Learn more about Search Results Loom - Page 15

- You may be interested
- 「大規模言語モデルをより効率的に最適化...
- 「APIガバナンスによるAIインフラストラク...
- 「アルマンド・ソラール・レザマが初代デ...
- 「エキスパートのミックスについて解説」
- 「ExcelでのPython 高度なデータ分析への...
- 効果的にMLソリューションを比較する方法
- 「GPT-4 対 ゼファー-7b-beta:どちらを使...
- 欠陥が明らかにされる:MLOpsコース作成の...
- KNNクラシファイアにおける次元の呪い
- 「06/11から12/11までの週のトップ重要コ...
- ストリートビューが救いの手を差し伸べる...
- 「2023年の人工知能(AI)と機械学習に関...
- (Note Since HTML is a markup language, ...
- エンティティの解決実装の複雑さ
- MAmmoTHとは、一般的な数学問題解決に特化...

ビジョン言語モデルの高速化:Habana Gaudi2上のBridgeTower
Optimum Habana v1.6 on Habana Gaudi2 では、最新のビジョン言語モデルである BridgeTower のファインチューニングにおいて、A100 と比較してほぼ3倍の高速化を実現しています。ハードウェアアクセラレーションによるデータの読み込みと高速な DDP 実装の2つの新機能がパフォーマンス向上に寄与しています。 これらの技術は、データの読み込みに制約がある他のワークロードにも適用できます。これは、さまざまなタイプのビジョンモデルに頻繁に起こるケースです。この投稿では、BridgeTower のファインチューニングを Habana Gaudi2 と Nvidia A100 80GB で比較するために使用したプロセスとベンチマークを紹介します。また、トランスフォーマーベースのモデルでこれらの機能を簡単に活用する方法も示します。 BridgeTower 最近のビジョン言語(VL)モデルは、さまざまなVLタスクで非常に重要であり、優位性を示しています。最も一般的なアプローチは、それぞれのモダリティから表現を抽出するためにユニモーダルエンコーダを利用することです。その後、これらの表現は融合されるか、クロスモーダルエンコーダに供給されます。VL表現学習のパフォーマンス制約と制限を効果的に扱うために、BridgeTower は複数のブリッジ層を導入し、ユニモーダルエンコーダのトップ層とクロスモーダルエンコーダの各層との間に接続を構築します。これにより、クロスモーダルエンコーダ内の異なる意味レベルで視覚とテキストの表現の効果的なボトムアップのクロスモーダルの整合性と融合が可能になります。…
企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
最近の数年間で、言語モデルは大きな注目を集め、自然言語処理、コンテンツ生成、仮想アシスタントなど、さまざまな分野を革新しました最も注目されているのは、

ドライバーレスカーの闇 プライバシーの侵害
自動運転車の出現は、より安全で効率的な移動の未来として長く称賛されてきました。しかし、自動運転技術がサンフランシスコなどの都市で現実のものとなるにつれて、この理想的なビジョンの真実はかなり異なるものとなっています。報告によれば、これらの車両に埋め込まれた常時オンの監視カメラは、個人のプライバシーに重大なリスクをもたらす可能性があります。法執行機関は、これらのカメラで撮影された映像へのアクセスを要求しています。これにより、専門家たちが指摘する監視と憲法上の権利の侵害への懸念が生じています。 約束されたビジョンと気まずい現実 自動車メーカーやテック企業の元々のビジョンでは、自動運転車は知能のあるAI駆動の驚異として描かれ、乗客と一般の安全を向上させるものとされていました。しかし、真実は最初に描かれた理想的なシナリオからは程遠いものとなっています。これらの車両は一般の安全に頻繁に障害物となり、専門家たちが長らく警告してきたプライバシーの懸念を抱えています。 