Learn more about Search Results documentation - Page 16

- You may be interested
- シンガポール国立大学の研究者たちは、ピ...
- データサイエンティストとして成功するた...
- 「MLOps をマスターするための5つの無料コ...
- 2023年に知っておくべきトップ10のパワフ...
- 「DevOpsとDataOpsとの私の経験」
- 「仕事を守るために自動化を避ける」
- [GPT-4V-Actと出会いましょう:GPT-4V(isi...
- 「独立性の理解とその因果推論や因果検証...
- 刑事弁護士が警告する:AIは、法廷が「自...
- ドローンが風力タービンを氷から保護する
- 「ウェアラブルデータによるコロナ感染予測」
- トロント大学の研究者が、大規模な材料デ...
- 「量子コンピュータを使用して暗黒物質を...
- 研究者たちは、医薬品の製造において画期...
- サイバー犯罪の推進者’ (Saibā hanz...

iPhone、iPad、およびMacでのCore MLによる高速で安定した拡散
先週、WWDC’23(Apple Worldwide Developers Conference)が開催されました。キーノート中のVision Proの発表に焦点が当てられましたが、それだけではありません。毎年のように、WWDC週はAppleのオペレーティングシステムとフレームワークの新機能について深く掘り下げる200以上の技術セッションが詰まっています。今年は特に、圧縮と最適化のためのCore MLの変更に興奮しています。これらの変更により、Stable Diffusionなどのモデルの実行が高速化され、メモリ使用量も少なくなります!一例として、12月にiPhone 13で実行したテストと現在の6ビットパレット化を使用した速度の比較を考えてみましょう: 12月のiPhoneでのStable Diffusionと現在の6ビットパレット化 目次 新しいCore MLの最適化 量子化および最適化されたStable Diffusionモデルの使用 カスタムモデルの変換と最適化 6ビット未満の使用 結論 新しいCore MLの最適化 Core MLは、Appleのデバイス内で効率的に機械学習モデルを実行するための成熟したフレームワークであり、CPU、GPU、およびMLタスクに特化したニューラルエンジンなど、Appleデバイスのすべてのコンピューティングハードウェアを活用します。デバイス上での実行は、Stable Diffusionや大規模な言語モデルの人気によって引き起こされた非常に興味深い時期を迎えています。多くの人々がこれらのモデルをさまざまな理由でハードウェア上で実行したいと考えており、利便性やプライバシー、APIのコスト削減などがその理由です。自然に、多くの開発者がデバイス上でこれらのモデルを効率的に実行する方法を探求し、新しいアプリやユースケースを作成しています。この目標を達成するためのCore MLの改善は、コミュニティにとって大きなニュースです!…

Hugging Faceのパネル
私たちは、PanelとHugging Faceのコラボレーションを発表できることを喜んでいます!🎉 Hugging Face SpacesにPanelのテンプレートを統合しました。これにより、Panelアプリを簡単に構築し、Hugging Face上で簡単にデプロイすることができます。 Panelは何を提供していますか? Panelは、Pythonで強力なツール、ダッシュボード、複雑なアプリケーションを簡単に構築できるオープンソースのPythonライブラリです。PyDataエコシステム、パワフルなデータテーブルなどがすぐに利用できるようになっています。高レベルのリアクティブAPIと低レベルのコールバックベースのAPIにより、探索的なアプリケーションを素早く構築することができます。また、複雑なマルチページアプリケーションや豊富な相互作用を持つアプリケーションを構築することも制限されません。PanelはHoloVizエコシステムの一員であり、データ探索ツールの連携エコシステムへのゲートウェイです。Panelは、他のHoloVizツールと同様に、NumFocusがスポンサーとなっており、AnacondaとBlackstoneからのサポートを受けています。 以下は、私たちのユーザーが価値を見出しているPanelのいくつかの注目すべき機能です。 Panelは、Matplotlib、Seaborn、Altair、Plotly、Bokeh、PyDeck、Vizzuなど、さまざまなプロットライブラリに広範なサポートを提供しています。 すべての相互作用は、Jupyterとスタンドアロンのデプロイメントで同じように機能します。Panelは、Jupyterノートブックからダッシュボードにコンポーネントをシームレスに統合することができ、データ探索と結果の共有の間でスムーズな移行を実現します。 Panelは、複雑なマルチページアプリケーション、高度な相互作用機能、大規模データセットの可視化、リアルタイムデータのストリーミングを構築することができます。 PyodideとWebAssemblyとの統合により、PanelアプリケーションをWebブラウザでシームレスに実行することができます。 Hugging FaceでPanelアプリを構築する準備はできましたか?Hugging Faceのデプロイメントドキュメントをチェックして、このボタンをクリックして旅を始めましょう: 🌐 コミュニティに参加しましょう Panelコミュニティは活気があり、サポートが充実しており、経験豊富な開発者やデータサイエンティストが知識を共有したり、助け合ったりすることを楽しみにしています。以下の方法で参加し、私たちとつながりましょう: Discord Discourse Twitter LinkedIn Github

