Learn more about Search Results [3] - Page 16

- You may be interested
- 「現実世界でのPythonのトップ10の使用例」
- 「生成AIにおけるニューラル微分方程式の...
- 「Objaverse-XLと出会ってください:1000...
- 「ダイナミックな時代のソフトウェアリー...
- PyTorchを使用した効率的な画像セグメンテ...
- 2023年のコード生成/コーディングにおける...
- ビデオゲームの世界でインタラクティブな...
- 「UBCと本田技研が、敏感なロボット用の革...
- ポイントクラウド用のセグメント化ガイド...
- アンサンブル学習技術:Pythonでのランダ...
- ETH ZurichとMax Plankの研究者が提案する...
- クラゲ、猫、ヘビ、宇宙飛行士は何を共有...
- ピクトリーレビュー(2023年7月):最高の...
- 「Amazon SageMaker Pipelines、GitHub、...
- 「データに基づくストーリーテリングのた...

「固有表現とニュース」
「オランダのニュース記事のデータセットに対して適用された固有表現認識を用いた実験による自動要約、推薦、およびその他の洞察の結果」

LLaMA 皆のためのLLM!
何年もの間、深層学習コミュニティは公開性と透明性を受け入れ、HuggingFaceのような大規模なオープンソースプロジェクトを生み出してきました深層学習における最も重要なアイデアの多くは、このようなプロジェクトで生まれました(例えば...
Pythonにおける型ヒント
先日、過去に作成したスクリプトの動作方法を解読しようとしていました何をするかは分かっていましたし、十分に説明されていてドキュメントもあったのですが、具体的な動作方法を理解するのは困難でした
PlotlyとPandas:効果的なデータ可視化のための力の結集
昔々、私たちの多くがこの問題にぶつかったことがありましたもし才能がないか、前もってデザインのコースを受講したことがなければ、視覚的なものを作ることはかなり困難で時間がかかるかもしれません…

ゼロからdbtモデルを設計する方法
「dbtの究極ガイドを調査していた時、実際にモデルをゼロから構築するための資料がほとんどないことに驚きました具体的な手順はツールの中ですべてカバーされていますが、...」

