Learn more about Search Results Adam - Page 15

- You may be interested
- 「思考伝搬:大規模言語モデルを用いた複...
- 大規模言語モデルにおけるより高い自己一...
- 「Salesforce Data Cloudを使用して、Amaz...
- 「Jupyter AIに会おう Jupyterノートブッ...
- 「Amazon SageMaker JumpStartで利用可能...
- iPhone、iPad、およびMacでのCore MLによ...
- リトリーバル オーグメンテッド ジェネレ...
- PyTorch / XLA TPUsでのHugging Face
- A. Michael West 医療現場における人間と...
- Optimum+ONNX Runtime – Hugging Fa...
- RPDiffと出会ってください:3Dシーン内の6...
- 『AnomalyGPTとは:産業異常を検出するた...
- プレイヤーの離脱を予測する方法、ChatGPT...
- 神経協調フィルタリングでレコメンデーシ...
- このAIペーパーは動きがあります 「LaMo」...
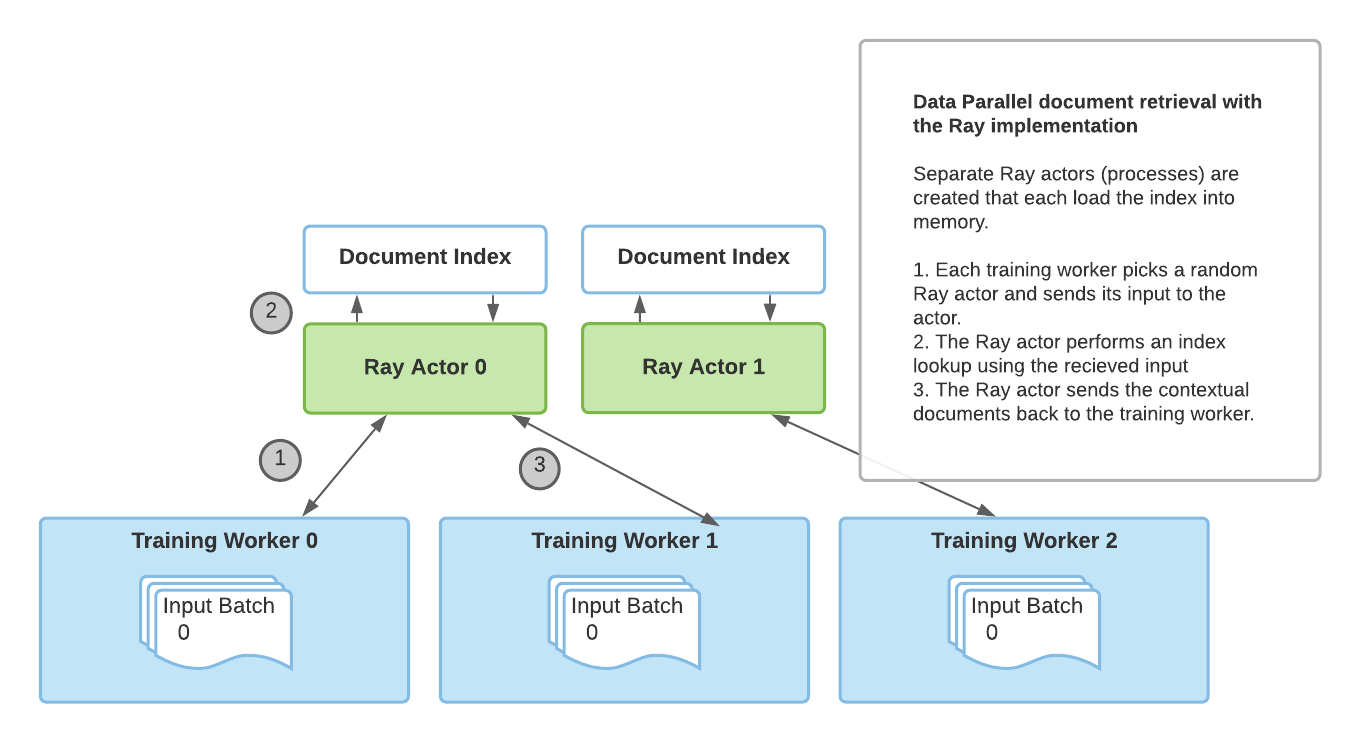
Huggingface TransformersとRayを使用した検索増強生成
アノスケールのチームからのゲストブログ投稿:Amog Kamsetty氏 Huggingface Transformersは最近、Retrieval Augmented Generation(RAG)モデルを追加しました。これは、外部のドキュメント(ウィキペディアなど)を活用して知識を拡充し、知識集約的なタスクで最先端の結果を実現する新しいNLPアーキテクチャです。このブログ投稿では、スケーラブルなアプリケーションを構築するためのライブラリであるRayをRAGの文脈におけるドキュメント検索メカニズムに統合する方法を紹介します。これにより、検索呼び出しの速度が2倍に向上し、RAGの分散ファインチューニングのスケーラビリティが向上します。 Retrieval Augmented Generation(RAG)とは何ですか? RAGの概要です。モデルは外部のデータセットから文脈ドキュメントを取得し、実行の一環として使用します。これらの文脈ドキュメントは元の入力と組み合わせて出力を生成するために使用されます。このGIFはFacebookのオリジナルのブログ投稿から取得されました。 最近、HuggingfaceはFacebook AIと提携して、RAGモデルをTransformersライブラリの一部として導入しました。 RAGは他のseq2seqモデルと同様に機能しますが、外部の知識ベース(ウィキペディアのテキストコーパスなど)から文脈ドキュメントを取得する中間コンポーネントを持っています。これらのドキュメントは入力シーケンスと組み合わせて基礎となるseq2seqジェネレータに渡されます。 この情報検索ステップにより、RAGはモデルパラメータに埋め込まれた知識と文脈のパッセージに含まれる情報という複数の知識源を活用することができます。これにより、質問応答などのタスクで他の最先端モデルを上回るパフォーマンスを発揮します。Huggingfaceが提供するデモを使用して、自分自身で試すこともできます。 