Learn more about Search Results で見る - Page 16

- You may be interested
- MITとMeta AIからのこのAI研究は、高度な...
- AIの検索アルゴリズム:最も人気のあるも...
- AIのプッシュとプルを克服する:AIを活用...
- 「2023年に注目すべきマーケティングトレ...
- 「チューリングテストと中国の部屋の議論...
- pd.read_htmlの良い点と悪い点、そして醜い点
- 『Janne Aas-Jakobsen、CONSIGLI ASの創業...
- 実践的な3Dアセット生成:ステップバイス...
- ショッピファイの従業員がAIによるレイオ...
- パーソナライズされたAIの簡単な作成方法...
- 「キャンドルとファルコン:Rustでの大規...
- 責任あるAI:AIウォッチドッグの重要な役...
- 「マイクロソフトは、VALLE-Xをオープンソ...
- 「開発者向けの15以上のAIツール(2023年9...
- 「より優れたモデルを構築するためには、...

「Google Sheetsにおける探索的データ分析」
PandasやJupyterのようなモダンなツールを使ってデータを処理するのはいつも楽しいですしかし、同僚や友人がデータ分析を依頼してきた場合、彼らがテクニカルではないと想像してみましょう...

研究者たちは、ナノLEDの正確なアレイを育成しました
新たな技術により、パーヴォスカイトナノクリスタルを必要な場所で生成することができるため、これら非常にデリケートな材料をナノスケールデバイスに統合することが可能です

ChatGPTは自己を規制するための法律を作成する
コスタリカは、人工知能(AI)の規制において興味深い一歩を踏み出しました。法的な専門知識の源泉として予想外の存在であるChatGPTを活用し、AIに関する新しい法律の起草に協力を仰ぎました。このAI搭載のチャットボットは、「弁護士のように考える」という驚異的な能力を持ち、コスタリカの憲法に合致した法案の作成を担当しました。AIの規制の未来を形作るこの非凡な取り組みの詳細について探ってみましょう。 また読む:米国議会が行動を起こす:人工知能の規制を提案する2つの新法案 AI法制度の専門知識において、議会がChatGPTを頼る コスタリカの政治家たちは、急速に進化する人工知能の分野を規制する緊急の必要性を認識しています。包括的な法律を作成するという複雑な課題に直面し、彼らはOpenAIが開発した知識と自然言語処理能力を備えたChatGPTの支援を求めました。国の憲法に基づく法案の起草をChatGPTに指示しました。 また読む:ChatGPTの偽の法的研究に騙された弁護士 AI規制における独自のアプローチが具体化 コンスタンサ・ヴァネッサ・カストロ議員の指導のもと、コスタリカにおけるAIの規制を目指す取り組みが勢いを増しています。ChatGPTの役割は重要であり、完全かつ緻密に作成された文書を提供し、提案法の基礎となりました。提案法の導入は好意的な意見と批判的な意見の両方を引き出し、AI規制におけるこの画期的な一歩の重要性が浮き彫りになりました。 また読む:中国が生成AIサービスを規制する大胆な一歩を踏み出す AI制御の重要な推奨事項 ChatGPTの専門知識により、コスタリカにおけるAIシステムの統治に必要な一連の重要な推奨事項が生まれました。チャットボットは、AI技術を監督する独立した規制機関の設立を提案しました。この機関は、説明責任、説明可能性、バイアスの防止、人権の保護などの重要な原則に基づいて運営されることが想定されています。これらの価値観を取り入れることで、提案法はコスタリカで倫理的かつ責任あるAIの使用を確保します。 また読む:OpenAIとDeepMindが英国政府と協力してAIの安全性と研究を進める 実施への道 提案法は、5月に正式に提出され、コスタリカのAI規制への道の重要な節目となっています。ただし、この法案は現在、さまざまな関係者からの意見と見解を集めるために公開討論のフェーズを経ています。このプロセスにより、法案は議会のさらなる検討と改善のための委員会に到達する前に、改訂と追加の討論が容易になります。 人間の介入は依然として重要 AIは驚異的な能力を示していますが、コンスタンサ・ヴァネッサ・カストロ議員は、立法における人間の介入の重要性を強調しています。この取り組みは、人工知能が人間の意思決定を補完するツールとして見るべきであり、それを置き換えるものではないということを示しています。コスタリカのAI規制のアプローチは、技術の進歩と人間の判断に必要な倫理的な考慮事項をバランスさせることを目指しています。 異なる視点と批判 コスタリカは、AI規制を検討するラテンアメリカ諸国の中で増え続ける数の一つです。AIのガバナンスに広範な支持はありますが、提案された法律に対してすべての立法者が同じ意見を持っているわけではありません。コスタリカの国会議員であるヨハナ・オバンドは、提案法が実質的な内容を欠き、「良い願いのリスト」を示しているだけだとして、法案に対する懸念を表明しました。オバンドは、ChatGPTが国家憲法から条文を作成することで、提案法の正確性と信頼性に疑問が投げかけられると考えています。 また読む:法律部門におけるAI革命:裁判所でチャットボットが中心に 国際基準に基づく展開 オバンドは、AI規制を基本的な権利と国際的な協定に基づいて策定することの重要性を強調しています。ただし、現在議論中の法案には、これらの権利と協定への具体的な言及がなく、改善の余地があります。ラテンアメリカでは、EUのAI法が参考とされており、生体認証の監視でのAIの使用の禁止や、AIによる情報の透明性を義務付けるなどのガイドラインが適用されています。 また読む:EU、ディープフェイクとAIコンテンツの特定策を求める ラテンアメリカにおける倫理的AIフレームワークへの取り組み この地域の立法者たちは、AI利用に関する倫理的な枠組みの開発に積極的に取り組んでいます。たとえば、メキシコは3月に個人情報と人権の保護に焦点を当てた倫理的な枠組みの確立を奨励する法案を導入しました。同様に、ペルーの議会は最近、デジタルセキュリティと倫理の原則を強調した最初のAIに関する法律を承認しました。これらの立法の努力は、AIの利用が倫理的で透明性があり、持続可能な環境を創造することを目指しています。 また読む:倫理的なAIの統治:非倫理的なAIを防ぐ規則と法規制…

