Learn more about Search Results コーパス - Page 15

- You may be interested
- 多言語での音声合成の評価には、SQuIdを使...
- 「MATLABとAmazon SageMakerによる機械学習」
- タイムシリーズの異常値のデマイスティフ...
- AIサージ:Stability AIのCEOは、2年以内...
- 「アソシエーテッド・プレスがジャーナリ...
- 「科学、情熱、そして多目的最適化の未来」
- 複雑なテキスト分類のユースケースにおい...
- ニューラル輝度場の不確実性をどのように...
- このAIニュースレターは、あなたが必要と...
- PoisonGPT ハギングフェイスのLLMがフェイ...
- 自分の脳の季節性を活用した、1年間のデー...
- 「スタンフォード大学の新しいAI研究は、...
- 「Data Enthusiasts向けにエキサイティン...
- フィリップスは、Amazon SageMakerをベー...
- パーソナライズされたAIの簡単な作成方法...

XLang NLP研究所の研究者がLemurを提案:テキストとコードの能力をバランスさせた最先端のオープンプリトレーニング済み大規模言語モデル
言語とテクノロジーの交差点によってますます推進される世界において、多目的かつ強力な言語モデルの需要はかつてなく高まっています。従来の大規模言語モデル(LLM)は、テキストの理解やコーディングのタスクに優れていましたが、両者の間に調和の取れたバランスを築くことはめったにありませんでした。この不均衡は、テキストの推論やコーディングの能力をシームレスにナビゲートできるモデルの市場においてギャップを残しました。そこで、このギャップを埋めることを目指す、オープンな事前学習済みおよび監督されたファインチューニングされたLLMの分野に革新的な貢献をする2つのプロジェクト、LemurとLemur-chatが登場します。 テキストとコードの両方を適切に処理できる言語モデルを作成することは、長年の課題でした。既存のLLMは通常、テキストの理解またはコーディングのタスクに特化していましたが、両方に優れているものはほとんどありませんでした。この特化は、開発者や研究者が一方の領域で優れているモデルと他方では不十分なモデルの選択を迫られることになりました。その結果、理解、推論、計画、コーディング、コンテキストの基礎を含む多面的なスキルセットを提供できるLLMの需要が生じました。 従来のLLMの形でいくつかの解決策が存在しますが、その限界は明白でした。業界には、テキストとコードに関連するタスクの複雑な要求を真にバランスさせることができるモデルが不足していました。これにより、言語モデルエージェントの風景には、理解、推論、コーディングの統合的なアプローチが必要とされる空白が生じました。 XLang LabとSalesforce Researchの共同研究によって率いられるLemurプロジェクトは、この言語モデル技術における重要なギャップを埋めることを目指しています。LemurとLemur-chatは、テキストとコードに関連するタスクの両方に優れた性能を発揮するオープンで事前学習済みで監督されたファインチューニングされたLLMを開発する先駆的な試みを表しています。この取り組みの基盤は、Llama 2の広範な事前学習による、約1000億行のコード集中データのコーパスです。この事前学習フェーズの後には、公開された教育および対話データの約30万のインスタンスでの監督されたファインチューニングが続きます。その結果、テキストの推論と知識のパフォーマンスを競争力を維持しながら、コーディングと基礎づけの能力が向上した言語モデルが得られます。 LemurとLemur-chatの性能指標は、その能力を証明しています。Lemurは、コーディングのベンチマークで他のオープンソース言語モデルを凌駕し、そのコーディング能力を示しています。同時に、テキストの推論と知識ベースのタスクにおいて競争力を維持し、その多目的なスキルセットを示しています。一方、Lemur-chatは、さまざまな次元で他のオープンソースの監督されたファインチューニングモデルを大きく上回る優れた能力を示しており、テキストとコードを結ぶ会話の文脈での優れた能力を示しています。 