ファインチューニングのスケーリング これらの文脈ドキュメントの取得は、RAGの最先端の結果にとって重要ですが、追加の複雑さをもたらします。データ並列トレーニングルーチンを介してトレーニングプロセスをスケーリングアップする際、ドキュメントの検索の単純な実装はトレーニングのボトルネックになることがあります。さらに、検索コンポーネントで使用されるドキュメントインデックスは非常に大きいため、各トレーニングワーカーが自分自身の複製されたインデックスを読み込むことは不可能です。 以前のRAGファインチューニングの実装では、torch.distributed通信パッケージを使用してドキュメント検索部分を活用していました。しかし、この実装は柔軟性に欠け、スケーラビリティに制約がありました。 その代わりに、フレームワークに依存しないアドホックな並行プログラミングのためのより柔軟な実装が必要です。それには、Rayが完璧に適しています。Rayは一般的な分散および並列プログラミングのためのシンプルで強力なPythonライブラリです。Rayを使用して分散ドキュメント検索を行うことで、torch.distributedに比べて検索呼び出しごとに2倍の高速化と、ファインチューニングのスケーラビリティの向上を実現しました。 ドキュメント検索のためのRay torch.distributedの実装によるドキュメント検索 torch.distributedを使用したドキュメント検索の主な欠点は、トレーニングに使用されるプロセスグループに依存していて、ランク0のトレーニングワーカーのみがインデックスをメモリに読み込んでいたことです。 その結果、この実装にはいくつかの制限がありました: 同期のボトルネック:ランク0のワーカーはすべてのワーカーから入力を受け取り、インデックスクエリを実行し、その結果を他のワーカーに送信する必要がありました。これにより、複数のトレーニングワーカーでのパフォーマンスが制限されました。 PyTorch固有の:ドキュメント検索プロセスグループはトレーニングに使用される既存のプロセスグループに依存する必要があり、トレーニングにはPyTorchを使用する必要がありました。…

🤗 Accelerate のご紹介
🤗 アクセラレート あらゆる種類のデバイスで、生の PyTorch のトレーニングスクリプトを実行できます。 PyTorch の上位レベルの多くのライブラリは、分散トレーニングや混合精度のサポートを提供していますが、それらが導入する抽象化により、ユーザーは基礎となるトレーニングループをカスタマイズするために新しい API を学ぶ必要があります。🤗 アクセラレートは、トレーニングループを完全に制御したい PyTorch ユーザーのために作成されましたが、分散トレーニング(複数のノード上のマルチ GPU、TPU など)、混合精度トレーニングに必要な骨格コードの記述(および保守)を行いたくないユーザーも対象です。今後の計画には、fairscale、deepseed、AWS SageMaker 特定のデータ並列処理とモデル並列処理のサポートも含まれます。 それは次の2つのことを提供します:骨格コードを抽象化するシンプルで一貫した API と、さまざまなセットアップでこれらのスクリプトを簡単に実行するための起動コマンドです。 簡単な統合! まずは例を見てみましょう: import torch import…
リモートセンシング(衛星)画像とキャプションを使用してCLIPの微調整
