティックデータセットでトレーニングされたハブからMask2Formerモデルをインスタンス化し、それに対応するプロセッサもインスタンス化します。作者たちはさまざまなデータセットでトレーニングされた30個以上のチェックポイントをリリースしていることに注意してください。 from…

3Dアセット生成:ゲーム開発のためのAI#3
ゲーム開発のためのAIへようこそ! このシリーズでは、AIツールを使用してわずか5日間で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに組み込む方法を学ぶことができます。以下のようにAIツールを使用する方法を紹介します: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー 短いビデオバージョンが欲しいですか?こちらでご覧いただけます。それ以外の場合は、技術的な詳細を知りたい場合は読み続けてください! 注意:このチュートリアルは、Unity開発とC#に精通している読者を対象としています。これらの技術に初めて触れる方は、続ける前に「初心者向けUnityシリーズ」をご覧ください。 Day 3: 3Dアセット このチュートリアルシリーズの第2部では、ゲームデザインのためのAIを使用しました。具体的には、ChatGPTを使用してゲームのデザインをブレインストーミングしました。 このパートでは、AIを使用して3Dアセットを生成する方法について説明します。簡単な答えは「できません」です。テキストから3Dへの変換は、現在のところ実用的にゲーム開発に適用することはできません。ただし、それは非常に速く変わっています。続けて読んで、テキストから3Dへの現在の状態、なぜそれがまだ役に立たないのか、そしてテキストから3Dの未来について学びましょう。 テキストから3Dへの現在の状態 第1部で説明したように、Stable Diffusionなどのテキストから画像への変換ツールは、ゲーム開発のワークフローで非常に役立ちます。しかし、テキストから3D、つまりテキストの記述から3Dモデルを生成することに関しては、最近この分野で多くの進展がありました: DreamFusionは2D拡散を使用して3Dアセットを生成します。 CLIPMatrixとCLIP-Mesh-SMPLXは直接テクスチャ付きメッシュを生成します。 CLIP-Forgeは言語を使用してボクセルベースのモデルを生成します。 CLIP-NeRFはテキストと画像でNeRFを制御します。 Point-EおよびPulsar+CLIPは言語を使用して3Dポイントクラウドを生成します。 Dream TexturesはBlenderでシーンのテクスチャを自動的に生成するためのテキストから画像への変換を使用します。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.