Learn more about Search Results 構成 - Page 169

- You may be interested
- マルコフとビネメ・シェビシェフの不等式
- 未来は今です:MedTechにおけるAIの6つの応用
- 「The Research Agent 大規模なテキストコ...
- 「サンノゼは歩行者の交通事故死を防ぐた...
- Windows上のAnacondaでPythonの依存関係の...
- データサイエンスがどのように価値を提供...
- 他人のPythonコードを簡単に理解する方法は?
- 「基本的なアルゴリズムと機械学習の最新...
- 「Zephyr-7Bの内部:HuggingFaceの超最適...
- 「Python 正しい方法で積分を計算する」
- 「創発的AIのためのガードレール構築への...
- StackLLaMA:RLHFを使用してLLaMAをトレー...
- ロボットが「グリップ」のアップグレード...
- A.I.-検出ツールを騙すのはどれくらい簡単...
- エンターテイメントデータサイエンス:ス...

このGoogleのAI論文は、さまざまなデバイスで大規模な拡散モデルを実行するために画期的なレイテンシー数値を集めるための一連の最適化を提示しています
モデルのサイズと推論ワークロードは、画像生成のための大規模な拡散モデルが一般的になったために急激に増加しています。リソースの限界により、モバイルコンテキストにおけるオンデバイスML推論のパフォーマンス最適化はデリケートなバランスアクトです。これらのモデルのかなりのメモリ要件と計算要件のため、デバイス上で大規模な拡散モデル(LDM)の推論を実行することは、コスト効率とユーザープライバシーの必要性を考慮すると、さらに大きな障壁を生じます。 基礎モデルの迅速な作成と広範な使用は、人工知能を完全に変革しました。その多様性と写真のようなリアルな画像を生成する能力から、大規模な拡散モデルは多くの注目を集めています。サーバーコストの削減、オフライン機能、強化されたユーザープライバシーは、これらのモデルをユーザーのデバイスにローカルに展開することの利点の一部にすぎません。デバイス上の計算およびメモリリソースの制限により、典型的な大規模な拡散モデルには10億以上のパラメータがあり、困難が生じます。 Googleの研究者たちは、モバイルデバイスにおけるGPUを使用した最速の推論レイテンシを可能にする大規模な拡散モデルの実装の一連の変更を提供しています。これらの更新により、さまざまなデバイスで全体的なユーザーエクスペリエンスが向上し、生成AIの利用範囲が拡大します。 低レイテンシ、強化されたプライバシー、大規模なスケーラビリティなど、サーバーベースの方法に比べて多くの利点を持つオンデバイスモデル推論アクセラレーションは、最近注目を集めています。深層学習で頻繁に使用されるsoftmax演算の複雑さは、さまざまな加速戦略を生み出す動機となっています。ウィノグラード畳み込みは、必要な乗算の数を最小限に抑えることにより、畳み込み計算の効率を向上させるために開発されました。これは、グラフィックス処理ユニット(GPU)にとって特に役立ちます。 