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

倫理と社会ニュースレター#4:テキストから画像へのモデルにおけるバイアス
要約: テキストから画像へのモデルのバイアスを評価するためにより良い方法が必要です はじめに テキストから画像(TTI)生成は最近のトレンドであり、数千のTTIモデルがHugging Face Hubにアップロードされています。各モダリティは異なるバイアスの影響を受ける可能性がありますが、これらのモデルのバイアスをどのように明らかにするのでしょうか?このブログ投稿では、TTIシステムのバイアスの源泉、それらに対処するためのツールと潜在的な解決策について、私たち自身のプロジェクトと広範なコミュニティのものを紹介します。 画像生成における価値観とバイアスのエンコード バイアスと価値観には非常に密接な関係があります。特に、これらが与えられたテキストから画像モデルのトレーニングやクエリに埋め込まれている場合、この現象は生成された画像に大きな影響を与えます。この関係は、広範なAI研究分野で知られており、それに対処するためのかなりの努力が進行中ですが、特定のモデルで進化する人々の価値観を表現しようとする複雑さは依然として存在しています。これは、適切に明らかにし、対処するための持続的な倫理的な課題を提起します。 たとえば、トレーニングデータが主に英語である場合、それはおそらく西洋の価値観を伝えています。その結果、異なる文化や遠い文化のステレオタイプな表現が得られます。以下の例では、同じプロンプト「北京の家」に対してERNIE ViLG(左)とStable Diffusion v 2.1(右)の結果を比較すると、この現象が顕著に現れます: バイアスの源泉 近年、自然言語処理(Abidら、2021年)およびコンピュータビジョン(BuolamwiniおよびGebru、2018年)の両方の単一モダリティのAIシステムにおけるバイアス検出に関する重要な研究が行われています。MLモデルは人々によって構築されるため、すべてのMLモデル(そして技術全般)にはバイアスが存在します。