Learn more about Search Results 調査 - Page 155

- You may be interested
- 「AIにおけるプロダクションシステムとは...
- 『Generative AIがサイバーセキュリティを...
- 「DreamPose」というAIフレームワークを使...
- 「Amazon SageMakerの最新機能を使用する...
- 「野心的なAI規制に対する力強いプロセス...
- 基本に戻る ウィーク4:高度なトピックと展開
- 「PIXART-αに会ってください:画像生成の...
- SetFit プロンプトなしで効率的なフューシ...
- 研究ライフサイクルの中心に倫理的な原則...
- 「NTUとSenseTimeの研究者が提案するSHERF...
- 「Amazon SageMakerを使用して、Rayベース...
- 「高速なスピン波によってマグノニックコ...
- 「パンダとPythonでデータの整理をマスタ...
- AIはクリエイティブな思考のタスクで人間...
- 「LegalBenchとは:英語の大規模言語モデ...

コールセンターにおけるAIソフトウェアが顧客サービスを革命化します
人工知能(AI)技術の急速な進歩により、チャットボットの導入を特に受けた顧客サービスとサポートに変革的なシフトがもたらされました。通信、保険、銀行、公共事業、政府機関など、さまざまな業界が、今後数年間でAIによるソリューションの導入を進める予定です。この次世代の自動化されたサポートシステムの提唱者たちは、比類のない利益を想像していますが、その他の人々は潜在的な落とし穴について懸念を表明しています。この記事では、コールセンターにおけるAIの影響について掘り下げます。それは、優れた顧客体験を提供するか、既存の課題を悪化させるかを検討します。 また読む:ChatGPTは、医師よりも質の高い医療アドバイスを提供する AIによるコールセンターの台頭 人工知能は、近年著しい進歩を遂げ、専門家たちは、顧客サービス業務での広範な採用を予想しています。従来のチャットボットに頼るのではなく、新しい世代のAI駆動システムは、驚異的な能力を示します。彼らは、個々の顧客のニーズに合わせたカスタマイズされた応答を提供するために、継続的に学習し、適応し、膨大な情報を活用することができます。 また読む:Sanctuary AIのPhoenixロボットとTeslaの最新ローンチ、Optimus!に会いましょう! 自動化サポートの二重性 高度なAIに基づく顧客サービスの見通しは有望ですが、その実装と潜在的な欠点については、正当な懸念があります。十分な準備なしに採用に急いだ場合、顧客の体験が失望する可能性があります。自動ループは、人道的支援にアクセスできず、困り果てた顧客が自分自身を取り囲んでいるという現実的な懸念があります。また、意図しない冒涜的または不正確なAIの応答も検討する必要があります。 また読む:ChatGPTがラジオホストに対して偽の告発を生成するため、OpenAIが名誉毀損訴訟に直面しています コールセンターの労働者への影響 コールセンターにおけるAIの導入は、今後10年間で何百万ものコールセンター労働者の大量失業を引き起こすことが予想されています。短期間では、状況は同じくらい厳しいようです。労働者は、クエリの処理に関する提案を提供し、パフォーマンスについて報告する機械による常時監視の見通しに直面しています。この増加した監視は、彼らの仕事の既に厳しい性質を強化し、より高いストレスレベルを引き起こす可能性があります。 また読む:人工知能の急速な上昇は、仕事の喪失を意味します:テックセクターで何千人もの人々が影響を受けています コスト削減と生産性向上のバランス 潜在的な欠点にもかかわらず、ビジネスにとって生成的AIの魅力は否定できません。最近のマッキンゼーの報告によると、顧客サービス機能の改善だけでも、世界中で4,040億ドルの驚異的な利益が得られる可能性があります。これらの潜在的な節約と生産性の向上は、組織がAI駆動のソリューションをさらに探求することを推進するでしょう。したがって、彼らはコスト効率と顧客満足度のバランスを慎重に維持する必要があります。 また読む:生成的AIは年間4.4兆ドルの貢献ができる:マッキンゼー 消費者のAIへの信頼 OpenAIのChatGPT、GoogleのBard、そしてMicrosoftのAI駆動のBing検索エンジンなどのAIチャットボットの出現は、一般大衆を魅了し、その応用についての多くの議論を引き起こしました。しかし、消費者の感情は分かれています。最近の調査によると、74%の回答者が、AIに基づく顧客サービスはライブ代表者とのやり取りよりも悪い体験を提供すると考えています。同様に、63%の人々が人間のエージェントをAIよりも信頼し、わずか6%がチャットボットに傾いています。さらに、カナダ人の大多数(63%)は、パンデミック中にチャットボットを雇用した企業が、ポストパンデミック時にライブ代表者に戻ることを期待しており、そうしない企業には否定的な影響があります。 私たちの意見 人工知能をコールセンターの運用に統合することは、機会と課題の両方を示します。潜在的な利益は、改善された顧客体験や巨大なコスト削減を含みますが、サービスの質やコールセンターの従業員への影響については正当な懸念があります。人間のタッチとAI駆動のサポートの適切なバランスを打つことは、AI時代において顧客サービスを最適化しようとする組織にとって重要です。コールセンターの景色がこの変革的なシフトを経験するにつれ、効率的で共感的な顧客体験の提供を優先し、AI駆動のテクノロジーの利点を受け入れることが不可欠です。

