Learn more about Search Results ML - Page 16

- You may be interested
- RLHF:人間のフィードバックからの強化学習
- オリゴが警告を発しています:TorchServe...
- 話してください:モデルが読み取る単語の...
- AIキャリアのトレンド:人工知能の世界で...
- 「フリーノイズ」にご挨拶:複数のテキス...
- GPTエンジニア:1つのプロンプトで強力な...
- ジェネレーティブAIアプリケーションを構...
- 極小データセットを用いたテキスト分類チ...
- 私は5ヶ月間、毎日ChatGPTを使用しました...
- LLMs(Language Model)と知識グラフ
- 「ビートルズの新曲「今とかつて」では、A...
- In Japanese, the title would be written...
- 「Google Chromeは、努力を要さずに読むこ...
- 「AIがキーストロークを聞く:新たなデー...
- 「カナダでウェブサイトを立ち上げる方法」
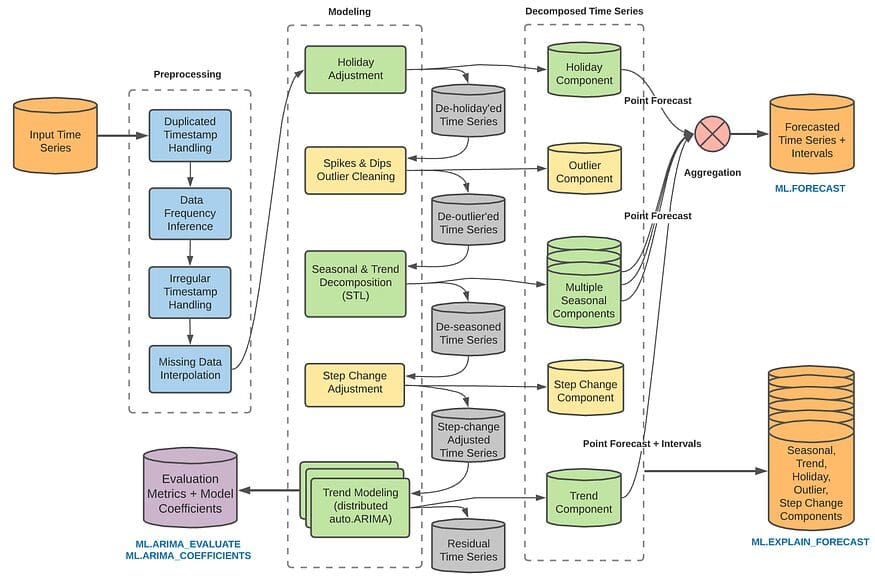
BQMLを使用した多変量時系列予測
GoogleのBQMLは、時系列モデルを作成するために使用することができます最近、マルチバリエート時系列モデルを作成するためにアップデートされましたこの記事では、シンプルなコードを使用してマルチバリエート時系列の予測方法を紹介し、単変量時系列モデルよりも強力な性能を発揮することができます
「データサイエンスプロジェクトを変革する:YAMLファイルに変数を保存する利点を見つけよう」
このブログ投稿では、データサイエンスプロジェクトで変数、パラメータ、ハイパーパラメータを保存するための中心的なリポジトリとしてYAMLファイルを使用するメリットについて説明しますこれによって、どのように...