「サポートベクトルマシンの優しい入門」
「分類のためのサポートベクターマシンの理解ガイド:理論からscikit-learnの実装まで」
サポートベクターマシンへの優しい入門
「分類のためのサポートベクトルマシン理解ガイド 理論からscikit-learnの実装まで」
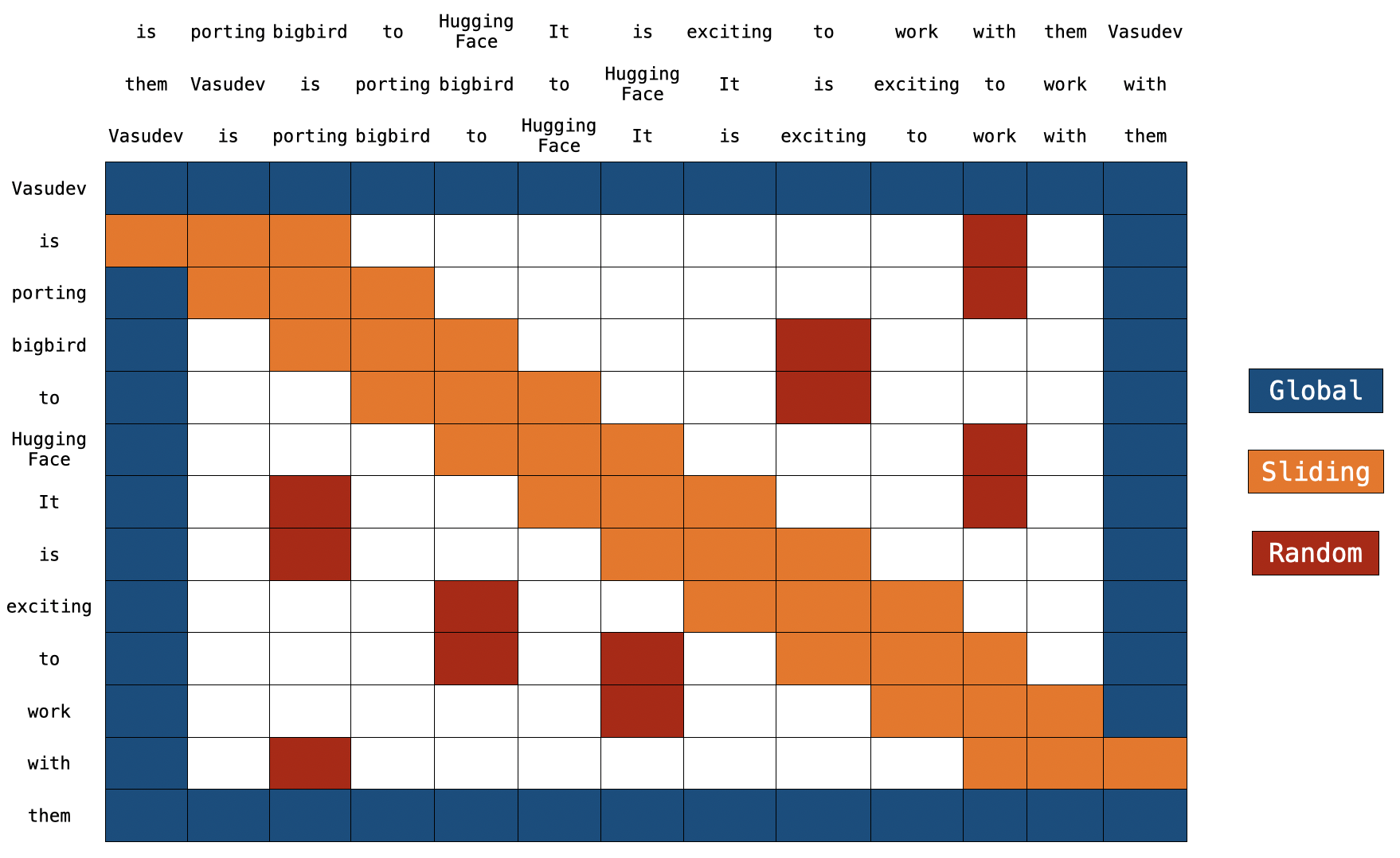
BigBirdのブロック疎な注意機構の理解
イントロダクション トランスフォーマーベースのモデルは、多くの自然言語処理タスクにおいて非常に有用であることが示されています。ただし、トランスフォーマーベースのモデルの主な制限は、O(n^2) の時間とメモリの複雑さ(ここで n はシーケンスの長さです)です。したがって、長いシーケンス n > 512 に対してトランスフォーマーベースのモデルを適用するのは計算上非常に高コストです。最近のいくつかの論文では、Longformer、Performer、Reformer、Clustered attention などが、完全な注意行列を近似することでこの問題を解決しようとしています。