Lemurプロジェクトは、XLang LabとSalesforce Researchの共同研究によるものであり、Salesforce Research、Google Research、Amazon AWSの寛大な寄付による支援を受けています。バランスの取れたオープンソース言語モデルに向けた旅はまだ途中ですが、Lemurの貢献は既に言語モデル技術の風景を変え始めています。テキストとコードに関連するタスクの両方で優れた性能を発揮するモデルを提供することで、Lemurは、言語とテクノロジーの複雑な交差点を航海しようとする開発者、研究者、組織にとって、強力なツールを提供します。 まとめると、Lemurプロジェクトは、言語モデルの世界における革新の象徴です。テキストとコードに関連するタスクを調和的にバランスさせる能力は、この分野における長年の課題に取り組んできました。Lemurは、さらなる研究を推進し、オープンソース言語モデルのより強力でバランスの取れた基盤を確立することを約束しながら、進化し続けることで、言語モデル技術の未来はこれまで以上に明るく多目的になります。

「インセプション、MBZUAI、そしてCerebrasが『Jais』をオープンソース化:世界最先端のアラビア語大規模言語モデル」の記事が公開されました
大規模言語モデル(GPT-3など)とその社会への影響は、大いに関心と議論の的です。大規模言語モデルは、自然言語処理(NLP)の分野を大きく前進させました。それらは、翻訳、感情分析、要約、質問応答など、さまざまな言語関連のタスクの精度を向上させました。大規模言語モデルによって強化されたチャットボットや仮想アシスタントは、複雑な会話を処理する能力が向上しています。これらは、顧客サポート、オンラインチャットサービス、一部のユーザーにとってはさえ仲間として使用されています。 アラビア語の大規模言語モデル(LLM)を構築することは、アラビア語の特徴やその方言の多様性のために独自の課題を持ちます。他の言語の大規模言語モデルと同様に、アラビア語のLLMはトレーニングデータからバイアスを受け継ぐ可能性があります。これらのバイアスに対処し、アラビア語のコンテキストでのAIの責任ある使用を確保することは、継続的な関心事です。 Inception、Cerebras、Mohamed bin Zayed University of Artificial Intelligence(UAE)の研究者たちは、新しいアラビア語ベースの大規模言語モデルJaisとJais-chatを紹介しました。彼らのモデルは、GPT-3の生成的事前学習アーキテクチャに基づいており、たった13Bのパラメータのみを使用しています。 彼らの主な課題は、モデルのトレーニングのための高品質なアラビア語データを入手することでした。英語のデータに比べて、2兆トークンまでのコーパスが利用可能である一方、アラビア語のコーパスはかなり小さいものでした。コーパスとは、言語学、自然言語処理(NLP)、テキスト分析のための研究や言語モデルのトレーニングに使用される、大規模で構造化されたテキストのコレクションです。コーパスは、言語のパターン、意味論、文法などを研究するための貴重なリソースとして活用されます。 彼らは、これを解決するために、限られたアラビア語の事前トレーニングデータを豊富な英語の事前トレーニングデータで補完するためにバイリンガルモデルをトレーニングしました。彼らは、Jaisを3950億トークン、その中に72 billionのアラビア語トークンと2320億の英語トークンを含むように事前トレーニングしました。彼らは、高品質なアラビア語データを生成するために、徹底的なデータフィルタリングとクリーニングを含む専門のアラビア語テキスト処理パイプラインを開発しました。 彼らは、彼らのモデルの事前学習と微調整の機能が、既知のすべてのオープンソースのアラビア語モデルを上回り、より大規模なデータセットでトレーニングされた最新のオープンソースの英語モデルと同等であると述べています。LLMの固有の安全上の懸念を考慮し、彼らはさらに安全志向の指示で微調整しました。安全プロンプト、キーワードベースのフィルタリング、外部分類器の形で追加のガードレールを設けました。 彼らは、Jaisが中東のNLPとAIの景観の重要な進化と拡大を表していると述べています。それはアラビア語の理解と生成を前進させ、主権的でプライベートな展開オプションを持つ地元のプレーヤーを支援し、応用とイノベーションの活発なエコシステムを育成します。この研究は、より言語的に包括的で文化的に意識の高い時代を築くためのデジタルとAIの転換の広範な戦略的イニシアチブをサポートしています。

