Learn more about Search Results Adam - Page 16

- You may be interested
- 「クロードへの5つのプロンプトエンジニア...
- 「10 Best AI医療書記」
- 「10 最高のワークフロー自動化ツール」
- 「Huggingface 🤗を使用したLLMsのためのR...
- 「中国、新たな規制提案でAIデータのセキ...
- 「機械学習の方法の比較:従来の方法と費...
- 新技術における公共の利益の定義
- 音楽の探索の未来:検索対生成
- このAIの論文は、ディフュージョンモデル...
- Amazon Transcribeは、100以上の言語に対...
- 2024年にデータアナリストになるための学...
- 即座のマルチビジュアライゼーションダッ...
- ハギングフェイス推論エンドポイントの始め方
- UCSDとMicrosoftの研究者がColDecoを導入...
- DeepMindからの新しいAI研究では、有向グ...

Megatron-LMを使用して言語モデルをトレーニングする方法
PyTorchで大規模な言語モデルをトレーニングするには、単純なトレーニングループだけでは不十分です。通常、複数のデバイスに分散しており、安定した効率的なトレーニングのための多くの最適化技術があります。Hugging Face 🤗 Accelerateライブラリは、トレーニングループに非常に簡単に統合できるように、GPUとTPUを跨いで分散トレーニングをサポートするために作成されました。🤗 TransformersもTrainer APIを介して分散トレーニングをサポートしており、トレーニングループの実装を必要とせずにPyTorchでの完全なトレーニングを提供します。 大規模なトランスフォーマーモデルを事前トレーニングするための研究者の間でのもう一つの人気ツールはMegatron-LMです。これはNVIDIAのApplied Deep Learning Researchチームによって開発された強力なフレームワークです。🤗 AccelerateとTrainerとは異なり、Megatron-LMの使用は直感的ではなく、初心者には少し抵抗があるかもしれません。しかし、これはGPU上でのトレーニングに最適化されており、いくつかの高速化を提供することができます。このブログ記事では、Megatron-LMを使用してNVIDIAのGPU上で言語モデルをトレーニングし、それをtransformersと一緒に使用する方法を学びます。 このフレームワークでGPT2モデルをトレーニングするためのさまざまなステップを紹介します。これには以下が含まれます。 環境のセットアップ データの前処理 トレーニング モデルの🤗 Transformersへの変換 なぜMegatron-LMを選ぶのか? トレーニングの詳細に入る前に、他のフレームワークよりもこのフレームワークが効率的である理由を理解しましょう。このセクションは、Megatron-DeepSpeedでのBLOOMトレーニングについての素晴らしいブログから着想を得ています。詳細については参照してください。このブログ記事はMegatron-LMへの優しい入門を提供することを目的としています。 データローダー Megatron-LMには、データがトークン化され、トレーニング前にシャッフルされる効率的なデータローダーが付属しています。また、データは番号付きのシーケンスに分割され、それらは計算が必要な場合にのみ計算されるようにインデックスで保存されます。インデックスを作成するために、エポック数はトレーニングパラメータに基づいて計算され、順序が作成され、その後シャッフルされます。これは通常の場合とは異なり、データセット全体を繰り返し処理してから2番目のエポックのために繰り返すというものです。これにより、学習曲線が滑らかになり、トレーニング中の時間が節約されます。 組み込みCUDAカーネル GPU上で計算を実行する場合、必要なデータはメモリから取得され、計算が実行され、結果がメモリに保存されます。簡単に言えば、組み込みカーネルのアイデアは、通常はPyTorchによって別々に実行される類似の操作を、単一のハードウェア操作に統合することです。そのため、複数の個別の計算で行われるメモリ移動の回数を減らします。以下の図は、カーネルフュージョンのアイデアを示しています。これは、詳細について説明しているこの論文からインスピレーションを受けています。 f、g、hが1つのカーネルで結合された場合、fとgの中間結果x’とy’はGPUレジスタに保存され、hによって即座に使用されます。しかし、フュージョンがない場合、x’とy’はメモリにコピーされ、hによって読み込まれる必要があります。したがって、カーネルフュージョンは計算に著しいスピードアップをもたらします。Megatron-LMはまた、PyTorchの実装よりも高速なApexのFused…

