Learn more about Search Results お知らせ - Page 16

- You may be interested
- 「ダイナミックな時代のソフトウェアリー...
- 「2023年における最高のAIファイナンスツ...
- MITとマイクロソフトの研究者が、DoLaとい...
- 極小データセットを用いたテキスト分類チ...
- 「学習におけるマウスの驚くべきアプロー...
- ChatGPTを使ってコーディングする方法R...
- チャットボットの台頭
- 「Code Llama内部:Meta AIがCode LLMスペ...
- スマートなメスは、医師が手術のスキルを...
- MITとETH Zurichの研究者たちが、動的なセ...
- 「ステーブル拡散」は実際にどのように機...
- vLLM:24倍速のLLM推論のためのPagedAtten...
- 「Huggy Lingo:Hugging Face Hubで言語メ...
- 「ChatGPT Canvaプラグインでグラフィック...
- 「AI規制、キャピトルヒルで初歩的な進展...

拡散モデルライブイベント
嬉しいお知らせです!Hugging FaceとJonathan WhitakerとのDiffusion Models Classが11月28日に公開されます🥳!この無料のコースでは、ディープラーニングの今年の最もエキサイティングな進展の一つである拡散モデルの理論と応用について学ぶことができます。もし拡散モデルについて初めて聞いた方は、以下のデモでその可能性を実感してください: この公開に合わせて、11月30日にライブコミュニティイベントを開催します。あなたも参加することができます!プログラムには、Stable Diffusionのクリエイター、Stability AIとMetaの研究者など、興奮するトークが含まれています! 参加登録は、このフォームからお願いします。スピーカーやトークの詳細は以下で提供されています。 ライブトーク トークは、拡散モデルの高レベルなプレゼンテーションと、それらを使ってアプリケーションを構築するためのツールに焦点を当てます。

GPT2からStable Diffusionへ:Hugging FaceがElixirコミュニティに参入します
エリクサーのコミュニティは、GPT2からStable Diffusionまでのいくつかのニューラルネットワークモデルがエリクサーに到着したことをお知らせいたします。これは、Hugging Face Transformersを純粋なエリクサーで実装したBumblebeeライブラリによって可能になりました。 これらのモデルで始めるために、エリクサーの計算ノートブックプラットフォームであるLivebookのチームが、「スマートセル」と呼ばれるコレクションを作成しました。これにより、開発者はわずか3回のクリックで異なるニューラルネットワークタスクのスキャフォールドを作成できます。詳細については、私のビデオアナウンスをご覧ください。 エリクサーが実行されるErlang仮想マシンの並行性と分散サポートのおかげで、開発者はこれらのモデルを既存のPhoenixウェブアプリケーションの一部として埋め込み、提供することができます。また、Broadwayを使用してデータ処理パイプラインに統合し、Nerves組み込みシステムと一緒にデプロイすることもできます。いずれのシナリオでも、BumblebeeモデルはCPUとGPUの両方にコンパイルされます。 背景 エリクサーに機械学習を導入する取り組みは、ほぼ2年前にNumerical Elixir(Nx)プロジェクトで始まりました。Nxプロジェクトは、マルチ次元テンソルと「数値定義」を実装しています。これは、CPU/GPUにコンパイルできるElixirのサブセットです。Nxは、Google XLA(EXLA)とLibtorch(Torchx)のバインディングを使用して、車輪の再発明を防いでいます。 Nxイニシアチブからは、他のいくつかのプロジェクトが生まれました。Axonは、FlaxやPyTorch Igniteなどのプロジェクトからインスピレーションを受け、エリクサーに機能的で組み合わせ可能なニューラルネットワークをもたらします。Explorerプロジェクトは、dplyrとRustのPolarsから借用して、エリクサーコミュニティに表現力豊かで高性能なデータフレームを提供します。 BumblebeeとTokenizersは、私たちが最近リリースしたものです。私たちは、Hugging Faceがコミュニティとツール間での協力的な機械学習を可能にすることに感謝しています。これは、エリクサーエコシステムを迅速に進化させる上で重要な役割を果たしました。 次に、エリクサーでのニューラルネットワークのトレーニングと転移学習に焦点を当てる予定です。これにより、開発者は事業やアプリケーションのニーズに合わせて事前学習済みモデルを拡張および特化することができます。また、伝統的な機械学習アルゴリズムの開発についても、さらに発表する予定です。 あなたの番です Bumblebeeを試してみたい場合は、次のことができます: Livebook v0.8をダウンロードし、ノートブック内の「+ Smart」セルメニューから「ニューラルネットワークタスク」を自動生成します。現在、Livebookを追加のプラットフォームとスペースで実行できるようにする作業を進めています(お楽しみに!😉)。 Bumblebeeモデルの例として、単一ファイルのPhoenixアプリケーションも作成しました。これは、Phoenix(+ LiveView)アプリケーションの一部として統合するための必要な基盤を提供します。 より実践的なアプローチに興味がある場合は、いくつかのノートブックを読んでみてください。 エリクサーの機械学習エコシステムの構築を支援したい場合は、上記のプロジェクトをチェックして試してみてください。コンパイラ開発からモデル構築まで、多くの興味深い領域があります。たとえば、Bumblebeeにさらにモデルやアーキテクチャを追加するプルリクエストは、歓迎されるでしょう。未来は並行、分散、そして楽しいです!

