Learn more about Search Results Falcon - Page 16

- You may be interested
- 「Pantsを使用してMachine LearningのMono...
- 「オムニバースへ:Blender 4.0 アルファ...
- VoAGIニュース、8月2日:ChatGPTコードイ...
- ビジュアルトランスフォーマー(ViT)モデ...
- PyTorch DDPからAccelerateへ、そしてTrai...
- メタの戦略的な優れた点:Llama 2は彼らの...
- GraphReduce グラフを使用した特徴エンジ...
- 研究者がCODES+ISSS最優秀論文賞を受賞し...
- 「データサイエンス、STEM、ビジネス、お...
- 新しいAI研究がREVを紹介:AI研究における...
- 「Pythonによる言語の指紋認識」
- このGoogleとUC BerkeleyのAI論文は、NeRF...
- 「共通の悪いデータの10つのケースとその...
- マルコフとビネメ・シェビシェフの不等式
- 「完璧な機械学習アルゴリズムを選ぶため...
「テキスト生成推論によるコンピュータからの大規模言語モデルの提供」
このブログ記事では、Hugging Faceのテキスト生成推論をセルフホストする方法について探求します
成功に導くデータチームの意思決定
現実は複雑です:人々や組織は予期しない方法で行動し、外部の出来事は私たちの最もうまくいくワークフローに次々と障害を投げ込むことがありますデータチームにとっては、誘惑に駆られることがあります...

Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
これは、オープンソースのLLM(Large Language Model)であるBLOOMをAmazon SageMakerに展開し、新しいHugging Face LLM Inference Containerを使用して推論を行う方法の例です。Open Assistantデータセットで訓練されたオープンソースのチャットLLMである12B Pythia Open Assistant Modelを展開します。 この例では以下の内容をカバーしています: 開発環境のセットアップ 新しいHugging Face LLM DLCの取得 Open Assistant 12BのAmazon SageMakerへの展開 モデルを使用して推論およびチャットを行う…

ファルコンはHugging Faceのエコシステムに着陸しました
イントロダクション ファルコンは、アブダビのテクノロジーイノベーション研究所が作成し、Apache 2.0ライセンスの下で公開された最新の言語モデルの新しいファミリーです。 特筆すべきは、Falcon-40Bが多くの現在のクローズドソースモデルと同等の機能を持つ、初めての「真にオープンな」モデルであることです 。これは、開発者、愛好家、産業界にとって素晴らしいニュースであり、多くのエキサイティングなユースケースの扉を開くものです。 このブログでは、ファルコンモデルについて詳しく調査し、まずそれらがどのようにユニークであるかを説明し、その後、Hugging Faceのエコシステムのツールを使ってそれらの上に構築することがどれほど簡単かを紹介します。 目次 ファルコンモデル デモ 推論 評価 PEFTによるファインチューニング 結論 ファルコンモデル ファルコンファミリーは、2つのベースモデルで構成されています:Falcon-40Bとその弟であるFalcon-7Bです。 40Bパラメータモデルは現在、Open LLM Leaderboardのトップを占めており、7Bモデルはそのクラスで最高のモデルです 。 Falcon-40BはGPUメモリを約90GB必要としますが、それでもLLaMA-65Bよりは少なく、Falconはそれを上回します。一方、Falcon-7Bは約15GBしか必要とせず、推論やファインチューニングは一般的なハードウェアでも利用可能です。 (このブログの後半では、より安価なGPUでもFalcon-40Bを利用できるように、量子化を活用する方法について説明します!) TIIはまた、モデルのInstructバージョンであるFalcon-7B-InstructとFalcon-40B-Instructを提供しています。これらの実験的なバリアントは、命令と会話データに適応された調整が行われているため、人気のあるアシスタントスタイルのタスクに適しています。 モデルを素早く試してみたい場合は、これらが最適な選択肢です。…

DuckDB Hugging Face Hubに保存されている50,000以上のデータセットを分析する
Hugging Face Hubは、誰にでもデータセットへのオープンアクセスを提供し、ユーザーがそれらを探索し理解するためのツールを提供することに特化しています。Falcon、Dolly、MPT、およびStarCoderなどの人気のある大規模言語モデル(LLM)のトレーニングに使用されるデータセットの多くを見つけることができます。不公平性や偏見を解決するためのDisaggregatorsのようなデータセット用のツールや、データセット内の例をプレビューするためのDataset Viewerなどのツールもあります。 Dataset Viewerを使用してOpenAssistantデータセットのプレビューを表示します。 私たちは、Hub上のデータセットを分析するための別の機能を最近追加しました。Hubに保存されている任意のデータセットでDuckDBを使用してSQLクエリを実行できます!2022年のStackOverflow Developer Surveyによると、SQLは3番目に人気のあるプログラミング言語です。また、分析クエリを実行するために設計された高速なデータベース管理システム(DBMS)が必要でしたので、DuckDBとの統合に興奮しています。これにより、より多くのユーザーがHub上のデータセットにアクセスし、分析することができると思います! 要約 Datasets Serverは、Hub上のすべての公開データセットをParquetファイルに自動変換します。データセットページの上部にある「Auto-converted to Parquet」ボタンをクリックすることで、それらのファイルを表示することができます。また、単純なHTTP呼び出しでParquetファイルのURLリストにアクセスすることもできます。 r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus") j = r.json() urls = [f['url'] for…