AIAgentに会ってみましょう:APIキーを必要とせず、GPT4によって動力を得るWebベースのAutomateGPT
AIAgentは、ユーザーが特定のタスクや目標に合わせてカスタマイズされたAIエージェントを作成する力を与える強力なWebベースのアプリケーションです。このアプリケーションは、目標を小さなタスクに分解し、それらを個別に完了することで機能します。このアプリの利点には、複数のAIエージェントを同時に実行できることや、最先端の技術を民主化することが挙げられます。 AIエージェントを使用することで、ユーザーはAIにタスクを指示することができます。たとえば、製品の競合他社を検索し、調査結果のレポートを作成したり、コードスニペットではなく、完全なアプリケーションを作成したりすることができます。 GPT-4の機能とインターネットアクセスを備えたAIAgentは、SEO最適化を伴うブログの自動化、ポッドキャストのトピックの研究などに最適です。APIキーは必要せず、クリーンでシンプルなユーザーインターフェイスを備えているため、AIエージェントとの作業がより簡単になります。 AIAgentは、ファイルの読み取りと書き込みができるため、ユーザーのドキュメントワークフローを効率化することができます。また、構文のハイライトを備えたインラインコードブロックや、サードパーティプラットフォームとのシームレスなコラボレーションなどの機能も備えています。 このツールの現在のバージョンは、ユーザーがGPT-3.5モデルを利用できる無料ティアを提供しています。ただし、GPT-4モデルにアクセスするためには、月額料金が必要です。 使用例 AIAgentは、SEO最適化が最優先事項であるブログコンテンツの調査や執筆を自動化するのに最適です。 ユーザーは、ツールを使用してTwitterの投稿スケジュールを明確に定義し、常にオーディエンスと価値あるコンテンツを共有することができます。 AIAgentは、インターネットアクセスを備えているため、ポッドキャストのトピックの研究に貴重なリソースとなります。さまざまなオンラインソースから重要な情報を取得し、ポッドキャストを充実させることができます。 このツールは、マーケティング分野で、経験豊富な専門家から戦略を学ぶことができます。マーケティングのプロフェッショナルからの記事や専門家の意見にアクセスして分析し、成功したマーケティング技術に関する洞察を得ることができます。 利点 AIAgentは、最新の自然言語処理と理解の最新技術を取り入れたGPT-4モデルによって動作します。 APIキーが不要であるため、シームレスで手間のかからない体験を提供できます。 シンプルでクリーンなユーザーインターフェイス(UI)により、ユーザーがシステムをスムーズに操作できます。 ツールにはインターネットアクセスがあり、オンラインリソースを活用してリアルタイム情報を取得することができます。 個人は、特定のニーズや好みに応じてタスクを完全にカスタマイズおよび変更することができます。 結論 以上より、AIAgentは、様々なタスクにカスタマイズされたAIエージェントを作成することができる強力なWebベースのアプリケーションです。高度なGPT-4モデルとインターネットアクセスにより、ブログの自動化、ポッドキャストのトピックの研究、マーケティング戦略の学習などの利点があります。AIAgentのユーザーフレンドリーなインターフェース、APIキーの不要性、複数のAIエージェントを同時に実行できる能力により、AIツールの分野でChatGPT、AutoGPT、AgentGPTなどの類似プラットフォームとの競合力が高まっています。
3つの質問:大規模言語モデルについて、Jacob Andreasに聞く
CSAILの科学者は、最新の機械学習モデルを通じた自然言語処理の研究と、言語が他の種類の人工知能をどのように高めるかの調査を説明しています
ChatGPT:ウェブデザイナーの視点
もし最新のニュースやトレンドについて常にアップデートしているのであれば、おそらく「ChatGPT」という言葉とその成功について耳にしたことがあるでしょう簡単に言えば、ChatGPTとは人工知能のことです

フラッシュセール:今日からAIの可能性を解き放とう!🚀
興奮するニュースです!待ちに待ったフラッシュセールが始まりましたこれは、今までにないAIの可能性を引き出すための独占的な機会を提供していますこの期間限定のオファーを見逃さないでください...

