Learn more about Search Results ドキュメンテーション - Page 15

- You may be interested
- ドメイン固有アプリケーションのためのLLM...
- BERT 101 – 最新のNLPモデルの解説
- 「AIと教育の公平性:ギャップを埋めるた...
- 「AIコントロールを手にして、サイバーセ...
- 「意思決定科学は静かに新しいデータサイ...
- チャットボットは学校での不正行為を助長...
- エンジニアにとって役立つ6つのリソース
- 気候変動との戦いをリードする6人の女性
- データサイエンスの愛好家が好むステーク...
- 「モノのインターネット」から「すべての...
- 「新しいHADARベースのイメージングツール...
- 複雑なテキスト分類のユースケースにおい...
- 「カスタムクエリを使用してビジネス特有...
- クロマに会ってください:LLMs用のAIネイ...
- 「深層学習による遺伝子制御の解明:オル...

「プロダクションでのあなたのLLMの最適化」
注意: このブログ投稿は、Transformersのドキュメンテーションページとしても利用可能です。 GPT3/4、Falcon、LLamaなどの大規模言語モデル(LLM)は、人間中心のタスクに取り組む能力を急速に向上させており、現代の知識ベース産業で不可欠なツールとして確立しています。しかし、これらのモデルを実世界のタスクに展開することは依然として課題が残っています: ほぼ人間のテキスト理解と生成能力を持つために、LLMは現在数十億のパラメータから構成される必要があります(Kaplanら、Weiら参照)。これにより、推論時のメモリ要件が増大します。 多くの実世界のタスクでは、LLMには豊富な文脈情報が必要です。これにより、推論中に非常に長い入力シーケンスを処理する能力が求められます。 これらの課題の核心は、特に広範な入力シーケンスを扱う場合に、LLMの計算およびメモリ能力を拡張することにあります。 このブログ投稿では、効率的なLLMの展開のために、現時点で最も効果的な技術について説明します: 低精度: 研究により、8ビットおよび4ビットの数値精度で動作することが、モデルのパフォーマンスに大幅な低下を伴わずに計算上の利点をもたらすことが示されています。 Flash Attention: Flash Attentionは、よりメモリ効率の高いアテンションアルゴリズムのバリエーションであり、最適化されたGPUメモリの利用により、高い効率を実現します。 アーキテクチャのイノベーション: LLMは常に同じ方法で展開されるため、つまり長い入力コンテキストを持つ自己回帰的なテキスト生成として、より効率的な推論を可能にする専用のモデルアーキテクチャが提案されています。モデルアーキテクチャの中で最も重要な進歩は、Alibi、Rotary embeddings、Multi-Query Attention(MQA)、Grouped-Query-Attention(GQA)です。 このノートブックでは、テンソルの視点から自己回帰的な生成の分析を提供し、低精度の採用の利点と欠点について包括的な探索を行い、最新のアテンションアルゴリズムの詳細な調査を行い、改良されたLLMアーキテクチャについて議論します。これを行う過程で、各機能の改善を示す実用的な例を実行します。 1. 低精度の活用 LLMのメモリ要件は、LLMを重み行列とベクトルのセット、およびテキスト入力をベクトルのシーケンスとして見ることで最も理解できます。以下では、重みの定義はすべてのモデルの重み行列とベクトルを意味するために使用されます。 この投稿の執筆時点では、LLMは少なくとも数十億のパラメータから構成されています。各パラメータは通常、float32、bfloat16、またはfloat16形式で保存される10進数の数値で構成されています。これにより、LLMをメモリにロードするためのメモリ要件を簡単に計算できます: X十億のパラメータを持つモデルの重みをロードするには、おおよそ4 *…

「Retrieval Augmented GenerationとLangChain Agentsを使用して、内部情報へのアクセスを簡素化する」
この投稿では、顧客が内部文書を検索する際に直面する最も一般的な課題について説明し、AWSサービスを使用して内部情報をより有用にするための生成型AI対話ボットを作成するための具体的なガイダンスを提供します組織内に存在するデータのうち、非構造化データが全体の80%を占めています[...]
「データサイエンスのワークフローをマスターする」
「定義からコミュニケーションまで、成功するデータサイエンスのワークフローを6つのステージで自信を持って進めるためのガイドです!」

「成功したプロンプトの構造の探索」
この記事では、著者がGPTConsoleのBirdとPixie AIエージェントのためのプログラマのハンドブックを読者に提供しています