「トランスフォーマーベースのエンコーダーデコーダーモデル」
!pip install transformers==4.2.1 !pip install sentencepiece==0.1.95 トランスフォーマーベースのエンコーダーデコーダーモデルは、Vaswani et al.によって有名なAttention is all you need論文で紹介され、現在では自然言語処理(NLP)におけるデファクトスタンダードのエンコーダーデコーダーアーキテクチャです。 最近、T5、Bart、Pegasus、ProphetNet、Margeなど、トランスフォーマーベースのエンコーダーデコーダーモデルの異なる事前学習目的に関する多くの研究が行われていますが、モデルのアーキテクチャはほとんど変わっていません。 このブログ記事の目的は、トランスフォーマーベースのエンコーダーデコーダーアーキテクチャがシーケンス対シーケンスの問題をどのようにモデル化しているかを詳細に説明することです。アーキテクチャによって定義された数学モデルとそのモデルを推論に使用する方法に焦点を当てます。途中で、NLPのシーケンス対シーケンスモデルについての背景をいくつか説明し、トランスフォーマーベースのエンコーダーとデコーダーのパーツに分解します。多くのイラストを提供し、トランスフォーマーベースのエンコーダーデコーダーモデルの理論と🤗Transformersにおける実際の使用方法のリンクを確立します。なお、このブログ記事ではそのようなモデルをトレーニングする方法については説明していません。これについては将来のブログ記事のテーマです。 トランスフォーマーベースのエンコーダーデコーダーモデルは、表現学習とモデルアーキテクチャに関する数年にわたる研究の成果です。このノートブックでは、ニューラルエンコーダーデコーダーモデルの歴史の簡単な概要を提供します。詳細については、Sebastion Ruder氏の素晴らしいブログ記事を読むことをお勧めします。また、セルフアテンションアーキテクチャの基本的な理解も推奨されます。以下のJay Alammar氏のブログ記事は、元のトランスフォーマーモデルの復習として役立ちます。 このノートブックの執筆時点では、🤗Transformersには、T5、Bart、MarianMT、Pegasusのエンコーダーデコーダーモデルが含まれており、これらはモデルの要約についてはドキュメントで要約されています。 このノートブックは4つのパートに分かれています: 背景 – ニューラルエンコーダーデコーダーモデルの短い歴史がRNNベースのモデルに焦点を当てて与えられます。 エンコーダーデコーダー…
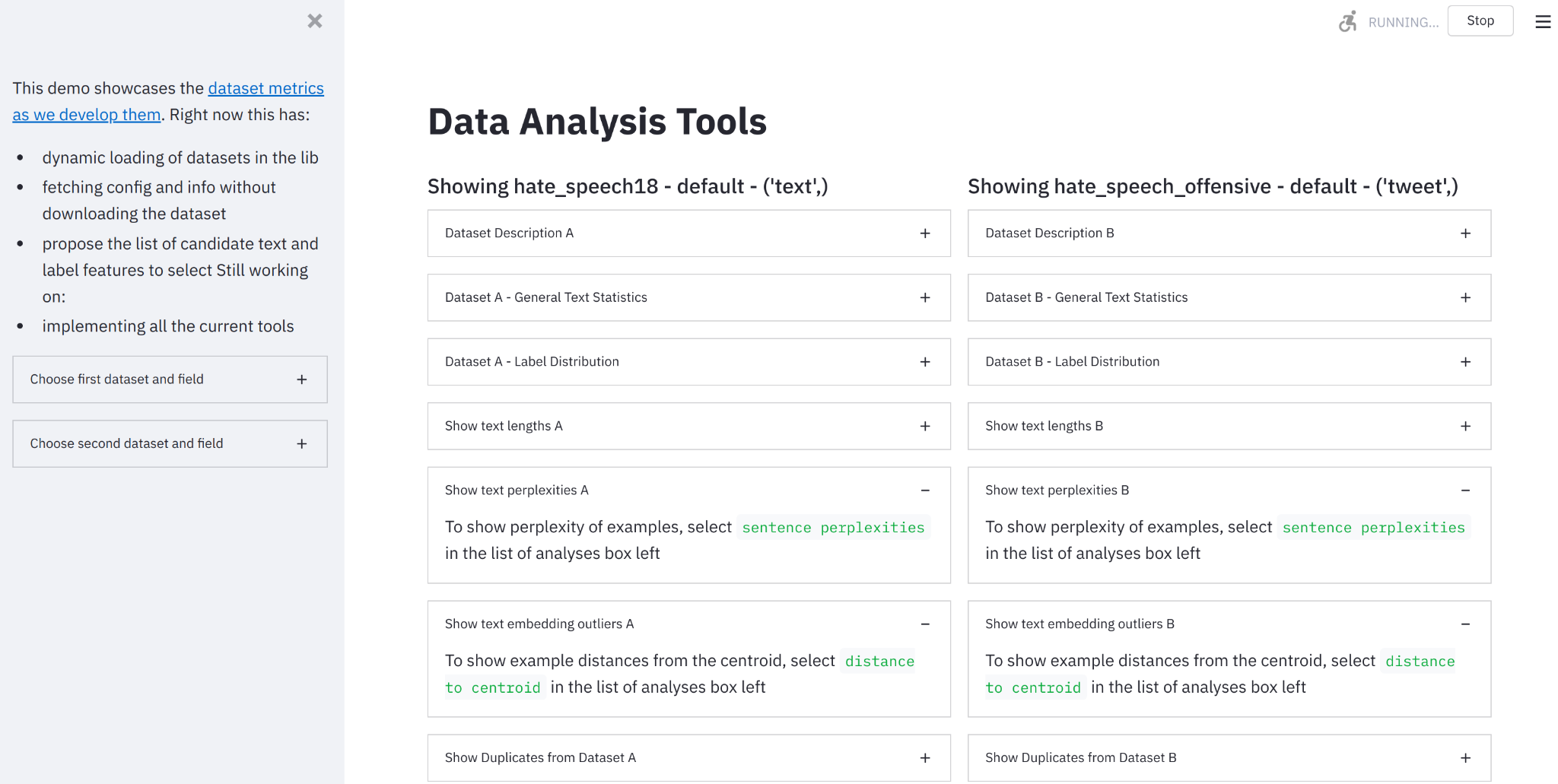
データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。 🤗データ計測ツールにアクセスするには、ここをクリックしてください。 機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。 そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。 🤗データ計測ツールとは何ですか? データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。 なぜこのツールを作成したのですか? 機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et…