特定のデータロールに適したプログラミング言語
特定のデータロールに必要なプログラミング言語は何ですか?
データサイエンティストとして成功するために必要なソフトスキル
データサイエンティストとしてのキャリアを構築する際には、ハードスキルにフォーカスすることが簡単です非線形カーネルを持つSVMのような新しいMLアルゴリズムを学ぶことや、新しいソフトウェアを学びたいと思うかもしれません
チャートの推論に基づくモデルの基盤
グーグルリサーチのリサーチソフトウェアエンジニア、ジュリアン・アイゼンシュロスによる投稿 ビジュアル言語は、情報を伝えるためにテキスト以外の絵文字を使用するコミュニケーション形式です。アイコノグラフィ、情報グラフィック、表、プロット、チャートなどの形でデジタルライフで普及しており、道路標識、コミックブック、食品ラベルなどの現実世界にも広がっています。このようなメディアをコンピュータがより理解できるようにすることは、科学的コミュニケーションと発見、アクセシビリティ、データの透過性に役立ちます。 ImageNetの登場以来、学習ベースのソリューションを使用してコンピュータビジョンモデルは大きな進歩を遂げてきましたが、焦点は自然画像にあり、分類、ビジュアルクエスチョンアンサリング(VQA)、キャプション、検出、セグメンテーションなどのさまざまなタスクが定義され、研究され、いくつかの場合には人間の性能に達成されています。しかし、ビジュアル言語は同じレベルの注目を集めていません。これは、この分野における大規模なトレーニングセットの不足のためかもしれません。しかし、PlotQA、InfographicsVQA、ChartQAなどの視覚言語イメージにおける質問応答システムの評価を目的とした新しい学術データセットが、ここ数年で作成されています。 ChartQAからの例。質問に答えるには、情報を読み取り、合計と差を計算する必要があります。 これらのタスクに対して構築された既存のモデルは、光学的文字認識(OCR)情報とその座標を大規模なパイプラインに統合することに頼っていましたが、プロセスはエラーが発生しやすく、遅く、一般化が悪いです。既存の畳み込みニューラルネットワーク(CNN)またはトランスフォーマーに基づくエンドツーエンドのコンピュータビジョンモデルは、自然画像で事前にトレーニングされたモデルを簡単にビジュアル言語に適応させることができなかったため、これらの方法が広く使用されていました。しかし、既存のモデルは、棒グラフの相対高さや円グラフのスライスの角度を読み取り、軸のスケールを理解し、色、サイズ、テクスチャでピクトグラムを伝説値に正しくマッピングし、抽出された数字で数値演算を実行するなど、チャートの質問に対する課題には準備ができていません。 これらの課題に対応するために、「MatCha:数学推論とチャートディレンダリングを活用したビジュアル言語の事前トレーニングの強化」という提案を行います。 MatChaは数学とチャートを表す言葉であり、2つの補完的なタスクでトレーニングされたピクセルからテキストへの基礎モデル(複数のアプリケーションでファインチューニングできる組み込み帰納バイアスを備えた事前トレーニングモデル)です。1つはチャートディレンダリングであり、プロットまたはチャートが与えられた場合、画像からテキストモデルはその基礎となるデータテーブルまたはレンダリングに使用されるコードを生成する必要があります。数学推論の事前トレーニングでは、テキストベースの数値推論データセットを選択し、入力を画像にレンダリングし、画像からテキストモデルが回答をデコードする必要があります。また、「DePlot:プロットからテーブルへの翻訳によるワンショットビジュアル言語推論」という、テーブルへの翻訳を介したチャートのワンショット推論にMatChaの上に構築されたモデルを提案します。