PyTorch DDPからAccelerateへ、そしてTrainerへ簡単に分散トレーニングをマスターしましょう
全般的な概要 このチュートリアルでは、PyTorchと単純なモデルのトレーニング方法について基本的な理解があることを前提としています。分散データ並列処理(DDP)というプロセスを通じて複数のGPUでのトレーニングを紹介します。以下の3つの異なる抽象化レベルを通じて行います: pytorch.distributedモジュールを使用したネイティブなPyTorch DDP pytorch.distributedをラップした🤗 Accelerateの軽量なラッパーを利用し、コードの変更なしに単一のGPUおよびTPUで実行できるようにする方法 🤗 Transformerの高レベルのTrainer APIを利用し、ボイラープレートコードを抽象化し、さまざまなデバイスと分散シナリオをサポートする方法 「分散」トレーニングとは何か、なぜ重要なのか? まず、公式のMNISTの例に基づいて、以下の非常に基本的なPyTorchのトレーニングコードを見てみましょう。 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as…

Diffusersを使用したDreamboothによる安定した拡散のトレーニング
ドリームブースは、特殊なファインチューニングの形式を使用して、安定拡散に新しい概念を教えるための技術です。一部の人々は、素晴らしい状況に自分自身を配置するために、いくつかの写真を使用してそれを利用しています。一方、他の人々は新しいスタイルを取り入れるためにそれを使用しています。🧨 Diffusersは、Dreamboothトレーニングスクリプトを提供しています。トレーニングには時間はかかりませんが、適切なハイパーパラメータのセットを選択するのは難しく、過学習しやすいです。 私たちは、Dreamboothのさまざまな設定の効果を分析するために多くの実験を行いました。この投稿では、Stable DiffusionをDreamboothでファインチューニングする際に結果を改善するための見つけたポイントといくつかのヒントを紹介します。 始める前に、この方法は決して悪意のある目的、何らかの害を引き起こすため、または人々を知らずになりすますために使用してはなりません。それでトレーニングされたモデルは、Stable Diffusionモデルの配布を規制するCreativeML Open RAIL-Mライセンスによって依然として拘束されます。 注意:この投稿の以前のバージョンはW&Bレポートとして公開されました。 要約:推奨設定 ドリームブースはすぐに過学習します。良質な画像を得るためには、トレーニングステップ数と学習率の間の「適切なスイートスポット」を見つける必要があります。低い学習率を使用し、結果が満足できるまでステップ数を徐々に増やすことを推奨します。 ドリームブースでは、顔に対してはより多くのトレーニングステップが必要です。私たちの実験では、バッチサイズ2とLR 1e-6を使用した場合に、800〜1200ステップがうまく機能しました。 事前保存は、顔のトレーニング時に過学習を避けるために重要です。他の対象に対しては、それほど大きな違いはないようです。 生成された画像がノイズが多いか品質が低下している場合、それはおそらく過学習を意味します。まず、上記の手順を試して避けてみてください。生成された画像がまだノイズが多い場合は、DDIMスケジューラを使用するか、より多くの推論ステップ(私たちの実験では約100ステップがうまく機能しました)を実行してみてください。 UNetに加えてテキストエンコーダをファインチューニングすることは、品質に大きな影響を与えます。私たちの最良の結果は、テキストエンコーダのファインチューニング、低いLR、適切なステップ数の組み合わせを使用して得られました。ただし、テキストエンコーダのファインチューニングにはより多くのメモリが必要ですので、少なくとも24 GBのRAMを持つGPUが理想です。Google ColabやKaggleが提供する16 GBのGPUのようなものでは、8ビットAdam、fp16トレーニング、勾配蓄積などの技術を使用してトレーニングすることが可能です。 EMAを使用してファインチューニングするかどうかに関係なく、類似の結果が得られました。 ドリームブースをトレーニングするためにsksという単語を使用する必要はありません。最初の実装の一部は、それが語彙の中で稀なトークンであったためにそれを使用しましたが、実際にはライフルの一種です。私たちの実験および@nitrosockeなどの実験は、ターゲットを説明するために自然に使用する用語を選択しても問題ないことを示しています。 学習率の影響 ドリームブースは非常に速く過学習します。良い結果を得るためには、データセットに合理的な学習率とトレーニングステップ数を調整します。私たちの実験(以下で詳細に説明)では、高い学習率と低い学習率で4つの異なるデータセットでファインチューニングを行いました。すべての場合で、低い学習率でより良い結果が得られました。 実験設定…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…

