Learn more about Search Results Google Play - Page 16

- You may be interested
- フラッシュセール:今日からAIの可能性を...
- 「クリエイティブな人々がAIに対して訴訟...
- 「シュレディンガー・ブリッジはテキスト...
- Amazon SageMaker Data WranglerのSnowfla...
- 研究者たちは、医薬品の製造において画期...
- 2023年の最高のAI販売アシスタントツール
- 「ZoomがAIトレーニングのために顧客デー...
- 「総合的な指標を通じて深層生成モデルの...
- プラグインを使ったチャットボットのため...
- 「大規模言語モデルの微調整に関する包括...
- はい、GitHubのCopilotは(実際の)秘密を...
- 学ぶための勇気: L1&L2正則化の解明(パ...
- PyTorch LSTMCell — 入力、隠れ状態、セル...
- 新たな研究が、AIの隠れた脆弱性を明らか...
- 「セマンティックカーネルへのPythonista...

コード生成を通じたモジュラーなビジュアル質問応答
投稿者:UCバークレーの博士課程生であるSanjay SubramanianとGoogle Researchの研究科学者であるArsha Nagrani、Perception Team ビジュアル質問応答(VQA)は、画像または複数の画像に関する質問に対する回答をモデルに求める機械学習のタスクです。従来のVQA手法では、数千の人間による質問-回答ペアが画像に関連付けられたラベル付きトレーニングデータが必要でした。近年、大規模な事前トレーニングの進歩により、少なくとも50のトレーニング例(few-shot)や人間によるVQAトレーニングデータ(zero-shot)なしで優れたパフォーマンスを発揮するVQA手法の開発が行われています。しかし、これらの手法とMaMMUTやVinVLなどの最先端の完全教師ありVQA手法との間にはまだ大きなパフォーマンスの差があります。特に、few-shot手法は空間的な推論、数え上げ、および多段階の推論に苦労しています。さらに、few-shot手法は通常、単一の画像に関する質問に答えることに制限されています。 「Modular Visual Question Answering via Code Generation」では、複雑な推論を必要とするVQAの精度を向上させるために、ACL 2023で発表される予定の論文で、CodeVQAというプログラム合成を使用したビジュアル質問応答のフレームワークを紹介します。具体的には、画像または画像セットに関する質問が与えられた場合、CodeVQAは画像を処理するための簡単なビジュアル関数を持つPythonプログラム(コード)を生成し、このプログラムを実行して回答を決定します。few-shotの設定では、CodeVQAはCOVRデータセットで約3%、GQAデータセットで約2%の改善を示し、従来の手法を上回ることを示しています。 CodeVQA CodeVQAアプローチでは、PALMなどのコード生成の大規模言語モデル(LLM)を使用してPythonプログラム(コード)を生成します。これらの関数を正しく使用するために、これらの関数の説明と、関連するPythonコードとの対になる視覚的な質問の「in-context」の例が含まれるプロンプトを作成します。これらの例を選択するために、入力質問と注釈付きプログラムの質問のエンベッディングを計算します(ランダムに選択された50の質問のセット)。そして、入力に最も類似した質問を選択し、それらをin-contextの例として使用します。プロンプトと回答を求めたい質問が与えられた場合、LLMはその質問を表すPythonプログラムを生成します。 CodeVQAフレームワークを具体化するために、3つのビジュアル関数である(1)query、(2)get_pos、および(3)find_matching_imageを使用します。 Queryは、単一の画像に関する質問に答えるために、few-shot Plug-and-Play VQA(PnP-VQA)メソッドを使用して実装されます。PnP-VQAは、数百万の画像キャプションペアで事前トレーニングされた画像キャプション変換モデルであるBLIPを使用してキャプションを生成し、これらを質問の回答を出力するLLMに入力します。 Get_posは、物体の説明を入力として受け取り、画像内のその物体の位置を返すオブジェクトローカライザです。この関数はGradCAMを使用して実装されています。具体的には、説明と画像はBLIPのテキスト-画像ジョイントエンコーダを通過し、画像-テキストのマッチングスコアを予測します。GradCAMは、このスコアの画像特徴量に対する勾配を取り、テキストに関連のある領域を見つけます。 Find_matching_imageは、複数の画像の質問で与えられた入力フレーズに最も一致する画像を見つけるために使用されます。この関数は、BLIPテキストエンコーダと画像エンコーダを使用してフレーズのテキスト埋め込みと各画像の画像埋め込みを計算します。そして、テキスト埋め込みと各画像埋め込みの内積は、各画像のフレーズへの関連度を表し、この関連度が最大となる画像を選択します。 これらの3つの関数は、非常に少ないアノテーション(例えば、ウェブから収集したテキストや画像テキストのペアと少数のVQAの例)を必要とするモデルを使用して実装できます。さらに、CodeVQAフレームワークは、ユーザーが実装するかもしれない他の関数(例:オブジェクト検出、画像セグメンテーション、または知識ベースの検索)にも簡単に拡張できます。 CodeVQAメソッドのイラスト。まず、大規模言語モデルが質問を表すPythonプログラム(コード)を生成します。この例では、簡単なVQAメソッド(query)が質問の一部に答えるために使用され、オブジェクトローカライザ(get_pos)が言及されたオブジェクトの位置を見つけます。そして、これらの関数の出力を組み合わせて元の質問に対する回答を生成します。…