モジュラーの共同創設者兼社長であるティム・デイビス- インタビューシリーズ
ティム・デイビスは、Modularの共同創設者兼社長ですModularは統合された、組み合わせ可能なツールのスイートであり、AIインフラストラクチャを簡素化し、チームがより迅速に開発、展開、イノベーションできるようにしますModularは、Pythonの優れた点とシステムを組み合わせることで、研究と製品化のギャップを埋める新しいプログラミング言語「Mojo」を開発することで最も知られています
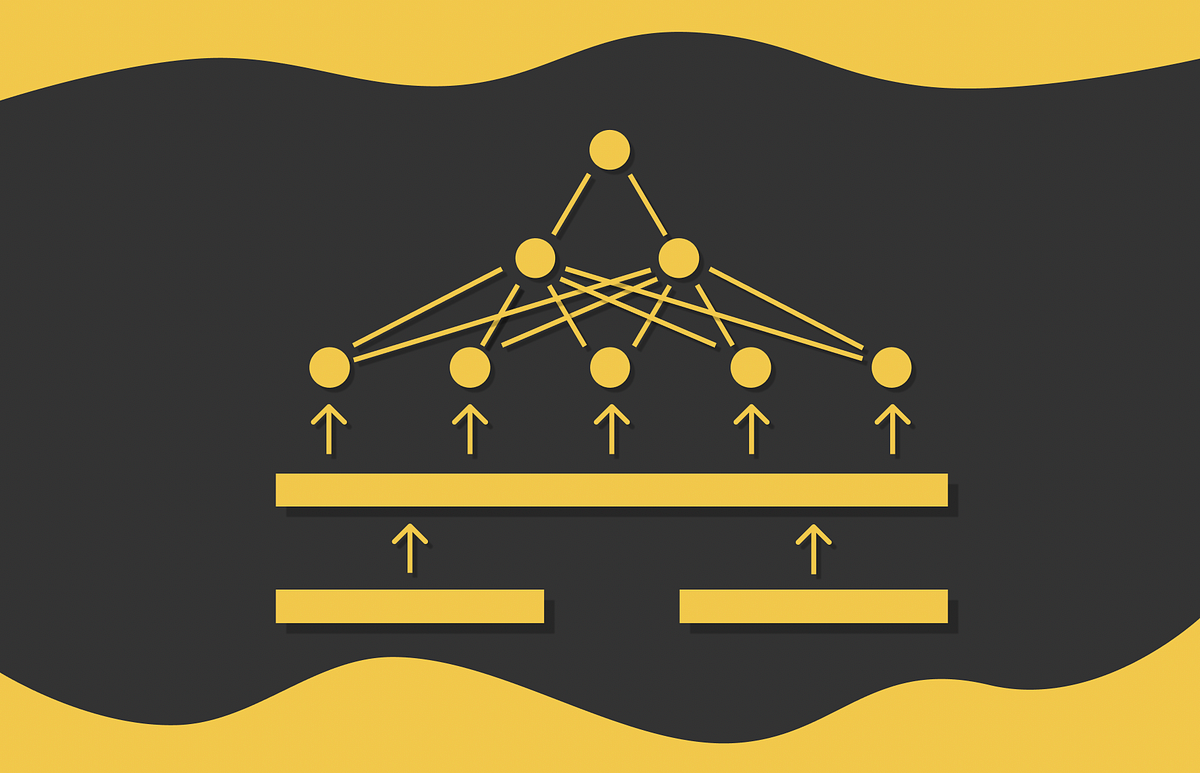
大規模言語モデル:SBERT
「トランスフォーマーが自然言語処理(NLP)において進化的な進歩を遂げたことは秘密ではありませんトランスフォーマーを基に、他の多くの機械学習モデルも進化していますその中の一つがBERTであり、主にいくつかの要素から構成されています...」

