Learn more about Search Results EU - Page 160

- You may be interested
- 「マイクロソフトのこのAI論文では、生物...
- 「インクリメンタルラーニング:メリット...
- LLM黙示録:オープンソースクローンの復讐
- 「生成AI解放:ソフトウェアエンジニアの...
- 「自己教師あり学習とトランスフォーマー...
- 「データの必要量はどのくらいですか? 機...
- データの可視化 複雑な情報を効果的に提示...
- 「MITとハーバードの研究者が提案する(FAn...
- 新興スタートアップにとってのAIカンファ...
- 高度なPython:メタクラス
- 線形代数の鳥瞰図:地図の尺度—行列式
- Graph RAG LLMによるナレッジグラフのパワ...
- 「条件付き確率とベイズの定理をシンプル...
- Googleの研究者が新たな大規模言語モデル...
- パーソナライズされたA.I.エージェントが...

FastAPI、AWS Lambda、およびAWS CDKを使用して、大規模言語モデルのサーバーレスML推論エンドポイントを展開します
データサイエンティストにとって、機械学習(ML)モデルを概念実証から本番環境へ移行することは、しばしば大きな課題を提供します主な課題の一つは、良好なパフォーマンスを発揮するローカルトレーニング済みモデルをクラウドに展開して、他のアプリケーションで使用することですこのプロセスを管理することは手間がかかる場合がありますが、適切なツールを使用することで、...
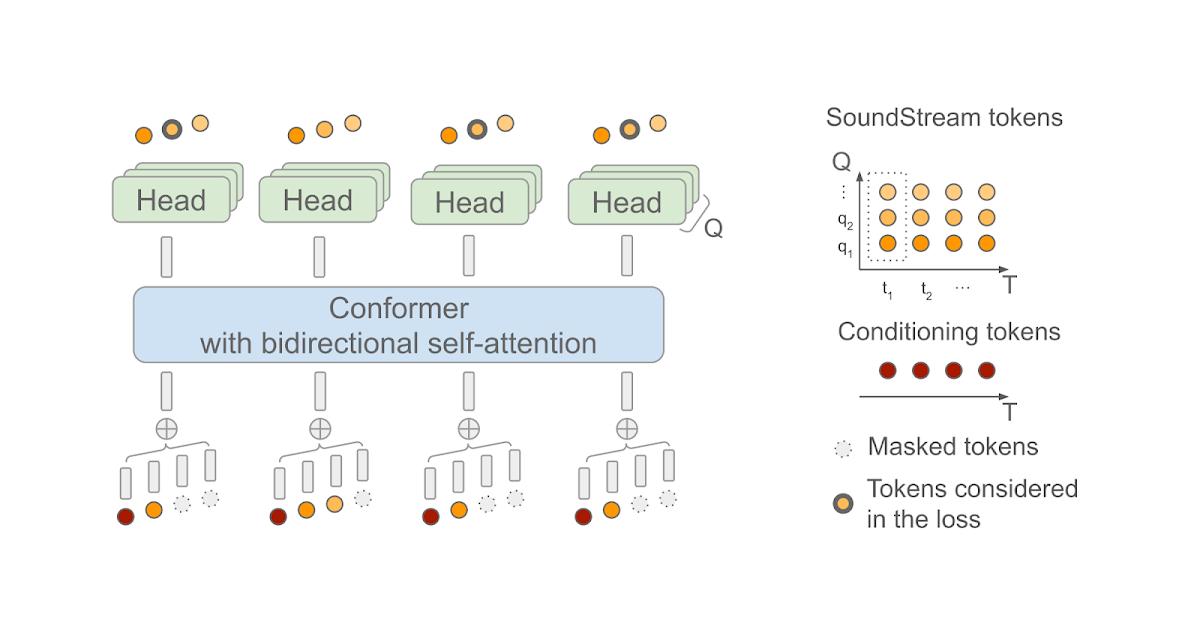
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。 最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。 この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 入力:オーディオプロンプト 出力:オーディオプロンプト+生成されたオーディオ SoundStormの設計 以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。 SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。 推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq…
線形回帰の理論的な深堀り
多くのデータサイエンス志望のブロガーが行うことがあります 線形回帰に関する入門的な記事を書くことですこれは、この分野に入る際に最初に学ぶモデルの1つであるため、自然な選択肢です...