「LLMの力を活用する:ゼロショットとフューショットのプロンプティング」
はじめに LLMのパワーはAIコミュニティで新たなブームとなりました。GPT 3.5、GPT 4、BARDなどのさまざまな生成型AIソリューションが異なるユースケースで早期採用されています。これらは質問応答タスク、クリエイティブなテキストの執筆、批判的分析などに使用されています。これらのモデルは、さまざまなコーパス上で次の文予測などのタスクにトレーニングされているため、テキスト生成に優れていると期待されています。 頑健なトランスフォーマーベースのニューラルネットワークにより、モデルは分類、翻訳、予測、エンティティの認識などの言語に基づく機械学習タスクにも適応することができます。したがって、適切な指示を与えることで、データサイエンティストは生成型AIプラットフォームをより実践的で産業的な言語ベースのMLユースケースに活用することが容易になりました。本記事では、プロンプティングを使用した普及した言語ベースのMLタスクに対する生成型LLMの使用方法を示し、ゼロショットとフューショットのプロンプティングの利点と制限を厳密に分析することを目指します。 学習目標 ゼロショットとフューショットのプロンプティングについて学ぶ。 例として機械学習タスクのパフォーマンスを分析する。 フューショットのプロンプティングをファインチューニングなどのより高度な技術と比較評価する。 プロンプティング技術の利点と欠点を理解する。 この記事はData Science Blogathonの一部として公開されました。 プロンプティングとは? まず、LLMを定義しましょう。大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ、複数のトランスフォーマーとフィードフォワードニューラルネットワークの層で構築されたディープラーニングシステムです。これらはさまざまなソースの大規模なデータセットでトレーニングされ、テキストを理解し生成するために構築されています。言語翻訳、テキスト要約、質問応答、コンテンツ生成などが例です。LLMにはさまざまなタイプがあります:エンコーダのみ(BERT)、エンコーダ+デコーダ(BART、T5)、デコーダのみ(PALM、GPTなど)。デコーダコンポーネントを持つLLMは生成型LLMと呼ばれ、これがほとんどのモダンなLLMの場合です。 生成型LLMに特定のタスクを実行させるには、適切な指示を与えます。LLMは、プロンプトとも呼ばれる指示に基づいてエンドユーザーに応答するように設計されています。ChatGPTなどのLLMと対話したことがある場合、プロンプトを使用したことがあります。プロンプティングは、モデルが望ましい応答を返すための自然言語のクエリで私たちの意図をパッケージングすることです(例:図1、出典:Chat GPT)。 以下のセクションでは、ゼロショットとフューショットの2つの主要なプロンプティング技術を詳しく見ていきます。それぞれの詳細と基本的な例を見ていきましょう。 ゼロショットプロンプティング ゼロショットプロンプティングは、生成型LLMに特有のゼロショット学習の特定のシナリオです。ゼロショットでは、モデルにラベル付きのデータを提供せず、完全に新しい問題に取り組むことを期待します。例えば、適切な指示を提供することにより、新しいタスクに対してChatGPTをゼロショットプロンプティングに使用します。LLMは多くのリソースからコンテンツを理解しているため、未知の問題に適応することができます。いくつかの例を見てみましょう。 以下は、テキストをポジティブ、ニュートラル、ネガティブの感情クラスに分類するための例です。 ツイートの例 ツイートの例は、Twitter US…

「セマンティックカーネルへのPythonistaのイントロ」
ChatGPTのリリース以来、大規模言語モデル(LLM)は産業界とメディアの両方で非常に注目されており、これによりLLMを活用しようとする前例のない需要が生まれました...
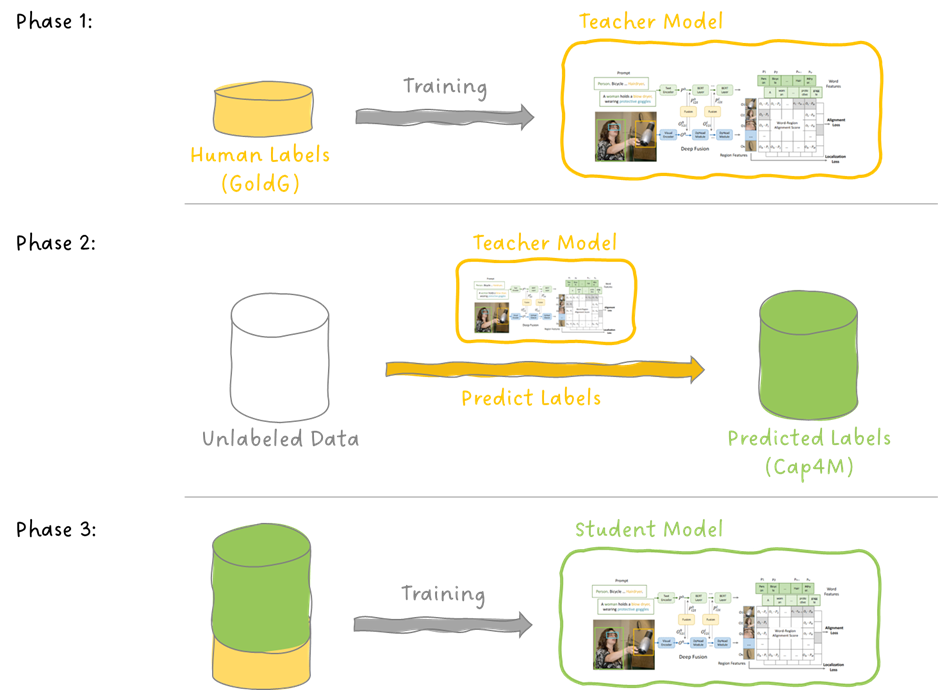
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げます...
