Learn more about Search Results 写真 - Page 166

- You may be interested
- 「浙江大学の研究者がUrbanGIRAFFEを提案...
- OpenAIはGPT-4 Turboを発表:カスタマイズ...
- 「DeepMindによるこのAI研究は、シンプル...
- マイクロソフトの研究者がPromptTTS 2を発...
- 「コンテキストに基づくドキュメント検索...
- 「LangchainとOpenAIを使用したGoogleドキ...
- アラゴンAIレビュー:2023年における究極...
- 「Pythia 詳細な研究のための16個のLLMス...
- Google at ACL 2023′ ACL 2023にお...
- ジェネラティブAI時代におけるデータキャ...
- 2023年に検討すべきトップのAutoMLフレー...
- 合成データプラットフォーム:構造化デー...
- 「速さの中で:NVIDIAがオムニバースクラ...
- 「Matplotlibを使用してリップスティック...
- 複数モードモデルとは何ですか?
PyTorchモデルのパフォーマンス分析と最適化—Part2
これは、GPU上で実行されるPyTorchモデルの分析と最適化に関する一連の投稿の第二部です最初の投稿では、プロセスとその重要な可能性を示しました...

中国における大量生産自動運転の課題
自律走行は、世界でも最も困難な運転の一つが既に存在する中国では、特に難しい課題です主に3つの要因が関係しています:動的...

SRGANs:低解像度と高解像度画像のギャップを埋める
イントロダクション あなたが古い家族の写真アルバムをほこりっぽい屋根裏部屋で見つけるシナリオを想像してください。あなたはすぐにほこりを取り、最も興奮してページをめくるでしょう。そして、多くの年月前の写真を見つけました。しかし、それでも、あなたは幸せではないです。なぜなら、写真が薄く、ぼやけているからです。写真の顔や細部を見つけるために目をこらします。これは昔のシナリオです。現代の新しいテクノロジーのおかげで、私たちはスーパーレゾリューション・ジェネレーティブ・アドバーサリ・ネットワーク(SRGAN)を使用して、低解像度の画像を高解像度の画像に変換することができます。この記事では、私たちはSRGANについて最も学び、QRコードの強化のために実装します。 出典: Vecteezy 学習目標 この記事では、以下のことを学びます: スーパーレゾリューションと通常のズームとの違いについて スーパーレゾリューションのアプローチとそのタイプについて SRGAN、その損失関数、アーキテクチャ、およびそのアプリケーションについて深く掘り下げる SRGANを使用したQRエンハンスメントの実装とその詳細な説明 この記事は、データサイエンスブログマラソンの一環として公開されました。 スーパーレゾリューションとは何ですか? 多くの犯罪捜査映画では、証拠を求めて探偵がCCTV映像をチェックする典型的なシナリオがよくあります。そして、ぼやけた小さな画像を見つけて、ズームして強化してはっきりした画像を得るシーンがあります。それは可能ですか?はい、スーパーレゾリューションの助けを借りて、それはできます。スーパーレゾリューション技術は、CCTVカメラによってキャプチャされたぼやけた画像を強化し、より詳細な視覚効果を提供することができます。 ………………………………………………………………………………………………………………………………………………………….. ………………………………………………………………………………………………………………………………………………………….. 画像の拡大と強化のプロセスをスーパーレゾリューションと呼びます。それは、対応する低解像度の入力から画像またはビデオの高解像度バージョンを生成することを目的としています。それによって、欠落している詳細を回復し、鮮明さを向上させ、視覚的品質を向上させることができます。強化せずに画像をズームインするだけでは、以下の画像のようにぼやけた画像が得られます。強化はスーパーレゾリューションによって実現されます。写真、監視システム、医療画像、衛星画像など、さまざまな領域で多くの応用があります。 ……….. スーパーレゾリューションの従来のアプローチ 従来のアプローチでは、欠落しているピクセル値を推定し、画像の解像度を向上させることに重点を置いています。2つのアプローチがあります。補間ベースの方法と正則化ベースの方法です。 補間ベースの方法 スーパーレゾリューションの初期の日々には、補間ベースの方法に重点が置かれ、欠落しているピクセル値を推定し、その後画像を拡大します。隣接するピクセル値が類似しているという仮定を使用して、これらの値を使用して欠落している値を推定します。最も一般的に使用される補間方法には、バイキュービック、バイリニア、および最近傍補間があります。しかし、その結果は満足できないものでした。これにより、ぼやけた画像が生じました。これらの方法は、基本的な解像度タスクや計算リソースに制限がある状況に適しているため、効率的に計算できます。 正則化ベースの手法 一方で、正則化ベースの手法は、画像再構成プロセスに追加の制約や先行条件を導入することで、超解像度の結果を改善することを目的としています。これらの技術は、画像の統計的特徴を利用して、再構築された画像の精度を向上させながら、細部を保存します。これにより、再構築プロセスにより多くの制御が可能になり、画像の鮮明度と細部が向上します。しかし、複雑な画像コンテンツを扱う場合には、過度の平滑化を引き起こすため、いくつかの制限があります。 これらの従来のアプローチにはいくつかの制限があるにもかかわらず、超解像度の強力な手法の出現への道を示しました。…