Pythonの依存関係管理:どのツールを選ぶべきですか?
あなたのデータサイエンスプロジェクトが拡大するにつれて、依存関係の数も増えますプロジェクトの環境を再現可能かつメンテナンス可能に保つために、効率的な依存関係を使用することが重要です...

GPTとBERT:どちらが優れているのか?
生成AIの人気の高まりに伴い、大規模言語モデルの数も増加していますこの記事では、GPTとBERTの2つのモデルを比較しますGPT(Generative...

BITEとは 1枚の画像から立ち姿や寝そべりのようなポーズなど、困難なポーズでも3D犬の形状とポーズを再構築する新しい手法
生物学や保全、エンターテインメントや仮想コンテンツの開発など、多くの分野で3D動物の形状や態度を捕捉してモデリングすることは有益です。動物を静止させたり、特定の姿勢を維持したり、観察者と物理的接触をしたり、協力的な何かをする必要はないため、カメラは動物を観察するための自然なセンサーです。Muybridge氏による有名な「馬の運動」の連続写真のように、写真を使用して動物を研究する歴史は長いです。しかし、以前の3D人間の形状や態度に関する研究とは異なり、最近では動物の独特な形状と位置に変化できる表現豊かな3Dモデルが開発されています。ここでは、単一の写真から3D犬再構築の課題に焦点を当てます。 犬は、四肢のような関節の変形が強く、品種間の広い形状変化があるため、モデル種として選ばれます。犬は定期的にカメラに捉えられます。したがって、様々な姿勢、形状、および状況が簡単に利用できます。人と犬をモデリングすることには同様の困難があるかもしれませんが、それらは非常に異なる技術的障壁を持っています。多くの3Dスキャンとモーションキャプチャデータがすでに利用可能であり、SMPLやGHUMのような堅牢な関節モデルを学習することが可能になっています。 それに対して、動物の3D観察を収集することは困難であり、現在は、すべての想定される形状と位置を考慮に入れた同様に表現豊かな3D統計モデルを学習するためにより多くのデータが必要です。SMALは、おもちゃのフィギュアから学習された、四足動物のパラメトリックモデルであり、犬を含む動物を写真から3Dで再現することが現在可能になりました。しかし、SMALは、猫からカバまで多くの種に対して一般的なモデルであり、さまざまな動物の多様な体型を描写できますが、大きな耳の範囲などの犬の品種の独特で微細な詳細を描写することはできません。この問題を解決するために、ETH Zurich、Max Planck Institute for Intelligent Systems、Germany、IMATI-CNR、Italyの研究者たちは、正しく犬を表現する最初のD-SMALパラメトリックモデルを提供しています。 また、人と比較して、犬は比較的少量のモーションキャプチャデータしか持っておらず、そのデータのうち座ったり寝そべったりする姿勢はめったにキャプチャされません。そのため、現在のアルゴリズムでは、特定の姿勢で犬を推測することが困難です。たとえば、歴史的データから3Dポーズの事前に学習すると、立ち上がったり歩いたりする姿勢に偏ってしまいます。一般的な制約を使用することで、この事前情報を弱めることができますが、ポーズの推定は非常に未解決となります。この問題を解決するために、彼らは、(地形)動物をモデリングする際に見落とされていた物理的タッチに関する情報を利用しています。つまり、重力の影響を受けるため、地面に立ったり、座ったり、寝転がったりすることができます。 複雑な自己遮蔽のある困難な状況では、彼らは地面接触情報を使用して複雑な犬のポーズを推定する方法を示しています。人間のポーズ推定において地面面制限が使用されてきましたが、四足動物にとっては潜在的な利点が大きいです。四本足は、より多くの地面接触点、座ったり寝そべったりしたときにより多くの体部位が隠れ、より大きな非剛体変形を示唆しています。以前の研究のもう一つの欠点は、再構築パイプラインがしばしば2D画像で訓練されていることです。