モデルカード
イントロダクション モデルカードは、機械学習モデルの理解、共有、改善のための重要なドキュメンテーションフレームワークです。適切に行われた場合、モデルカードは境界オブジェクトとして機能し、異なるバックグラウンドや目標を持つ人々(開発者、学生、政策立案者、倫理学者、機械学習モデルに影響を受ける人々など)がモデルを理解するためにアクセスできる単一のアーティファクトとなります。 今日、私たちはモデルカードの作成ツールとモデルカードガイドブックを発表しました。モデルカードの記入方法、ユーザースタディ、MLドキュメンテーションの最先端について詳しく説明しています。この作業は、他の多くの人々や組織によるものを基にしており、異なるバックグラウンドや役割を持つ人々の包括的な参加を重視しています。私たちは、これが改善されたMLドキュメンテーションの道筋となることを願っています。 要約すると、今日は以下のリリースを発表します: プログラムを必要とせずにカード作成を容易にするモデルカードクリエーターツール。さらに、異なるセクションの作業をチームで共有するための支援をします。 huggingface_hubライブラリでリリースされた更新されたモデルカードテンプレート。学界や業界全体でのモデルカードの作業をまとめています。 カードの記入方法を詳しく説明した注釈付きモデルカードテンプレート。 Hugging Faceでのモデルカードの使用に関するユーザースタディ。 モデルドキュメンテーションの最先端に関するランドスケープ分析と文献レビュー。 現在までのモデルカード モデルカードは、Mitchellらによって提案され、自然言語処理のデータステートメント(Bender&Friedman、2018)やデータセットのデータシート(Gebruら、2018)といった主要なドキュメンテーションフレームワークの努力に触発されています。機械学習ドキュメンテーションの領域は拡大し進化しており、データ、モデル、およびMLシステムのためのさまざまなドキュメンテーションツールやテンプレートが提案され、開発されてきました。これには、何百もの研究者、関係者、提唱者などの信じられないほどの研究成果が反映されています。また、MLドキュメンテーションと責任あるAIの変革理論との関係について重要な議論も、MLドキュメンテーションエコシステムの発展に影響を与えています。 ML内のドキュメンテーションにおけるこれまでの取り組みは、さまざまな対象に対応しています。私たちは、今日共有する作業でこれらのアイデアの多くを取り入れています。 私たちの取り組み 私たちの作業は、モデルカードの現在の状況と将来の展望を示しています。私たちは、成長するMLドキュメンテーションツールのランドスケープを広範に分析し、Hugging Face内でユーザーインタビューを行い、モデルカードに関する多様な意見を補完しました。また、Hugging Face HubのMLモデルに対してモデルカードを作成または更新し、これらの経験を基に新しいモデルカードのテンプレートを提案しています。 モデルカードの標準化 ガイドブックでさらに詳しく説明されている背景調査やユーザースタディを通じて、一般の人々が理解する「モデルカード」の新しい標準を確立することを目指しました。 これらの調査結果に基づいて、HFモデルカードの構造と内容を標準化するだけでなく、デフォルトのプロンプトテキストも提供する新しいモデルカードテンプレートを作成しました。このテキストは、モデルカードのセクションの執筆を支援するためのものであり、特にバイアス、リスク、制限のセクションに焦点を当てています。 アクセシビリティと包括性 モデルカードの作成における参加のハードルを下げるために、モデルカード作成ツールを設計しました。これは、グラフィカルユーザーインターフェース(GUI)を備えたツールであり、コーディングやマークダウンの使用を必要とせずに、さまざまなスキルセットや役割を持つ人々やチームが簡単に協力してモデルカードを作成できるようにします。 この作成ツールは、モデルカードをまだ作成していない人々に簡単に作成するように促し、以前にモデルカードを作成したことがある人々にはプロンプトされた情報を追加するように促します。同時に、倫理的な要素を重視します。…
