Learn more about Search Results arXiv - Page 16

- You may be interested
- 天候の変化:AI、高速計算がより速く、効...
- 『React開発の向上:ChatGPTの力を解き放...
- テキサス大学の研究者たちは、機械学習を...
- クラゲ、猫、ヘビ、宇宙飛行士は何を共有...
- 「アドビが新しい生成AIモデルで未来のデ...
- 「データビジュアル化のためのWebスクレイ...
- 「ChatGPTコードインタプリタは、すべての...
- 「NVIDIAのCEO、ジェンソン・ホアン氏がSI...
- 『UltraFastBERT:指数関数的に高速な言語...
- 「サイバーセキュリティとAI、テキサスサ...
- ハイパーヒューマンに会ってください:潜...
- 「オープンソースモデルと商用AI/ML APIの...
- ドローンが風力タービンを氷から保護する
- 「限られた訓練データで機械学習モデルは...
- 「AIオバマ」とフェイクニュースキャスタ...

「2023年に機械学習とコンピュータビジョンの進歩について最新情報を入手する方法」
学界や産業界で実践している機械学習やコンピュータビジョンの最近の進展に圧倒されていますか?YouTubeチャンネル、ニュースレター、ポッドキャスト、プラットフォームなどを知っていますか?
Mozilla Common Voiceでの音声言語認識-第II部:モデル
これはMozilla Common Voiceデータセットに基づく音声認識に関する2番目の記事です最初の部分ではデータの選択と最適な埋め込みの選択について議論しましたさて、いくつかのトレーニングを行いましょう...

『nnU-Netの究極ガイド』
「画像セグメンテーションの主要なツールであるnnU-Netについて、詳細なガイドに深く入り込んでください最先端の結果を得るための知識を獲得しましょう」

PythonでのZeroからAdvancedなPromptエンジニアリングをLangchainで
大規模言語モデル(LLM)の重要な要素は、これらのモデルが学習に使用するパラメータの数ですモデルが持つパラメータが多いほど、単語やフレーズの関係をより理解することができますつまり、数十億のパラメータを持つモデルは、さまざまな創造的なテキスト形式を生成し、開放的な質問に回答する能力を持っています