Optimum+ONNX Runtime – Hugging Faceモデルのより簡単で高速なトレーニング
はじめに 言語、ビジョン、音声におけるトランスフォーマーベースのモデルは、複雑なマルチモーダルのユースケースをサポートするためにますます大きくなっています。モデルのサイズが増えるにつれて、これらのモデルをトレーニングし、サイズが増えるにつれてスケーリングするために必要なリソースにも直接的な影響があります。Hugging FaceとMicrosoftのONNX Runtimeチームは、大規模な言語、音声、ビジョンモデルのファインチューニングにおいて進歩をもたらすために協力しています。Hugging FaceのOptimumライブラリは、ONNX Runtimeとの統合により、多くの人気のあるHugging Faceモデルのトレーニング時間を35%以上短縮するオープンなソリューションを提供します。本稿では、Hugging Face OptimumとONNX Runtimeトレーニングエコシステムの詳細を紹介し、Optimumライブラリの利点を示すパフォーマンスの数値を提示します。 パフォーマンスの結果 以下のチャートは、Optimumを使用したHugging Faceモデルのパフォーマンスを示しており、トレーニングにONNX RuntimeとDeepSpeed ZeRO Stage 1を使用することで、39%から130%までの印象的な高速化が実現されています。パフォーマンスの測定は、ベースライン実行としてPyTorchを使用した選択されたHugging Faceモデルで行われ、2番目の実行ではトレーニングのためにONNX Runtimeのみを使用し、最終的な実行ではONNX Runtime + DeepSpeed ZeRO Stage…

Hugging FaceとAWSが協力し、AIをよりアクセスしやすくするためにパートナーシップを結成
AIをすべての人に開放し、アクセス可能にする時が来ました。それがHugging FaceとAmazon Web Services(AWS)の拡大した長期戦略的パートナーシップの目標です。両社は、次世代の機械学習モデルの利用可能性を加速させ、機械学習コミュニティがよりアクセスしやすくなり、開発者が最高のパフォーマンスを最低のコストで実現できるよう支援することを目指しています。 新しい世代のオープンでアクセス可能なAI 機械学習はすぐにすべてのアプリケーションに組み込まれつつあります。経済のあらゆるセクターに与える影響が明確になるにつれて、最新のモデルにアクセスし、評価できるようにすることは、これまで以上に重要になっています。AWSとのパートナーシップは、専用のツールを使用してクラウドで最新の機械学習モデルを構築、トレーニング、展開することをより迅速かつ容易にすることで、この未来への道を切り拓いています。 テキスト、音声、画像を処理および生成する新しいTransformerおよびDiffuserの機械学習モデルには、大幅な進歩がありました。しかし、これらの人気のある生成AIモデルのほとんどは公開されておらず、最大のテック企業と他のすべての企業との機械学習能力のギャップを広げています。この傾向に対抗するため、AWSとHugging Faceは協力して、次世代のモデルをグローバルなAIコミュニティに提供し、機械学習を民主化します。戦略的パートナーシップを通じて、Hugging FaceはAWSを優先的なクラウドプロバイダーとして活用し、Hugging Faceのコミュニティの開発者がAWSの最新のツール(Amazon SageMaker、AWS Trainium、AWS Inferentiaなど)にアクセスして、モデルをトレーニング、微調整、展開することができるようにします。これにより、開発者は特定のユースケースに対してモデルのパフォーマンスをさらに最適化し、コストを削減することができます。Hugging Faceは、Amazon SageMakerを使用して最新の革新的な研究成果を適用し、次世代のAIモデルを構築します。Hugging FaceとAWSは、機械学習の最新の進展をグローバルなAIコミュニティが利用できるようにし、生成AIアプリケーションの作成を加速させるためのギャップを埋めています。 「AIの未来はここにありますが、均等には分布していません」とHugging FaceのCEOであるClement Delangueは述べています。「アクセシビリティと透明性は、進歩を共有し、これらの新しい機能を賢明かつ責任を持って使用するためのツールを作成するための鍵です。Amazon SageMakerとAWS設計のチップは、私たちのチームとより大きな機械学習コミュニティが最新の研究をオープンに再現可能なモデルに変換できるようにします。誰でもそれを基礎に構築することができます」。 クラウドでAIを拡大するための協力 この拡大した戦略的パートナーシップにより、Hugging FaceとAWSは、Hugging Faceにホストされている最新のモデルをAmazon…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…
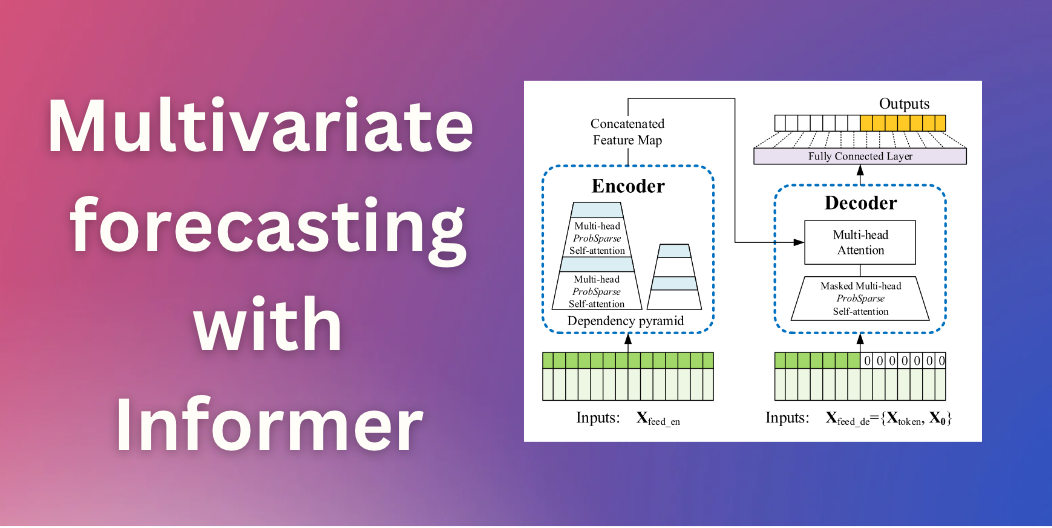
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