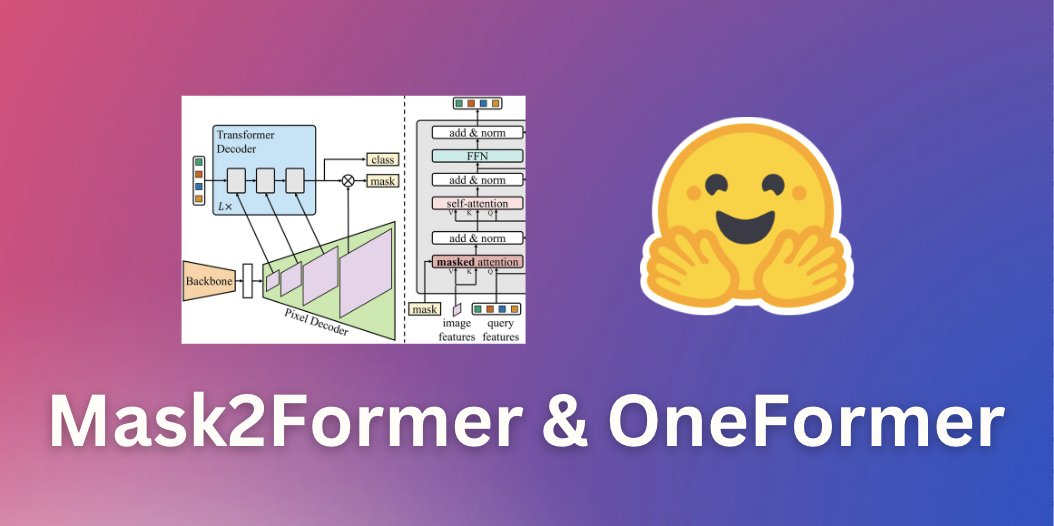
マスク2フォーマーとワンフォーマーによるユニバーサル画像セグメンテーション
このガイドでは、画像セグメンテーションのための最先端のニューラルネットワークであるMask2FormerとOneFormerを紹介します。これらのモデルは、最先端モデルの簡単な実装を提供するオープンソースのライブラリである🤗 transformersで利用できます。途中で、さまざまな形式の画像セグメンテーションの違いについて学びます。 画像セグメンテーション 画像セグメンテーションは、人や車などの画像内の異なる「セグメント」を識別するタスクです。より具体的には、画像セグメンテーションは異なる意味を持つピクセルをグループ化するタスクです。詳細については、Hugging Faceのタスクページを参照してください。 画像セグメンテーションは、主に3つのサブタスクに分割できます。それぞれのサブタスクを実行するための多数の方法とモデルアーキテクチャがあります。 インスタンスセグメンテーションは、画像内の個々の人物などの異なる「インスタンス」を識別するタスクです。インスタンスセグメンテーションは、オブジェクト検出と非常に似ていますが、境界ボックスではなく、対応するクラスラベルとともに一連のバイナリセグメンテーションマスクを出力したいという点が異なります。インスタンスはしばしば「オブジェクト」や「事物」とも呼ばれます。ただし、個々のインスタンスは重なる場合があります。 意味セグメンテーションは、画像の各ピクセルの「人」や「空」などの異なる「意味カテゴリ」を識別するタスクです。インスタンスセグメンテーションとは異なり、与えられた意味カテゴリの個々のインスタンスの区別はありません。たとえば、「人」のカテゴリのマスクを作成するだけであり、個々の人物のマスクを作成するわけではありません。対象カテゴリに個別のインスタンスがない「空」や「草」などの意味カテゴリは、しばしば「物」と呼ばれます(素晴らしい名前ですね)。ピクセルごとのカテゴリには重なりがないことに注意してください。 パノプティックセグメンテーションは、Kirillov et al.によって2018年に導入され、モデルが対応するバイナリマスクとクラスラベルのセットを単に識別することで、インスタンスセグメンテーションと意味セグメンテーションを統一することを目指しています。セグメントは「物」または「物」のどちらでもなります。インスタンスセグメンテーションとは異なり、異なるセグメント間の重なりはありません。 以下の図は、3つのサブタスクの違いを示しています(このブログ投稿から取得)。 ここ数年、研究者たちは通常、インスタンスセグメンテーション、意味セグメンテーション、パノプティックセグメンテーションのいずれかに特化したいくつかのアーキテクチャを提案してきました。インスタンスセグメンテーションとパノプティックセグメンテーションは、通常、オブジェクトインスタンスごとにバイナリマスクと対応するラベルのセットを出力することによって解決されました(インスタンス検出と非常に似ていますが、インスタンスごとに境界ボックスの代わりにバイナリマスクを出力します)。これは通常「バイナリマスク分類」と呼ばれます。一方、意味セグメンテーションは、モデルがピクセルごとに1つの「セグメンテーションマップ」を出力することで解決されることが一般的でした。