これらの方法により、ChartQAの以前の最高記録を20%以上超え、パラメータが1000倍多い最高の要約システムに達成します。両方の論文はACL2023で発表されます。 チャートディレンダリング プロットやチャートは、基礎となるデータテーブルとコードによって通常生成されます。コードは、図の全体的なレイアウト(タイプ、方向、色/形状スキームなど)を定義し、基礎となるデータテーブルは実際の数字とそのグループ化を確立します。データとコードの両方がコンパイラ/レンダリングエンジンに送信され、最終的な画像が作成されます。チャートを理解するには、イメージ内の視覚パターンを発見し、効果的に解析してグループ化し、主要な情報を抽出する必要があります。プロットレンダリングプロセスを逆転するには、すべてのこのような機能が必要であり、したがって理想的な事前トレーニングタスクとして機能することができます。 ランダムなプロットオプションを使用して、Airbus A380 Wikipediaページの表から作成されたチャートです。MatChaの事前トレーニングタスクは、イメージからソーステーブルまたはソースコードを回復することです。 チャート、その基礎となるデータテーブル、およびそのレンダリングコードを同時に取得することは、実践的には困難です。事前トレーニングデータを十分に収集するために、[chart、code]および[chart、table]のペアを独立して蓄積します。[chart、code]の場合、適切なライセンスを持つすべてのGitHub IPythonノートブックをクロールし、図を含むブロックを抽出します。図とそれに直前にあるコードブロックは、[chart、code]ペアとして保存されます。[chart、table]のペアについては、2つのソースを調査しました。最初のソースは、合成データで、TaPasコードベースからWebクロールされたWikipediaテーブルを手動でコードに変換します。列のタイプに応じて、いくつかのプロットオプションをサンプリングして組み合わせます。さらに、事前トレーニングコーパスを多様化するために、PlotQAで生成された[chart、table]ペアも追加します。2番目のソースはWebクロールされた[chart、table]ペアです。Statista、Pew、Our World in Data、OECDの4つのWebサイトから合計約20,000ペアを含むChartQAトレーニングセットでクロールされた[chart、table]ペアを直接使用します。 数学的推論 MatChaに数値推論知識を組み込むために、テキスト数学データセットから数学的推論スキルを学習します。事前トレーニングには、MATHとDROPの2つの既存のテキスト数学推論データセットを使用します。MATHは合成的に作成され、各モジュール(タイプ)の質問ごとに200万のトレーニング例を含んでいます。DROPは読解型のQAデータセットで、入力はパラグラフのコンテキストと質問です。 DROPでの質問を解決するには、モデルがパラグラフを読み、関連する数字を抽出し、数値計算を実行する必要があります。私たちは、両方のデータセットが補完的であることを発見しました。MATHには、異なるカテゴリーにわたる多数の質問が含まれており、モデルに明示的に注入する必要がある数学的操作を特定するのに役立ちます。DROPの読解形式は、モデルが情報抽出と推論を同時に実行する典型的なQA形式に似ています。実際には、両方のデータセットの入力を画像にレンダリングします。モデルは答えをデコードするように訓練されます。 MATHとDROPからの例をMatChaの事前トレーニング目的に取り込むことにより、MatChaの数学的推論スキルを向上させます。