情報抽出の始まり:キーワードを強調し、頻度を取得する
毎日利用可能な情報量が増えるにつれて、関連する統計情報を迅速に収集する能力は、関係マッピングや獲得にとって重要です
「LLMガイド、パート1:BERT」 LLMガイド、パート1:BERTについてのガイドです
2017年は、Transformerモデルが初めて登場した機械学習の歴史的な年でした多くのベンチマークで驚くべきパフォーマンスを発揮し、さまざまな用途に適しているようです...

「GPTの内部- I:テキスト生成の理解」
「さまざまなドメインの同僚と定期的に関わりながら、データサイエンスの背景をほとんど持たない人々に機械学習の概念を伝えるという課題に取り組んでいますここでは、私は試みています...」

ドメイン特化の大規模言語モデルの6つの例
「GoogleのBardやOpenAIのChatGPTなどの大規模言語モデルを使った経験があるほとんどの人々は、一般的で業界特化していないLLM(Large Language Model)と一緒に作業してきましたしかし、時間が経つにつれて、多くの業界がこれらのモデルの力を認識してきましたそれによって、彼らは理解するようになりました...」

「GPTモデルの信頼性に関する詳細な分析」
最近のグローバルな世論調査では、半数以上の回答者が、この新興技術を金融計画や医療ガイダンスなどの機密性の高い分野に利用すると回答しました。しかし、幻覚、ディスインフォメーション、バイアスなどの問題があるという懸念もあります。機械学習の最近の発展により、特に大規模言語モデル(LLMs)は、チャットボットや医療診断からロボットまで、さまざまな分野で利用されています。言語モデルの評価とその能力と限界をより良く理解するために、異なるベンチマークが開発されています。例えば、GLUEやSuperGLUEのような、全般的な言語理解を評価するための標準化されたテストが開発されています。 最近では、HELMが多様なユースケースと指標でLLMsの包括的なテストとして発表されました。LLMsがますます多くの分野で使用されるにつれて、その信頼性についての疑念が高まっています。既存のLLMの信頼性評価は、主に頑健性や過信などの要素に焦点を当てた狭義の評価です。 さらに、大規模言語モデルの能力の向上は、LLMsの信頼性の問題を悪化させる可能性があります。特に、GPT-3.5とGPT-4は、対話向けに最適化された特殊な最適化手法により、指示に従う能力が向上しています。これにより、ユーザーはトーンや役割などの適応や個別化の変数をカスタマイズすることができます。テキストの埋め込みにしか適していなかった古いモデルと比較して、改善された機能により、質問応答やディスカッション中の短いデモンストレーションを通じた文脈学習などの機能が追加されます。 GPTモデルの信頼性を徹底的に評価するために、一部の研究者グループは、さまざまなシナリオ、タスク、メトリック、データセットを用いて、8つの信頼性視点に絞り込み評価を行いました。グループの最も重要な目標は、GPTモデルの頑健性を困難な状況で測定し、さまざまな信頼性の文脈でのパフォーマンスを評価することです。このレビューでは、一貫性を確認し複製可能な結果を得るために、GPT-3.5とGPT-4モデルに焦点を当てています。 GPT-3.5とGPT-4について話しましょう GPT-3の後継であるGPT-3.5とGPT-4により、新しい形の相互作用が可能になりました。これらの最先端モデルは、スケーラビリティと効率性の向上、およびトレーニング手法の改善を経ています。 GPT-3.5やGPT-4のような事前学習済みの自己回帰(デコーダのみ)トランスフォーマーは、先行モデルと同様に、左から右にトークンごとにテキストトークンを生成し、それらのトークンに対して行った予測をフィードバックします。GPT-3に比べて改善されたものの、GPT-3.5のモデルパラメータの数は1750億のままです。GPT-4のパラメータセットの正確なサイズや事前トレーニングコーパスの詳細は不明ですが、GPT-3.5よりも大きな財務投資がトレーニングに必要です。 GPT-3.5とGPT-4は、次のトークンの確率を最大化するために従来の自己回帰事前トレーニング損失を使用します。さらに、LLMsが指示に従い、人間の理想と一致する結果を生成することを確認するために、GPT-3.5とGPT-4は人間のフィードバックからの強化学習を使用します。 これらのモデルは、OpenAI APIクエリングシステムを使用してアクセスすることができます。APIコールを介して温度や最大トークンを調整することで、出力を制御することが可能です。