Learn more about Search Results arXiv - Page 15

- You may be interested
- 「ユナイテッド航空がコスト効率の高い光...
- ビジネスにおける機械学習オペレーション...
- ソルボンヌ大学の研究者は、画像、ビデオ...
- 次元性の祝福?!(パート1)
- 機械学習の専門家 – Sasha Luccioni
- 「Vianaiの新しいオープンソースのソリュ...
- 「P-値:統計的有意性の理解を平易な言葉で」
- VoAGIニュース、7月19日:ChatGPTが退位?...
- AIを用いた遺伝子発現の予測
- 「プロダクションでのあなたのLLMの最適化」
- 「ジェネレーティブAI 2024年とその先:未...
- マサチューセッツ州ローウェル大学の研究...
- Pythonによる(Bio)イメージ分析:ヒストグ...
- 「ゼロ冗長最適化(ZeRO):Pythonによる...
- AIとの対話:より優れた言語モデルの構築

「目と耳を持つChatGPT:BuboGPTは、マルチモーダルLLMsにおいて視覚的なグラウンディングを可能にするAIアプローチです」
大規模言語モデル(LLM)は、自然言語処理の領域でゲームチェンジャーとして登場しました。彼らは私たちの日常生活の重要な一部になりつつあります。最も有名なLLMの例はChatGPTであり、この時点でほとんどの人がそれについて知っており、ほとんどの人が日常的に使用していると安全に言えます。 LLMはその巨大なサイズと膨大なテキストデータからの学習能力によって特徴付けられます。これにより、彼らは一貫した文脈に即した人間らしいテキストを生成することができます。これらのモデルは、GPT(Generative Pre-trained Transformer)やBERT(Bidirectional Encoder Representations from Transformers)などの深層学習アーキテクチャに基づいて構築されており、言語の長距離依存関係を捉えるために注意メカニズムを使用しています。 大規模なデータセットでの事前トレーニングと特定のタスクでの微調整を活用することで、LLMはテキスト生成、感情分析、機械翻訳、質問応答など、さまざまな言語関連のタスクで優れたパフォーマンスを発揮しています。LLMが改良を続けるにつれて、機械と人間のような言語処理の間のギャップを埋め、自然言語の理解と生成を革新するという莫大なポテンシャルを秘めています。 一方、一部の人々は、LLMがテキスト入力に限定されているため、その全ての潜在能力を活用していないと考えていました。彼らはLLMの潜在能力を言語以外の領域に広げる取り組みを行ってきました。いくつかの研究では、画像、動画、音声、オーディオなどのさまざまな入力信号をLLMと統合し、強力なマルチモーダルチャットボットを構築することに成功しています。 しかし、ここにはまだ長い道のりがあります。これらのモデルのほとんどは、視覚オブジェクトと他のモダリティの関係を理解していません。視覚的に強化されたLLMは高品質な説明を生成することができますが、視覚的な文脈に明示的に関連付けることなく、ブラックボックス的な方法で行います。 マルチモーダルLLMにおいてテキストと他のモダリティの間に明示的かつ有益な対応関係を確立することで、ユーザーエクスペリエンスを向上させ、これらのモデルに新たな応用を可能にすることができます。そこで、私たちはBuboGPTに会いましょう。