Learn more about Search Results gradio - Page 16

- You may be interested
- UCサンディエゴとMeta AIの研究者がMonoNe...
- 2023年に検討すべきトップのAutoMLフレー...
- 中国の研究者たちは、構造化データに対す...
- ホワイトハウス、AI安全への懸念に対処す...
- 「コンダ遅すぎ? マンバを試してみて!」
- 仕事を加速するAIツール16選
- AIを通じて、AskEllyn Bridgesは乳がん患...
- 将来のアプリケーションを支える大規模言...
- 「Sierra DivisionがNVIDIA Omniverseを使...
- 新しいAI研究がGPT4RoIを紹介します:地域...
- 「ソーシャルメディアと機械学習を使用し...
- 部屋温超伝導体の主張を支持する研究
- 「365データサイエンスは、11月20日まで無...
- 「アジア競技大会、eスポーツがオリンピッ...
- 『DiffBIRを紹介:事前学習済みのテキスト...

TensorFlowとXLAを使用した高速なテキスト生成
TL;DR : TensorFlowを使用した🤗transformersを使ったテキスト生成は、XLAでコンパイルできるようになりました。これにより、以前よりも最大100倍高速化され、PyTorchよりもさらに高速になりました – 以下のコラボをチェックしてください! テキスト生成 大規模言語モデルの品質が向上するにつれて、そのモデルができることに対する私たちの期待も高まりました。特にOpenAIのGPT-2のリリース以来、テキスト生成機能を持つモデルが注目されています。そして、その理由は妥当です – これらのモデルは要約、翻訳、さらにはいくつかの言語タスクでのゼロショット学習能力のデモンストレーションを行うことができます。このブログ記事では、TensorFlowを使用してこのテクノロジーを最大限に活用する方法を紹介します。 🤗transformersライブラリはNLPモデルから始まりましたので、テキスト生成は私たちにとって非常に重要な要素です。アクセス可能で、簡単に制御可能で効率的であることをHugging Faceの民主化の取り組みの一環として保証することが目的です。テキスト生成のさまざまなタイプについては以前のブログ記事があります。ただし、以下にコア機能のクイックな概要があります – 私たちのgenerate関数に慣れている場合や、TensorFlowの特異性に直接ジャンプしたい場合は、スキップしても構いません。 まずは基本から始めましょう。テキスト生成は、do_sampleフラグによって確定的または確率的になります。デフォルトでは、Falseに設定されており、出力は確定的であるため、Greedy Decodingとも呼ばれます。それをTrueに設定すると、サンプリングとも呼ばれるため、出力は確率的になりますが、seed引数(stateless TensorFlowのランダム数生成と同じ形式)を介して再現可能な結果を得ることもできます。一般的なガイドラインとして、モデルから事実情報を得る場合は確定的な生成を、よりクリエイティブな出力を目指す場合は確率的な生成を望むでしょう。 # transformers >= 4.21.0が必要です # サンプリングの出力は、使用するハードウェアによって異なる場合があります。 from transformers…

Hugging Face Spacesでタンパク質を可視化する
この投稿では、Hugging Face Spacesでタンパク質を可視化する方法について見ていきます。 動機 🤗 タンパク質は、医薬品から洗剤まで私たちの生活に大きな影響を与えています。タンパク質の機械学習は、新しい興味深いタンパク質の設計を支援するための急速に成長している分野です。タンパク質は、主にアミノ酸と呼ばれる一連の構成要素を3D空間に配列して、タンパク質の機能を与える複雑な3Dオブジェクトです。機械学習の目的で、タンパク質は、例えば座標、グラフ、またはタンパク質言語モデルで使用するための1次元の文字列として表現することができます。 タンパク質の有名な機械学習モデルの一つにAlphaFold2があります。AlphaFold2は、類似のタンパク質の多重配列と構造モジュールを使用してタンパク質配列の構造を予測します。 AlphaFold2が登場して以来、OmegaFold、OpenFoldなど、さまざまなモデルが登場しました(詳細はこのリストやこのリストを参照)。 見ることは信じること タンパク質の構造は、タンパク質の機能を理解する上で重要な要素です。現在、mol*や3dmol.jsなどのブラウザで直接タンパク質を可視化するためのツールがいくつか利用可能です。この投稿では、3Dmol.jsとHTMLブロックを使用して、Hugging Face Spaceに構造可視化を統合する方法を学びます。 必要条件 すでにgradio Pythonパッケージがインストールされていること、およびJavascript / JQueryの基本的な知識を持っていることを確認してください。 コードの概要 3Dmol.jsのセットアップ方法に入る前に、インターフェースの最小機能デモを作成する方法を見てみましょう。 以下のコードは、4桁のPDBコードまたはPDBファイルを受け入れる簡単なデモアプリを作成します。アプリは、RCSB Protein Databankからpdbファイルを取得して表示するか、アップロードされたファイルを使用して表示します。 import gradio…