「医療分野における生成型AI」
はじめに 生成型人工知能は、ここ数年で急速に注目を集めています。医療と生成型人工知能の間に強い関係性が生まれていることは驚くことではありません。人工知能(AI)はさまざまな産業を急速に変革しており、医療分野も例外ではありません。AIの特定のサブセットである生成型人工知能は、医療分野において画期的な存在となっています。 生成型AIシステムは、新しいデータ、画像、さらには完全な芸術作品を生成することができます。医療分野では、この技術は診断、新薬の発見、患者ケア、医学研究の向上において非常に有望です。本記事では、医療分野における生成型人工知能の潜在的な応用と利点、実装上の課題、倫理的な考慮事項について探究します。 学習目標 GenAIとその医療分野への応用 GenAIの医療分野における潜在的な利点 医療分野における生成型AIの実装上の課題と制約 医療分野における生成型AIの将来的な展望 本記事は、Data Science Blogathonの一環として公開されました。 医療分野における生成型人工知能の潜在的な応用 医療分野において、GenAIをどのように活用できるかについて、いくつかの研究が行われています。GenAIは、新薬のための分子構造や化合物の生成に影響を与え、有望な薬剤候補の同定と発見を促進しています。これにより、先端技術を活用しながら時間とコストを節約することが可能です。以下は、これらの潜在的な応用の一部です: 医療画像および診断の向上 医療画像は、診断と治療計画において重要な役割を果たしています。生成型AIアルゴリズム(生成対抗的ネットワーク(GAN)や変分オートエンコーダー(VAE)など)は、医療画像解析を大幅に改善しています。これらのアルゴリズムは、実際の患者データに似た合成医療画像を生成することができ、機械学習モデルのトレーニングと検証に役立ちます。また、限られたデータセットを補完するために追加のサンプルを生成することで、画像に基づく診断の正確性と信頼性を向上させることもできます。 薬剤の発見と開発の促進 新薬の発見と開発は、複雑で時間がかかり、費用がかかる作業です。生成型AIは、所望の特性を持つ仮想化合物や分子を生成することで、このプロセスを大幅に加速することができます。研究者は、生成モデルを用いて広大な化学空間を探索し、新たな薬剤候補を同定することができます。これらのモデルは既存のデータセット(既知の薬剤構造と関連する特性を含む)から学習し、望ましい特性を持つ新しい分子を生成します。 個別化医療と治療 生成型AIは、患者データを活用して個別化された治療計画を作成することで、個別化医療を革新する潜在能力を持っています。電子健康記録、遺伝子プロファイル、臨床結果などの大量の患者情報を分析することにより、生成型AIモデルは個別化された治療の推奨を生成することができます。これらのモデルはパターンを特定し、病気の進行を予測し、介入に対する患者の反応を推定することができるため、医療提供者は情報に基づいた意思決定を行うことができます。 医学研究と知識生成 生成型AIモデルは、特定の特性と制約を満たす合成データを生成することで、医学研究を支援することができます。合成データは、機密性の高い患者情報の共有に関連するプライバシーの問題を解決しながら、研究者が有益な洞察を抽出し、新たな仮説を開発することができます。 また、生成型AIは臨床試験のための合成患者コホートを生成することもできます。これにより、研究者はさまざまなシナリオをシミュレートし、実際の患者に対する高価で時間のかかる試験を実施する前に治療の効果を評価することができます。この技術は、医学研究を加速し、イノベーションを推進し、複雑な疾患に対する理解を広げる可能性があります。 事例研究: CPPE-5…
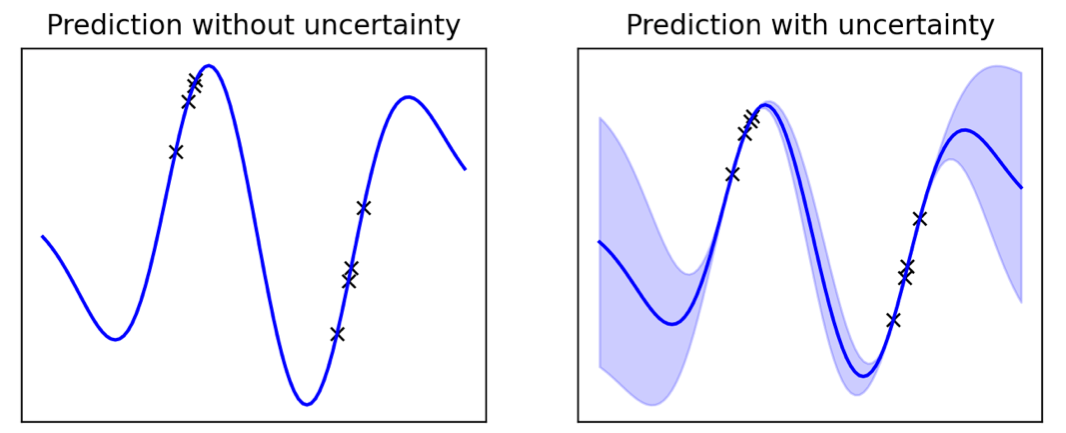
ベイズ深層学習への優しい入門
「確率的プログラミングの興奮する世界へようこそ!この記事は初心者向けのベイズ深層学習とディープニューラルネットワークの紹介です」

OpenAIの進化:GPT5への競争
最近、自然言語処理(NLP)の分野では、生成事前学習トランスフォーマー(GPT)モデルが最も強力なものとして登場し、重要な進展が見られています

