Learn more about Search Results gradio - Page 15

- You may be interested
- アリババは、2つのオープンソースの大規模...
- 「事実かフィクションかを超えて:GPT-4の...
- 「5つの最高のAIインテリアデザインツール...
- ビジネスにおけるオープンソースと専有モ...
- 「Protopia AIによる企業LLMアクセラレー...
- 『ジュリエット・パウエル&アート・ク...
- AIが統合セールスチームにより高速かつ高...
- 生成AIにおける5つの倫理的考慮事項
- 「アレックス・ホルモジ法を用いて、3つの...
- マイクロソフトが「TypeChat」をリリース...
- 「GlotLIDをご紹介します:1665言語に対応...
- 「Amazon SageMaker JumpStartを使用して...
- OpenAIはGPT-3.5 Turboのファインチューニ...
- 「アルテアナのアートスクワッド」が結成...
- Python Webスクレイピングの始め方(LLMs...
1時間以内に初めてのディープラーニングアプリを作成しましょう
私はもう10年近くデータ分析をしています時折、データから洞察を得るために機械学習の技術を使用しており、クラシックな機械学習を使うことにも慣れています

AI WebTVの構築
AI WebTVは、自動ビデオと音楽合成の最新の進歩を紹介するための実験的なデモです。 👉 AI WebTVスペースにアクセスしてストリームを視聴できます。 モバイルデバイスを使用している場合は、Twitchのミラーからストリームを視聴できます。 AI WebTVの目的は、ZeroscopeやMusicGenなどのオープンソースのテキストからビデオを生成するモデルを使用して、エンターテイニングでアクセスしやすい方法でビデオをデモすることです。 これらのオープンソースモデルは、Hugging Faceハブで見つけることができます: ビデオ用: zeroscope_v2_576とzeroscope_v2_XL 音楽用: musicgen-melody 個々のビデオシーケンスは意図的に短く作られており、WebTVは芸術方向性やプログラミングを持つ実際のショーではなく、テックデモ/ショーリールとして見るべきです。 AI WebTVは、ビデオショットのシーケンスを取り、テキストからビデオを生成するモデルに渡してテイクのシーケンスを生成することで動作します。 さらに、人間によって書かれた基本テーマとアイデアは、LLM(この場合はChatGPT)を通じて渡され、各ビデオクリップごとにさまざまな個別のプロンプトを生成するために使用されます。 以下は、AI WebTVの現在のアーキテクチャのダイアグラムです: WebTVはNodeJSとTypeScriptで実装されており、Hugging Faceでホストされているさまざまなサービスを使用しています。 テキストからビデオへのモデル 中心となるビデオモデルはZeroscope…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…

コース開始コミュニティイベント
