Learn more about Search Results RoPE - Page 15

- You may be interested
- ChatGPT の機能 観察、ヒント、およびトリ...
- 「合成イメージングがAIトレーニングの効...
- 「テンソル量子化:語られなかった物語」
- 「初心者におすすめの副業5選(無料のコー...
- 「スポーツアナリストになるにはどうすれ...
- 「Googleの「この画像について」機能:AI...
- 「時系列分析を用いた回帰モデルの頑健性...
- 中国のこのAI論文は、ダイナミックなSLAM...
- トランスフォーマーによるOCRフリーの文書...
- 「本番環境での機械学習モデルのモニタリ...
- 一般的に、オープンエンドの遊びから優れ...
- 「クラシック音楽の作曲家を識別するため...
- 「データサイエンスにおける予測の無限の...
- Google DeepMindは、ChatGPTを超えるアル...
- AIが白人を好むとき

「Jupyter APIを使用してノートブックをスケジュールして呼び出す」
GCP CloudRunnerやCloud Functionsといったサーバーレスクラウドサービスのおかげで、ノートブックをデプロイして周期的に実行するために高額な仮想マシンやサーバーを管理する必要はありません

「StableCodeの公開:AIによるコーディングの新たな地平線」
この記事では、開発効率とアクセシビリティを向上させるためにStability AIが開発した革新的なAI製品であるStableCodeについて探求しますその独自の機能、基盤技術、そして開発者コミュニティへの潜在的な影響について詳しく解説します
多段階回帰モデルとシンプソンのパラドックス
「データ分析は、その職業名からも明らかなように、データサイエンティストの仕事の重要な一部であり、記述統計や単純な回帰モデルから高度な機械学習までさまざまな分野にわたります」

「生成AIの規制」
生成型の人工知能(AI)が注目を集める中、この技術を規制する必要性が高まっていますなぜなら、この技術は大規模な人口に対して迅速に負の影響を与える可能性があるからです影響は以下のようなものが考えられます...
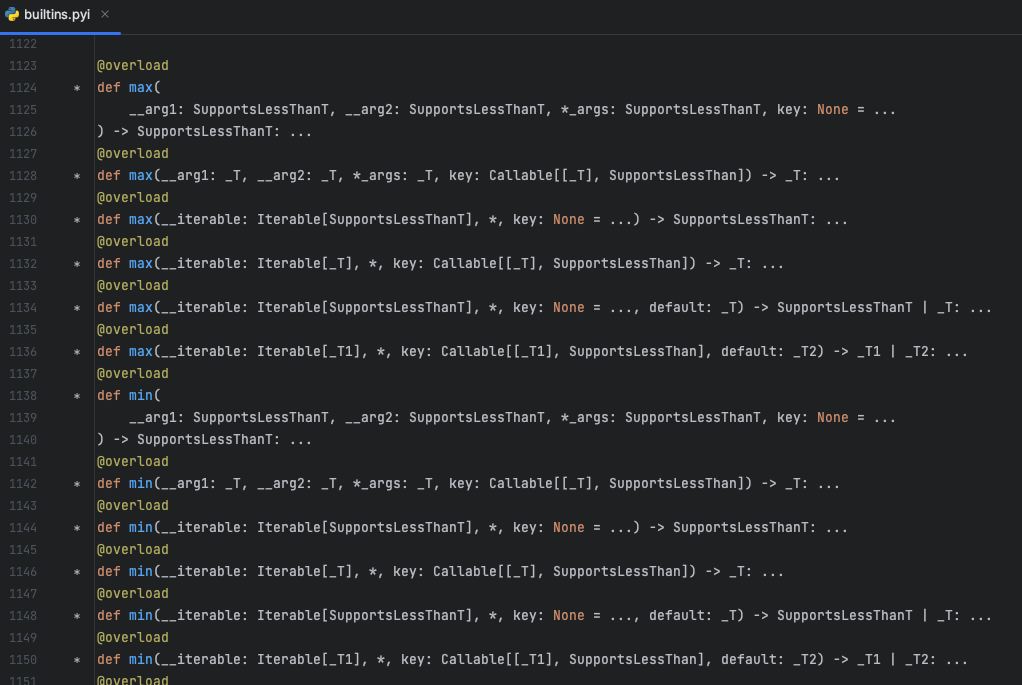
「Pythonデコレーターは開発者のエクスペリエンスをスーパーチャージします🚀」
Pythonの@overloadデコレータは、Pythonの組み込みモジュールであるtypingで見つけることができますこのデコレータは、開発者が関数やメソッドに複数のタイプ固有のシグネチャを指定することを可能にしますこれにより、…