「MLOpsの全機械学習ライフサイクルをカバーする:論文要約」
このAIの論文は、MLOpsの分野に関する包括的な調査を提供しています。MLOpsは、機械学習のライフサイクル全体を自動化することに焦点を当てた新興の学問です。この調査は、MLOpsのパイプライン、課題、ベストプラクティスなど、幅広いトピックをカバーしています。モデルの要件分析、データの収集、データの準備、特徴量エンジニアリング、モデルのトレーニング、評価、システムの展開、モデルの監視など、機械学習プロセスのさまざまなフェーズについて詳しく説明しています。さらに、ビジネス価値、品質、人間の価値、倫理など、ライフサイクル全体での重要な考慮事項についても議論されています。 この論文は、MLOpsの包括的な調査を提示し、機械学習のライフサイクルを自動化することの重要性を強調しています。調査では、MLOpsのパイプライン、課題、ベストプラクティス、および機械学習プロセスのさまざまなステージについて取り上げています。 この論文は以下の図でまとめられています: https://arxiv.org/abs/2304.07296: 機械学習プロセス モデルの要件分析 機械学習プロジェクトを始めるために、ステークホルダーはモデルの要件を分析し特定する必要があります。このセクションでは、ビジネス価値、モデルの品質、人間の価値(プライバシー、公正性、セキュリティ、責任)、倫理の4つの基本的な側面について説明しています。ステークホルダーは目的を定義し、価値と問題を特定するためのツールを評価し、要件を優先順位付けし、関連するステークホルダーを巻き込み、必要な機能を決定することが推奨されています。 データの収集と準備 データの準備フェーズは、機械学習タスクに適した高品質のデータを確保するために重要な役割を果たします。このセクションでは、データの収集、データの発見、データの拡張、データの生成、およびETL(抽出、変換、読み込み)プロセスについて取り上げています。データの品質チェック、データのクリーニング、データの統合、データのマッチング、および探索的データ分析(EDA)を行うことの重要性を強調しています。 特徴量エンジニアリング 特徴量エンジニアリングは、予測モデリングの性能向上に重要です。このセクションでは、特徴量の選択と抽出、特徴量の構築、特徴量のスケーリング、データのラベリング、特徴量の補完などの技術を強調しています。各技術に関連する特定のアルゴリズムとメソッドも説明されており、Principal Component Analysis(PCA)、Independent Component Analysis(ICA)、およびStandardization and Normalizationも含まれています。 モデルのトレーニング モデルのトレーニングフェーズでは、監視された学習、非監視学習、半教師あり学習、強化学習など、さまざまなタイプの機械学習モデルがカバーされています。このセクションでは、特定の問題に適したモデルを選択するモデル選択についても議論されています。また、クロスバリデーション、ブートストラップ、ランダム分割などのモデル選択の方法も探求されています。ハイパーパラメータのチューニング、つまりモデルのパラメータを最適化するプロセスも取り上げられています。 モデルの評価 モデルの評価は、さまざまなメトリックを使用してモデルのパフォーマンスを評価することに焦点を当てています。このセクションでは、精度、適合率、再現率、Fスコア、ROC曲線下面積(AUC)などの一般的な評価メトリックを紹介しています。モデルのパフォーマンスだけでなく、ビジネス価値も考慮することの重要性を強調しています。 システムの展開 システムの展開には、適切なMLモデルオペレーティングプラットフォームの選択、システムの統合、システム統合テストの実施、およびシステムのエンドユーザーへのリリースが含まれます。カナリア展開やブルーグリーン展開などの展開戦略も説明されています。MLシステムの展開に関連する課題も議論されており、スムーズな展開プロセスのためのヒントも提供されています。 モデルの監視…

Macでの安定したDiffusion XLと高度なCore ML量子化
Stable Diffusion XLは昨日リリースされ、素晴らしいです。大きな(1024×1024)高品質の画像を生成することができます。新しいトリックにより、プロンプトへの適合性が向上しました。最新のノイズスケジューラの研究により、非常に暗いまたは非常に明るい画像を簡単に生成することができます。さらに、オープンソースです! 一方、モデルはより大きくなり、したがって一般的なハードウェアでの実行が遅くなり、困難になりました。Hugging Faceのdiffusersライブラリの最新リリースを使用すると、16 GBのGPU RAMでCUDAハードウェア上でStable Diffusion XLを実行できるため、Colabの無料層で使用することができます。 過去数か月間、人々がさまざまな理由でローカルでMLモデルを実行することに非常に興味を持っていることが明確になってきました。これにはプライバシー、利便性、簡単な実験、または利用料金がかからないことなどが含まれます。AppleとHugging Faceの両方でこの領域を探索するために、私たちは一生懸命取り組んできました。私たちはApple SiliconでStable Diffusionを実行する方法を示したり、Core MLの最新の進化を利用してサイズとパフォーマンスを改善するための6ビットのパレット化を紹介したりしました。 Stable Diffusion XLでは、次のようなことを行いました: ベースモデルをCore MLにポートし、ネイティブのSwiftアプリで使用できるようにしました。 Appleの変換および推論リポジトリを更新し、興味のあるファインチューニングを含むモデルを自分で変換できるようにしました。 Hugging Faceのデモアプリを更新し、Hubからダウンロードした新しいCore ML Stable…