Transformerデザインの広範な成功と採用は、注意メカニズムの高速化に関する研究を引き起こしました。 Reformerは、計算コストを削減するために疎な近似を使用し、他の作品は低ランクまたは近似テクニックの組み合わせを使用しています。 FlashAttentionは、ハードウェア構成を考慮した正確な注意アルゴリズムであり、より良いパフォーマンスを実現するために使用されます。 主な焦点は、大規模な拡散モデルを使用して書かれた説明からビジュアルを作成するという課題にあります。提案された改善内容がStable Diffusionアーキテクチャとどのように機能するかに焦点が当てられているにもかかわらず、これらの最適化は他の大規模な拡散モデルにも簡単に転送できることは重要です。テキストからの推論は、逆拡散プロセスを誘導するために、望ましいテキストの説明に基づく追加の調整が必要です。 LDMのノイズリダクションモデルで広く使用される注意ブロックは、改善の主要な領域を示しています。モデルは、入力に注意ブロックの重みをより与えることで、関連する情報に絞り込むことができます。注意モジュールは、複数の方法で最適化することができます。以下に詳細を記載された2つの最適化のうち、どちらが最良の結果をもたらすかに応じて、研究者は通常1つだけを利用します。 最初の最適化である部分的に融合されたsoftmaxは、行列の乗算と統合することにより、注意モジュールのsoftmax中に読み取られ、書き込まれるメモリ量を減らします。もう1つの微調整では、I/Oに配慮した正確な注意方法であるFlashAttentionを使用します。 GPUからの高帯域幅メモリアクセスの数を減らすことで、メモリ帯域幅の制限があるアプリケーションには優れた選択肢です。多数のレジスタが必要であり、彼らは、この方法が特定のサイズのSRAMに対してのみ機能することを発見しました。したがって、彼らは特定のサイズの注意行列に対して、一部のGPUでのみこの方法を使用します。 さらに、チームは、LDMの一般的に使用されるレイヤーやユニットの融合ウィンドウが、商用GPUアクセラレートML推論エンジンで現在使用可能なものよりもはるかに大きくなければならないことが判明しました。標準的な融合ルールの制限を考慮して、彼らは、より幅広い種類のニューラルオペレータを実行できるカスタム実装を考案しました。彼らの注意は、ガウス誤差線形ユニット(GELU)とグループ正規化層の2つのサブフィールドに向けられました。 モデルファイルサイズの制限、大量のランタイムメモリ要件、および長時間の推論レイテンシは、デバイス自体での大規模なモデルのML推論を行う際の重要な障害となっています。研究者は、メモリ帯域幅の使用が主要な制約であることを認識しました。したがって、ALU /メモリ効率比を健全に保ちながら、メモリ帯域幅の利用を改善することに焦点を当てました。彼らが実証した最適化は、記録的なレイテンシ値を持つさまざまなデバイスで大規模な拡散モデルを実行することを可能にしました。これらの改善により、モデルの適用範囲が拡大し、幅広いデバイスでユーザーエクスペリエンスが向上しました。