これはこの制約に取り組むものです。 BuboGPTは、視覚オブジェクトを他のモダリティに接続することでLLMに視覚的な基礎付けを取り入れる最初の試みです。BuboGPTは、事前トレーニングされたLLMとよく一致する共有表現空間を学習することにより、テキスト、ビジョン、オーディオのための共同マルチモーダル理解とチャットを実現します。 BuboGPTの概要。出典: https://arxiv.org/pdf/2307.08581.pdf 視覚的な基礎付けは容易な課題ではないため、それがBuboGPTのパイプラインの重要な部分を担っています。このメカニズムは、視覚オブジェクトとモダリティとの間の細かい関係を確立します。 パイプラインには、タギングモジュール、グラウンディングモジュール、エンティティマッチングモジュールの3つのモジュールが含まれています。タギングモジュールは、入力画像の関連するテキストタグ/ラベルを生成し、グラウンディングモジュールは各タグに対して意味的なマスクまたはボックスをローカライズし、エンティティマッチングモジュールはタグと画像の説明から一致するエンティティをLLMの推論に使用します。視覚オブジェクトと他のモダリティを言語を介して接続することで、BuboGPTはマルチモーダル入力の理解を向上させます。 BuboGPTチャットの例。出典: https://arxiv.org/pdf/2307.08581.pdf 任意の入力の複数モーダル理解を可能にするために、BuboGPTはMini-GPT4に似た2段階のトレーニングスキームを採用しています。最初の段階では、音声エンコーダとしてImageBind、視覚エンコーダとしてBLIP-2、および言語とビジョンまたは音声の特徴を整列させるQ-formerを学習するためのLLMとしてVicunaを使用します。2番目の段階では、高品質な指示に従うデータセットでマルチモーダルな指示の調整を行います。 このデータセットの構築は、LLMが提供されたモダリティを認識し、入力が適切にマッチしているかどうかを認識するために重要です。したがって、BuboGPTは、ビジョン指示、音声指示、正の画像・音声ペアを使用した音の位置づけ、および意味推論のための負のペアを使用した画像・音声キャプショニングのためのサブセットを持つ、新しい高品質なデータセットを構築しています。負の画像・音声ペアを導入することで、BuboGPTはより良いマルチモーダルな整合性を学び、より強力な共同理解能力を示すことができます。

「分かれれば倒れ、一緒に立つ:CoTrackerは、ビデオ内の複数のポイントを共同で追跡するAIアプローチです」
I had trouble accessing your link so I’m going to try to continue without it. 近年、AIの領域で画像生成と大規模言語モデルの進歩が目覚ましく、その革新的な能力により長い間注目を浴びてきました。画像生成と言語モデルの両方は非常に優れており、生成された出力と実際のものを区別するのは困難です。 しかし、近年急速に進歩したのはこれらだけではありません。コンピュータビジョンの応用でも印象的な進歩が見られます。例えば、セグメンテーション・エニシング(SAM)モデルは、オブジェクトのセグメンテーションにおいて新たな可能性を開拓しました。SAMは画像またはより印象的にはビデオ内の任意のオブジェクトをトレーニング辞書に依存せずにセグメント化することができます。 ビデオ部分は特に興味深いです。ビデオは常に扱いにくいデータと考えられてきました。