嬉しいお知らせです。Hugging Faceチームの多くの作業の結果、Hugging Faceコースのパート2が11月15日にリリースされます!パート1では、事前学習済みモデルの使用方法、テキスト分類タスクでの微調整、そして結果のモデルハブへのアップロードを教えることに焦点を当てました。パート2では、他の一般的なNLPタスクに焦点を当てます:トークン分類、言語モデリング(因果関係とマスク)、翻訳、要約、質問応答。また、Hugging Faceエコシステム全体について詳しく説明し、特に🤗データセットと🤗トークナイザーについても詳しく説明します。 このリリースに合わせて、コミュニティイベントを開催しますので、ぜひご参加ください!プログラムには2日間の講演が含まれ、その後、いかなるNLPタスクでもモデルの微調整に焦点を当てたチームプロジェクトが行われ、最後にこのようなライブデモが行われます。もし機械学習の新しい仕事を探している場合は、これらのデモはあなたのポートフォリオにうまく収まります。また、参加者全員には、それらの中から1つを構築することに成功した場合に修了証が送られます。 AWSはこのイベントをスポンサーしており、Amazon SageMakerを介して参加者に無料のコンピューティングを提供しています。 登録するには、このフォームに記入してください。以下に、2日間の講演の詳細をご紹介します。 1日目(11月15日):Transformerの概要とトレーニング方法の高レベルビュー 講演の初日は、Transformerモデルの高レベルなプレゼンテーションと、トレーニングや微調整に使用できるツールに焦点を当てます。 2日目(11月16日):使用するツール 2日目は、Hugging Face、Gradio、AWSチームによる講演に焦点を当て、使用するツールを紹介します。
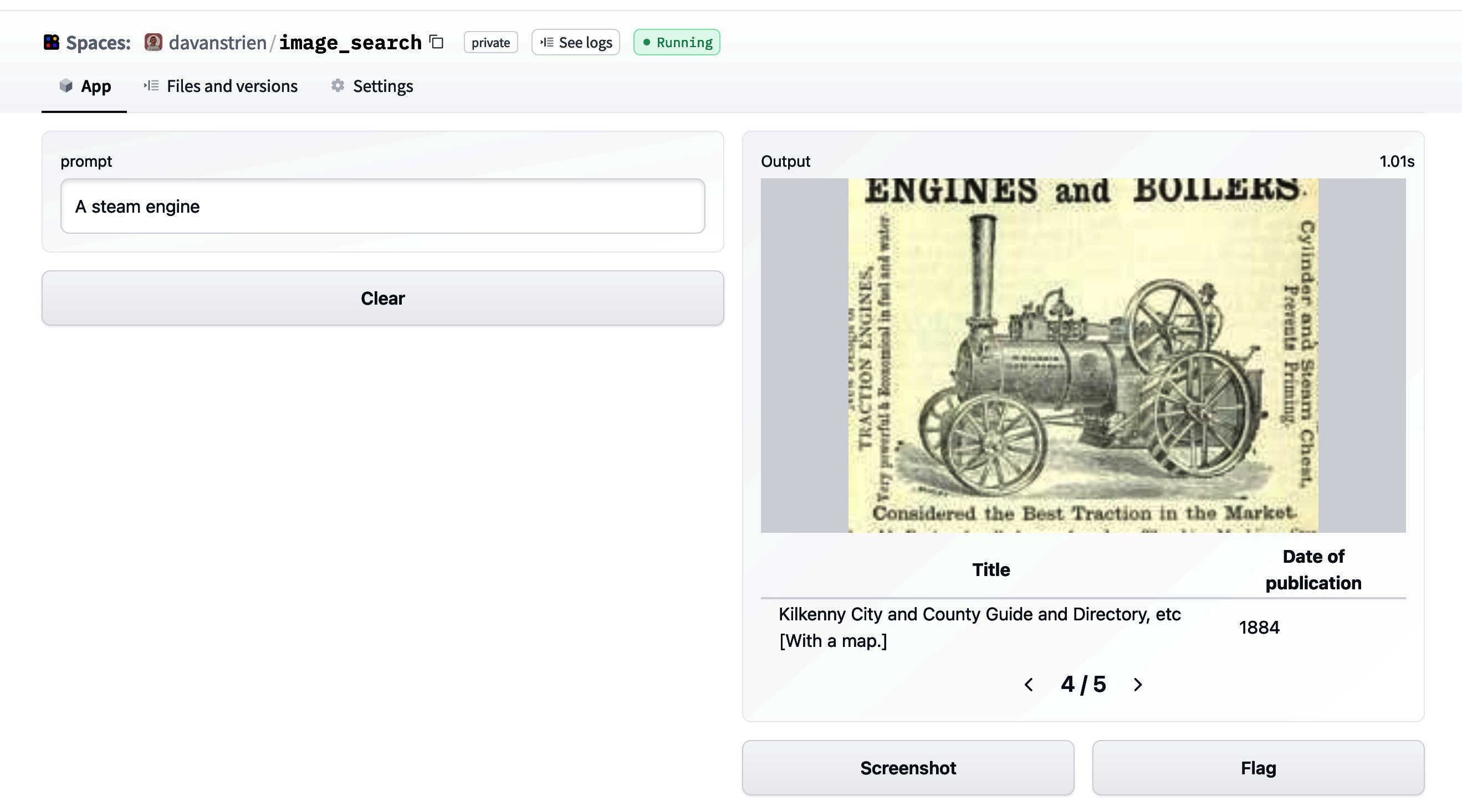
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

教育のためのHugging Faceをご紹介します 🤗
機械学習がソフトウェア開発の圧倒的な割合を占めること、非技術的な人々がますますAIシステムに触れることを考えると、AIの主な課題の1つは従業員のスキルを適応・向上させることです。また、AIの倫理的および重要な問題を積極的に考慮するために教育スタッフをサポートする必要があります。 Hugging Faceは機械学習を民主化するオープンソース企業として、世界中のあらゆるバックグラウンドの人々に教育を提供することが重要だと考えています。 私たちは2022年3月にMLデモクラタイゼーションツアーを開始し、Hugging Faceの専門家が16カ国の1000人以上の学生に対して実践的な機械学習クラスを教えました。新しい目標は、「2023年末までに500万人に機械学習を教える」ことです。 このブログ記事では、教育に関する目標達成方法の概要を提供します。 🤗 すべての人のための教育 🗣️ 私たちの目標は、機械学習の可能性と限界を誰にでも理解してもらうことです。これによって、これらの技術の応用が社会全体にとって正味の利益につながる方向へ進化すると信じています。 私たちの既存の取り組みの一部の例: 私たちはMLモデルのさまざまな使い方(要約、テキスト生成、物体検出など)を非常にわかりやすく説明しています。 モデルページのウィジェットを通じて、誰でも直接ブラウザでモデルを試すことができるようにしています。そのため、それを行うための技術的なスキルの必要性を低下させています(例)。 システムで特定された有害なバイアスについてドキュメント化し、警告しています(GPT-2など)。 誰でも1クリックでMLの潜在能力を理解できるオープンソースのMLアプリを作成するためのツールを提供しています。 🤗 初心者向けの教育 🗣️ 私たちは、オンラインコース、実践的なワークショップ、その他の革新的な技術を提供することで、機械学習エンジニアになるためのハードルを下げたいと考えています。 私たちは自然言語処理(NLP)やその他のドメインについての無料コースを提供しています(近日中に)。これらのコースでは、Hugging Faceエコシステムの無料ツールやライブラリを使用して学ぶことができます。このコースの最終目標は、(ほぼ)どんな機械学習の問題にもTransformerを適用する方法を学ぶことです! 私たちはDeep Reinforcement Learningについての無料コースを提供しています。このコースでは、理論と実践でDeep…