また読む:Didi Neuron:未来の無人タクシー 法執行機関による映像の要求:驚くべき事実 Bloombergの最新の報告によれば、Googleの子会社であるWaymoは、自動運転車業界の重要なプレイヤーです。彼らの自律走行中に撮影された映像について、法執行機関からの要求にさらされています。この事実は、自動運転車の約束された未来からの心配な逸脱を示しており、自動車産業における監視技術の使用についての疑問を提起しています。 ディストピアの可能性:監視とプライバシーの専門家が声を上げる プライバシーや監視に関する懸念が高まる中、この開発の影響について専門家たちは注目を集めています。反監視活動家であるアルバート・フォックス・カーン氏は、監視技術監視プロジェクトのディレクターであり、自動車の監視、カメラ映像の継続的な記録などは車両を警察の道具に変える可能性があり、自動車会社が技術を投資し、社会を独裁主義に向かわせないようにする必要性を強調しています。 自動運転技術のグローバルな拡大:データの収集と取り扱い 自動運転技術がカリフォルニアを超えてテキサスやアリゾナなどの都市に広がり、さらには世界的な場所に到達するにつれて、企業がユーザーデータをどのように収集、保存、取り扱うかを理解することが重要になってきます。自動運転システムの拡大は、データプライバシーや法執行機関によるユーザー情報の誤用の可能性について重要な問題を提起しています。 令状と召喚状のジレンマ テック企業によるユーザーデータの収集は、必然的に法的な注目を集めます。情報時代では、ユーザーデータの要求は令状や召喚状を通じて避けられないものとなっています。この問題は、欧州連合が最近自律走行車に対する法的枠組みを確立し、製造業者がデータを収集し、当局に提供することを可能にする可能性があるため、アメリカ合衆国を超えて広がっています。この規定の完全な影響はまだ見えていません。 個人の安全のコスト:プライバシー対監視 WaymoやCruiseなどの企業は、安全な自律型車の構築に対する公約を一般に保証していますが、個人の安全はしばしば後退します。プライバシーの専門家は、監視技術やデータ収集システムが法執行機関の要求に対して脆弱であり、憲法上のプライバシー権を侵害し、弱者のコミュニティに不釣り合いな影響を与えると強調しています。 スポットライトの中のカメラ:恐ろしい経験 カメラの存在は自動運転システムの機能に不可欠です。外部カメラは車両が道路を進むのを支援し、内部カメラは顧客サポートを提供するとされています。しかし、テストドライブ中に一部の乗客が顔を隠して旅行をする光景から、常時監視に対する不快感が明らかになっています。 法執行機関の関心:Waymoと捜査令状 最近の報告では、法執行機関が自動運転車のカメラで撮影された映像の潜在的な価値を認識していることが示されています。Bloombergの調査によれば、Waymoはサンフランシスコでの自律型車のビデオ録画に関して少なくとも9つの捜査令状の対象となっています。ただし、通常ギャグオーダーが伴うことがあるこのような要求の真の範囲は不明です。 企業の対応:プライバシーに向けて努力 Waymoは、適用される法律と法的手続きに準拠しているかどうかを確認するために、各法執行機関からの要求を審査していると主張しています。データの共有を最小限に抑え、過度に広範な要求には反対しています。同様に、Cruiseもプライバシーの重要性を強調し、法的手続きまたは個人の安全が危険にさらされている緊急の状況にのみ、データを提供しています。 私たちの意見 自動運転車革命が勢いを増す中、個人のプライバシーへの侵害が重要な懸念となっています。監視カメラの使用やユーザーデータの収集は、安全性、監視、および憲法上の権利のバランスについて重大な問題を提起します。自動車メーカーやテクノロジー企業は、プライバシー保護を優先すべきです。また、自動運転の未来の約束が個人の自由の犠牲とならないようにも注意する必要があります。監視、データプライバシー、および自動運転車におけるAI技術の責任ある使用についての議論は、今後数年間の交通の未来を形作るでしょう。 詳しくはこちら:AIが自動車産業をどのように変えているのか?