したがって、意味セグメンテーションは「ピクセルごとの分類」の問題として扱われました。このパラダイムを採用する人気のある意味セグメンテーションモデルには、SegFormer(詳細なブログ投稿を書いた)とUPerNetなどがあります。 ユニバーサル画像セグメンテーション 幸いなことに、2020年ごろから、インスタンスセグメンテーション、意味セグメンテーション、およびパノプティックセグメンテーションのすべてのタスクを統一されたアーキテクチャで解決できるモデルが登場し始めました。これは最初にDETRが行ったものであり、”物”クラスと”物”クラスを統一的な方法で扱うことによってパノプティックセグメンテーションを解決した最初のモデルでした。キーイノベーションは、トランスフォーマーデコーダが並列的に一連のバイナリマスクとクラスを生成することでした。これはMaskFormerの論文で改善され、”バイナリマスク分類”のパラダイムが意味セグメンテーションにも非常にうまく適用されることが示されました。 Mask2Formerは、ニューラルネットワークアーキテクチャをさらに改善することで、インスタンスセグメンテーションにも拡張します。したがって、個別のアーキテクチャから、研究者たちが現在「ユニバーサル画像セグメンテーション」と呼んでいる、すべての画像セグメンテーションタスクを解決できるアーキテクチャに進化しました。興味深いことに、これらのユニバーサルモデルはすべて「マスク分類」のパラダイムを採用しており、完全に「ピクセルごとの分類」のパラダイムを廃止しています。Mask2Formerのアーキテクチャを示す図は、以下に示されています(オリジナルの論文から取得)。 要するに、画像はまずバックボーン(この論文ではResNetまたはSwin Transformerのどちらか)に送信されて、低解像度の特徴マップのリストを取得します。次に、これらの特徴マップは、ピクセルデコーダモジュールを使用して高解像度の特徴に改善されます。最後に、トランスフォーマーデコーダは一連のクエリを受け取り、ピクセルデコーダの特徴に基づいて一連のバイナリマスクとクラスの予測を行います。 Mask2Formerは、最先端の結果を得るために、各タスクごとにトレーニングする必要があることに注意してください。これは、OneFormerモデルによって改善されました。OneFormerモデルは、データセットのパノプティックバージョンのみをトレーニングすることで、すべての3つのタスクで最先端のパフォーマンスを実現します。さらに、テキストエンコーダを追加してモデルを「インスタンス」、「セマンティック」、または「パノプティック」の入力に条件付けることで、これをさらに改善しました。このモデルは、今日でも🤗 transformersで利用できます。Mask2Formerよりも精度が高くなっていますが、追加のテキストエンコーダにより遅延が大きくなります。OneFormerの概要については、以下の図を参照してください。Swin Transformerまたは新しいDiNATモデルをバックボーンとして使用しています。 TransformersでのMask2FormerとOneFormerの推論 Mask2FormerとOneFormerの使用法は非常に簡単であり、前身であるMaskFormerと非常に似ています。COCOパノプティックデータセットでトレーニングされたハブからMask2Formerモデルをインスタンス化し、それに対応するプロセッサもインスタンス化します。作者たちはさまざまなデータセットでトレーニングされた30個以上のチェックポイントをリリースしていることに注意してください。 from…

どのような要素が対話エージェントを有用にするのか?