対応する2D画像と共に3Dデータを収集することは困難です。そのため、再投影すると視覚的証拠に近くなりますが、視野方向に沿って歪んでいる位置や形状を予測することがあります。 異なる角度から見ると、3D再構築が誤った場合があります。対応するデータがないため、遠くまたは隠れた体の部分をどこに配置すべきかを決定するための十分な情報がないためです。彼らは再び、地面接触のシミュレーションが有益であることを発見しました。結合された2Dと3Dデータを手動で再構築(または合成)する代わりに、より緩い3D監視方法に切り替えて、地面接触ラベルを取得します。アノテーターには、犬の下の地面が平らかどうかを指示し、平らである場合は3D動物の地面接触点を追加で注釈するように求めます。これは、アノテーターに実際の写真を提示することで実現されます。 図1 は、BITEが単一の入力画像から犬の3D形状と姿勢を推定できるようになったことを示しています。このモデルは、様々な品種やタイプ、そして訓練ポーズの範囲外である困難なポーズ、たとえば地面に座ったり寝そべったりすることができます。 彼らは、単一の画像から表面を分類し、接点をかなり正確に検出するようにネットワークを教育できることがわかりました。これらのラベルはトレーニングだけでなく、テスト時にも使用できます。最新の最先端モデルであるBARCに基づいて、再構築システムはBITEと呼ばれています。彼らは、新しいD-SMAL犬モデルを初期の荒い適合ステップとして使用してBARCを再トレーニングします。その後、結果の予測を最近作成したリファインメントネットワークに送信し、接地損失を使用してカメラの設定と犬のスタンスの両方を改善するためにトレーニングします。テスト時にも接地損失を使用して、テスト画像に完全に自律的に適合を最適化することができます(図1を参照)。これにより、再構築の品質が大幅に向上します。BARCポーズ事前に対するトレーニングセットにそのようなポーズが含まれていなくても、BITEを使用して(局所的に平面的な)地面に正しく立つ犬を取得したり、座ったり横たわったりといった姿勢で現実的に再構築したりすることができます。3D犬再構築に関する先行研究は、主観的な視覚評価または写真に戻って2D残差を評価することによって評価されており、深度に関連する不正確さを投影しています。彼らは、客観的な3D評価の欠如を克服するために、実際の犬をさまざまな視点から3Dスキャンして、3D真実値を持つ半合成データセットを開発しました。彼らは、この新しいデータセットを使用して、BITEとその主要な競合他社を評価し、BITEがこの分野の新しい標準を確立することを示しています。 彼らの貢献の要約は以下の通りです: 1. SMALから開発された、新しい、犬種固有の3DポストureおよびフォームモデルであるD-SMALを提供します。 2.同時に地面の局所平面を評価するためのニューラルモデルであるBITEを作成します。BITEは、信じられる地面接触を促進します。 3.モデルを使用する前に、(必然的に小さい)先行モデルでエンコードされたものとは非常に異なる犬の位置を回復することが可能であることを示します。 4. StanfordExtraデータセットを使用して、単眼カメラによる3Dポストure推定の最先端を改善します。 5.実際の犬のスキャンに基づく半合成3Dテストコレクションを提供し、真の3D評価への移行を促進します。

メリーランド大学カレッジパーク校の新しいAI研究では、人間の目の反射から3Dシーンを再構成することができるAIシステムが開発されました