ビデオを扱う際には、どのようなタスクを達成しようとしているにせよ、モーショントラッキングが重要な要素となります。これが問題の基礎です。 モーショントラッキングの重要な要素の1つは、ポイントの対応関係を確立することです。最近では、動的なオブジェクトと移動カメラを持つビデオでのモーション推定を行うための複数の試みがありました。この難しいタスクでは、ビデオフレーム全体の2Dポイントの位置を推定し、基礎となる3Dシーンポイントの投影を表現します。 モーション推定の2つの主要なアプローチは、オプティカルフローとトラッキングです。オプティカルフローはビデオフレーム内のすべてのポイントの速度を推定し、トラッキングはポイントの運動を統計的に独立したものとして推定します。 近代的なディープラーニング技術により、ポイントトラッキングは進歩していますが、追跡されたポイント間の相関関係という重要な側面が見落とされています。直感的には、同じ物理的なオブジェクトに属するポイントは関連しているはずですが、従来の方法ではそれらを独立して扱ってしまい、誤った近似値を導くことになります。この問題に取り組むCoTrackerの登場です。 CoTrackerは、追跡されたポイント間の相関関係を考慮することで、長いビデオシーケンスでのポイントトラッキングを革新しようとするニューラルネットワークベースのトラッカーです。このネットワークはビデオと変動する数の開始トラック位置を入力とし、指定されたポイントの完全なトラックを出力します。 CoTrackerは複数のポイントの共同トラッキングをサポートし、ウィンドウアプリケーションでより長いビデオを処理することができます。トランスフォーマーベースのネットワークは、時間を1つの次元、トラッキングポイントをもう1つの次元とする2Dグリッド上で動作し、適切なセルフアテンション演算子を使用することで、各トラックをウィンドウ内でまとめて考慮し、トラック間で情報を交換し、それらの固有の相関関係を活用することができます。 CoTrackerの概要。出典:…
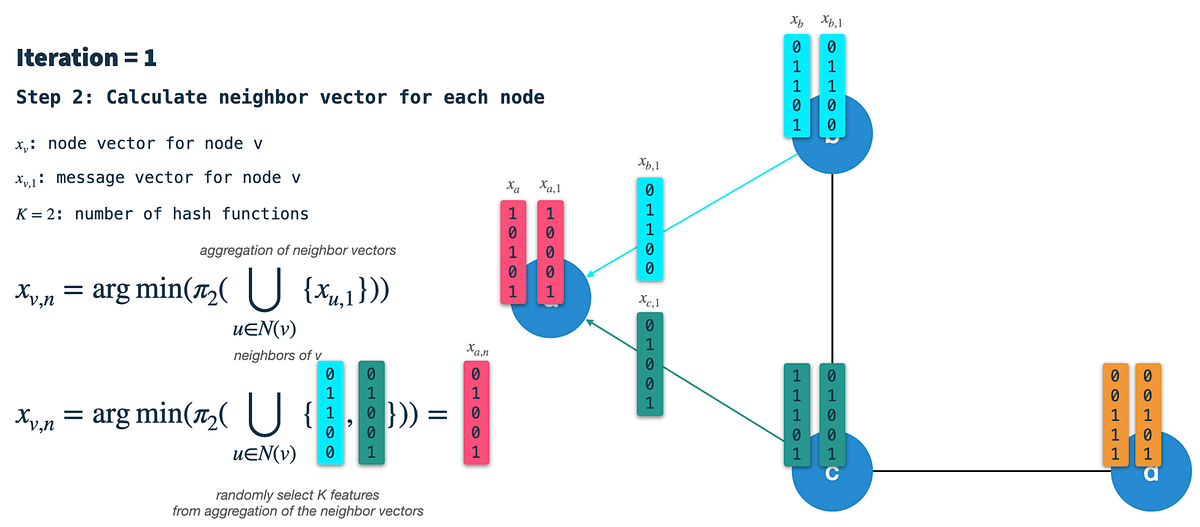
HashGNN Neo4j GDSの新しいノード埋め込みアルゴリズムに深く入り込む
HashGG(#GNN)は、高次の近接性とノードの特性を捉えるためにメッセージパッシングニューラルネットワーク(MPNN)の概念を利用するノード埋め込み技術ですこれにより、大幅にスピードアップします...

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…

「生成AIの布地を調整する:FABRICは反復的なフィードバックで拡散モデルを個別化するAIアプローチです」
ジェネラティブAIは、今では私たち全員が馴染みのある用語です。最近、彼らは大きく進化し、多くのアプリケーションで重要なツールとなっています。 ジェネラティブAIの主役は拡散モデルです。これらは強力なジェネラティブモデルの一種として登場し、画像合成や関連するタスクを革新しています。これらのモデルは、高品質かつ多様な画像を生成することで、驚異的なパフォーマンスを示しています。GANやVAEなどの従来のジェネラティブモデルとは異なり、拡散モデルはノイズ源を反復的に洗練することで、安定した一貫した画像生成を実現しています。 拡散モデルは、トレーニング中の高品質な画像生成とモードの崩壊の削減において、大きな注目を集めています。これにより、画像合成、インペイント、スタイル転送など、さまざまなドメインでの広範な採用と応用が実現されています。 