ChatGPTの技術:RLHF、IFT、CoT、レッドチーミング、およびその他 この記事は、中国語の簡体字で翻訳されています。 数週間前、ChatGPTが登場し、一連の不明瞭な頭字語(RLHF、SFT、IFT、CoTなど)が公衆の議論を巻き起こしました。これらの不明瞭な頭字語は何であり、なぜそれらが重要なのでしょうか?私たちはこれらのトピックに関する重要な論文を調査し、これらの作品を分類し、達成された成果からの要点をまとめ、まだ示されていないことを共有します。 まず、言語モデルに基づく会話エージェントの現状を見てみましょう。ChatGPTは最初ではありません。実際、OpenAIよりも前に、MetaのBlenderBot、GoogleのLaMDA、DeepMindのSparrow、およびAnthropicのAssistant(このエージェントの完璧な帰属なしでの継続的な開発はClaudeとも呼ばれています)など、多くの組織が言語モデルの対話エージェントを公開しています。一部のグループは、オープンソースのチャットボットを構築する計画を発表し、ロードマップを公開しています(LAIONのOpen Assistant)。他のグループも確実に同様の作業を進めており、まだ発表していないでしょう。 以下の表は、これらのAIチャットボットを公開アクセス、トレーニングデータ、モデルアーキテクチャ、および評価方向の詳細に基づいて比較しています。ChatGPTには文書化された情報がないため、代わりにChatGPTの基礎となったと信じられているOpenAIの指示fine-tunedモデルであるInstructGPTの詳細を共有します。 トレーニングデータ、モデル、およびファインチューニングには多くの違いがあることが観察されますが、共通点もあります。これらのチャットボットの共通の目標は、ユーザーの指示に従うことです。たとえば、ChatGPTに詩を書くように指示することなどです。 予測テキストから指示の従属へ 通常、ベースモデルの言語モデリング目標だけでは、モデルがユーザーの指示に対して有益な方法で従うことを学ぶには十分ではありません。モデル開発者は、指示の細かいチューニング(IFT)を使用して、ベースモデルを、感情、テキスト分類、要約などの古典的なNLPタスクのデモンストレーションによって微調整し、非常に多様なタスクセットにおける指示の書かれた方針を学びます。これらの指示のデモンストレーションは、指示、入力、および出力の3つの主要なコンポーネントで構成されています。入力はオプションです。一部のタスクでは、ChatGPTの例のように指示のみが必要です。入力と出力が存在する場合、インスタンスが形成されます。特定の指示に対して複数の入力と出力が存在する場合もあります。以下に[Wang et al.、’22]からの例を示します。 IFTのデータは通常、人間によって書かれた指示と言語モデルを用いた指示のインスタンスのコレクションからなります。ブートストラップのために、LMは(上記の図のように)いくつかの例を使用してフューショット設定でプロンプトされ、新しい指示、入力、および出力を生成するように指示されます。各ラウンドで、モデルは人間によって選択されたサンプルとモデルによって生成されたサンプルの両方からプロンプトを受け取ります。データセットの作成における人間とモデルの貢献の割合はスペクトラムです。以下の図を参照してください。 一方は完全にモデル生成されたIFTデータセットであり、例えばUnnatural Instructions(Honovich et al.、’22)です。もう一方は手作りの指示の大規模な共同作業であり、Super-natural instructions(Wang et al.、’22)などです。これらの間には、Self-instruct(Wang et al.、’22)のような、高品質のシードデータセットを使用してブートストラップする方法もあります。IFTのデータセットを収集するもう1つの方法は、さまざまなタスク(プロンプトを含む)の既存の高品質なクラウドソーシングNLPデータセットを統一スキーマや多様なテンプレートを使用して指示としてキャストすることです。この研究の一環には、T0(Sanh et al.、’22)、自然言語指示データセット(Mishra et…