FedMLとThetaが分散型AIスーパークラスターを発表:生成AIとコンテンツ推薦を強化
画期的なコラボレーションにより、FedMLとTheta Networkは、生成型AIとコンテンツ推薦の風景を変えるための分散型AIスーパークラスターの立ち上げを共同で行いました。このパートナーシップは、協調/連邦学習と分散型ビデオストリーミングの力を活用し、Theta.tvの視聴者向けに個別化されたコンテンツ配信を革新することを目指しています。 この革新的なプロジェクトの核心は、Theta Edge Networkコミュニティにあります。このコミュニティは、FedMLのプラットフォームに対して自分自身の好みや計算リソースを提供することで重要な役割を果たします。FedMLは、これらの貴重なリソースを活用して、Theta.tv上の視聴体験を向上させるために特別に調整された高度なAIモデルをトレーニングおよび展開します。 FedMLは、協調的で協力的な人工知能プラットフォームとしての評判を確立しており、シームレスなコラボレーションを可能にする使いやすいMLOpsユーザーインターフェースを提供しています。Thetaとのこのパートナーシップにより、機械学習、ブロックチェーン、コンピュータビジョン、自然言語処理、セキュリティ(ゼロ知識証明)、プライバシーなどの専門家から成る異分野のチームが結集しました。その結果、Theta.tv上のコンテンツ推薦を革新する可能性を秘めたWeb3 x AIプラットフォームが生まれました。 プロセスは、FedMLクライアントがTheta Edgeノードに接続することから始まります。これらのノードはTheta.tvのバックエンドに接続されています。この接続により、FedMLはこれらのノードからデータにアクセスし、最先端のビデオ推薦モデルをトレーニング、微調整、提供するために使用します。 この画期的な技術の潜在的な影響は、ビデオ推薦に限定されません。メディア企業は分散型機械学習を活用して、個々のユーザーの好みに基づいたビデオコンテンツをキュレーションすることで、視聴時間とユーザーエンゲージメントを向上させることができます。このアプリケーションは、ビデオの推薦にとどまらず、個々のユーザーの好みに合わせたニュース記事の提供や映画の提案など、さまざまな領域で活用することができます。 さらに、FedMLとThetaの協力により、生成型AIの開発が可能となります。これにより、自動要約や生成型ビデオコンテンツによってビデオ体験を向上させ、ゲームのヒントを提供し、総合的なユーザーエクスペリエンスを向上させることができます。さらに、この技術はビデオ広告の配信を最適化し、視聴者により適切で関連性の高い広告体験を提供する可能性があります。 このプロジェクトは、分散型AI領域において重要なマイルストーンとなります。なぜなら、このパートナーシップにより、より正確で安全かつプライバシーを保護するAIモデルを生み出すことが約束されるからです。AI産業を分散化することにより、このパートナーシップは高度なAI機能をよりアクセス可能にし、包括的かつ民主的なAIの風景を促進します。 まとめると、FedMLとTheta Networkの協力は、コンテンツ推薦と生成型AIを革新する最先端の技術の素晴らしい融合を表しています。分散型AIスーパークラスターは、視聴者に個別化された魅力的なコンテンツを提供し、デジタルメディアの消費方法を変革することを約束しています。このパートナーシップが分散型AIを新たな高みに導くことで、より安全で正確で包括的なAIの未来を築く道を開拓しています。

「MLOpsの考え方:常に本番準備完了」
「プロジェクトの最初からMLのプロダクションマインドセットが欠如していると、特にプロダクション時に驚きが生じ、再モデリングや市場投入までの時間の遅延を引き起こす可能性があります」
フルスタック7ステップMLOpsフレームワーク
エンドツーエンドの機械学習システム、バッチアーキテクチャ特徴エンジニアリング、トレーニング、バッチ(推論)パイプラインオーケストレーションモニタリング検証デプロイMLOps

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…
相互に接続された複数ページのStreamlitアプリを作成する方法
注意:この記事はもともとStreamlitブログで紹介されていましたVoAGIコミュニティの皆様にご覧いただくために、こちらでも共有したいと思いますわぁ!私が初めてブログ記事を公開してから、なんとも信じられない3ヶ月です...