入力テキストを画像としてレンダリングします。 エンドツーエンドの結果 Webサイト理解に特化した画像からテキストへの変換トランスフォーマーであるPix2Structモデルバックボーンを使用し、上記の2つのタスクで事前トレーニングを行います。MatChaの強みを示すために、表の基礎にアクセスできない質問応答や要約のためのチャートやプロットを含むいくつかの視覚言語タスクで微調整します。MatChaは、以前のモデルの性能を大幅に上回り、基礎となるテーブルにアクセスできると仮定する以前の最先端も上回ります。 以下の図では、チャートと作業するための標準的なアプローチであったOCRパイプラインから情報を取り込んだ2つのベースラインモデルを最初に評価します。最初のものはT5に基づき、2番目のものはVisionTaPasに基づきます。また、PaLI-17BとPix2Structのモデル結果を報告します。PaLI-17Bは、多様なタスクでトレーニングされた大型(他のモデルの約1000倍)のイメージプラステキスト・トゥ・テキスト・トランスフォーマーですが、テキストやその他の視覚言語の読み取り能力に限界があります。最後に、Pix2StructとMatChaのモデル結果を報告します。…
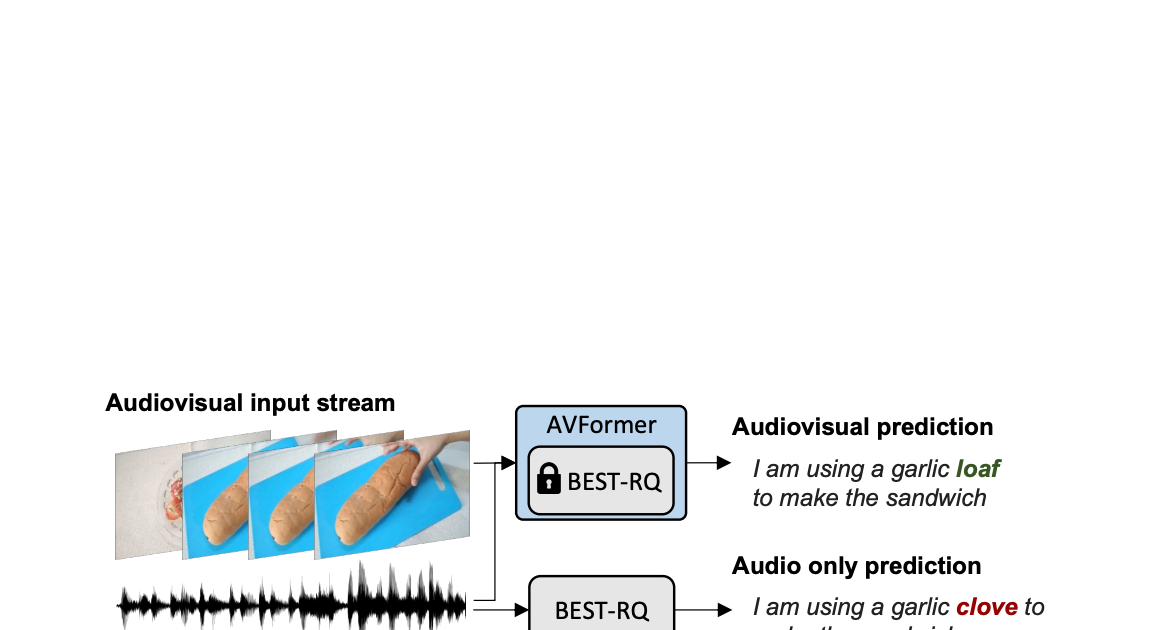
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビデオの転写、音声コマンドなど、さまざまなアプリケーションで広く採用されている確立された技術です。この技術の課題は、ノイズのあるオーディオ入力に集中していますが、マルチモーダルビデオ(テレビ、オンライン編集ビデオなど)の視覚ストリームはASRシステムの堅牢性を向上させる強力な手がかりを提供することができます。これをオーディオビジュアルASR(AV-ASR)と呼びます。 唇の動きは音声認識に強力な信号を提供し、AV-ASRの最も一般的な焦点であるが、野外のビデオで口が直接見えないことがよくあります(例えば、自己中心的な視点、顔のカバー、低解像度など)ため、新しい研究領域である拘束のないAV-ASR(AVATARなど)が誕生し、口の領域だけでなく、ビジュアルフレーム全体の貢献を調査しています。 ただし、AV-ASRモデルをトレーニングするためのオーディオビジュアルデータセットを構築することは困難です。How2やVisSpeechなどのデータセットはオンラインの教育ビデオから作成されていますが、サイズが小さいため、モデル自体は通常、ビジュアルエンコーダーとオーディオエンコーダーの両方から構成され、これらの小さなデータセットで過剰適合する傾向があります。それにもかかわらず、オーディオブックから取得した大量のオーディオデータを用いた大規模なトレーニングによって強く最適化された最近リリースされた大規模なオーディオモデルがいくつかあります。LibriLightやLibriSpeechなどがあります。これらのモデルには数十億のパラメータが含まれ、すぐに利用可能であり、ドメイン間で強い汎化性能を示します。 上記の課題を考慮して、私たちは「AVFormer:ゼロショットAV-ASRの凍結音声モデルにビジョンを注入する」と題した論文で、既存の大規模なオーディオモデルにビジュアル情報を付加するシンプルな方法を提案しています。同時に、軽量のドメイン適応を行います。AVFormerは、軽量のトレーニング可能なアダプタを使用して、視覚的な埋め込みを凍結されたASRモデルに注入します(Flamingoが大規模な言語モデルに視覚テキストタスクのためのビジュアル情報を注入する方法と似ています)。これにより、最小限の追加トレーニング時間とパラメータで弱くラベル付けられた少量のビデオデータでトレーニング可能です。