これは、画像の中で特定の視覚的特性が過剰または過少に表現される(たとえば、オフィスワーカーのすべての画像にネクタイがある)ことや、文化的および地理的なステレオタイプの存在(たとえば、白いドレスとベールを着た花嫁のすべての画像、代表的な花嫁のイメージである赤いサリーの花嫁など)が現れることで現れます。AIシステムは広く異なるセクターやツール(例:Firefly、Shutterstock)に展開される社会技術的なコンテキストで展開されるため、既存の社会的なバイアスや不平等を強化する可能性があります。以下にバイアスの源泉の非徹底的なリストを示します: トレーニングデータのバイアス:テキストから画像への変換のための人気のあるマルチモーダルデータセット(たとえば、テキストから画像へのLAION-5B、画像キャプショニングのMS-COCO、ビジュアルクエスチョンアンサリングのVQA v2.0など)には、多数のバイアスや有害な関連が含まれていることが判明しています(Zhaoら、2017年、PrabhuおよびBirhane、2021年、Hirotaら、2022年)。これらのデータセットでトレーニングされたモデルには、画像生成の多様性の欠如や、文化やアイデンティティグループの共通のステレオタイプが永続化するという初期の結果がHugging Face Stable Biasプロジェクトから示されています。たとえば、CEO(右)とマネージャー(左)のDall-E 2の生成結果を比較すると、両方とも多様性に欠けていることがわかります: 事前トレーニングデータのフィルタリングにおけるバイアス:モデルのトレーニングに使用される前に、データセットに対して何らかの形のフィルタリングが行われることがよくあります。これにより、異なるバイアスが導入されます。たとえば、Dall-E 2の作者たちは、トレーニングデータのフィルタリングが実際にバイアスを増幅することを発見しました。これは、既存のデータセットが女性をより性的な文脈で表現するというバイアスや、使用されるフィルタリング手法の固有のバイアスに起因する可能性があると彼らは仮説を立てています。 推論におけるバイアス:Stable…
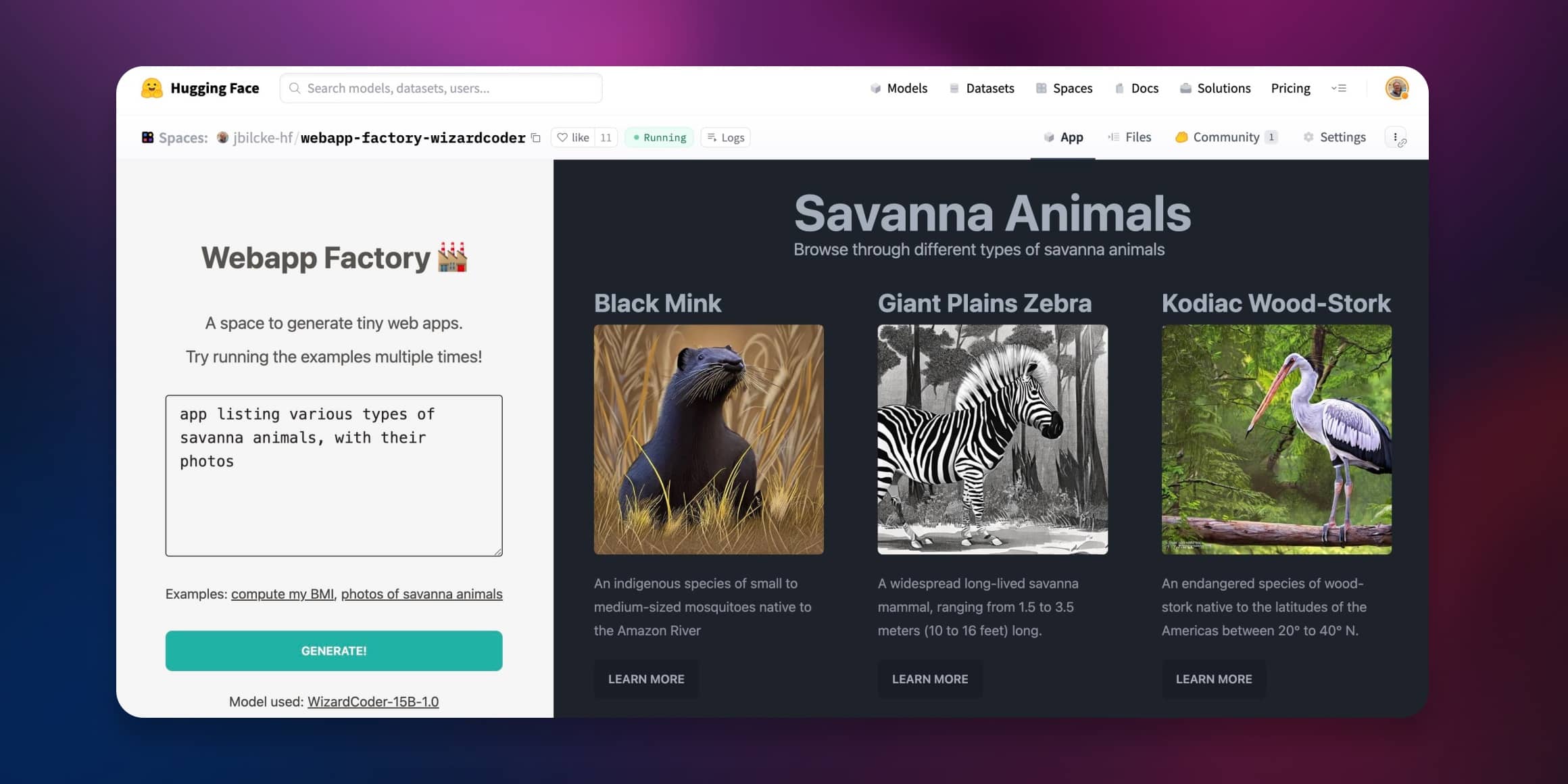
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