リモートセンシング(衛星)画像とキャプションを使用したCLIPの微調整 今年の7月、Hugging FaceはFlax/JAXコミュニティウィークを開催し、自然言語処理(NLP)とコンピュータビジョン(CV)の分野でHugging Faceトランスフォーマーモデルを訓練するプロジェクトの提出をコミュニティに呼びかけました。 参加者はFlaxとJAXを使用したTensor Processing Units(TPUs)を使用しました。JAXは線形代数ライブラリ(numpyのような)で、自動微分(Autograd)を行い、XLAにコンパイルできます。また、FlaxはJAX用のニューラルネットワークライブラリであり、エコシステムです。TPUの計算時間は、共同スポンサーであるGoogle Cloudが無料で提供しました。 その後の2週間で、チームはHugging FaceとGoogleの講義に参加し、JAX/Flaxを使用して1つ以上のモデルを訓練し、それらをコミュニティと共有し、モデルの機能を示すHugging Face Spacesデモを提供しました。約100チームが参加し、170のモデルと36のデモが生まれました。 私たちのチームは、おそらく他の多くのチームと同様に、12のタイムゾーンにまたがる分散型のチームです。私たちの共通点は、TWIML Slackチャンネルに所属していることであり、そこでは人工知能(AI)と機械学習(ML)のトピックに関心を持つメンバーが集まっています。 私たちは、OpenAIのCLIPネットワークをRSICDデータセットの衛星画像とキャプションで微調整しました。CLIPネットワークは、インターネット上で見つかる画像とキャプションのペアを使用して、自己教師ありの方法で視覚的な概念を学習します。推論中、モデルはテキストの説明に基づいて最も関連性の高い画像を予測するか、画像に基づいて最も関連性の高いテキストの説明を予測することができます。CLIPは、普段の画像に対してゼロショットで使用するには十分なパワフルです。しかし、衛星画像は普段の画像とは異なるため、CLIPを微調整することが有益であると考えました。私たちの直感は正しかったようで、評価結果(後述)が示すようになりました。この記事では、私たちのトレーニングと評価プロセスの詳細、およびこのプロジェクトへの今後の取り組みについて説明します。 私たちのプロジェクトの目標は、有用なサービスを提供し、CLIPを実用的なユースケースに使用する方法を示すことでした。私たちのモデルは、テキストクエリを使用して大規模な衛星画像のコレクションを検索するためにアプリケーションによって使用することができます。そのようなクエリは、画像全体を記述することができます(例:ビーチ、山、空港、野球場など)、またはこれらの画像内の特定の地理的または人工的な特徴を検索または言及することができます。CLIPは、他のドメインでも同様に微調整することができます。これは、医療画像のメディカルチームによって示されています。 テキストクエリを使用して大規模な画像コレクションを検索する能力は、非常に強力な機能であり、社会的な善だけでなく、悪意のある目的にも使用することができます。国家防衛や反テロ活動、気候変動の影響を管理可能な状態になる前に発見し対処する能力など、様々な応用が考えられます。ただし、この力は、権威主義的な国家による軍事や警察の監視などの目的で誤用される可能性もあるため、倫理的な問題も提起されます。 プロジェクトについては、プロジェクトページで詳細を読むことができます。また、独自のデータで推論に使用するために、トレーニング済みモデルをダウンロードすることもできます。デモでも実際の動作を確認することができます。 トレーニング データセット 私たちは、主にRSICDデータセットを使用してCLIPモデルを微調整しました。このデータセットは、Google Earth、Baidu Map、MapABC、Tiandituから収集された約10,000枚の画像から構成されています。このデータセットは、Exploring Models…

