Learn more about Search Results the Hub - Page 159

- You may be interested
- 新しい人工知能(AI)の研究アプローチは...
- 「効果的なマーケティング戦略開発のため...
- 「共通テーブル式を使ってSQLロジックを向...
- データサイエンティストとは具体的に何を...
- 「ゲーミングからAIへ:NvidiaのAI革命に...
- 「データエンジニア vs データサイエンテ...
- クラウドインスタンスのスタートアップス...
- 5つの最高のDeepfake検出ツールと技術(20...
- 「AIを活用して国連の持続可能な開発目標...
- アプリケーションの近代化における生成AI...
- You.comは、複雑な数学や科学の質問に対し...
- 「蒸留されたアイデンティティの傾向最適...
- 新しいSHAPプロット:バイオリンプロット...
- 「リコメンデーションシステムにおける2つ...
- マイクロソフトAI研究チームが提案する「A...

中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
大規模言語モデル(LLM)には、GPT-3、PaLM、OPT、BLOOM、GLM-130Bなどが含まれます。これらのモデルは、言語に関してコンピュータが理解し、生成できる可能性の限界を大きく押し上げています。最も基本的な言語アプリケーションの一つである質問応答も、最近のLLMの突破によって大幅に改善されています。既存の研究によると、LLMのクローズドブックQAおよびコンテキストに基づくQAのパフォーマンスは、教師ありモデルのものと同等であり、LLMの記憶容量に対する理解に貢献しています。しかし、LLMにも有限な容量があり、膨大な特別な知識が必要な問題に直面すると、人間の期待には及びません。したがって、最近の試みでは、検索やオンライン検索を含む外部知識を備えたLLMの構築に集中しています。 たとえば、WebGPTはオンラインブラウジング、複雑な問い合わせに対する長い回答、同等に役立つ参照を行うことができます。人気があるにもかかわらず、元のWebGPTアプローチはまだ広く採用されていません。まず、多数の専門家レベルのブラウジング軌跡の注釈、よく書かれた回答、および回答の優先順位のラベリングに依存しており、これらは高価なリソース、多くの時間、および広範なトレーニングが必要です。第二に、システムにウェブブラウザとのやり取り、操作指示(「検索」、「読む」、「引用」など)を与え、オンラインソースから関連する材料を収集させる行動クローニングアプローチ(すなわち、模倣学習)は、基本的なモデルであるGPT-3が人間の専門家に似ている必要があります。 最後に、ウェブサーフィンのマルチターン構造は、ユーザーエクスペリエンスに対して過度に遅いことがあり、WebGPT-13Bでは、500トークンのクエリに対して31秒かかります。本研究の清華大学、北京航空航天大学、Zhipu.AIの研究者たちは、10億パラメータのジェネラル言語モデル(GLM-10B)に基づく、高品質なウェブエンハンスド品質保証システムであるWebGLMを紹介します。図1は、その一例を示しています。このシステムは、効果的で、手頃な価格で、人間の嗜好に敏感であり、最も重要なことに、WebGPTと同等の品質を備えています。システムは、LLM-拡張検索器を含む、いくつかの新しいアプローチや設計を使用して、良好なパフォーマンスを実現しています。精製されたリトリーバーと粗い粒度のウェブ検索を組み合わせた2段階のリトリーバーである。 GPT-3のようなLLMの能力は、適切な参照を自発的に受け入れることです。これは、小型の密集リトリーバーを改良するために洗練される可能性があります。引用に基づく適切なフィルタリングを使用して高品質のデータを提供することで、LLMはWebGPTのように高価な人間の専門家に頼る必要がありません。オンラインQAフォーラムからのユーザーチャムアップシグナルを用いて教えられたスコアラーは、さまざまな回答に対する人間の多数派の嗜好を理解することができます。 図1は、WebGLMがオンラインリソースへのリンクを含むサンプルクエリに対する回答のスナップショットを示しています。 彼らは、適切なデータセットアーキテクチャがWebGPTの専門家ラベリングに比べて高品質のスコアラーを生成できることを示しています。彼らの定量的な欠損テストと詳細な人間評価の結果は、WebGLMシステムがどれだけ効率的かつ効果的かを示しています。特に、WebGLM(10B)は、彼らのチューリングテストでWebGPT(175B)を上回り、同じサイズのWebGPT(13B)よりも優れています。Perplexity.aiの唯一の公開可能なシステムを改善するWebGLMは、この投稿時点で最高の公開可能なウェブエンハンスドQAシステムの一つです。結論として、著者らは次のことを提供しています。・人間の嗜好に基づく、効果的なウェブエンハンスド品質保証システムであるWebGLMを構築しました。WebGPT(175B)と同等のパフォーマンスを発揮し、同じサイズのWebGPT(13B)よりもはるかに優れています。 WebGPTは、LLMsと検索エンジンによって動力を与えられた人気システムであるPerplexity.aiをも凌駕します。•彼らは、WebGLMの現実世界での展開における制限を特定しています。彼らは、ベースラインシステムよりも効率的でコスト効果の高い利点を実現しながら、高い精度を持つWebGLMを可能にするための新しい設計と戦略を提案しています。•彼らは、Web強化QAシステムを評価するための人間の評価メトリックを定式化しています。広範な人間の評価と実験により、WebGLMの強力な能力が示され、システムの将来的な開発についての洞察が生成されました。コードの実装はGitHubで利用可能です。

Pythonで絶対に犯してはいけない10の失敗
Pythonを学び始めると、多くの場合、悪い習慣に遭遇することがありますこの記事では、Python開発者としてのレベルを上げるためのベストプラクティスを学びます私が覚えているのは、私が...