ストーリーの生成:ゲーム開発のためのAI #5
AIゲーム開発へようこそ!このシリーズでは、AIツールを使用してわずか5日で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに取り入れる方法を学ぶことができます。以下のような目的でAIツールを使用する方法をお見せします: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが欲しいですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細を読み続けてください! 注:この投稿では、ゲームデザインにChatGPTを使用したPart 2への参照がいくつかあります。ChatGPTの動作方法、言語モデルの概要、およびその制限についての追加のコンテキストについては、Part 2をお読みください。 Day 5: ストーリー このチュートリアルシリーズのPart 4では、Stable DiffusionとImage2Imageを2Dアセットのワークフローに使用する方法について説明しました。 この最終パートでは、ストーリーにAIを使用します。まず、農業ゲームのプロセスを説明し、注意すべき⚠️ 制限事項について説明します。次に、ゲーム開発の文脈での関連技術と今後の方向性について話します。最後に、最終的なゲームについてまとめます。 プロセス 要件:このプロセス全体でChatGPTを使用しています。ChatGPTと言語モデリングについての詳細については、シリーズのPart 2をお読みいただくことをおすすめします。ChatGPTは唯一の解決策ではありません。オープンソースの対話エージェントなど、数多くの新興競合他社が存在します。対話エージェントの新興市場についてさらに詳しく学ぶために、先を読んでください。 ChatGPTにストーリーの執筆を依頼します。ゲームに関する多くのコンテキストを提供した後、ChatGPTにストーリーの要約を書いてもらいます。 ChatGPTは、ゲームStardew…

音声合成、音声認識、そしてSpeechT5を使ったその他の機能
私たちは喜んでお知らせします。SpeechT5は🤗Transformersで利用可能になりました。これは最先端の機械学習モデルの簡単に使用できる実装を提供するオープンソースライブラリです。 SpeechT5はもともと、Microsoft Research Asiaによって開発された論文「SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing」で説明されています。論文の著者が公開した公式のチェックポイントはHugging Face Hubで利用可能です。 すぐに試してみたい場合は、以下のデモがあります: 音声合成(TTS) 音声変換 自動音声認識 はじめに SpeechT5は、1つのアーキテクチャに3つの異なる種類の音声モデルを組み込んでいます。 以下のことができます: 音声からテキストへの変換(自動音声認識や話者識別に使用) テキストから音声への変換(音声を合成) 音声から音声への変換(異なる声や音声の強調を行う) SpeechT5の基本的なアイデアは、テキストから音声、音声からテキスト、テキストからテキスト、音声から音声までのデータの混合で単一のモデルを事前学習することです。これにより、モデルはテキストと音声の両方から同時に学習します。この事前学習アプローチの結果は、テキストと音声の両方に共有される統一された隠れ表現の空間を持つモデルです。…