データサイエンティストやアナリストのための統計の基礎
データサイエンスまたはデータ分析の旅における重要な統計的概念

AIマニア:バブルがはじける方向に向かっているのか?
仮想通貨ブームの後、人工知能(AI)の世界はベンチャーキャピタリスト(VC)の関心の大きな急増を経験しました。しかし、仮想通貨からAIに焦点が移るにつれて、AIブームの持続可能性に関する懸念が浮上しました。AIブームが終わりに近づいている兆候が表面化しており、AIバブルの崩壊の可能性があります。本記事では、AI市場の現状、GPUへの過度な依存、知的財産の不足、市場の飽和の兆候について掘り下げます。 また読む:中国の10億ドルの賭け:Baiduの14.5億ドルのAIファンドが新たな自己依存のAI時代を示す AIがVCの関心で仮想通貨を追い越す 2022年の暗号通貨の低迷に続いて、VCは安息地を求め、それを人工知能で見つけました。OpenAIが2022年末にリリースしたChatGPTは、AIがVC市場での支配の始まりを示しました。この突破口により、Google、Microsoft、FacebookなどのテックジャイアントもAIブームに参入し、AIスタートアップの成長をさらに後押ししました。 また読む:KPMGがAIに20億ドル以上を賭け、120億ドルの収益を目指す AI資金洪水:スタートアップに数億ドルが注ぎ込まれる AIスタートアップは、驚異的な投資ラウンドで巨額の資金を調達しました。Jasper AI、Anthropic、Inflection AIなどは、数十億ドルの資本を調達した数少ない例です。PitchBookの調査によると、AI市場は急速に休眠中の研究分野から投資家にとって利益の出る遊び場に変貌しました。 また読む:AWSとAccelが「ML Elevate 2023」を開始し、インドのAIスタートアップエコシステムを支援 GPU不足:高性能ハードウェアを追い求める 印象的な投資にもかかわらず、AIスタートアップは重大な課題に直面しています。それは、重要なGPUの不足です。調達された資金のほとんどは、NvidiaやAMDなどの企業から高性能GPUを獲得するために使われます。この激しい競争は供給チェーンの問題を悪化させ、そのような支出の長期的な実現可能性についての懸念を引き起こしています。 また読む:中国の強力なNvidia AIチップの隠れた市場 知的財産(IP)の潜在的な不足 多くのAIプラットフォームは、OpenAIなどの既存プレーヤーのAPIに大きく依存しており、知的財産の制御や所有権がほとんどありません。需要が減退すると、Jasper AIなどのスタートアップはレイオフを余儀なくされ、頑丈なプロダクトの堀を持たないビジネスの脆弱性がさらに浮き彫りにされます。 市場の飽和と性能の低下の兆候 市場の飽和は、ChatGPT、Bard、BingなどのAIチャットボットへの関心が初めて低下していることから明らかになっています。GPT-4のパフォーマンスの増加した不正確さに関する報告は、AIバブルの持続可能性についての懸念を引き起こしています。スタンフォード大学の研究によると、GPT-3.5とGPT-4のパフォーマンスは時間の経過とともに低下していることから、潜在的な転換点を示しています。 また読む:チップデザインへの政府の介入:インドの半導体志向にとって利益か損失か? 私たちの意見 AIは確かにさまざまな産業を革新し、投資家の熱狂を引き起こしましたが、市場の飽和と外部APIへの依存はAIバブルについての懸念を引き起こしています。GPUへの過度の需要とAIモデルのパフォーマンスの低下は、バブルにさらなる重みを加えています。AIマニアは、業界レポートや潜在的な破産がバーストにつながる可能性があるため、現実的なチェックを受ける可能性があります。AIの未来を待ちながら、投資家や開発者は市場を注意深く観察し、将来の課題を乗り越え、持続可能な機会を見つける必要があります。