オッターに会いましょう:大規模データセット「MIMIC-IT」を活用した最先端のAIモデルであり、知覚と推論のベンチマークにおいて最新の性能を実現しています
マルチファセットモデルは、書かれた言語、写真、動画などの様々なソースからのデータを統合し、さまざまな機能を実行することを目指しています。これらのモデルは、視覚とテキストデータを融合させたコンテンツを理解し、生成することにおいて、かなりの可能性を示しています。 マルチファセットモデルの重要な構成要素は、ナチュラルランゲージの指示に基づいてモデルを微調整する指示チューニングです。これにより、モデルはユーザーの意図をより良く理解し、正確で適切な応答を生成することができます。指示チューニングは、GPT-2やGPT-3のような大規模言語モデル(LLMs)で効果的に使用され、実世界のタスクを達成するための指示に従うことができるようになりました。 マルチモーダルモデルの既存のアプローチは、システムデザインとエンドツーエンドのトレーニング可能なモデルの観点から分類することができます。システムデザインの観点では、ChatGPTのようなディスパッチスケジューラを使用して異なるモデルを接続しますが、トレーニングの柔軟性が欠けているため、コストがかかる可能性があります。エンドツーエンドのトレーニング可能なモデルの観点では、他のモダリティからモデルを統合しますが、トレーニングコストが高く、柔軟性が制限される可能性があります。以前のマルチモーダルモデルにおける指示チューニングのデータセットには、文脈に沿った例が欠けています。最近、シンガポールの研究チームが提案した新しいアプローチは、文脈に沿った指示チューニングを導入し、このギャップを埋めるための文脈を持つデータセットを構築しています。 この研究の主な貢献は以下の通りです。 マルチモーダルモデルにおける指示チューニングのためのMIMIC-ITデータセットの導入。 改良された指示に従う能力と文脈的学習能力を持ったオッターモデルの開発。 より使いやすいOpenFlamingoの最適化実装。 これらの貢献により、研究者には貴重なデータセット、改良されたモデル、そしてより使いやすいフレームワークが提供され、マルチモーダル研究を進めるための貴重な資源となっています。 具体的には、著者らはMIMIC-ITデータセットを導入し、OpenFlamingoの文脈的学習能力を維持しながら、指示理解能力を強化することを目的としています。データセットには、文脈的関係を持つ画像とテキストのペアが含まれており、OpenFlamingoは文脈的例に基づいてクエリされた画像-テキストペアのテキストを生成することを目指しています。MIMIC-ITデータセットは、OpenFlamingoの指示理解力を向上させながら、文脈的学習を維持するために導入されました。これには、画像-指示-回答の三つ組と対応する文脈が含まれます。OpenFlamingoは、画像と文脈的例に基づいてテキストを生成するためのフレームワークです。 トレーニング中、オッターモデルはOpenFlamingoのパラダイムに従い、事前学習済みのエンコーダーを凍結し、特定のモジュールを微調整しています。トレーニングデータは、画像、ユーザー指示、GPTによって生成された回答、および[endofchunk]トークンを含む特定の形式に従います。モデルは、クロスエントロピー損失を使用してトレーニングされます。著者らは、Please view this post in your web browser to complete the quiz.トークンで予測目標を区切ることにより、トレーニングデータを分離しています。 著者らは、OtterをHugging Face Transformersに統合し、研究者がモデルを最小限の努力で利用できるようにしました。彼らは、4×RTX-3090…