Diffusersライブラリの開発に関する倫理ガイドライン
私たちは、一つひとつのコミットによって、私たちのライブラリをより責任あるものにする旅に出ています! Diffusersライブラリのドキュメンテーションの一部として、倫理的なフレームワークの公開をお知らせできることを誇りに思っています。 拡散モデルの現実のケースアプリケーションと社会への潜在的な負の影響を考慮すると、このイニシアチブは、Diffusersライブラリのメンテナによるコミュニティの貢献に関する技術的な意思決定を導くことを目的としています。私たちは、意思決定の方法について透明性を持ち、何よりも、それらの意思決定を導く価値観を明確にすることを目指しています。 私たちは、倫理を、ガイドとなる価値観、具体的な行動、そして継続的な適応というプロセスとして捉えています。そのため、私たちはガイドラインを時間と共に調整することにコミットし、Diffusersプロジェクトの進化と、それを生かし続けるコミュニティからの価値あるフィードバックに従います。 透明性:私たちは、PRの管理やユーザへの選択の説明、技術的な意思決定について透明性を持つことにコミットしています。 一貫性:私たちは、プロジェクトの管理においてユーザに同じレベルの注意を保証し、技術的に安定した一貫性を持つことにコミットしています。 シンプルさ:Diffusersライブラリの使用と活用を容易にするため、プロジェクトのゴールをシンプルで一貫性のあるものにすることにコミットしています。 アクセシビリティ:Diffusersプロジェクトは、技術的な専門知識を持たないコントリビュータでも実行できるようにすることで、研究成果をコミュニティによりアクセスしやすくするお手伝いをします。 再現性:Diffusersライブラリを介して提供されるアップストリームのコード、モデル、データセットの再現性について透明性を持つことを目指しています。 責任:コミュニティとチームワークを通じて、この技術の潜在的なリスクと危険を予測し、軽減するために、私たちはユーザに対して共同の責任を持ちます。 さらに、Hugging Faceチームと広くコミュニティによって実装された安全機能とメカニズムの非網羅的なリストを提供しています。 コミュニティタブ:プロジェクトについて議論し、より良いコラボレーションを図るためのコミュニティタブです。 タグ機能:リポジトリの作成者は、コンテンツを「一般公開しない」とタグ付けすることができます。 バイアスの探索と評価:Hugging Faceチームは、Stable DiffusionとDALL-Eのバイアスを対話的にデモンストレーションするスペースを提供しています。この意味で、バイアスの探求と評価をサポート・奨励しています。 デプロイメントにおける安全性の促進 安全なStable Diffusion:ウェブクロールされたデータセットでトレーニングされたStable Diffusionなどのモデルが不適切な退化に苦しむという問題を緩和します。関連論文:Safe Latent Diffusion: Mitigating…
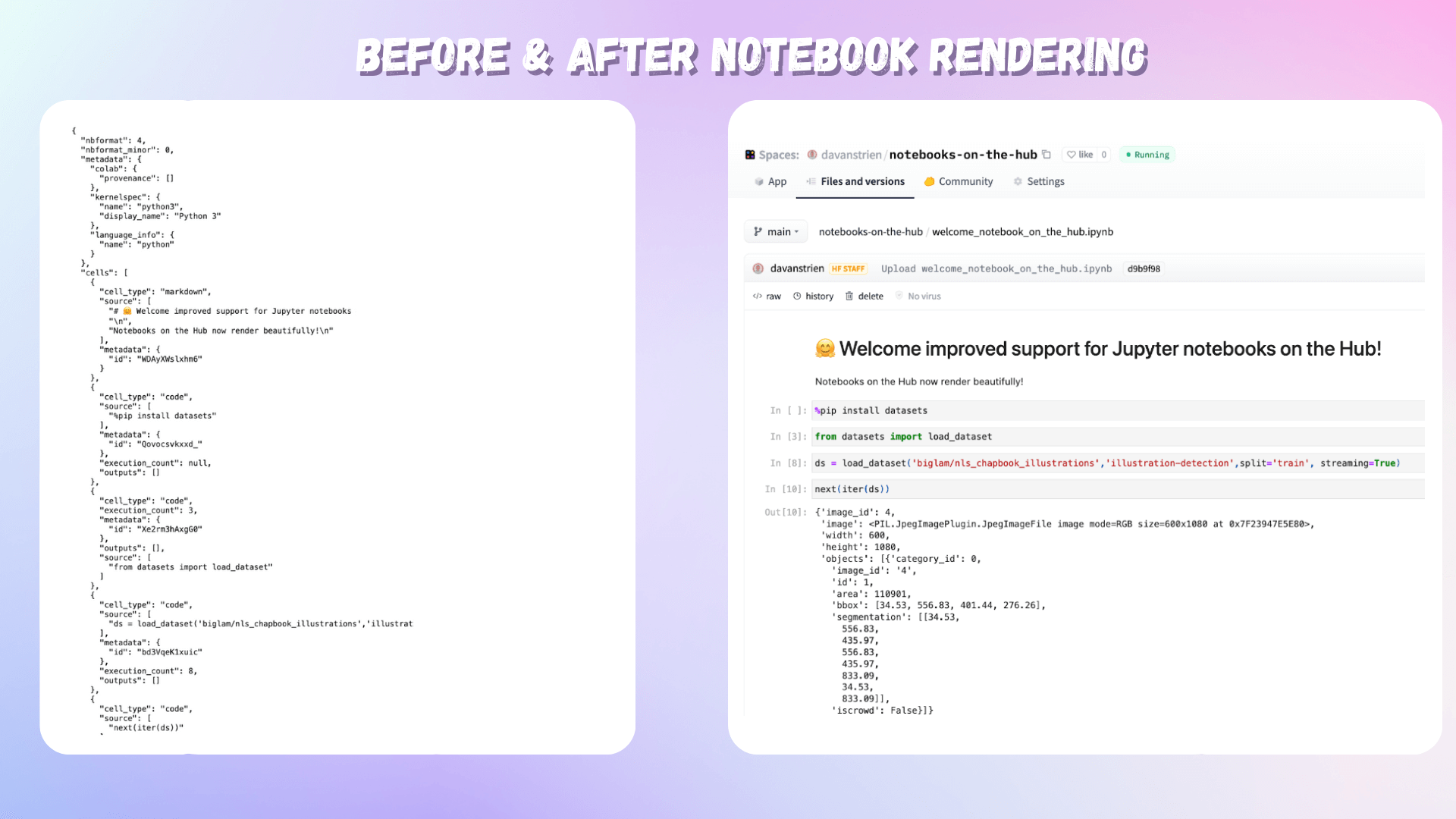
Jupyter × Hugging Face
私たちは、Hugging Face HubでホストされているJupyterノートブックへのサポートを改善したことをお知らせします! Jupyterノートブックは、学習のための重要なリソースとしてだけでなく、モデル開発に使用される主要なツールとして、機械学習のさまざまな分野で重要な要素となっています。ノートブックのインタラクティブでビジュアルな性質により、モデル、データセット、デモを開発する際に素早くフィードバックを受けることができます。多くの人にとって、機械学習モデルのトレーニングへの最初の接触はJupyterノートブックを通じて行われ、多くの実践者はノートブックを自分の作業を開発し、共有するための重要なツールとして使用しています。 