Googleはカナダに「リンク税」を支払わないと伝え、ニュースリンクを検索から削除すると発表しました
カナダはテック企業にニュース機関への支払いを求めており、同様の法案がアメリカでも審議中です

北京大学の研究者たちは、ChatLawというオープンソースの法律用の大規模言語モデルを紹介しましたこのモデルには、統合された外部知識ベースが搭載されています
人工知能の成長と発展により、大規模な言語モデルが広く利用可能になりました。ChatGPT、GPT4、LLaMA、Falcon、Vicuna、ChatGLMなどのモデルは、さまざまな伝統的なタスクで優れたパフォーマンスを発揮し、法律業界にとっても多くの機会を開いています。ただし、信頼性のある最新かつ高品質なデータを収集することが、大規模な言語モデルの構築には不可欠です。したがって、効果的かつ効率的なオープンソースの法律言語モデルの作成が重要になっています。 人工知能による大規模モデルの開発は、医療、教育、金融など、いくつかの産業に影響を与えています。BloombergGPT、FinGPT、Huatuo、ChatMedなどのモデルは、難解な問題の解決や洞察に有用で効果的であることが証明されています。一方で、法律の領域では、その固有の関連性と正確さの必要性から、徹底的な調査と独自の法的モデルの作成が求められます。法律は、コミュニティの形成、人間関係の規制、そして正義を確保する上で重要です。法律実務家は、賢明な判断を下し、法律を理解し、法的助言を提供するために正確で最新の情報に頼る必要があります。 法的用語の微妙なニュアンス、複雑な解釈、法律の動的な性質は、特殊な問題を引き起こし、専門的な解決策を必要とします。最先端のGPT4などのモデルでも、法的な困難に関しては頻繁に幻覚現象や驚くべき結果が生じることがあります。多くの人々は、関連するドメインの専門知識でモデルを改善することが良い結果をもたらすと考えています。しかし、早期の法的LLM(LawGPT)にはまだ多くの幻覚と不正確な結果が存在するため、これは事実ではありません。当初は中国の法的LLMの需要があることが理解されました。しかし、13億以上のパラメータを持つ中国のモデルは、商業的に利用可能な時点では存在しませんでした。MOSSなどのソースからのトレーニングデータを組み合わせ、中国語の語彙を増やすことで、経済的に実現可能なモデルであるOpenLLAMAの基盤が改善されました。これにより、北京大学の研究者は、中国語の基本モデルを構築し、それに法律特有のデータを追加してChatLawという法的モデルをトレーニングすることができました。 以下は、論文の主な貢献です: 1. 幻覚を減らすための成功した方法:モデルのトレーニング手順を改善し、推論時に「相談」「参照」「自己提案」「応答」という4つのモジュールを組み込むことにより、幻覚を減らす方法を提案しています。参照モジュールを介して垂直モデルと知識ベースを統合することで、幻覚がより少なくなり、ドメイン固有の知識がモデルに組み込まれ、信頼性のあるデータが知識ベースから使用されます。 2. ユーザーの日常言語から法的特徴語を抽出するモデルがトレーニングされました。これはLLMに基づいています。法的な意味を持つ用語を認識するこのモデルの助けを借りて、ユーザーの入力内の法的状況を迅速かつ効果的に特定し、分析することができます。 3. BERTを使用して、ユーザーの普通の言語と930,000件の関連する裁判文書のデータセットとの類似度を測定するモデルがトレーニングされました。これにより、類似した法的文脈を持つ文章を迅速に検索し、追加の研究や引用が可能になります。 4. 中国語の法的試験評価データセットの開発:中国語を話す人々の法的専門知識を評価するためのデータセットを作成しました。また、さまざまなモデルが法的な多肢選択問題でどれだけ優れたパフォーマンスを発揮するかを判断するためのELOアリーナスコアリングシステムも作成しました。 また、一つの汎用的な法的LLMは、この領域で一部のタスクに対してのみうまく機能する可能性があります。そのため、彼らは複数の状況に対応するために、多肢選択問題、キーワード抽出、質問応答などのさまざまなモデルを開発しました。HuggingGPT技術を使用して、大規模なLLMをコントローラーとして使用し、これらのモデルの選択と展開を管理しました。ユーザーの要求に基づいて、このコントローラーモデルは動的に特定のモデルを選択してアクティブにし、タスクに最適なモデルを使用することを保証します。