しかし、完璧ではありません。印象的な能力にも関わらず、拡散モデルの課題の1つは、テキストの説明に基づいてモデルを特定の望ましい出力に効果的に誘導することです。テキストのプロンプトを通じて好みを正確に説明することは通常困難であり、時には不十分であったり、モデルがそれらを無視し続けることもあります。そのため、通常は生成された画像を洗練させて利用可能にする必要があります。 しかし、あなたはモデルに何を描かせたいのかを知っています。したがって、理論的には、生成された画像の品質、それが想像にどれだけ近いかを評価するのに最適な人物です。私たちが見たいものをモデルが理解できるように、このフィードバックを画像生成パイプラインに統合できればどうでしょうか?それでは、FABRICに出会う時がきました。 FABRIC(Attention-Based Reference Image Conditioningを介したフィードバック)は、拡散モデルの生成プロセスに反復的なフィードバックの統合を可能にする新しいアプローチです。 FABRICは、ユーザーフィードバックに基づいて機能します。出典: https://arxiv.org/pdf/2307.10159.pdf FABRICは、以前の世代または人間の入力から収集された肯定的および否定的なフィードバック画像を利用します。これにより、将来の結果を洗練するためにリファレンスイメージを利用した調整が可能となります。この反復的なワークフローにより、ユーザーの好みに基づいて生成された画像を微調整し、より制御可能かつインタラクティブなテキストから画像への生成プロセスを提供します。 FABRICは、ControlNetに触発されており、リファレンスイメージに似た新しい画像を生成する能力を導入しました。 FABRICは、U-Net内の自己注意モジュールを活用し、画像内の他のピクセルに「注意」を向け、リファレンスイメージから追加情報を注入することができます。リファレンスイメージを通過させて、Stable DiffusionのU-Netを介してキーと値を計算し、これらのキーと値をU-Netの自己注意層に保存することで、ノイズ除去プロセスがリファレンスイメージに注意を向け、意味情報を組み込むことができます。 FABRICの概要。出典: https://arxiv.org/pdf/2307.10159.pdf さらに、FABRICは、マルチラウンドの肯定的および否定的なフィードバックを組み込むために拡張されており、好きな画像と嫌いな画像ごとに別々のU-Netパスが実行され、フィードバックに基づいて注目スコアが再重み付けされます。フィードバックプロセスは、ノイズ除去ステップに従ってスケジュールされるため、生成された画像の反復的な洗練が可能となります。
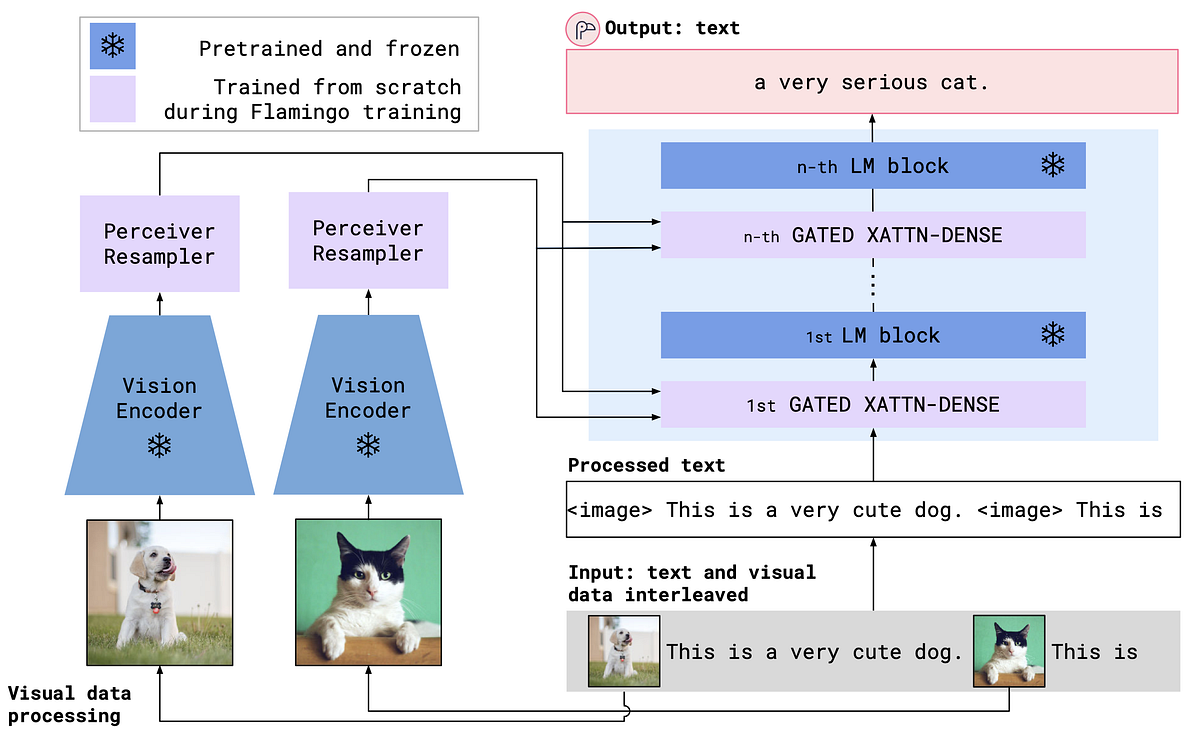
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」
Langchain 101 構造化データ(JSON)の抽出
「VoAGIの新しい方針に基づいて、私はLLM関連ソフトウェアの実践的な側面に焦点を当てた一連の短い記事を始める予定です」
「HaystackにおけるRAGパイプラインの拡張 DiversityRankerとLostInTheMiddleRankerの紹介」
最近の自然言語処理(NLP)と長文質問応答(LFQA)の進歩は、わずか数年前にはまるでSFの世界から来たようなものだと思われていたでしょう誰...