「SafeCoder対クローズドソースのコードアシスタント」
数十年にわたり、ソフトウェア開発者は、コード品質の向上と生産性の向上を支援するための手法、プロセス、ツールを設計してきました。たとえば、アジャイル、テスト駆動開発、コードレビュー、CI/CDなどは、今やソフトウェア業界の定番です。 Googleは「How Google Tests Software」(Addison-Wesley、2012)で、システムテストの最終テスト段階でバグを修正するコストが、ユニットテスト段階で修正するコストの1000倍高いと報告しています。これにより、チェーンの最初のリンクである開発者には、初めから品質の高いコードを書くという大きなプレッシャーがかかります。 生成型AIに関する大騒ぎがある一方で、コード生成は開発者が迅速に優れたコードを提供するのに有望な方法のようです。実際、早期の研究では、GitHub CopilotやAmazon CodeWhispererなどの管理されたサービスが、開発者の生産性を向上させるのに役立つことが示されています。 ただし、これらのサービスはユーザー固有の技術文化やプロセスにカスタマイズできないクローズドソースのモデルに依存しています。Hugging Faceは数週間前にSafeCoderをリリースし、この問題を解決しました。SafeCoderは、エンタープライズ向けのコードアシスタントソリューションであり、最新のモデル、透明性、カスタマイズ性、ITの柔軟性、プライバシーを提供します。 この記事では、SafeCoderをクローズドソースのサービスと比較し、当社のソリューションから期待できる利点を強調します。 最先端のモデル SafeCoderは現在、StarCoderモデルをベースに構築されています。StarCoderは、BigCode共同プロジェクト内で設計およびトレーニングされたオープンソースモデルのファミリーです。 StarCoderは、80以上のプログラミング言語でコード生成のためにトレーニングされた155億のパラメータモデルです。Multi-Query Attention(MQA)などの革新的なアーキテクチャの概念を使用してスループットを向上させ、レイテンシを低減させる技術を採用しています。この技術は、FalconとLLaMa 2モデルでも使用されています。 StarCoderは8192トークンのコンテキストウィンドウを持っており、より多くのコードを考慮して新しいコードを生成するのに役立ちます。また、コードの末尾に新しいコードを追加するだけでなく、コードの途中にも挿入することができます。 さらに、HuggingChatと同様に、SafeCoderは時間の経過とともに新しい最先端のモデルを導入し、シームレスなアップグレードパスを提供します。 残念ながら、クローズドソースのコードアシスタントサービスは、基礎となるモデル、その機能、およびトレーニングデータに関する情報を共有していません。 透明性 SafeCoderは、チンチラのスケーリング法則に従って、1兆(1,000億)のコードトークンでトレーニングされたコンピューティング最適化モデルです。これらのトークンは、許可されたオープンソースリポジトリから抽出された2.7テラバイトのデータセットで構築されています。オプトアウトのリクエストへの対応に努め、リポジトリ所有者が自分のコードがデータセットの一部であるかどうかを確認するためのツールも開発しました。 透明性の精神に則り、研究論文ではモデルのアーキテクチャ、トレーニングプロセス、詳細なメトリクスについて開示しています。 残念ながら、クローズドソースのサービスは、「数十億行のコードでトレーニングされました」といった曖昧な情報にとどまっています。私たちの知る限りでは、利用可能なメトリクスはありません。 カスタマイズ性…

「データサイエンスのデータ管理原則」
「基礎に戻る:データサイエンティストが知っておくべき主要なデータ管理の原則の理解」

「トップのGPTとAIコンテンツ検出器」
GPTZero 教育者やAI生成文章の特定に興味のある他の人々は、GPTZeroというツールを使用することができます。 GPTZeroには、論文が機械生成されているかどうかを示す盗作スコアが含まれています。ツールはAI生成のテキストを個別に下線引きして表示するため、利用者の利便性に配慮しています。 GPTZeroのバッチアップロード機能により、ユーザーは複数のファイルを同時にアップロードすることができるため、教育者は一度に複数のクラスの作業を迅速に評価することができます。 APIにより、組織はGPTZero技術を既存のシステムに簡単に統合することができます。APIの実装は簡単であり、ビジネスはエンドポイントを個別の顧客に合わせるための統合支援を提供しています。 APIのドキュメントはオンラインで利用者が閲覧できます。 NYUやPurdueを含む多くの世界の大学で、GPTZeroはAI生成テキストの特定に効果的な手法であることがわかっています。 GPTZeroチームは教師向けの製品を向上させるために常に努力しており、K16 SolutionsやCanvasなどの企業と協力しています。 ZeroGPT.cc ZeroGPTは、高度なアルゴリズム、機械学習アルゴリズム、および自然言語処理手法を使用して、AI生成素材を正確に認識する無料のAIコンテンツ検出ツールです。 AI検出器は、人間とAIによって作成されたテキストを含む広範なデータセットでトレーニングされており、それぞれの執筆スタイルの特徴的なパターンと特徴を理解し認識することができます。 ユーザーがテキストをボックスに入力すると、ZeroGPTは正確な分析を行い、人間が書いたテキストとAI / GPTが生成したテキストの割合を示す結果を返します。 ZeroGPTは迅速でほぼ瞬時の結果を提供し、信頼性のあるテキスト検出のためにさまざまな言語で動作します。 この柔軟なソフトウェアは、GPT-4、GPT-3、GPT-2、LLaMA、Google Bardなど、これらのモデルに基づいて構築されたさまざまなAIサービスの結果を特定することができます。 また、ZeroGPTはユーザーの情報を保持しません。したがって、個人情報は安全です。 ライターや学生、教授、フリーランサー、コピーライターは、ZeroGPTを使用してAI生成素材を特定することで利益を得ることができます。 ZeroGPT Detector 無料のZeroGPT Detectorを使用すると、AIが作成した文章かどうかを判断することができます。機械学習と自然言語処理を使用して、コンテンツの一部が人間または人工知能によって作成されたかどうかを判断します。…
施設分散問題:混合整数計画モデル
いくつかの施設配置問題では、施設を配置する必要があります他の施設に影響を与えたり、悪影響を及ぼしたりしないようにするために、施設の位置を決める必要がありますリスク軽減の動機によって駆動されるかどうかに関係なく...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.