LLM-Blenderに会いましょう:複数のオープンソース大規模言語モデル(LLM)の多様な強みを活用して一貫して優れたパフォーマンスを達成するための新しいアンサンブルフレームワーク
大規模言語モデルは、さまざまなタスクにおいて驚異的なパフォーマンスを発揮しています。ユニークでクリエイティブなコンテンツの生成や回答の提供から、言語の翻訳や文章の要約まで、LLMは人間のまねをすることに成功しました。GPT、BERT、PaLMなどのよく知られたLLMは、正確に指示に従い、大量の高品質データにアクセスすることで、話題になっています。GPT4やPaLMのようなモデルはオープンソースではないため、アーキテクチャやトレーニングデータを理解することができない人がいるのに対して、Pythia、LLaMA、Flan-T5などのオープンソースLLMの存在により、研究者がカスタム指示データセットでモデルを微調整し、改善する機会を提供しています。これにより、Alpaca、Vicuna、OpenAssistant、MPTなどのより小型で効率的なLLMの開発が可能になります。 市場をリードするオープンソースLLMはひとつではありません。多様な例において最高のLLMは大きく異なるため、これらのLLMを動的にアンサンブルすることは、改良された回答を継続して生み出すために必要不可欠です。さまざまなLLMの独自の貢献を統合することで、バイアス、エラー、不確実性を低減し、人間の好みにより近い結果を得ることができます。この問題に対処するため、人工知能アレン研究所、南カリフォルニア大学、浙江大学の研究者らは、複数のオープンソース大規模言語モデルの多くの利点を利用して、常に優れたパフォーマンスを発揮するアンサンブルフレームワークであるLLM-BLENDERを提案しました。 LLM-BLENDERは、PAIRRANKERとGENFUSERの2つのモジュールで構成されています。これらのモジュールは、異なる例に対して最適なLLMが大きく異なることを示しています。最初のモジュールであるPAIRRANKERは、潜在的な出力の微小な変化を特定するために開発されました。これは、元のテキストと各LLMからの2つの候補出力を入力として、高度なペアワイズ比較技術を使用します。入力と候補ペアを共にエンコードするために、RoBERTaなどのクロスアテンションエンコーダを使用し、PAIRRANKERはこのエンコードを使用して2つの候補の品質を決定することができます。 2番目のモジュールであるGENFUSERは、上位ランクに入った候補を統合して改善された出力を生成することに焦点を当てています。GENFUSERは、選択されたLLMの利点を最大限に活用しつつ、欠点を最小限に抑えることを目的としています。GENFUSERは、さまざまなLLMの出力を統合することで、1つのLLMの出力よりも優れた出力を開発することを目指しています。 評価には、MixInstructというベンチマークデータセットが提供されており、Oracleペアワイズ比較を組み合わせ、さまざまな指示データセットを組み合わせています。このデータセットでは、11の人気のあるオープンソースLLMを使用して、各入力に対して複数の候補を生成し、さまざまな指示に従うタスクを実行します。自動評価のためにOracle比較が使用されており、候補出力に対するグランドトゥルースランキングが与えられているため、LLM-BLENDERや他のベンチマーク技術のパフォーマンスを評価することができます。 実験結果は、LLM-BLENDERが個別のLLMやベースライン技術よりも優れたパフォーマンスを発揮することを示しています。LLM-BLENDERのアンサンブル手法を使用することで、単一のLLMやベースライン方法を使用する場合と比較して、より高品質な出力が得られることが示されています。PAIRRANKERの選択は、参照ベースのメトリックやGPT-Rankにおいて、個別のLLMモデルを上回っています。GENFUSERは、PAIRRANKERのトップピックを利用して、効率的な融合を通じて応答品質を大幅に改善しています。 LLM-BLENDERは、Vicunaなどの個別のLLMを上回り、アンサンブル学習を通じてLLMの展開と研究を改善する可能性を示しています。