「LK-99超伝導体:突破かもしれない、新たな希望かもしれない」
「専門家たちは、室温超伝導体に関する非凡な主張に反対していますしかし、失敗しても新たな材料研究の道が開ける可能性があります」

一貫性のあるAIビデオエディターが登場しました:TokenFlowは、一貫性のあるビデオ編集のために拡散特徴を使用するAIモデルです
拡散モデルは、この時点でお馴染みのものです。過去の1年間、AIの領域で鍵となるトピックでした。これらのモデルは、画像生成において驚くべき成功を収め、まったく新しいページを開きました。 私たちは、テキストから画像を生成する時代にいますし、それらは日々改善されています。MidJourneyなどの拡散型生成モデルは、大規模な画像テキストデータセットを使用しており、テキストの提示に基づいて多様で現実的な視覚コンテンツを生成する能力を示しています。 テキストから画像へのモデルの急速な進化は、画像編集とコンテンツ生成の著しい進展をもたらしました。現在、ユーザーは生成された画像と実際の画像のさまざまな要素を制御することができます。これにより、アイデアをよりよく表現し、手作業の描画に数日間費やす代わりに、比較的迅速な方法で結果を示すことができます。 ただし、これらの画期的な進展をビデオの領域に適用する場合は、状況は異なります。ここでは進展が比較的遅いです。テキストからビデオを生成する大規模な生成モデルは登場しましたが、解像度、ビデオの長さ、および表現できるビデオのダイナミクスの複雑さに関してはまだ制限があります。 ビデオ編集に画像拡散モデルを使用する際の主な課題の1つは、編集されたコンテンツがすべてのビデオフレームで一貫していることを確保することです。画像拡散モデルに基づく既存のビデオ編集方法は、自己注意モジュールを複数のフレームに拡張することでグローバルな外観の整合性を実現していますが、望ましいレベルの時間的一貫性を達成するのは難しいことがよくあります。これにより、プロフェッショナルや準プロフェッショナルは、追加の手作業を含む緻密なビデオ編集手順に頼ることがあります。 それでは、TokenFlowに会いましょう。これは、事前学習されたテキストから画像へのモデルの力を活用して、自然なビデオのテキストによる編集を可能にするAIモデルです。 TokenFlowの主な目標は、入力テキストプロンプトで表現される目標の編集に従って、元のビデオの空間レイアウトとモーションを維持しながら、高品質のビデオを生成することです。 TokenFlowはテキストプロンプトを使用して自然なビデオを編集できます。出典:https://arxiv.org/pdf/2307.10373.pdf TokenFlowは、時間の一貫性の解決を目指して導入されました。それは編集されたビデオの特徴がフレーム間で一貫していることを保証するために、元のビデオのダイナミクスに基づいて編集された拡散特徴を伝播させることによって実現されます。これにより、追加のトレーニングや微調整の必要なしに、最先端の画像拡散モデルの生成事前知識を活用することができます。TokenFlowは、既存の拡散型画像編集手法ともシームレスに連携します。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.