人間の目は素晴らしい器官であり、視覚を可能にし、重要な環境データを保管することができます。通常、目は2つのレンズとして使用され、光をその網膜を構成する感光細胞に向けて誘導します。しかし、他人の目を見ると、角膜から反射された光も見ることができます。カメラを使用して他人の目を写真に撮ると、イメージングシステム内の一対のミラーに自分の目を変えます。観察者の網膜に届く光と彼らの目から反射する光は同じ源から来るため、彼らのカメラは観察している環境に関する詳細を含む写真を提供するはずです。 以前の実験では、2つの目の画像が、観察者が見ている世界の全景表現を回復させました。リライト、焦点オブジェクトの推定、グリップ位置の検出、個人認識などのアプリケーションは、後続の調査でさらに研究されています。現在の3Dビジョンとグラフィックスの開発により、単一の全景環境マップを再構築するだけでなく、観察者の現実を3次元で復元できるかどうか熟考しています。頭が自然に動くと、目が複数のビューから情報をキャプチャし、反映することを知っています。 メリーランド大学の研究者たちは、過去の画期的な業績と最新のニューラルレンダリングの最新の進歩を融合させた、観察者の環境の3D再構築のための全く新しい技術を提供しています。彼らの方法は、静止したカメラを使用し、目の画像からマルチビューの手掛かりを抽出します。通常のNeRFキャプチャセットアップでは、マルチビュー情報を取得するために移動カメラが必要です(しばしばカメラ位置の推定に続きます)。概念的には単純ですが、実際には、目の画像から3D NeRFを再構築することは困難です。最初の困難は、ソース分離です。彼らは、人間の目の複雑な虹彩のテクスチャと反射を区別する必要があります。 これらの複雑なパターンにより、3D再構築プロセスが不明瞭になります。通常、正常なキャプチャでは、場面のクリーンな写真に対して、虹彩のテクスチャが混在することはありません。この構成により、再構築技術はより困難になり、ピクセルの相関が崩れます。角膜のポーズの推定は、2つ目の困難を提示します。画像観察から正確に位置を特定することが困難であり、小さく、難解な目です。ただし、それらの位置と3D方向の正確さは、マルチビュー再構築にとって重要です。 これらの困難を克服するために、この研究の著者は、虹彩テクスチャを全体的な輝度場から区別しやすくするために、2つの重要な要素を追加して、目の画像でNeRFをトレーニングするためにNeRFを再利用しました。短い放射線を使用したテクスチャ分解(a)およびアイポーズの微調整(b)です。彼らは、現実的なテクスチャを持つ人工的な角膜から反射をキャプチャする写真で複雑な屋内環境の合成データセットを作成して、彼らの技術のパフォーマンスと効果を評価します。彼らはまた、いくつかのアイテムで実際に収集された人工および実際の眼球画像の研究を行い、彼らの方法論のいくつかの設計決定を支援します。 これらが彼らの主な貢献です。 •彼らは、過去の画期的な業績と最新のニューラルレンダリングの最新の進歩を融合させた、観察者の環境の3D再構築のための全く新しい技術を提供しています。 •彼らは、目の画像で虹彩テクスチャを分解するための放射状事前分布を導入することで、再構築された輝度場の品質を大幅に向上させています。 •彼らは、アイボールのノイズのあるポーズ推定を減らす角膜ポーズの微調整プロセスを開発することにより、人間の目から特徴を収集する特別な問題を解決しています。 これらの進展により、視線外の3Dシーンを明らかにし、キャプチャするためのアクシデンタルイメージングの広い範囲で研究・開発の新しい機会が生まれました。彼らのウェブサイトには、彼らの開発を実証するいくつかのビデオがあります。 図1は、目の反射を使用して放射輝度場を再構築することを示しています。人間の目は非常に反射します。被写体の目の反射だけを使用して、移動する頭を記録する一連のフレームから彼らが見ている3Dシーンを再構築して表示することができることを示しています。

ChatGPTの哲学コース:このAI研究は、対話エージェントのLLMの振る舞いを探究します