スクラッチからCodeParrot 🦜をトレーニングする
このブログポストでは、GitHub CoPilotの背後にある技術を構築するために必要なものについて説明します。GitHub CoPilotは、プログラマがコードを書く際に提案を行うアプリケーションです。このステップバイステップガイドでは、ゼロから完全にトレーニングされた大規模なGPT-2モデルであるCodeParrot 🦜を訓練する方法を学びます。CodeParrotはPythonのコードを自動補完することができます – こちらで試してみてください。さあ、ゼロから構築してみましょう! ソースコードの大規模なデータセットの作成 まず必要なものは、大規模なトレーニングデータセットです。Pythonのコード生成モデルを訓練することを目指して、GoogleのBigQueryで利用可能なGitHubのダンプにアクセスし、すべてのPythonファイルに絞り込みました。その結果、180GBのデータセットがあり、2000万のファイルが含まれています(こちらで入手可能)。初期のトレーニング実験の結果、データセットの重複はモデルの性能に深刻な影響を与えることがわかりました。データセットを調査すると、次のことがわかりました: ユニークなファイルの0.1%が全ファイルの15%を占めています ユニークなファイルの1%が全ファイルの35%を占めています ユニークなファイルの10%が全ファイルの66%を占めています 詳細は、このTwitterスレッドで調査結果について詳しくご覧いただけます。重複を削除し、CoPilotの背後にあるモデルであるCodexの論文で見つかった同じクリーニングヒューリスティックを適用しました。CodexはGitHubのコードでファインチューニングされたGPT-3モデルです。 クリーニングされたデータセットはまだ50GBの大きさであり、Hugging Face Hubで利用可能です:codeparrot-clean。これで新しいトークナイザーを設定し、モデルを訓練することができます。 トークナイザーとモデルの初期化 まず、トークナイザーが必要です。コードを適切にトークンに分割するために、コード専用のトークナイザーをトレーニングしましょう。既存のトークナイザー(例えばGPT-2)を取り、train_new_from_iterator()メソッドで独自のデータセットでトレーニングします。それから、Hubにプッシュします。コードの例からインポートや引数のパース、ログ出力は省略していますが、前処理やダウンストリームタスクの評価を含めた完全なコードはこちらで見つけることができます。 # トレーニング用のイテレーター def batch_iterator(batch_size=10): for _ in…
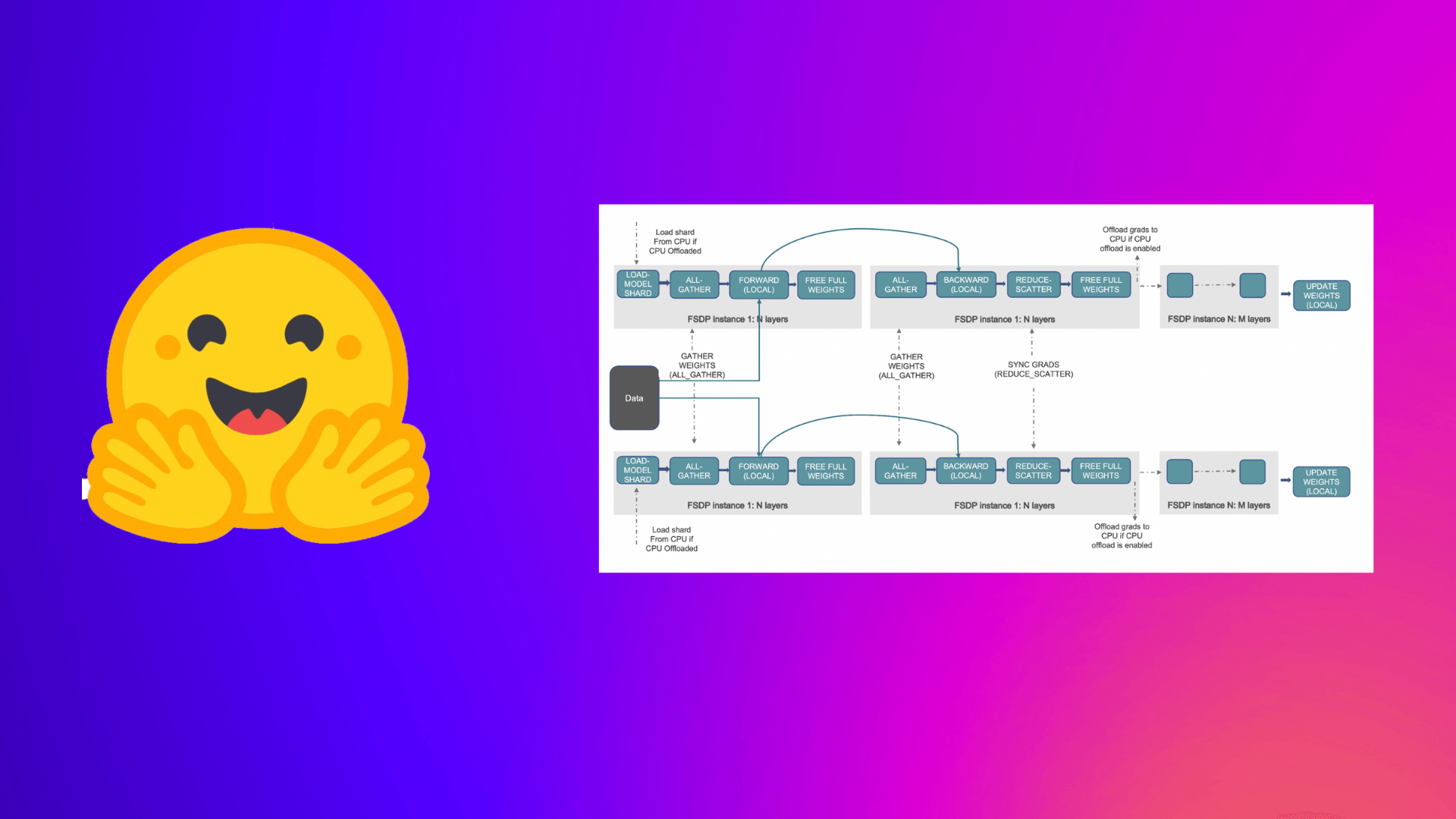
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…

