Learn more about Search Results 財務 - Page 15

- You may be interested
- 「Saturn 大規模な言語モデルおよびその他...
- フルスケールのゲームプレイ:「ドラゴン...
- 5つの最高のChatGPT SEOプラグイン
- 「NVIDIAは、エンタープライズや開発者向...
- 「エラーバーの可視化に深く潜る」
- 「Amazon SageMakerを使用して、Rayベース...
- このAI研究は、多モーダル大規模言語モデ...
- 「月光スタジオのAIパワード受付アバター...
- Google AIは、TPUを使用して流体の流れを...
- 「セマンティックカーネルへのPythonista...
- ChatGPT の機能 観察、ヒント、およびトリ...
- Amazon Lex、Langchain、およびSageMaker ...
- 「SwimXYZとの出会い:水泳モーションとビ...
- 「Baichuan-13Bに会いましょう:中国のオ...
- ドキュメントAIの加速

フリーランサーが真の自由を達成するためのAIの3つの方法
ほとんどの人々がフリーランスを選ぶのは、自由を追い求めているからです考えてみてください自営業や「自分で働く」ということは、クライアントを選び、スケジュールを管理するという魅力がありますフリーランサーの数が増えていることは驚くことではありませんこれは、経済政策研究センターが報告したものです

AWSにおける生成AIとマルチモーダルエージェント:金融市場における新たな価値を開拓するための鍵
マルチモーダルデータは、市場、経済、顧客、ニュースおよびソーシャルメディア、リスクデータを含む、金融業界の貴重な要素です金融機関はこのデータを生成し、収集し、利用して、金融業務の洞察を得たり、より良い意思決定を行ったり、パフォーマンスを向上させたりしますしかし、マルチモーダルデータには複雑さと不足に起因する課題があります