このGoogleのAI論文は、さまざまなデバイスで大規模な拡散モデルを実行するために画期的なレイテンシー数値を集めるための一連の最適化を提示しています
モデルのサイズと推論ワークロードは、画像生成のための大規模な拡散モデルが一般的になったために急激に増加しています。リソースの限界により、モバイルコンテキストにおけるオンデバイスML推論のパフォーマンス最適化はデリケートなバランスアクトです。これらのモデルのかなりのメモリ要件と計算要件のため、デバイス上で大規模な拡散モデル(LDM)の推論を実行することは、コスト効率とユーザープライバシーの必要性を考慮すると、さらに大きな障壁を生じます。 基礎モデルの迅速な作成と広範な使用は、人工知能を完全に変革しました。その多様性と写真のようなリアルな画像を生成する能力から、大規模な拡散モデルは多くの注目を集めています。サーバーコストの削減、オフライン機能、強化されたユーザープライバシーは、これらのモデルをユーザーのデバイスにローカルに展開することの利点の一部にすぎません。デバイス上の計算およびメモリリソースの制限により、典型的な大規模な拡散モデルには10億以上のパラメータがあり、困難が生じます。 Googleの研究者たちは、モバイルデバイスにおけるGPUを使用した最速の推論レイテンシを可能にする大規模な拡散モデルの実装の一連の変更を提供しています。これらの更新により、さまざまなデバイスで全体的なユーザーエクスペリエンスが向上し、生成AIの利用範囲が拡大します。 低レイテンシ、強化されたプライバシー、大規模なスケーラビリティなど、サーバーベースの方法に比べて多くの利点を持つオンデバイスモデル推論アクセラレーションは、最近注目を集めています。深層学習で頻繁に使用されるsoftmax演算の複雑さは、さまざまな加速戦略を生み出す動機となっています。ウィノグラード畳み込みは、必要な乗算の数を最小限に抑えることにより、畳み込み計算の効率を向上させるために開発されました。これは、グラフィックス処理ユニット(GPU)にとって特に役立ちます。 Transformerデザインの広範な成功と採用は、注意メカニズムの高速化に関する研究を引き起こしました。 Reformerは、計算コストを削減するために疎な近似を使用し、他の作品は低ランクまたは近似テクニックの組み合わせを使用しています。 FlashAttentionは、ハードウェア構成を考慮した正確な注意アルゴリズムであり、より良いパフォーマンスを実現するために使用されます。 主な焦点は、大規模な拡散モデルを使用して書かれた説明からビジュアルを作成するという課題にあります。提案された改善内容がStable Diffusionアーキテクチャとどのように機能するかに焦点が当てられているにもかかわらず、これらの最適化は他の大規模な拡散モデルにも簡単に転送できることは重要です。テキストからの推論は、逆拡散プロセスを誘導するために、望ましいテキストの説明に基づく追加の調整が必要です。 LDMのノイズリダクションモデルで広く使用される注意ブロックは、改善の主要な領域を示しています。モデルは、入力に注意ブロックの重みをより与えることで、関連する情報に絞り込むことができます。注意モジュールは、複数の方法で最適化することができます。以下に詳細を記載された2つの最適化のうち、どちらが最良の結果をもたらすかに応じて、研究者は通常1つだけを利用します。 最初の最適化である部分的に融合されたsoftmaxは、行列の乗算と統合することにより、注意モジュールのsoftmax中に読み取られ、書き込まれるメモリ量を減らします。もう1つの微調整では、I/Oに配慮した正確な注意方法であるFlashAttentionを使用します。 GPUからの高帯域幅メモリアクセスの数を減らすことで、メモリ帯域幅の制限があるアプリケーションには優れた選択肢です。多数のレジスタが必要であり、彼らは、この方法が特定のサイズのSRAMに対してのみ機能することを発見しました。したがって、彼らは特定のサイズの注意行列に対して、一部のGPUでのみこの方法を使用します。 さらに、チームは、LDMの一般的に使用されるレイヤーやユニットの融合ウィンドウが、商用GPUアクセラレートML推論エンジンで現在使用可能なものよりもはるかに大きくなければならないことが判明しました。標準的な融合ルールの制限を考慮して、彼らは、より幅広い種類のニューラルオペレータを実行できるカスタム実装を考案しました。彼らの注意は、ガウス誤差線形ユニット(GELU)とグループ正規化層の2つのサブフィールドに向けられました。 モデルファイルサイズの制限、大量のランタイムメモリ要件、および長時間の推論レイテンシは、デバイス自体での大規模なモデルのML推論を行う際の重要な障害となっています。研究者は、メモリ帯域幅の使用が主要な制約であることを認識しました。したがって、ALU /メモリ効率比を健全に保ちながら、メモリ帯域幅の利用を改善することに焦点を当てました。彼らが実証した最適化は、記録的なレイテンシ値を持つさまざまなデバイスで大規模な拡散モデルを実行することを可能にしました。これらの改善により、モデルの適用範囲が拡大し、幅広いデバイスでユーザーエクスペリエンスが向上しました。