SalesForceのAI研究者が、マスク不要のOVISを紹介:オープンボキャブラリーインスタンスセグメンテーションマスクジェネレータ
インスタンスセグメンテーションは、複数のオブジェクトを同じクラスに属するものとして、それらを異なるエンティティとして識別するコンピュータビジョンのタスクを指します。深層学習技術の急速な進歩により、過去数年間でセグメンテーション技術のインスタンス数が著しく増加しています。たとえば、畳み込みニューラルネットワーク(CNN)やMask R-CNNなどの先進的なアーキテクチャを使用してインスタンスセグメンテーションが行われます。このような技術の主要な特徴は、オブジェクト検出機能とピクセル単位のセグメンテーションを組み合わせることにより、画像内の各インスタンスに対して正確なマスクを生成し、全体像をより良く理解することができることです。 しかし、既存の検出モデルには、識別できる基本カテゴリの数に関するある種の欠点があります。以前の試行では、COCOデータセットでトレーニングされた検出モデルは、約80のカテゴリを検出する能力を獲得できることが示されています。しかし、追加のカテゴリを識別するには、労力と時間がかかります。これに対処するために、Open Vocabulary(OV)メソッドが存在し、画像とキャプションのペアとビジョン言語モデルを活用して新しいカテゴリを学習します。しかし、基本カテゴリと新しいカテゴリを学習するときの監督には大きな違いがあります。これは、基本カテゴリに過剰適合し、新しいカテゴリに対して一般化が不十分になることが多いためです。そのため、人間の介入がほとんど必要なく新しいカテゴリを検出する方法が必要です。これにより、モデルは現実世界のアプリケーションにとってより実用的でスケーラブルになります。 この問題に対処するため、Salesforce AIの研究者は、画像キャプションペアからバウンディングボックスとインスタンスマスク注釈を生成する方法を考案しました。彼らの提案された方法、Mask-free OVISパイプラインは、擬似マスク注釈を使用して、ビジョン言語モデルから派生した弱い監督を利用することで、基本的なカテゴリと新しいカテゴリを学習します。このアプローチにより、労力を要する人間の注釈が不要になり、過剰適合の問題が解決されます。実験的評価により、彼らの方法論が既存の最先端のオープンボキャブラリーインスタンスセグメンテーションモデルを超えることが示されました。さらに、彼らの研究は、2023年の著名なコンピュータビジョンとパターン認識会議で認められ、受け入れられました。 Salesforceの研究者は、擬似マスクの生成とオープンボキャブラリーインスタンスセグメンテーションの2つの主要なステージで構成されるパイプラインを考案しました。最初のステージでは、画像キャプションペアから対象物の擬似マスク注釈を作成します。事前にトレーニングされたビジョン言語モデルを利用して、オブジェクトの名前がテキストプロンプトとして機能し、オブジェクトをローカライズします。さらに、GradCAMを使用して反復的なマスキングプロセスを実行し、擬似マスクを精度良くオブジェクト全体にカバーするようにします。2番目のステージでは、以前生成されたバウンディングボックスを使用して、GradCAMアクティベーションマップと最も重なりが高い提案を選択するために、弱く監督されたセグメンテーション(WSS)ネットワークがトレーニングされます。最後に、生成された擬似注釈を使用してMask-RCNNモデルがトレーニングされ、パイプラインが完了します。 このパイプラインは、事前にトレーニングされたビジョン言語モデルと弱い監督モデルの力を利用して、追加のトレーニングデータとして使用できる擬似マスク注釈を自動生成することにより、人間の介入が不要になります。研究者たちは、MS-COCOやOpenImagesなどの人気のあるデータセットでいくつかの実験を行い、彼らのアプローチに擬似注釈を使用することで、検出およびインスタンスセグメンテーションのタスクで優れた性能を発揮することが示されました。Salesforceの研究者による独自のビジョン言語ガイドアプローチによる擬似注釈生成は、人間の注釈者を必要としないより高度で正確なインスタンスセグメンテーションモデルの誕生の道を開きます。