Rocket Money x Hugging Face プロダクションで変動するMLモデルのスケーリング
「彼らはただのサービスプロバイダではなく、私たちの目標と結果に投資しているパートナーだと気づきました」- ニコラス・クザック、ロケットマネーのシニアMLエンジニア。 MLOpsチームなしでの本番環境でのMLモデルのスケーリングとメンテナンス 私たちは、Rocket Money(以前の名前はTruebillの個人ファイナンスアプリ)を作成し、ユーザーが自分の財務状況を改善できるようにしました。ユーザーは銀行口座をアプリにリンクさせ、トランザクションを分類し、カテゴリ分けし、繰り返しのパターンを特定して、個人の財務状況を総合的かつ包括的に表示します。トランザクション処理の重要な段階は、Rocket Moneyが会員のためにキャンセルし、費用を交渉できるいくつかの既知の販売業者やサービスを検出することです。この検出は、短く、しばしば切り詰められ、暗号化された形式のトランザクション文字列をクラスに変換して、製品体験を豊かにするために使用します。 新しいシステムへの旅 最初に、正規表現ベースの正規化器を使用してトランザクションからブランドと製品を抽出しました。これらは、文字列を対応するブランドにマッピングする複雑になる決定表と併用されました。このシステムは、キャンセルと交渉に対応する製品にのみ結び付けられたクラスが存在する場合には効果的でしたが、ユーザーベースが拡大し、サブスクリプションエコノミーが急速に発展し、製品の範囲が拡大するにつれて、新しいクラスの数と正規表現のチューニングや衝突の防止に追いつく必要がありました。これを解決するために、バッグオブワーズモデルとクラスごとのモデルアーキテクチャを使用したさまざまな従来の機械学習(ML)ソリューションを検討しました。このシステムはメンテナンスとパフォーマンスに苦労し、保留となりました。 私たちは、まっさらな状態から新しいチームと新しい命令を組み立てることに決めました。最初の課題はトレーニングデータを蓄積し、ゼロから社内システムを構築することでした。私たちはRetoolを使用してラベリングキュー、ゴールドスタンダードの検証データセット、ドリフト検出モニタリングツールを構築しました。さまざまなモデルトポロジーを試しましたが、最終的にはBERTファミリーのモデルを選び、テキスト分類の問題を解決しました。初期のモデルのテストと評価のほとんどは、GCPのデータウェアハウス内でオフラインで実施されました。ここでは、4000以上のクラスを持つモデルのパフォーマンスを測定するために使用したテレメトリとシステムを設計および構築しました。 Hugging Faceとのパートナーシップによるドメインの課題と制約の解決 私たちのドメイン内には、商品を提供する業者や処理/支払い会社、機関の違い、ユーザーの行動の変化など、独自の課題がいくつかあります。効率的なモデルのパフォーマンスアラート設計と現実的なベンチマーキングデータセットの構築は、継続的に課題となっています。もう1つの重要な課題は、システムの最適なクラス数を決定することです-各クラスは作成とメンテナンスに相当な労力を要するため、ユーザーとビジネスへの価値を考慮する必要があります。 オフラインのテストでうまく機能するモデルと少数のMLエンジニアのチームを持つ私たちは、新たな課題に直面しました:そのモデルを私たちの本番パイプラインにシームレスに統合すること。既存の正規表現システムは、月間100万以上のトランザクションを処理し、非常に負荷の高い状態で動作していましたので、パイプライン内で低い全体的なレイテンシを維持するために動的にスケーリングできる高可用性のシステムが重要でした。当時の小さなスタートアップとして、モデルサービングソリューションを構築する代わりに購入することにしました。当時、社内でのモデルオペレーションの専門知識はなく、MLエンジニアのエネルギーを製品内のモデルのパフォーマンス向上に集中させる必要がありました。これを念頭に置いて、私たちは解決策を探しました。 最初は、プロトタイピングに使用していた手作りの社内モデルホスティングソリューションをAWS SagemakerとHugging Faceの新しいモデルホスティング推論APIと比較して試してみました。データの保存にはGCPを使用し、モデルトレーニングにはGoogle Vertex Pipelinesを使用していたため、AWS Sagemakerへのモデルのエクスポートは不便でバグがありました。幸いなことに、Hugging Faceの設定は迅速かつ簡単であり、1週間以内に一部のトラフィックを処理することができました。Hugging Faceはそのまま動作し、この摩擦の低減により、私たちはこの道を進むことになりました。 約3か月にわたる評価期間の後、私たちはHugging Faceをモデルのホスティングに選びました。この期間中、トランザクションのボリュームを徐々に増やし、最悪のケースシナリオのボリュームに基づいた数々のシミュレートされた負荷テストを実施しました。このプロセスにより、システムを微調整し、パフォーマンスを監視し、トランザクションの拡張負荷を処理する推論APIの能力に自信を持つことができました。 技術的な能力を超えて、私たちはハギングフェイスのチームとの強い関係を築きました。彼らは単なるサービスプロバイダーではなく、私たちの目標と成果に投資しているパートナーであることを発見しました。コラボレーションの初期段階で、私たちは貴重な存在であるとわかる共有のSlackチャンネルを設置しました。彼らが問題に対して迅速に対応し、積極的な問題解決のアプローチを取る姿勢には特に感銘を受けました。彼らのエンジニアやCSMは、私たちの成功への取り組みと正しい方法での取り組みを常に示しました。これにより、最終的な選択をする時に私たちは追加の自信を得ることができました。…

デブセコプス:セキュリティをデブオプスのワークフローに統合する
この包括的なガイドでは、DevSecOpsの原則、利点、課題、実世界での使用例、およびベストプラクティスについて詳しく説明します

「Kognitosの創設者兼CEO、ビニー・ギル- インタビューシリーズ」
ビニー・ギルは、複数の役職と企業を横断する多様で幅広い業務経験を持っていますビニーは現在、Kognitosの創設者兼CEOであり、プログラミングを利用可能にし、企業の業務と顧客体験を最適化することに焦点を当てた会社ですビニーはコンピュータサイエンスの分野で多くの特許を持つ多作な発明家であり、[…]と信じています