カスタムデータセットでセマンティックセグメンテーションモデルを微調整する
このガイドでは、最先端のセマンティックセグメンテーションモデルであるSegformerのファインチューニング方法を紹介します。私たちの目標は、ピザ配達ロボットのためのモデルを構築することで、それによってロボットがどこに進むべきかを見ることができ、障害物を認識できるようにすることです 🍕🤖。最初に、Segments.aiで一連の歩道の画像にラベルを付けます。次に、🤗 transformersというオープンソースのライブラリを使用して、事前学習済みのSegFormerモデルをファインチューニングします。このライブラリは、最先端のモデルの簡単な実装を提供しています。このプロセスで、最大のオープンソースのモデルとデータセットのカタログであるHugging Face Hubの使用方法も学びます。 セマンティックセグメンテーションは、画像内の各ピクセルを分類するタスクです。これはより正確な画像の分類方法と見なすことができます。医療画像や自動運転など、さまざまな分野で幅広い用途があります。例えば、ピザ配達ロボットの場合、画像内の歩道がどこにあるか正確に知ることが重要です。 セマンティックセグメンテーションは分類の一種であるため、画像分類とセマンティックセグメンテーションに使用されるネットワークアーキテクチャは非常に似ています。2014年、Longらによる画像セグメンテーションのための異彩を放つ論文では、畳み込みニューラルネットワークが使用されています。最近では、画像分類にTransformers(例:ViT)が使用されており、最新のセマンティックセグメンテーションにも使用されており、最先端の技術をさらに押し上げています。 SegFormerは、2021年にXieらによって提案されたセマンティックセグメンテーションのモデルです。ポジションエンコーディングを使用しない階層的なトランスフォーマーエンコーダと、単純な多層パーセプトロンデコーダを持っています。SegFormerは、複数の一般的なデータセットで最先端の性能を実現しています。さあ、ピザ配達ロボットが歩道の画像でどのようにパフォーマンスを発揮するか見てみましょう。 必要な依存関係をインストールして始めましょう。データセットとモデルをHugging Face Hubにプッシュするために、Git LFSをインストールし、Hugging Faceにログインする必要があります。 git-lfsのインストール方法は、お使いのシステムによって異なる場合があります。Google ColabにはGit LFSが事前にインストールされていることに注意してください。 pip install -q transformers datasets evaluate segments-ai apt-get…