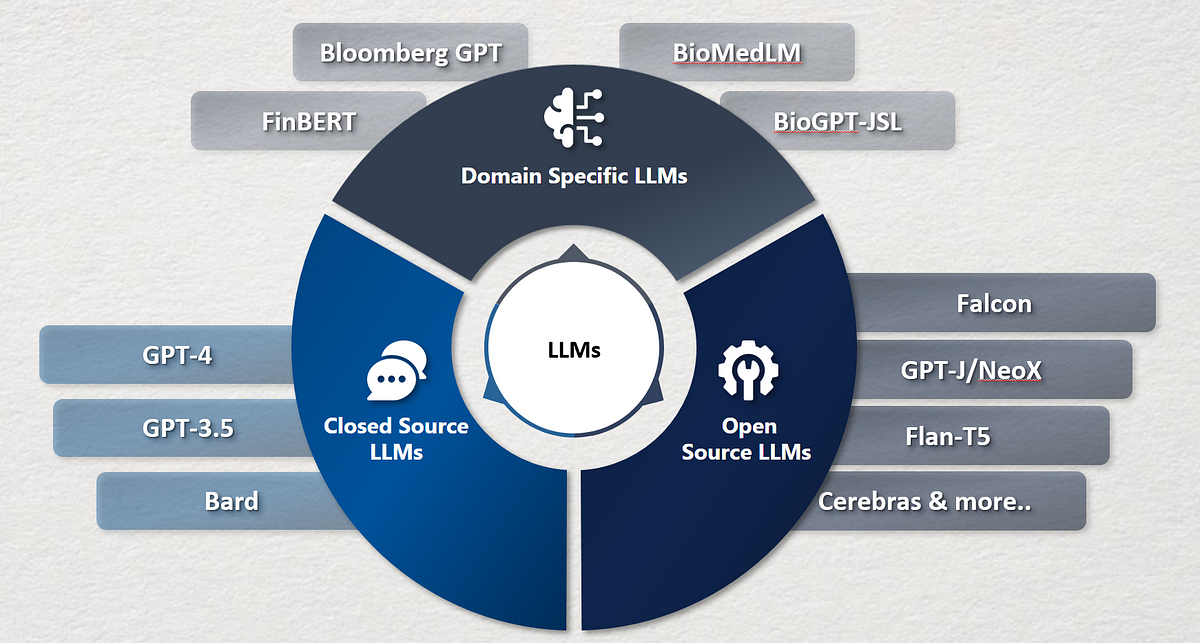
大規模言語モデル(LLM)とは何ですか?LLMの応用と種類
コンピュータプログラムである大規模言語モデルは、テキストの解析や作成のための新しいオプションをソフトウェアに提供します。大規模言語モデルは、ペタバイト以上のテキストデータを使用してトレーニングされることが珍しくなく、そのサイズは数テラバイトになることもあります。モデルのパラメータは、以前のトレーニングデータから学習されたコンポーネントであり、テキスト生成などのタスクにおけるモデルの適性を確立します。音声認識、感情分析、テキスト要約、スペルチェック、トークンの分類など、自然言語処理(NLP)の活動は、言語モデルを基盤としています。言語モデルはテキストを分析し、ほとんどの自然言語処理のタスクで次のトークンの確率を予測することができます。ユニグラム、N-グラム、指数、およびニューラルネットワークは、言語モデルの有効な形式です。 LLMの応用 以下のチャートは、大規模言語モデル(LLM)の現状を機能、製品、およびサポートソフトウェアの面でまとめたものです。 画像の出典:https://cobusgreyling.medium.com/the-large-language-model-landscape-9da7ee17710b シェルコマンドの生成 次世代ターミナルのWarpは、GPT-3を使用して自然言語を実行可能なシェル命令に変換します。GitHub Copilotのようなものですが、ターミナル向けです。 経験豊富なプログラマでも、シェルコマンドの構文を説明する必要がある場合があります。 正規表現の生成 開発者にとって正規表現の生成は時間がかかりますが、Autoregex.xyzはGPT-3を活用してこのプロセスを自動化します。 コピーライティング このタスクに最も人気のあるモデルはGPT-3ですが、BigScienceのBLOOMやEleuther AIのGPT-Jなどのオープンソースの代替品もあります。Copy ai、Copysmith、Contenda、Cohere、Jasper aiなどのスタートアップ企業は、この分野でアプリを開発しており、ブログ投稿、販売コンテンツ、デジタル広告、ウェブサイトのコピーなどの執筆を素早く容易にします。 分類 テキストを予め定義されたカテゴリに分類することは、教師あり学習の例です。クラスタリングという教師なし学習技術を用いることで、意味が似ているテキストを事前定義されたクラスなしでまとめることができます。 応答生成 応答生成は、サンプルの対話を使用して対話のフローを生成し、機械学習のアプローチを採用するアイデアです。ユーザーに提示される次の議論がモデルによって決定され、ユーザーの過去の応答と最も可能性の高い将来の会話を考慮に入れます。これを予測対話と呼びます。 テキストの生成 LLMの能力は、簡単な説明からテストを生成することで、「メタ能力」と見なされるかもしれません。ほとんどのLLMは生成の役割を果たします。フューショット学習データは、生成を大幅に向上させるだけでなく、データのキャスティングもデータの使用方法に影響を与えます。 知識応答 知識応答は、アプリケーションプログラミングインターフェース(API)のクエリや従来の知識ストアに頼ることなく、一般的なクロスドメインの問い合わせに対する応答を可能にする知識重視の自然言語処理(KI-NLP)の応用です。 知識重視の自然言語処理はウェブ検索ではなく、意味検索をサポートする知識ベースです。…
Hugging Face Datasets での作業
AIプラットフォームであるHugging Faceは、最先端のオープンソースの機械学習モデルの構築、トレーニング、展開を行いますこれらのトレーニング済みモデルをホスティングするだけでなく、Hugging Faceはデータセットもホスティングしています...