ディフューザーの新着情報は何ですか?🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。 画像から画像へのパイプライン テキストの逆転 インペインティング より小さなGPUに最適化 Mac上で実行 ONNXエクスポーター 新しいドキュメント コミュニティ SD潜在空間での動画生成 モデルの説明可能性 日本語のStable Diffusion 高品質なファインチューニングモデル Stable Diffusionによるクロスアテンション制御 再利用可能なシード 画像から画像へのパイプライン 最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます! 公式のColabノートブックに基づいたコードを見てみましょう。 from diffusers import…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…

Hugging Faceの機械学習デモ(arXiv上)
私たちは、Hugging FaceがarXivと協力して論文をよりアクセスしやすく、見つけやすく、楽しくすることを発表できることを非常に嬉しく思っています!今日から、Hugging Face SpacesはarXivLabsとの統合を通じて、コミュニティまたは著者自身によって作成されたデモへのリンクを含むDemoタブとして提供されます。お気に入りの論文のデモタブに移動することで、オープンソースのデモへのリンクを見つけ、すぐに試すことができます🔥 Hugging Face Spacesは2021年10月のローンチ以来、コミュニティによって作成された12,000以上のオープンソースの機械学習デモを構築し共有するために使用されています。Spacesを使用すると、Hugging Faceユーザーはブラウザを使用してコードを実行することなく、モデルを共有、探索、議論し、対話型アプリケーションを構築することができます。これらのデモは、GradioやStreamlitなどのオープンソースのツールを使用し、Hugging Face Hubで利用可能なモデルとデータセットを活用して構築されています。 最新のarXivの統合により、ユーザーは論文のarXivの要約ページで最も人気のあるデモを見つけることができます。たとえば、BERT言語モデルのデモを試したい場合は、BERT論文のarXivページに移動し、デモタブに移動します。そこには、オープンソースコミュニティによって作成された200以上のデモが表示されます。一部のデモは単にBERTモデルを紹介しているだけであり、他のデモはBERTをより大きなパイプラインの一部として変更または使用する関連アプリケーションを紹介しています。上記のデモのようなものです。 デモにより、機械学習だけでなく、生物学、化学、天文学、経済学など、計算モデルが構築される他の分野を広範な視聴者が探索できるようになります。デモはモデルの動作原理の認識と理解を高め、研究者の仕事の可視性を高め、より多様な視聴者がバイアスやその他の問題を特定およびデバッグできるようにします。これらのデモにより、コードを一行も書くことなく、他の人が論文の結果を探索することができるため、研究の再現性が向上します!arXivとのこの統合に興奮しており、研究コミュニティがコミュニケーション、発信、解釈性を向上させるためにどのように活用するかを楽しみにしています。
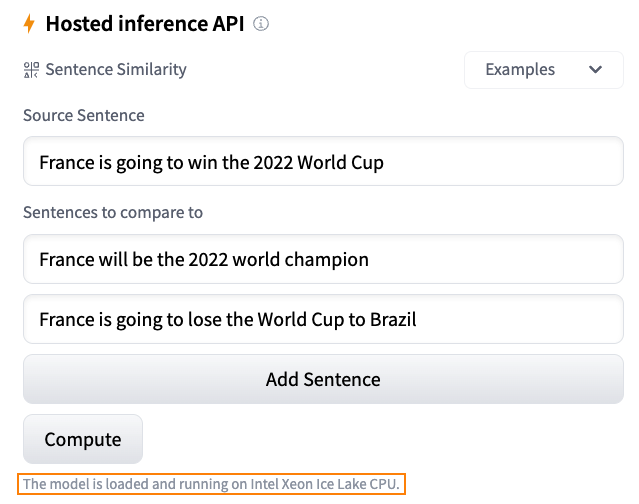
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。 これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。 このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください! 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択 目次: 機械バイアスについて 機械バイアス:機械学習システムからリスクへ バイアスをコンテキストに置く ツールと推奨事項 機械学習開発全体でのバイアスの対処 タスクの定義 データセットのキュレーション モデルのトレーニング 🤗のバイアスツールの概要 機械バイアス:機械学習システムから個人および社会的なリスクへ 機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。 しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます: 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。…

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
動機 トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。 しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました! PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。 また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。 つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。 本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です: LoRA:LORA:大規模言語モデルの低ランク適応 Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力 P-Tuning:GPTも理解しています ユースケース ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です: Google Colabで、Nvidia GeForce RTX…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.