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…

機械学習洞察のディレクター
機械学習のテーブルの席は、技術的なスキル、問題解決能力、ビジネスの洞察力など、ディレクターのような役職にしかないものです。 機械学習および/またはデータサイエンスのディレクターは、しばしばMLシステムの設計、数学の深い知識、MLフレームワークの熟知、リッチなデータアーキテクチャの理解、実世界のアプリケーションへのMLの適用経験、優れたコミュニケーションスキルを持つことが求められます。また、業界の最新動向に常に精通していることも期待されています。これは大変な注文です! これらの理由から、私たちはこのユニークなMLディレクターのグループにアクセスし、ヘルスケアからファイナンス、eコマース、SaaS、研究、メディアなど、さまざまな産業における彼らの現在のMLの洞察と業界のトレンドについての記事シリーズを作成しました。たとえば、あるディレクターは、MLを使用して空の空転トラック運転(約20%の時間が発生)をわずか19%に減らすことで、約10万人のアメリカ人の炭素排出量を削減できると指摘しています。注意:これは元ロケット科学者によって行われた即興の計算ですが、私たちはそれを受け入れます。 この最初のインストールでは、地中に埋まった地雷を検出するために地中レーダーを使用している研究者、元ロケット科学者、ツォンカ語に堪能なアマチュアゲーマー(クズ=こんにちは!)、バン生活を送っていた科学者、まだ実践的な高性能データサイエンスチームのコーチ、関係性、家族、犬、ピザを大切にするデータ実践者など、豊富なフィールドの洞察を持つ機械学習ディレクターの意見を紹介します。 🚀 さまざまな産業における機械学習ディレクターのトップと出会い、彼らの見解を聞いてみましょう: アーキ・ミトラ – Buzzfeedの機械学習ディレクター 背景:ビジネスにおけるMLの約束にバランスをもたらす。プロセスよりも人。希望よりも戦略。AIの利益よりもAIの倫理。ブラウン・ニューヨーカー。 興味深い事実:ツォンカ語を話すことができます(Googleで検索してください!)そしてYouth for Sevaを支援しています。 Buzzfeed:デジタルメディアに焦点を当てたアメリカのインターネットメディア、ニュース、エンターテイメント会社。 1. MLがメディアにポジティブな影響を与えたのはどのような点ですか? 顧客のためのプライバシー重視のパーソナライゼーション:すべてのユーザーは個別であり、長期的な関心事は安定していますが、短期的な関心事は確率的です。彼らはメディアとの関係がこれを反映することを期待しています。ハードウェアアクセラレーションの進歩と推奨のためのディープラーニングの組み合わせにより、この微妙なニュアンスを解読し、ユーザーに適切なコンテンツを適切なタイミングで適切なタッチポイントで提供する能力が解き放たれました。 メディア製作者のための支援ツール:メディアにおける制作者は限られた資産ですが、MLによる人間-ループアシストツールにより、彼らの創造的な能力を保護し、協力的なマシン-人間のフライホイールを解き放つことができました。適切なタイトル、画像、ビデオ、および/またはコンテンツに合わせて自動的に提案するだけの簡単なことでも、協力的なマシン-人間のフライホイールを解き放つことができます。 テストの締め付け:資本集約型のメディアベンチャーでは、ユーザーの共感を得る情報を収集する時間を短縮し、即座に行動する必要があります。ベイジアンテクニックのさまざまな手法と強化学習の進歩により、時間だけでなくそれに関連するコストも大幅に削減することができました。 2. メディア内の最大のMLの課題は何ですか? プライバシー、編集の声、公平な報道:メディアは今以上に民主主義の重要な柱です。MLはそれを尊重し、他のドメインや業界では明確に考慮されない制約の中で操作する必要があります。編集によるカリキュレーションされたコンテンツとプログラミングとMLによる推奨のバランスを見つけることは、依然として課題です。BuzzFeedにとってももう1つのユニークな課題は、インターネットは自由であるべきだと信じているため、他の企業とは異なり、ユーザーを追跡していないことです。 3. メディアへのMLの統合を試みる際に、よく見かける間違いは何ですか?…