Hugging Faceは、共同作業型の機械学習プラットフォームであり、コミュニティは15万以上のモデル、2万5000以上のデータセット、3万以上のMLアプリを共有しています。Hubにはモデルやデータセットのバージョニングツールがあり、モデルカードやクライアントサイドのライブラリを使用してバージョニングプロセスを自動化することができます。ただし、ハイパーパラメータとモデルカードを含めるだけでは、最良の再現性を提供するには十分ではありません。これがノートブックが役立つ場所です。これらのモデル、データセット、デモと共に、Hubには7000以上のノートブックがホストされています。これらのノートブックは、モデルやデータセットの開発プロセスを文書化し、他の人がこれらのリソースをどのように使用できるかを示すガイダンスやチュートリアルを提供することがよくあります。そのため、Hubでのノートブックのホスティングに対する私たちの改善されたサポートには、興奮しています。 何を変更しましたか? Jupyterノートブックファイル(通常はipynb拡張子で共有される)は、JSONファイルです。これらのファイルを直接表示することは可能ですが、人間が読むことを意図した形式ではありません。私たちは、Hubでホストされているノートブックのレンダリングサポートを追加しました。これにより、ノートブックは人間が読みやすい形式で表示されるようになりました。 Hubでホストされているノートブックのレンダリング前後の比較画像 なぜ私たちはHub上でより多くのノートブックをホストすることに興奮しているのでしょうか? ノートブックは、他の人があなたが作成し、共有したリソースを使用する方法を文書化するのに役立ちます。モデルやデータセットと同じ場所でノートブックを共有することで、他の人が作成したリソースを簡単に使用できるようになります。 多くの人々がHubを使用して機械学習のポートフォリオを開発しています。これにより、Jupyterノートブックを使用してこのポートフォリオを補完することができます。 HubでホストされているノートブックをGoogle Colabでワンクリックで直接開くサポートが追加されました。今後の発表にご期待ください!

Hugging Faceは、Microsoftとの協力により、Azure上でHugging Faceモデルカタログを開始します
本日、Hugging FaceはMicrosoftとの協力を拡大し、Hugging Face HubからオープンソースモデルをAzure Machine Learningにもたらすことを発表しました。私たちが共同で新しいHugging Face Hubモデルカタログを作成し、Azure Machine Learning Studio内で直接利用できるようにしました。このカタログには、Hugging Face Hubからの最も人気のあるTransformersモデルが数千点含まれています。この新しい統合により、数クリックでHugging Faceモデルを管理されたエンドポイントにデプロイし、安全かつスケーラブルなAzureインフラ上で実行することができます。 この新しいエクスペリエンスは、昨年Azure Marketplaceで新しい管理アプリとしてAzure Machine Learning Endpointsを立ち上げた際に発表した戦略的パートナーシップを拡大しています。以前のマーケットプレースのソリューションは有望な初期段階でしたが、Azure Machine Learning内でのネイティブな統合を通じてのみ克服できる制約がありました。これらの課題に対処し、お客様のエクスペリエンスを向上させるために、私たちはMicrosoftと協力して、Azure Machine Learning Studio内のHugging…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.