このスペースを見る:AIを使用してリスクを推定し、資産を監視し、クレームを分析する新しい空間金融の分野
金融の意思決定をする際には、ドローン、衛星、またはAIパワードセンサーから取得した大局的な情報を見ることが重要です。 空間金融という新興分野では、銀行、保険会社、投資会社、および事業者がリスクと機会を分析し、新しいサービスや製品を提供し、保有資産の環境への影響を測定し、危機後の被害を評価するために、リモートセンサーや空中画像からのAIの洞察を活用しています。 空間金融の応用には、資産のモニタリング、エネルギー効率のモデリング、排出物や汚染物の追跡、違法な鉱業や森林伐採の検出、自然災害のリスクの分析などがあります。NVIDIAのAIソフトウェアとハードウェアは、これらの応用を加速するために、ビジネスデータを地理空間データと組み合わせるための支援を提供できます。 投資に関連する環境と社会のリスクをよりよく理解することで、金融部門は持続可能な開発をサポートする可能性の高い投資を優先することができます。これは環境、社会、ガバナンス(ESG)として知られる枠組みです。 持続可能な投資への関心は高まっており、Bloomberg Intelligenceの分析によれば、ESG資産は2025年までに世界の総管理資産の3分の1以上を占めると推定されています。また、欧州連合宇宙プログラム機関の報告書によると、保険業や金融業は次の10年間で地球観測データとサービスの最大の消費者となり、2031年までに総売上高が10億ドルを超える見込みです。 NVIDIA Inceptionのメンバーの中には、工場周辺の水質汚染を追跡したり、野火の金融リスクを評価したり、嵐後の被害を評価したりすることができるGPUアクセラレートAIアプリケーションを開発しているスタートアップがあります。 大規模データのための強力な計算 GPUアクセラレートAIとデータサイエンスは、複雑で構造化されていないデータから迅速に洞察を抽出することができます。これにより、銀行や事業者は衛星、ドローン、アンテナ、エッジセンサーからキャプチャされたデータのリアルタイムストリーミングと分析を設定することができます。 航空写真を監視することにより、公共の宇宙機関から無料で入手できるもの、または民間企業からより詳細なものを使用して、解析者は貯水池からの水の使用量の推移、建設プロジェクトのために伐採された木の数、竜巻によって損傷を受けた家の数などを明確に把握することができます。 この機能により、政府の義務付けられた開示書類、環境影響報告書、さらには保険請求などの正確性を検証することで、投資を監査するのに役立ちます。 たとえば、投資家は、製品ラインでネットゼロを達成したと報告している会社のサプライチェーンを追跡し、衛星画像で確認できる石炭灰を発する海外の工場に依存していることを発見するかもしれません。また、ビルからの熱放射を分析するセンサーは、税金控除対象となる低排出ビジネスを特定するのに役立ちます。 NVIDIAのエッジコンピューティングソリューションは、自律型マシンやその他の組み込みアプリケーション向けのNVIDIA Jetsonプラットフォームを含め、空間金融のさまざまなAIイニシアチブを支えています。 アプリケーションの高速化のためにNVIDIAハードウェアを使用するだけでなく、開発者は、ビジョンAIのためのNVIDIA Metropolisプラットフォームの一部であるストリーミング分析のためのNVIDIA DeepStreamソフトウェア開発キット、およびジオスペーシャルデータの詳細な3DビジュアライゼーションのためのNVIDIA Omniverseプラットフォームを使用しています。 保険業務-リスク評価から請求の加速まで NVIDIA Inceptionのメンバーは、ジオスペーシャルデータを保険会社に洞察を提供するGPUアクセラレートアプリケーションを開発しており、保険対象物の状態を監視するために必要な高価な現地訪問の回数を減らすことができます。 ルクセンブルクに拠点を置くRSS-Hydroは、衛星画像から洪水の影響をマッピングするためにGPUコンピューティングをクラウドとオンプレミスで使用しています。同社はまた、洪水のリスクを効果的に伝え、緊急時のリソース配分計画を通知するために、FloodSENSを3Dでアニメーション化するためにNVIDIA Omniverseを使用しています。…