「LLMはiPhone上でネイティブに動作できるのか? MLC-LLMとは、GPUアクセラレーションを備えた広範なプラットフォームに直接言語モデル(LLM)を導入するためのオープンフレームワークです」
大型言語モデル(LLM)は、人工知能の分野で現在の注目のトピックです。医療、金融、教育、エンターテイメントなど、さまざまな業界で大きな進歩が既になされています。GPT、DALLE、BERTなどのよく知られた大型言語モデルは、驚異的なタスクを実行し、生活を楽にしています。GPT-3はコードを完成させたり、人間のように質問に答えたり、短い自然言語プロンプトだけでコンテンツを生成したりすることができます。一方、DALLE 2は単純なテキストの説明に応じて画像を作成することができます。これらのモデルは人工知能と機械学習の大きな変革に貢献し、パラダイムシフトを実現するのに役立っています。 増え続けるモデルの開発に伴い、それらの広範な計算、メモリ、ハードウェアアクセラレーションの要件を収容するために強力なサーバーが必要となります。これらのモデルを非常に効果的かつ効率的にするためには、それらが消費者のデバイス上で独立して実行できる必要があります。これにより、アクセス性と利用可能性が高まり、ユーザーはインターネット接続やクラウドサーバーへの依存なしに、個人のデバイスで強力なAIツールにアクセスできるようになります。最近、MLC-LLMが導入されました。これはLLMをCUDA、Vulkan、Metalなどの広範なプラットフォームにGPUアクセラレーションとともに直接導入するオープンフレームワークです。 MLC LLMは、CPUやGPU、ネイティブアプリケーションを含むさまざまなハードウェアバックエンドにモデルを展開することができます。これは、サーバーやクラウドベースのインフラストラクチャが必要なく、任意の言語モデルをローカルデバイス上で実行できることを意味します。MLC LLMは、開発者が自然言語処理(NLP)やコンピュータビジョンなどの自分のユースケースに合わせてモデルのパフォーマンスを最適化するための生産性の高いフレームワークを提供します。さらに、ローカルのGPUを使用してアクセラレーションすることもできるため、個人のデバイス上で高精度かつ高速な複雑なモデルを実行することが可能です。 LLMやチャットボットをデバイス上でネイティブに実行するための具体的な手順が、iPhone、Windows、Linux、Mac、Webブラウザーに提供されています。iPhoneユーザー向けには、MLC LLMがTestFlightページを介してインストールできるiOSチャットアプリが提供されています。アプリはスムーズに実行するために少なくとも6GBのメモリが必要であり、iPhone 14 Pro MaxとiPhone 12 Proでテストされています。iOSアプリ上でのテキスト生成速度は、時折不安定になることがあり、最初は遅くなることがありますが、通常の速度に回復します。 Windows、Linux、Macユーザー向けには、MLC LLMがターミナルでボットとチャットするためのコマンドラインインターフェース(CLI)アプリを提供しています。CLIアプリをインストールする前に、Condaなどの依存関係と、WindowsとLinuxのNVIDIA GPUユーザー向けの最新のVulkanドライバーなどをインストールする必要があります。依存関係をインストールした後、ユーザーはCLIアプリをインストールし、ボットとチャットを開始するための手順に従うことができます。Webブラウザーを使用するユーザー向けには、MLC LLMはWebLLMという補完プロジェクトを提供しており、モデルをブラウザーにネイティブに展開します。すべての操作はブラウザー内で実行され、サーバーのサポートなしでWebGPUでアクセラレーションされます。 結論として、MLC LLMは多様なハードウェアバックエンドとネイティブアプリケーション上でLLMを展開するための信じられないほどの汎用的なソリューションです。様々なデバイスとハードウェア構成で実行できるモデルを構築したい開発者にとって、これは素晴らしいオプションです。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.