私たちは、オープンかつ協力的な機械学習のために1億ドルを調達しました 🚀
今日は、素晴らしいニュースをお伝えします!Hugging Faceは、Lux CapitalをリードとするシリーズCの資金調達で1億ドルを調達しました🔥🔥🔥。Sequoia、Coatue、そして既存の投資家であるAddition、a_capital、SV Angel、Betaworks、AIX Ventures、Kevin Durant、Thirty Five VenturesのRich Kleiman、Datadogの共同設立者兼CEOであるOlivier Pomelなどが主要な出資者となっています。 2018年にPyTorch BERTをオープンソース化して以来、私たちは長い道のりを歩んできましたが、まだ始まったばかりです!🙌 機械学習は、技術を構築するためのデフォルトの方法になりつつあります。1日の平均を考えてみると、機械学習はあらゆるところにあります:Zoomの背景、Googleでの検索、Uberの利用、オートコンプリート機能を使用したメールの作成など、すべてが機械学習です。 Hugging Faceは、現在最も急成長しているコミュニティであり、機械学習のための最も使用されているプラットフォームです!自然言語処理、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などのための100,000以上の事前学習モデルと10,000以上のデータセットをホストしており、Hugging Face Hubは、最先端のモデルを作成、共同作業、展開するための機械学習のホームとなっています。 10,000以上の企業がHugging Faceを使用して機械学習による技術を構築しています。彼らの機械学習科学者、データサイエンティスト、機械学習エンジニアは、私たちの製品とサービスの助けを借りて、数え切れないほどの時間を節約し、機械学習のロードマップを加速させています。 私たちはAI分野にポジティブな影響を与えたいと考えています。より責任あるAIの進展は、モデル、データセット、トレーニング手順、評価指標をオープンに共有し、問題を解決するために協力することを通じて実現されると考えています。オープンソースとオープンサイエンスは、信頼性、堅牢性、再現性、継続的なイノベーションをもたらします。これを念頭に、私たちはBigScienceをリードしています。これは、1,000人以上の研究者が集まり、非常に大きな言語モデルの研究と作成を行う協力的なワークショップです。そして、私たちは現在、世界最大のオープンソースの多言語言語モデルのトレーニングを行っています🌸 ⚠️ しかし、まだ大量の作業が残されています。 Hugging Faceでは、機械学習にはバイアス、プライバシー、エネルギー消費などの重要な制約と課題があることを認識しています。オープンさ、透明性、協力を通じて、これらの課題を緩和するための責任ある包括的な進歩、理解、および説明責任を促進することができます。…

打ち上げ!最初のMLプロジェクトを始める方法 🚀