科学者たちはまた、これらのモデルが静的ではなく変化することを指摘しています。実験では、安定したバリアントのモデルを使用して信頼性の結果を保証しています。 毒性、ステレオタイプに対するバイアス、敵対的攻撃に対する頑健性、OODインスタンスに対する頑健性、敵対的なデモンストレーションに対する頑健性、プライバシー、倫理、公平性の観点から、研究者はGPT-4とGPT-3.5の信頼性に関する詳細な評価を行っています。一般的に、GPT-4は全般的にGPT-3.5よりも優れた性能を示しています。ただし、GPT-4は指示により忠実に従うため、操作が容易になる可能性があり、ジェイルブレイキングや誤解を招く(敵対的な)システムのプロンプトやデモンストレーションに対して新しいセキュリティ上の懸念が生じます。さらに、これらの例は、モデルの信頼性に影響を与えるさまざまな特性や入力のプロパティがあることを示しており、追加の調査が必要です。 これらの評価に基づいて、GPTモデルを使用してLLMsを保護するために、次の研究の方向性が検討される可能性があります。より多くの共同評価。GPTモデルのさまざまな信頼性の視点を検討するために、1-2回のディスカッションなどの静的なデータセットを主に使用しています。巨大な言語モデルが進化するにつれ、これらの脆弱性がより深刻になるかどうかを判断するために、対話型ディスカッションでLLMsを調査することが重要です。 文脈による学習の誤認は、偽のデモンストレーションやシステムプロンプト以外にも大きな問題です。これらは、モデルの弱点をテストし、最悪のケースでのパフォーマンスを把握するために、さまざまなジェイルブレイキングシステムプロンプトや偽(敵対的な)デモを提供します。対話に偽の情報を意図的に注入することで、モデルの出力を操作することができます(いわゆる「ハニーポット会話」)。さまざまなバイアスの形式に対するモデルの感受性を観察することは魅力的です。 関連する敵を考慮した評価。ほとんどの研究は、各シナリオで1つの敵のみを考慮に入れていますが、実際には、経済的なインセンティブが十分にあれば、様々なライバルが結託してモデルを騙すことが可能です。そのため、協調的かつ秘密裏な敵対的行動に対するモデルの潜在的な感受性を調査することは重要です。 特定の設定での信頼性の評価。感情分類やNLIタスクなどの標準的なタスクは、ここで提示された評価においてGPTモデルの一般的な脆弱性を示しています。法律や教育などの分野でGPTモデルが広く使用されていることを考慮して、これら特定のアプリケーションにおける弱点を評価することは重要です。 GPTモデルの信頼性を確認する。LLMの経験的な評価は重要ですが、特に安全性の重要なセクターでは、保証が欠けることがしばしばあります。さらに、その不連続な構造により、GPTモデルの厳密な検証が困難になります。具体的な機能に基づいた保証と検証を提供したり、モデルの抽象化に基づいた検証を提供したり、ディスクリートな空間を対応する連続的な空間(意味の保持を持つ埋め込み空間など)にマッピングして検証を行うなど、難しい問題をより管理しやすいサブ問題に分割することができます。 GPTモデルを保護するための追加情報と推論分析の組み込み。統計のみに基づいているGPTモデルは改善する必要があり、複雑な問題を論理的に推論することはできません。モデルの結果の信頼性を保証するために、ドメイン知識と論理的推論の能力を言語モデルに提供し、基本的なドメイン知識や論理を満たすように結果を保護することが必要かもしれません。 ゲーム理論に基づいたGPTモデルの安全性を確保する。作成時に使用される「役割プレイ」のシステムプロンプトは、モデルが役割を切り替えたり操作したりするだけで簡単に騙されることを示しています。これは、GPTモデルの対話中にさまざまな役割を作り出して、モデルの応答の一貫性を保証し、モデルが自己矛盾に陥ることを防ぐためのものです。特定のタスクを割り当てて、モデルが状況を徹底的に理解し、信頼性のある結果を提供することが可能です。 特定のガイドラインと条件に基づいてGPTのバージョンをテストする。モデルは一般的な適用性に基づいて評価されますが、ユーザーにはセキュリティや信頼性のニーズがあり、それを考慮する必要があります。したがって、ユーザーのニーズや指示を特定の論理空間や設計コンテキストにマッピングし、出力がこれらの基準を満たしているかどうかを評価することは、モデルの監査をより効率的かつ効果的に行うために不可欠です。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.