これらのモデルについて詳しく知りたい場合は、🤗の最近のブログ記事をチェックしてください。 BigBird(論文で紹介)は、この問題に対処するための最近のモデルの1つです。 BigBird は通常の注意(つまり、BERTの注意)ではなく、ブロックスパースな注意を使用し、BERTよりも低い計算コストで長さ 4096 のシーケンスを処理することができます。 BigBird は、長いドキュメントの要約、長いコンテキストを持つ質問応答など、非常に長いシーケンスを含むさまざまなタスクでSOTAを達成しています。 BigBird RoBERTa-like モデルは現在、🤗Transformersで利用できます。この記事の目的は、読者に 詳細な BigBird の実装の理解を提供し、🤗Transformers…
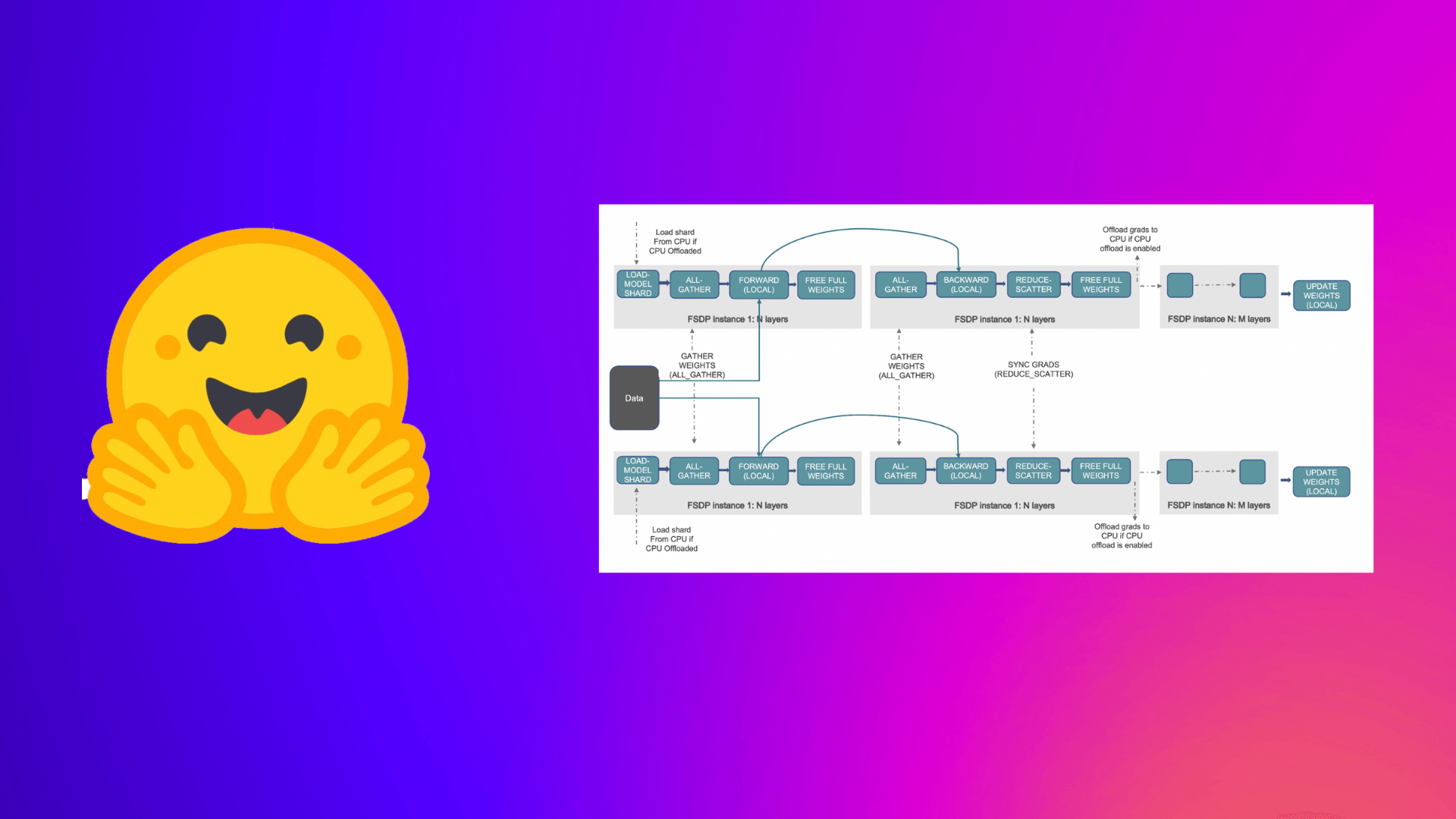
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.