機械学習の世界に初めて入る人々は、2つの頻繁な stumbling block によく遭遇します。最初の stumbling block は、学習するための適切なライブラリを選ぶことであり、選択肢が多い場合には困難な課題です。適切なライブラリを選び、いくつかのチュートリアルを終えた後でも、次の問題は最初の大規模プロジェクトを考え出し、適切にスコープを設定して学習を最大化することです。これらの問題にぶつかったことがある場合、またはツールキットに追加する新しい ML ライブラリを探している場合は、正しい場所にいます! この記事では、Sentence Transformers (ST) を例に挙げながら、新しいライブラリを使って0から100まで進むためのいくつかのヒントを紹介します。まず、STの基本的な機能を理解し、学習に適した素晴らしいライブラリであることを強調します。次に、最初の自己主導プロジェクトに取り組むための戦術を共有します。また、最初のSTプロジェクトの構築方法と、その過程で学んだことについても話しましょう 🥳 Sentence Transformers とは何ですか? Sentence embeddings?Semantic search?Cosine similarity?!?! 😱 数週間前まで、これらの用語は私にとって混乱して頭がクラクラするほどでした。Sentence Transformers…

文のトランスフォーマーを使用してプレイリスト生成器を構築する
数時間前に、Sentence TransformersとGradioを使用して構築したプレイリスト生成器を公開しました。それに続いて、プロジェクトを効果的な学習体験として活用する方法について考察しました。しかし、実際にプレイリスト生成器をどのように構築したのでしょうか?この投稿では、そのプロジェクトを解説し、埋め込みの生成方法と多段階のGradioデモの構築方法について説明します。 以前のHugging Faceブログの記事でも探求したように、Sentence Transformers(ST)は文の埋め込みを生成するためのツールを提供するライブラリです。使用できる歌詞のデータセットにアクセスできたため、STの意味的検索機能を活用して与えられたテキストプロンプトからプレイリストを生成することにしました。具体的には、プロンプトから埋め込みを作成し、その埋め込みを事前生成された歌詞の埋め込みセット全体で意味的検索に使用し、関連するソングのセットを生成することでした。これはすべて、Hugging Face Spacesでホストされた新しいBlocks APIを使用したGradioアプリに包括されます。 Gradioのやや高度な使用方法について説明しますので、ライブラリに初めて取り組む方は、この投稿のGradio固有の部分に取り組む前に、Blocksの紹介を読むことをお勧めします。また、歌詞のデータセットは公開しませんが、Hugging Face Hubで歌詞の埋め込みを試すことができます。それでは、始めましょう! 🪂 Sentence Transformers:埋め込みと意味的検索 埋め込みはSentence Transformersの鍵です!以前の記事で埋め込みが何であり、どのように生成するかについて学びましたので、この投稿を続ける前にそれをチェックすることをお勧めします。 Sentence Transformersには、事前学習された埋め込みモデルの大規模なコレクションがあります!独自のトレーニングデータを使用してこれらのモデルを微調整するチュートリアルも用意されていますが、多くのユースケース(歌詞のコーパスを対象とした意味的検索など)では、事前学習されたモデルが問題なく機能します。ただし、利用可能な埋め込みモデルが非常に多いため、どれを使用するかをどのように知ることができるのでしょうか? STのドキュメントでは、多くの選択肢が強調されており、評価メトリックといくつかの使用ケースの説明も示されています。MS MARCOモデルはBing検索エンジンのクエリでトレーニングされていますが、他のドメインでも優れたパフォーマンスを発揮するため、このプロジェクトではこれらのいずれかを選択することができると判断しました。