Transformers.jsを使用してMLを搭載したウェブゲームの作成
このブログ記事では、ブラウザ上で完全に動作するリアルタイムのMLパワードWebゲーム「Doodle Dash」を作成した方法を紹介します(Transformers.jsのおかげで)。このチュートリアルの目的は、自分自身でMLパワードのWebゲームを作成するのがどれだけ簡単かを示すことです… ちょうどOpen Source AI Game Jam(2023年7月7日-9日)に間に合います。まだ参加していない場合は、ぜひゲームジャムに参加してください! ビデオ:Doodle Dashデモビデオ クイックリンク デモ:Doodle Dash ソースコード:doodle-dash ゲームジャムに参加:Open Source AI Game Jam 概要 始める前に、作成する内容について話しましょう。このゲームは、GoogleのQuick, Draw!ゲームに触発されており、単語とニューラルネットワークが20秒以内にあなたが描いているものを推測するというものです(6回繰り返し)。実際には、彼らのトレーニングデータを使用して独自のスケッチ検出モデルを訓練します!オープンソースは最高ですよね? 😍 このバージョンでは、1つのプロンプトずつできるだけ多くのアイテムを1分間で描くことができます。モデルが正しいラベルを予測した場合、キャンバスがクリアされ、新しい単語が与えられます。タイマーが切れるまでこれを続けてください!ゲームはブラウザ内でローカルに実行されるため、サーバーの遅延について心配する必要はありません。モデルはあなたが描くと同時にリアルタイムの予測を行うことができます… 🤯…

PDFからのエンティティ抽出をLLMsを使用して自動化する方法
現代の機械学習アプリケーションにおいて、高品質なラベル付きデータの必要性は言い尽くせませんモデルの性能向上から公平性の確保まで、ラベル付きデータの力は非常に大きいです...
Pythonプロジェクトのセットアップ:パートV
経験豊富な開発者であろうと、🐍 Pythonを始めたばかりであろうと、堅牢で保守性の高いプロジェクトの構築方法を知ることは重要ですこのチュートリアルでは、...のプロセスを案内します
レコメンダーシステムにおけるPrecision@NとRecall@Nの解説
Accuracy Metrics(正解率指標)は、機械学習の全体的なパフォーマンスを評価するための有用な指標であり、データセット内の正しく分類されたインスタンスの割合を示します評価指標では…

Amazon SageMaker StudioでAmazon SageMaker JumpStartの独自の基盤モデルを使用してください
Amazon SageMaker JumpStartは、機械学習(ML)の旅を加速するのに役立つMLハブですSageMaker JumpStartを使用すると、公開されているものと独自のファウンデーションモデルを探索して、生成型AIアプリケーションのための専用のAmazon SageMakerインスタンスに展開できますSageMaker JumpStartは、ネットワーク隔離環境からファウンデーションモデルを展開することができます[...]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.