「Vianaiの新しいオープンソースのソリューションがAIの幻覚問題に取り組む」
「AI、特に大規模言語モデル(LLM)が時折正確でない、または潜在的に有害な出力を生成することは秘密ではありませんこれらの異常は「AI幻覚」と呼ばれ、金融、評判、さらには法的な結果の固有のリスクのためにLLMの統合を検討している企業にとって重大な障壁となっていますこの重要な懸念に対応するために、Vianai Systemsは先駆者として...」

「複雑なエンジニアリング図面のためのOCRの使用」 「複雑なエンジニアリング図面のためのOCRの使用」という文になります
光学文字認識(OCR)は、ビジネスが文書処理を自動化する方法を革新しましたただし、技術の品質と精度はすべてのアプリケーションに適しているわけではありません処理される文書が複雑であるほど、精度は低下します特にエンジニアリング図面には特に当てはまります箱から出してすぐのOCR技術では、[…]

「LangchainとDeep Lakeでドキュメントを検索してください!」
イントロダクション langchainやdeep lakeのような大規模言語モデルは、ドキュメントQ&Aや情報検索の分野で大きな進歩を遂げています。これらのモデルは世界について多くの知識を持っていますが、時には自分が何を知らないかを知ることに苦労することがあります。それにより、知識の欠落を埋めるためにでたらめな情報を作り出すことがありますが、これは良いことではありません。 しかし、Retrieval Augmented Generation(RAG)という新しい手法が有望です。RAGを使用して、プライベートな知識ベースと組み合わせてLLMにクエリを投げることで、これらのモデルをより良くすることができます。これにより、彼らはデータソースから追加の情報を得ることができ、イノベーションを促進し、十分な情報がない場合の誤りを減らすことができます。 RAGは、プロンプトを独自のデータで強化することによって機能し、大規模言語モデルの知識を高め、同時に幻覚の発生を減らします。 学習目標 1. RAGのアプローチとその利点の理解 2. ドキュメントQ&Aの課題の認識 3. シンプルな生成とRetrieval Augmented Generationの違い 4. Doc-QnAのような業界のユースケースでのRAGの実践 この学習記事の最後までに、Retrieval Augmented Generation(RAG)とそのドキュメントの質問応答と情報検索におけるLLMのパフォーマンス向上への応用について、しっかりと理解を持つことができるでしょう。 この記事はデータサイエンスブログマラソンの一環として公開されました。 はじめに ドキュメントの質問応答に関して、理想的な解決策は、モデルに質問があった時に必要な情報をすぐに与えることです。しかし、どの情報が関連しているかを決定することは難しい場合があり、大規模言語モデルがどのような動作をするかに依存します。これがRAGの概念が重要になる理由です。…

「マーケティングにおける人工知能の短いガイド」
「デジタルマーケティングにおける人工知能の役割や、ビジネスにおける他のAIツールがデータに基づく意思決定に与える影響について学びましょう」
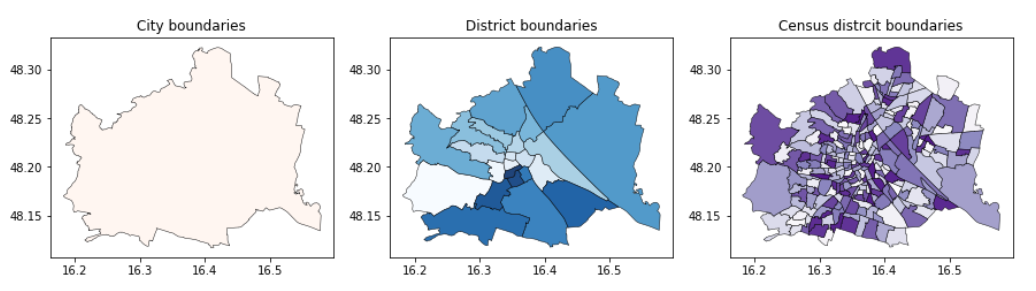
「ウィーンのオープンデータポータルを利用した都市緑地の平等性の評価」
特に、最近専門家や地方自治体の間で関心が高まっている都市開発の問題を提起しますこの問題は、緑の平等として知られる概念に関連しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.