専門AIトレーニングの変革- LMFlowの紹介:優れたパフォーマンスのために大規模な基盤モデルを効率的に微調整し、個別化するための有望なツールキット
大規模言語モデル(LLMs)は、大規模な基盤モデルの上に構築されており、以前は不可能だったさまざまなタスクを実行する一般的な能力を示しています。しかし、特定のドメインやジョブでのパフォーマンスを向上させるには、このようなLLMのさらなるファインチューニングが必要です。大規模モデルのファインチューニングには、以下のような一般的な手順が含まれます: ニッチな領域での継続的な事前学習により、広範な基礎モデルがそのような領域での専門知識を獲得することができます。 自然言語の特定のタイプの命令を理解し実行するために、大規模な汎用ベースモデルの調整。 必要な会話能力を備えた大規模な基礎モデルのトレーニング(RLHF:人間のフィードバックを用いた強化学習)。 すでにいくつかの大規模モデルが事前学習され、一般に公開されています(GPT-J、Bloom、LLaMAなど)。しかし、これらのモデル全体で効率的にファインチューニング操作を行うことができる公開ツールボックスはありません。 香港大学とプリンストン大学の研究者チームが、制約されたリソースで効率的に巨大モデルのファインチューニングと推論を支援するための使いやすく軽量なツールセットを作成しました。 Nvidia 3090 GPUと5時間あれば、7兆パラメータのLLaMAモデルに基づいたカスタムモデルをトレーニングすることができます。このフレームワークを使用して単一のマシン上で7、13、33、65兆パラメータのLLaMAのバージョンをファインチューニングした後、研究用にモデルの重みが提供されました。 オンラインで無償で利用できる大規模言語モデルの出力を最適化するには、以下の4つのステップがあります: 最初のステップは「ドメイン適応」であり、モデルを特定のドメインに対応させるためのトレーニングです。 2番目のステップはタスク適応であり、要約、質問応答、翻訳などの特定の目標を達成するためにモデルをトレーニングすることを意味します。 3番目のステージは、教示型質問・回答のペアに基づいてモデルのパラメータを調整する「教示型ファインチューニング」です。 最後のステップは、人々の意見に基づいてモデルを改善する「人間のフィードバックを用いた強化学習」です。 LMFlowは、これらの4つのステップに対する完全なファインチューニング手順を提供し、制約された計算リソースにもかかわらず、巨大言語モデルの個別のトレーニングを可能にします。 LMFlowは、連続的な事前トレーニング、命令調整、RLHFなどの機能を備えた大規模モデルの包括的なファインチューニング手法を提供し、使いやすく柔軟なAPIも提供しています。LMFlowによって、個別のモデルトレーニングが誰もが利用できるようになりました。質問応答、コンパニオンシップ、執筆、翻訳、さまざまな科目での専門的な相談などの活動において、各人は利用可能なリソースに基づいて適切なモデルを選択することができます。ユーザーが十分な大きさのモデルとデータセットを持っている場合、より長い期間のトレーニングにより優れた結果が得られます。チームは最近、ChatGPTよりも優れた33兆パラメータのモデルをトレーニングしました。
グリーンAI:AIの持続可能性を向上させるための方法とソリューション
もし、あなたがこの記事を開いたのであれば、おそらく現在の大規模言語モデル(LLM)の安全性と信頼性に関する現在の論争について聞いたことがあるでしょう有名な人々によって署名された公開書簡...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.