2023年はLLMの年です。ChatGPT、GPT-4、LLaMAなど、新しいLLMモデルが続々と注目を集めています。これらのモデルは自然言語処理の分野を革新し、さまざまなドメインで増え続ける利用に遭遇しています。 LLMには、対話を行うなど、人間のような対話者との魅力的な幻想を生み出す幅広い行動を示す驚くべき能力があります。ただし、LLMベースの対話エージェントは、いくつかの点で人間とは大きく異なることを認識することが重要です。 私たちの言語スキルは、世界との具体的なやり取りを通じて発達します。私たちは個人として、社会化や言語使用者のコミュニティでの浸透を通じて認知能力や言語能力を獲得します。このプロセスは赤ちゃんの場合はより早く、成長するにつれて学習プロセスは遅くなりますが、基礎は同じです。 一方、LLMは、与えられた文脈に基づいて次の単語またはトークンを予測することを主な目的とした、膨大な量の人間が生成したテキストで訓練された非具体的なニューラルネットワークです。彼らのトレーニングは、物理的な世界の直接的な経験ではなく、言語データから統計的なパターンを学ぶことに焦点を当てています。 これらの違いにもかかわらず、私たちはLLMを人間らしく模倣する傾向があります。これをチャットボット、アシスタントなどで行います。ただし、このアプローチには難しいジレンマがあります。LLMの行動をどのように説明し理解するか? LLMベースの対話エージェントを説明するために、「知っている」「理解している」「考えている」などの用語を人間と同様に使用することは自然です。ただし、あまりにも文字通りに受け取りすぎると、このような言葉は人工知能システムと人間の類似性を誇張し、その深い違いを隠すことになります。 では、どのようにしてこのジレンマに取り組むことができるでしょうか? AIモデルに対して「理解する」や「知っている」という用語をどのように説明すればよいでしょうか? それでは、Role Play論文に飛び込んでみましょう。 この論文では、効果的にLLMベースの対話エージェントについて考え、話すための代替的な概念的枠組みや比喩を採用することを提案しています。著者は2つの主要な比喩を提唱しています。1つ目の比喩は、対話エージェントを特定のキャラクターを演じるものとして描写するものです。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。 2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。 自己回帰サンプリングの例。出典:https://arxiv.org/pdf/2305.16367.pdf 最初の比喩は、対話エージェントを特定のキャラクターとして演じるものとして描写します。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。 2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。 対話エージェントの交代の例。出典:https://arxiv.org/pdf/2305.16367.pdf このフレームワークを採用することで、研究者やユーザーは、人間にこれらの概念を誤って帰属させることなく、欺瞞や自己認識などの対話エージェントの重要な側面を探求することができます。代わりに、焦点は、役割演技シナリオでの対話エージェントの行動や、彼らが模倣できる様々なキャラクターを理解することに移ります。 結論として、LLMに基づく対話エージェントは人間らしい会話をシミュレートする能力を持っていますが、実際の人間の言語使用者とは大きく異なります。役割プレイヤーやシミュレーションの組み合わせなどの代替的な隠喩を使用することにより、LLMベースの対話システムの複雑なダイナミクスをより理解し、その創造的な可能性を認識しながら、人間との根本的な相違を認識できます。

データサイエンティストとは具体的に何をする人なのでしょうか?
この様々な職務記述の羅列からも明らかなように、データサイエンティストの役割が実際に日々何を含むのかを明確に把握するのは非常に困難であることがあります既存の多くの記事は、...
PatchTST 時系列予測における画期的な技術革新
トランスフォーマーベースのモデルは、自然言語処理の分野(BERTやGPTモデルなど)やコンピュータビジョンなど、多くの分野で成功を収めていますしかし、時間の問題になると...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.