『私をすばやく中心に置いてください:主題拡散は、オープンドメインのパーソナライズされたテキストから画像生成を実現できるAIモデルです』
テキストから画像へのモデルは、過去1年間のAIの議論の中心でした。この分野の進歩は非常に迅速に起こり、その結果、印象的なテキストから画像へのモデルが存在します。生成型AIは新しいフェーズに入っています。 拡散モデルはこの進歩の主要な貢献者でした。これらのモデルは強力な生成モデルの一部として登場しました。これらのモデルは、望ましい画像にゆっくりとノイズを除去することによって高品質の画像を生成するよう設計されています。拡散モデルは隠れたデータパターンを捉え、多様で現実的なサンプルを生成することができます。 拡散ベースの生成モデルの急速な進歩は、テキストから画像の生成方法を革新しました。思いつくものは何でも画像として要求でき、モデルは非常に正確にそれを生成することができます。さらに進歩が進むにつれて、AIによって生成された画像がどれであるかを理解するのが難しくなってきています。 しかし、ここには問題があります。これらのモデルは画像を生成するためにテキストの説明にのみ頼っています。あなたは見たいものを「説明」することしかできません。さらに、ほとんどの場合、それを個人化することは容易ではありません。 自分の家のインテリアデザインを行い、建築家と協力すると想像してみてください。建築家は以前のクライアントのために作成したデザインしか提供できず、デザインの一部を個人化しようとしても無視され、別の使用済みのスタイルが提供されるだけです。とても満足できるとは言えませんね。これが個人化を求める場合、テキストから画像へのモデルで得られる体験になるかもしれません。 幸いなことに、これらの制限を克服する試みが行われています。研究者は、テキストの説明と参照画像を統合してより個人化された画像生成を実現する方法を探求しました。一部の方法では、特定の参照画像での微調整が必要ですが、他の方法では個人化したデータセットでベースモデルを再学習することにより、忠実度と汎化性能に潜在的な欠点が生じます。さらに、既存のアルゴリズムのほとんどは特定のドメインに特化しており、マルチコンセプトの生成、テスト時の微調整、およびオープンドメインのゼロショット能力の処理には手が届きません。 そこで、今日は私たちがオープンドメインの個人化に一歩近づいた新しいアプローチについて紹介します。それがSubject-Diffusionです。 SubjectDiffusionは高品質な主題駆動型画像を生成することができます。出典: https://arxiv.org/pdf/2307.11410.pdf Subject-Diffusionは革新的なオープンドメインの個人化テキストから画像への生成フレームワークです。1つの参照画像のみを使用し、テスト時の微調整の必要性を排除しています。個人化画像生成のための大規模なデータセットを構築するために、自動データラベリングツールを活用し、76百万枚の画像と22億2200万のエンティティを備えたSubject-Diffusionデータセット(SDD)が作成されました。 Subject-Diffusionには、3つの主要なコンポーネントがあります:位置制御、細かい参照画像制御、および注目制御です。位置制御では、ノイズ注入プロセス中に主要な主題のマスク画像を追加します。細かい参照画像制御では、テキストと画像の情報を組み合わせたモジュールを使用して、両方の細かさの統合を改善します。複数の主題のスムーズな生成を可能にするために、トレーニング中に注目制御が導入されます。 SubjectDiffusionの概要。出典: https://arxiv.org/pdf/2307.11410.pdf Subject-Diffusionは高い忠実度と汎化性能を実現し、1つの参照画像ごとに形状、姿勢、背景、スタイルの変更を加えた単一の主題、複数の主題、人物主体の個人化画像を生成することができます。また、特別に設計されたノイズ除去プロセスを介して、カスタマイズされた画像とテキストの説明との間のスムーズな補間を可能にします。定量的な比較によれば、Subject-Diffusionはさまざまなベンチマークデータセットで、テスト時の微調整あり・なしの他の最先端手法と比較して優れた性能を示しています。

大規模画像モデルのための最新のCNNカーネル
「OpenAIのChatGPTの驚異的な成功が大型言語モデルのブームを引き起こしたため、多くの人々が大型画像モデルにおける次のブレークスルーを予測していますこの領域では、ビジョンモデルは...」
モジラのコモンボイスでの音声言語認識 — Part I.
「話者の言語を特定することは、後続の音声テキスト変換のために最も困難なAIのタスクの一つですこの問題は、例えば人々が住んでいる場所で発生することがあります...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.