研究者たちは、画像内の似たような材料を特定するためにAIを使用しています
この機械学習の手法は、ロボットのシーン理解、画像編集、オンライン推薦システムに役立つことができます
ChatGPT:ウェブデザイナーの視点
もし最新のニュースやトレンドについて常にアップデートしているのであれば、おそらく「ChatGPT」という言葉とその成功について耳にしたことがあるでしょう簡単に言えば、ChatGPTとは人工知能のことです

新しい方法:AIによって地図がより没入感あるものになる
AIの進歩により、マップで経路を理解する新しい方法がありますさらに、開発者向けの新しい没入型ツールもあります

I/O 2023 で発表した100のこと
Google I/O 2023はニュースとローンチで満ち溢れていましたここではI/Oで発表された100のことを紹介します
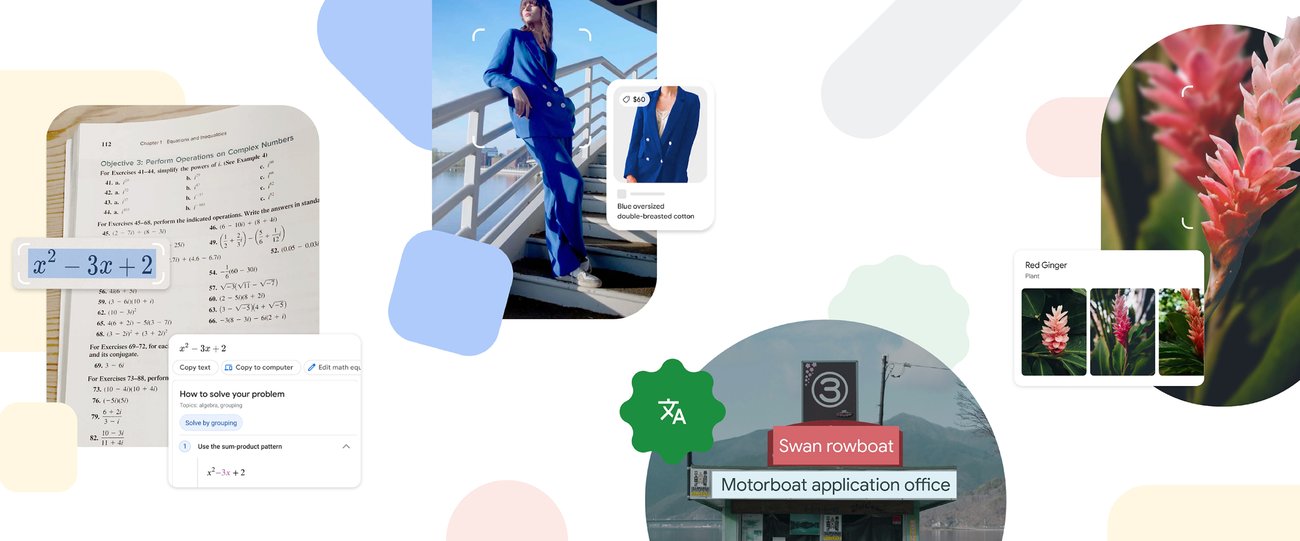
8つの方法でGoogleレンズがあなたの生活をより簡単にする方法
Google Lensは、見たものを検索して周りの世界を探索することが簡単になりますそれには、肌の状態を検索する新機能も含まれています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.