巨大なデータベース内のデータ検索を加速する新しい手法
研究者たちは、データベースの重要なコンポーネントであるハッシュ関数をより高速かつ効率的に構築するために、機械学習を使用しました
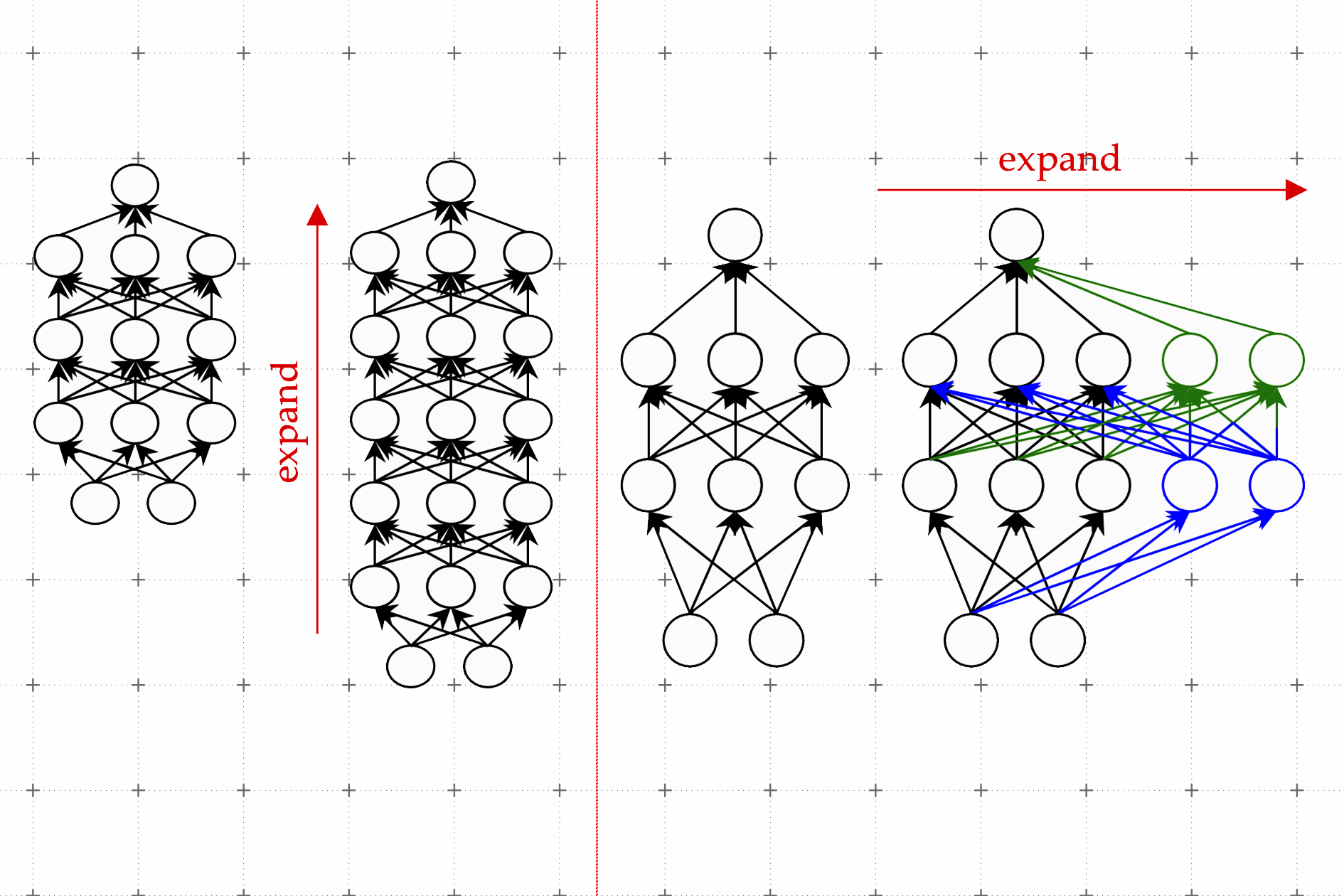
機械学習モデルを成長させる方法の学習
新しいLiGO技術により、大規模な機械学習モデルのトレーニングを加速し、AIアプリケーションの開発にかかる費用と環境負荷を削減します

ChatGPT 4 API、Google Meet、Google Drive&Docs APIを使用した会議議事録生成
この技術記事では、Google Meet、Google Drive、およびGoogle Docs APIとChatGPT 4 APIを活用して、ミーティング議事録を自動生成する方法について調べます議事録を取ること...

Google フォトのマジックエディター:写真を再構築するための新しいAI編集機能
Magic Editorは、AIを使用して写真を再構想するのを手助けする実験的な編集体験です今年後半には、選択されたPixel電話での早期アクセスが計画されています
欠陥が明らかにされる:MLOpsコース作成の興味深い現実
不完全なものが明らかにされる舞台裏バッチ特徴ストアMLパイプラインMLプラットフォームPythonGCPGitHub ActionsAirflowMLOpsCI/CDコース

特定のデータロールに適したプログラミング言語
特定のデータロールに必要なプログラミング言語は何ですか?

Gorillaに会ってください:UCバークレーとMicrosoftのAPI拡張LLMは、GPT-4、Chat-GPT、およびClaudeを上回ります
モデルは、Torch Hub、TensorFlow Hub、およびHuggingFaceからのAPIによって拡張されています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.