文のトランスフォーマーを使用してプレイリスト生成器を構築する
数時間前に、Sentence TransformersとGradioを使用して構築したプレイリスト生成器を公開しました。それに続いて、プロジェクトを効果的な学習体験として活用する方法について考察しました。しかし、実際にプレイリスト生成器をどのように構築したのでしょうか?この投稿では、そのプロジェクトを解説し、埋め込みの生成方法と多段階のGradioデモの構築方法について説明します。 以前のHugging Faceブログの記事でも探求したように、Sentence Transformers(ST)は文の埋め込みを生成するためのツールを提供するライブラリです。使用できる歌詞のデータセットにアクセスできたため、STの意味的検索機能を活用して与えられたテキストプロンプトからプレイリストを生成することにしました。具体的には、プロンプトから埋め込みを作成し、その埋め込みを事前生成された歌詞の埋め込みセット全体で意味的検索に使用し、関連するソングのセットを生成することでした。これはすべて、Hugging Face Spacesでホストされた新しいBlocks APIを使用したGradioアプリに包括されます。 Gradioのやや高度な使用方法について説明しますので、ライブラリに初めて取り組む方は、この投稿のGradio固有の部分に取り組む前に、Blocksの紹介を読むことをお勧めします。また、歌詞のデータセットは公開しませんが、Hugging Face Hubで歌詞の埋め込みを試すことができます。それでは、始めましょう! 🪂 Sentence Transformers:埋め込みと意味的検索 埋め込みはSentence Transformersの鍵です!以前の記事で埋め込みが何であり、どのように生成するかについて学びましたので、この投稿を続ける前にそれをチェックすることをお勧めします。 Sentence Transformersには、事前学習された埋め込みモデルの大規模なコレクションがあります!独自のトレーニングデータを使用してこれらのモデルを微調整するチュートリアルも用意されていますが、多くのユースケース(歌詞のコーパスを対象とした意味的検索など)では、事前学習されたモデルが問題なく機能します。ただし、利用可能な埋め込みモデルが非常に多いため、どれを使用するかをどのように知ることができるのでしょうか? STのドキュメントでは、多くの選択肢が強調されており、評価メトリックといくつかの使用ケースの説明も示されています。MS MARCOモデルはBing検索エンジンのクエリでトレーニングされていますが、他のドメインでも優れたパフォーマンスを発揮するため、このプロジェクトではこれらのいずれかを選択することができると判断しました。プレイリスト生成器に必要なのは、いくつかの意味的な類似性を持つ曲を見つけることであり、特定のパフォーマンス指標に達成することにはあまり興味がないため、sentence-transformers/msmarco-MiniLM-L-6-v3を任意に選びました。 STの各モデルには、設定可能な入力シーケンス長があります(最大値まで)。その後、入力は切り捨てられます。私が選んだモデルは最大シーケンス長が512ワードピースであり、これは歌を埋め込むのに十分ではないことがわかりました。幸いなことに、歌詞をモデルが解析できるように小さなチャンクに分割する簡単な方法があります。それは、詩です!歌を詩に分割し、各詩を埋め込んだ後、検索がはるかに優れた結果を示すことになります。 歌は詩に分割され、それぞれの詩は埋め込まれます。 実際に埋め込みを生成するには、Sentence Transformersモデルの.encode()メソッドを呼び出し、文字列のリストを渡すだけです。その後、埋め込みを好きな方法で保存できます。この場合は、pickle形式で保存することにしました。…