「モンテカルロシミュレーションを通じてA/Bテストのパフォーマンスを理解するための初心者向けガイド」
このチュートリアルでは、共変量がランダム化実験におけるA/Bテストの精度にどのように影響するかを探求します適切にランダム化されたA/Bテストでは、処置群と対照群の平均結果を比較することでリフトを計算します...
データ駆動型のディスパッチ
「現代のスピーディーな世界において、データに基づく意思決定がディスパッチ応答システムにおいて不可欠となっていますディスパッチャーは、通話を聞いて優先順位を付けるという一種のトリアージを行います...」

アバカスAIは、新しいオープンロングコンテキスト大規模言語モデルLLM「ジラフ」を紹介します
最近の言語モデルは長い文脈を入力として受け取ることができますが、それらが長い文脈をどれだけ効果的に使用しているかについてはさらなる知見が必要です。LLMsは長い文脈に拡張することができるのでしょうか?これは未解決の問いです。Abacus AIの研究者たちは、Llamaというモデルの文脈長の能力を開発するためのさまざまな手法を用いた実験を行いました。このモデルは、文脈長2048で事前学習されています。彼らはこれらのモデルをIFTを用いてスケール4および16で線形にスケールアップしました。モデルをスケール16にスケールアップすると、16kの文脈長または20-24kの文脈長までのワールドタスクを実行することができます。 文脈長を拡張するための異なる手法には、線形スケーリング、回転位置埋め込み(RoPE)のフーリエ基底のスケーリング、フーリエ基底の切り捨て、および位置ベクトルのランダム化があります。Abacus AIの研究者たちは、これらの手法を実装することでRedPajamaデータセットとVicunaデータセットを組み合わせてfine-tuningしました。彼らは、線形スケーリングは堅牢であるが、モデルの文脈長を増加させることがわかりました。切り捨てとランダム化はパープレキシティのスコアが高いが、リトリーバルタスクでは性能が低い結果となりました。 これらのモデルの評価には、LMSys、オープンブックの質問応答データセット、およびWikiQAからのデータセットを使用しました。LMSysデータセットは、文脈内の部分文字列を特定するために使用されました。WikiQAタスクは、Wikipediaのドキュメント内の情報に基づいて質問に答えるタスクです。 チームは、Google Natural Questionsのショートアンサーフォーマットデータに基づいたQAタスクを構築しました。出力は、元のドキュメントからコピー&ペーストした短い単語の回答だけであることを保証しています。これにより、LLMがどこを参照する必要があるのかを正確に特定することができ、回答を異なる位置に配置することで拡張された文脈長の各部分を効果的に評価することができます。彼らはまた、異なるサイズの同じWikipediaドキュメントの複数のバージョンを作成し、モデルのサイズにわたる公平な評価を行うことができました。 Wikipediaベースのデータセットの問題点は、モデルが事前学習されたテキストから回答を出力してしまうことです。研究者たちは、数値の回答のみを持つ質問からなる変更されたデータセットを作成することで、この問題を解決しました。彼らは回答とドキュメント内のすべての出現箇所を異なる数字に変更しました。これにより、モデルが事前学習テキストから再現する場合に誤った回答をするようになります。元のQAタスクをFree Form QA(FFQA)とし、変更されたタスクをAltered Numerical QA(AltQA)としました。 AbacusAIの研究者たちは、QAタスクの両バージョンのすべての例における存在精度を評価しました。存在精度は、モデルの生成された解答に回答が部分文字列として存在するかどうかを測定する指標です。彼らは、IFTによる精度の向上がモデルが達成できる文脈長の範囲を拡張しないことを観察しました。 研究者たちは、スケールされた文脈とIFTの組み合わせによる性能の飛躍的な向上を示しています。彼らは、スケールされた文脈ファクターによって補間されたすべての位置で、FFQAでは2倍、AltQAでは2.5倍の改善を観察しました。最後に、彼らの研究は、テーマをより良く捉え、より簡単に表現することができるより大きな文脈の言語モデルを提案しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.