プレイリスト生成器に必要なのは、いくつかの意味的な類似性を持つ曲を見つけることであり、特定のパフォーマンス指標に達成することにはあまり興味がないため、sentence-transformers/msmarco-MiniLM-L-6-v3を任意に選びました。 STの各モデルには、設定可能な入力シーケンス長があります(最大値まで)。その後、入力は切り捨てられます。私が選んだモデルは最大シーケンス長が512ワードピースであり、これは歌を埋め込むのに十分ではないことがわかりました。幸いなことに、歌詞をモデルが解析できるように小さなチャンクに分割する簡単な方法があります。それは、詩です!歌を詩に分割し、各詩を埋め込んだ後、検索がはるかに優れた結果を示すことになります。 歌は詩に分割され、それぞれの詩は埋め込まれます。 実際に埋め込みを生成するには、Sentence Transformersモデルの.encode()メソッドを呼び出し、文字列のリストを渡すだけです。その後、埋め込みを好きな方法で保存できます。この場合は、pickle形式で保存することにしました。…

敵対的なデータを使用してモデルを動的にトレーニングする方法
ここで学ぶこと 💡ダイナミックな敵対的データ収集の基本的なアイデアとその重要性。 ⚒敵対的データを動的に収集し、モデルをそれらでトレーニングする方法 – MNIST手書き数字認識タスクを例に説明します。 ダイナミックな敵対的データ収集(DADC) 静的ベンチマークは、モデルの性能を評価するための広く使用されている方法ですが、多くの問題があります:飽和していたり、バイアスがあったり、抜け穴があったりし、研究者が指標の増加を追い求める代わりに、信頼性のあるモデルを構築することができません1。 ダイナミックな敵対的データ収集(DADC)は、静的ベンチマークのいくつかの問題を緩和する手法として大いに期待されています。DADCでは、人間が最先端のモデルを騙すための例を作成します。このプロセスには次の2つの利点があります: ユーザーは、自分のモデルがどれだけ堅牢かを評価できます。 より強力なモデルをさらにトレーニングするために使用できるデータを提供します。 このように騙し、敵対的に収集されたデータでモデルをトレーニングするプロセスは、複数のラウンドにわたって繰り返され、人間と合わせてより堅牢なモデルが得られるようになります1。 敵対的データを使用してモデルを動的にトレーニングする ここでは、ユーザーから敵対的なデータを動的に収集し、それらを使用してモデルをトレーニングする方法を説明します – MNIST手書き数字認識タスクを使用します。 MNIST手書き数字認識タスクでは、28×28のグレースケール画像の入力から数字を予測するようにモデルをトレーニングします(以下の図の例を参照)。数字の範囲は0から9までです。 画像の出典:mnist | Tensorflow Datasets このタスクは、コンピュータビジョンの入門として広く認識されており、標準(静的)ベンチマークテストセットで高い精度を達成するモデルを簡単にトレーニングすることができます。しかし、これらの最先端のモデルでも、人間がそれらを書いてモデルに入力したときに正しい数字を予測するのは難しいとされています:研究者は、これは静的テストセットが人間が書く非常に多様な方法を適切に表現していないためだと考えています。したがって、人間が敵対的なサンプルを提供し、モデルがより一般化するのを助ける必要があります。 この手順は以下のセクションに分けられます: モデルの設定 モデルの操作…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.