Hugging FaceのTensorFlowの哲学
はじめに PyTorchやJAXからの競争が増えても、TensorFlowは最も使用されるディープラーニングフレームワークのままです。また、それらの他の2つのライブラリとはいくつか非常に重要な点で異なります。特に、高レベルのAPIであるKerasと、データの読み込みライブラリであるtf.dataとの統合が非常に密接です。 PyTorchのエンジニアの中には(ここでオープンプランオフィスを暗く見つめながら私を想像してください)、これを克服すべき問題だと見なす傾向があります。彼らの目標は、TensorFlowが彼らのやり方に従って低レベルのトレーニングとデータの読み込みコードを使用できるようにする方法を見つけることです。これはTensorFlowに取り組む間違った方法です! Kerasは素晴らしい高レベルのAPIです。プロジェクトが数モジュールよりも大きい場合、それを押しのけると、必要になると気付いたときに、その機能のほとんどを自分で再現することになります。 洗練された、尊敬され、非常に魅力的なTensorFlowエンジニアとして、私たちは最先端のモデルの驚異的なパワーと柔軟性を使用したいと思っていますが、私たちが使い慣れたツールとAPIでそれらを扱いたいのです。このブログポストでは、Hugging Faceでそれを実現するために行う選択と、TensorFlowプログラマーとしてフレームワークから期待できることについて説明します。 インタールード:30秒で🤗 経験豊富なユーザーは、このセクションをざっと読んだりスキップしたりして構いませんが、Hugging Faceとtransformersに初めて出会う方には、ライブラリのコアアイデアについて概要を説明する必要があります。モデルを事前学習済みモデルとして名前でリクエストするだけで、1行のコードで取得できます。最も簡単な方法は、TFAutoModelクラスを使用するだけです。 from transformers import TFAutoModel model = TFAutoModel.from_pretrained("bert-base-cased") この1行でモデルのアーキテクチャがインスタンス化され、重みが読み込まれます。これにより、元の有名なBERTモデルの正確なレプリカが得られます。ただし、このモデル自体ではあまり役に立ちません – 出力ヘッドや損失関数がありません。実際には、これは最後の隠れ層の直後で終了するニューラルネットワークの「ステム」です。では、どのようにして出力ヘッドを追加するのでしょうか?簡単です、異なるAutoModelクラスを使用するだけです。ここでは、Vision Transformer(ViT)モデルを読み込み、画像分類ヘッドを追加しています。 from transformers import TFAutoModelForImageClassification…

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.