「ゲームからAIへ:NvidiaのAI革命における重要な役割」
Nvidiaは現在、Facebook、Tesla、Netflixよりも価値が高くなっていますロイターによると、株価は過去8ヶ月で3倍に増加しましたしかし、これはどのようにして起こったのでしょうか?ほぼ破産寸前だった会社がどのようにして…
「ゲーミングからAIへ:NvidiaのAI革命における重要な役割」
Nvidiaは現在、Facebook、Tesla、Netflixよりも価値が高いですロイターによると、株価は過去8ヶ月で3倍になりましたしかし、これはどのようにして起こったのでしょうか?ほとんど終わりかけていた会社がどのようにして…

AI/DLの最新トレンドを探る:メタバースから量子コンピューティングまで
著者は、MetaverseやQuantum Computingなど、人工知能とディープラーニングのいくつかの新興トレンドについて議論しています
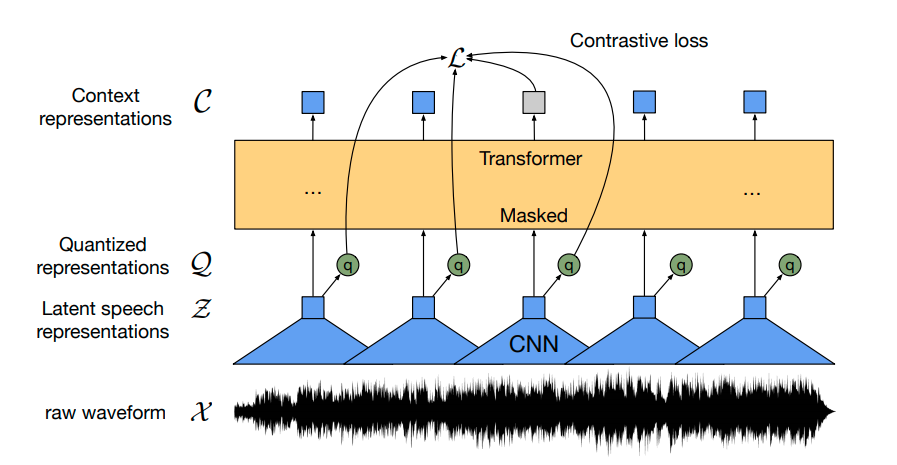
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…

スペースインベーダーとの深層Q学習
ハギングフェイスとのディープ強化学習クラスのユニット3 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しい更新版はこちらから利用できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 前のユニットでは、最初の強化学習アルゴリズムであるQ-Learningを学び、それをゼロから実装し、FrozenLake-v1 ☃️とTaxi-v3 🚕の2つの環境でトレーニングしました。 このシンプルなアルゴリズムで優れた結果を得ました。ただし、これらの環境は比較的単純であり、状態空間が離散的で小さかったため(FrozenLake-v1では14の異なる状態、Taxi-v3では500の状態)。 しかし、大きな状態空間の環境では、Qテーブルの作成と更新が効率的でなくなる可能性があることを後で見ていきます。 今日は、最初のディープ強化学習エージェントであるDeep Q-Learningを学びます。Qテーブルの代わりに、Deep Q-Learningは、状態を受け取り、その状態に基づいて各アクションのQ値を近似するニューラルネットワークを使用します。 そして、RL-Zooを使用して、Space Invadersやその他のAtari環境をプレイするためにトレーニングします。RL-Zooは、トレーニング、エージェントの評価、ハイパーパラメータの調整、結果のプロット、ビデオの記録など、RLのためのトレーニングフレームワークであるStable-Baselinesを使用しています。 では、始めましょう! 🚀 このユニットを理解するためには、まずQ-Learningを理解する必要があります。…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.