ディフューザを使用してControlNetをトレーニングしてください
イントロダクション ControlNetは、追加の条件を付加することで拡散モデルを細かく制御することができるニューラルネットワーク構造です。この技術は、「Adding Conditional Control to Text-to-Image Diffusion Models」という論文で登場し、すぐにオープンソースの拡散コミュニティで広まりました。著者はStable Diffusion v1-5を制御するための8つの異なる条件をリリースしました。これには、ポーズ推定、深度マップ、キャニーエッジ、スケッチなどが含まれます。 このブログ投稿では、3Dシンセティックフェイスに基づいた顔のポーズモデルであるUncanny Facesモデルのトレーニング手順を詳細に説明します(実際にはUncanny Facesは予期しない結果であり、それがどのように実現されたかについては後ほどご紹介します)。 安定した拡散のためのControlNetのトレーニングの始め方 独自のControlNetをトレーニングするには、3つのステップが必要です: 条件の計画:ControlNetはStable Diffusionをさまざまなタスクに対応できる柔軟性があります。事前にトレーニングされたモデルはさまざまな条件を示しており、コミュニティはピクセル化されたカラーパレットに基づいた他の条件を作成しています。 データセットの構築:条件が決まったら、データセットの構築の時間です。そのためには、データセットをゼロから構築するか、既存のデータセットの一部を使用することができます。モデルをトレーニングするためには、データセットには3つの列が必要です:正解のimage、conditioning_image、およびprompt。 モデルのトレーニング:データセットの準備ができたら、モデルのトレーニングの時間です。これは、ディフューザーのトレーニングスクリプトのおかげで最も簡単な部分です。少なくとも8GBのVRAMを持つGPUが必要です。 1. 条件の計画 条件を計画するために、次の2つの質問を考えると役立ちます: どのような条件を使用したいですか? 既存のモデルで「通常の」画像を私の条件に変換できるものはありますか?…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.