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
オープンソースのLLMであるFalcon、(オープン-)LLaMA、X-Gen、StarCoder、またはRedPajamaは、ここ数ヶ月で大きく進化し、ChatGPTやGPT4などのクローズドソースのモデルと特定のユースケースで競合することができるようになりました。しかし、これらのモデルを効率的かつ最適化された方法で展開することはまだ課題です。 このブログ投稿では、モデルの展開を容易にするマネージドSaaSソリューションであるHugging Face Inference EndpointsにオープンソースのLLMを展開する方法と、応答のストリーミングとエンドポイントのパフォーマンステストの方法を紹介します。さあ、始めましょう! Falcon 40Bの展開方法 LLMエンドポイントのテスト JavaScriptとPythonでの応答のストリーミング 始める前に、Inference Endpointsについての知識をおさらいしましょう。 Hugging Face Inference Endpointsとは何ですか Hugging Face Inference Endpointsは、本番環境での機械学習モデルの展開を簡単かつ安全な方法で提供します。Inference Endpointsを使用することで、開発者やデータサイエンティストはインフラストラクチャの管理をせずにAIアプリケーションを作成できます。展開プロセスは数回のクリックで簡略化され、オートスケーリングによる大量のリクエストの処理、ゼロスケールへのスケールダウンによるインフラストラクチャのコスト削減、高度なセキュリティの提供などが可能となります。 LLM展開における最も重要な機能のいくつかは以下の通りです: 簡単な展開: インフラストラクチャやMLOpsの管理を必要とせず、本番用のAPIとしてモデルを展開できます。 コスト効率:…

SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
ChatGPTや他のLLM(Language Model)を使用してSQLクエリを生成しようとしたことがある方は手を挙げてください私は試してみましたし、現在も試しています!しかし、新しいオープンソースのファミリーが登場したことをお伝えできるのがとても嬉しいです...

MPT-30B:モザイクMLは新しいLLMを使用して、NLPの限界を em>GPT-3を凌駕します
MosaicMLのLLMにおける画期的な進歩について、MPTシリーズで学びましょうMPT-30Bおよびその微調整された派生モデル、MPT-30B-InstructとMPT-30B-Chatが他のモデルを凌駕する方法を探索してください
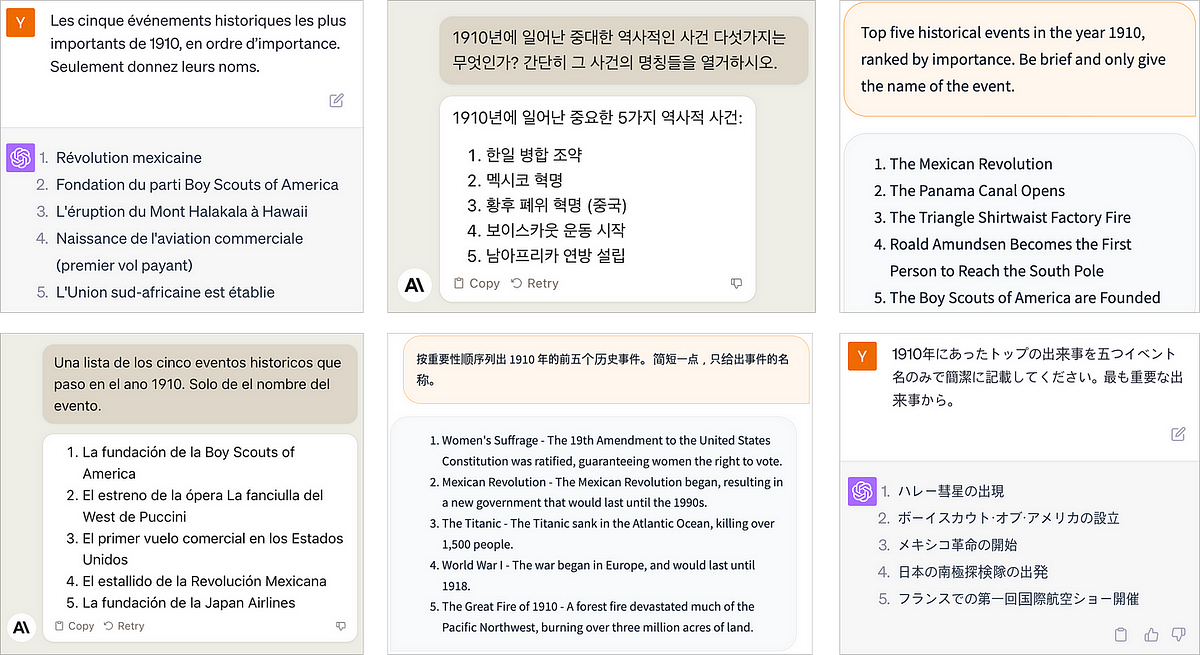
AIのレンズを通じた世界の歴史
人工知能の進歩、特に大規模な言語モデルにより、歴史研究や教育においては興奮すべき可能性が広がっていますしかし、その方法については慎重に検証することが重要です...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.