深層強化学習の概要
Hugging FaceとのDeep Reinforcement Learningクラスの第1章 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 人工知能の最も魅力的なトピックへようこそ: Deep Reinforcement Learning(深層強化学習) Deep RLは、エージェントが行動を実行し、結果を観察することで、環境内でどのように振る舞うかを学習する機械学習の一種です。…

transformers、accelerate、bitsandbytesを使用した大規模トランスフォーマーの8ビット行列乗算へのやさしい入門
導入 言語モデルはますます大きくなっています。この執筆時点では、PaLMは540Bのパラメータを持ち、OPT、GPT-3、およびBLOOMは約176Bのパラメータを持ち、さらに大きなモデルに向かっています。以下は、いくつかの最近の言語モデルのサイズを示した図です。 したがって、これらのモデルは簡単にアクセス可能なデバイス上で実行するのが難しいです。例えば、BLOOM-176Bで推論を行うためには、8つの80GBのA100 GPU(各約15,000ドル)が必要です。BLOOM-176Bを微調整するには、これらのGPUが72台必要です!PaLMのようなさらに大きなモデルでは、さらに多くのリソースが必要です。 これらの巨大なモデルは多くのGPUで実行する必要があるため、モデルの性能を維持しながらこれらの要件を削減する方法を見つける必要があります。モデルサイズを縮小するためのさまざまな技術が開発されており、量子化や蒸留などの技術があります。 BLOOM-176Bのトレーニングを完了した後、HuggingFaceとBigScienceでは、この大きなモデルをより少ないGPUで簡単に実行できるようにする方法を探していました。BigScienceコミュニティを通じて、大規模モデルの予測パフォーマンスを低下させずに大規模モデルのメモリフットプリントを2倍に減らすInt8推論の研究について知らされました。すぐにこの研究に協力し始め、Hugging Faceのtransformersに完全に統合することで終了しました。このブログ記事では、Hugging FaceモデルのLLM.int8()統合を提供し、詳細を以下で説明します。研究についてもっと読みたい場合は、論文「LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale」を読んでください。 この記事では、この量子化技術の高レベルの概要を提供し、transformersライブラリへの統合の難しさを概説し、このパートナーシップの長期的な目標を立てます。 ここでは、なぜ大きなモデルが多くのメモリを使用するのか、BLOOMが350GBになる理由について、少しずつ基本的な前提を説明します。 機械学習で使用される一般的なデータ型 まず、機械学習の文脈では「精度」とも呼ばれる異なる浮動小数点データ型の基本的な理解から始めます。 モデルのサイズは、そのパラメータの数とその精度によって決まります。一般的には、float32、float16、またはbfloat16のいずれかのデータ型が使用されます(以下の画像は、https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/から引用されています)。 Float32(FP32)は、標準化されたIEEE 32ビット浮動小数点表現を表します。このデータ型では、幅広い浮動小数点数を表現することが可能です。FP32では、8ビットが「指数」に、23ビットが「仮数」に、1ビットが数値の符号に予約されています。さらに、ほとんどのハードウェアはFP32の操作と命令をサポートしています。 浮動小数点16ビット(FP16)のデータ型では、5ビットが指数に、10ビットが仮数に予約されています。これにより、FP16数の表現可能な範囲はFP32よりもはるかに低くなります。これにより、FP16数はオーバーフロー(非常に大きな数を表現しようとする)やアンダーフロー(非常に小さな数を表現する)のリスクにさらされます。 例えば、10k…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.