プロジェクトゲームフェイスをご紹介します:ハンズフリーで、AIにより動くゲーミングマウス
新しいオープンソースのハンズフリーゲーミングマウス、プロジェクトゲームフェイスは、ゲームをよりアクセスしやすくする可能性があります

I/O 2023 で発表した100のこと
Google I/O 2023はニュースとローンチで満ち溢れていましたここではI/Oで発表された100のことを紹介します

洪水予測により、より多くの人々が安全に過ごせるよう支援する
AIを活用した洪水ハブは、世界約80カ国に拡大しています
欠陥が明らかにされる:MLOpsコース作成の興味深い現実
不完全なものが明らかにされる舞台裏バッチ特徴ストアMLパイプラインMLプラットフォームPythonGCPGitHub ActionsAirflowMLOpsCI/CDコース

「Storytelling with Data」によると、データの視覚化をすぐに改善するためのMatplotlibのヒント
「Storytelling with Data」(Cole Nussbaumer Knaflic著)で得た教訓に基づいて、Matplotlibとseabornのデータ可視化を改善する方法

Gorillaに会ってください:UCバークレーとMicrosoftのAPI拡張LLMは、GPT-4、Chat-GPT、およびClaudeを上回ります
モデルは、Torch Hub、TensorFlow Hub、およびHuggingFaceからのAPIによって拡張されています
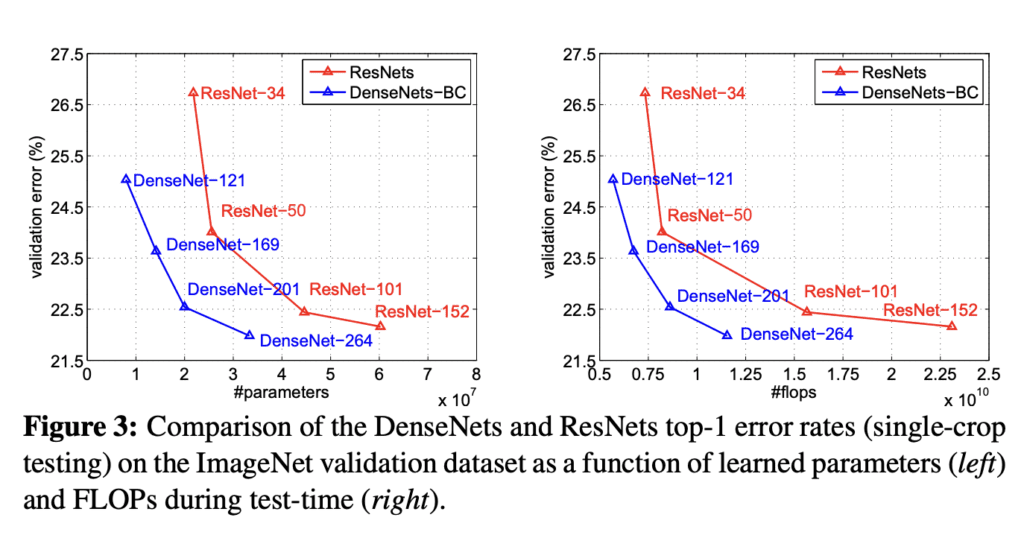
FLOPsとMACsを使用して、Deep Learningモデルの計算効率を計算する
この記事では、その定義、違い、およびPythonパッケージを使用してFLOPsとMACsを計算する方法について学びます

通貨為替レートの予測のためのSARIMAモデル
はじめに 通貨の為替レート予測とは、ある通貨の価値が他の通貨に対して将来的にどのように変化するかを予測することです。通貨の予測は、人々、企業、そして金融機関が賢明な金融判断を下すのに役立ちます。使用できる予測技術の1つはSARIMAです。 SARIMAは、季節的なパターンを持つ時系列データを推定するための優れた時系列予測技術です。 SARIMAは、過去と現在の時系列データの関連性をモデル化し、データ内のパターンを認識することによって機能します。 SARIMAは、傾向や季節性を捉えるためのさまざまな自己回帰(AR)モデルや移動平均(MA)モデル、および差分を利用します。 「季節性」とは、日々、週次、年次など、一定期間にわたって規則的に予測可能なデータの変動を指します。 為替レートの変化を予測することで、通貨価値の変化についてより正確な情報を得ることができます。 では、この記事の手順に従って予測を行いましょう。 学習目標 歴史データのパターンとトレンドを特定することにより、個人、企業、金融機関が市場動向を予測するのに役立ちます。 通貨の変動に関連する潜在的なリスクを特定することにより、リスクを軽減することができます。 通貨変換を最適化するために、最適な通貨変換時期を特定することができます。 将来の為替レートの方向性に関する情報を提供することにより、意思決定を改善することができます。 これらの目的に基づいて、SARIMAを使用してモデルを開発し、季節的なデータのパターンを集計して将来的な値のより正確な予測を行います。 この記事は、Data Science Blogathonの一部として公開されました。 ステップ1:ライブラリのインポート !pip install pmdarima from pmdarima.arima import…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.