トレーニング中のシンプルなカリキュラムスキームも紹介し、オーディオとビジュアルの情報を効果的に共同処理できるようにするために重要であることを示します。その結果、AVFormerモデルは、3つの異なるAV-ASRベンチマーク(How2、VisSpeech、Ego4D)で最新のゼロショットパフォーマンスを達成し、同時に伝統的なオーディオのみの音声認識ベンチマーク(LibriSpeechなど)のまともなパフォーマンスを保持しています。 拘束のないオーディオビジュアル音声認識。軽量モジュールを使用して、ビジョンを注入して、オーディオビジュアルASRのゼロショットを実現するために、Best-RQ(灰色)の凍結音声モデルにビジョンを注入します。AVFormer(青)というパラメーターとデータ効率の高いモデルが作成されます。オーディオ信号がノイズの場合、視覚的なパンの生成トランスクリプトでオンリーミステイク「クローブ」を「ローフ」に修正するのに役立つ視覚的なパンが役立つ場合があります。 軽量モジュールを使用してビジョンを注入する 私たちの目標は、既存のオーディオのみのASRモデルにビジュアル理解能力を追加しながら、その汎化性能を各ドメイン(AVおよびオーディオのみのドメイン)に維持することです。 このために、既存の最新のASRモデル(Best-RQ)に次の2つのコンポーネントを追加します:(i)線形ビジュアルプロジェクター、および(ii)軽量アダプター。前者は、オーディオトークン埋め込みスペースにおける視覚的な特徴を投影します。このプロセスにより、別々に事前トレーニングされたビジュアル機能とオーディオ入力トークン表現を適切に接続することができます。後者は、その後最小限の変更で、ビデオのマルチモーダル入力を理解するためにモデルを変更します。その後、これらの追加モジュールを、HowTo100Mデータセットからのラベル付けされていないWebビデオとASRモデルの出力を擬似グラウンドトゥルースとして使用してトレーニングし、Best-RQモデルの残りを凍結します。このような軽量モジュールにより、データ効率と強力なパフォーマンスの汎化が可能になります。 我々は、AV-ASRベンチマークにおいて、モデルが人手で注釈付けされたAV-ASRデータセットで一度もトレーニングされていないゼロショット設定で、拡張モデルを評価しました。 ビジョン注入のためのカリキュラム学習 初期評価後、私たちは経験的に、単純な一回の共同トレーニングでは、モデルがアダプタとビジュアルプロジェクタの両方を一度に学習するのが困難であることがわかりました。この問題を緩和するために、私たちは、これら2つの要因を分離し、ネットワークを順序良くトレーニングする2段階のカリキュラム学習戦略を導入しました。最初の段階では、アダプタパラメータが全くフィードされずに最適化されます。アダプタがトレーニングされたら、ビジュアルトークンを追加し、トレーニング済みのアダプタを凍結したまま第2段階でビジュアルプロジェクションレイヤーのみをトレーニングします。 最初の段階は、音声ドメイン適応に焦点を当てています。第2段階では、アダプタが完全に凍結され、ビジュアルプロジェクタは、ビジュアルトークンをオーディオ空間に投影するためのビジュアルプロンプトを生成することを学習する必要があります。このように、私たちのカリキュラム学習戦略は、モデルがAV-ASRベンチマークでビジュアル入力を統合し、新しい音声ドメインに適応することを可能にします。私たちは、交互に適用する反復的な適用では性能が低下するため、各段階を1回だけ適用します。 AVFormerの全体的なアーキテクチャとトレーニング手順。アーキテクチャは、凍結されたConformerエンコーダー・デコーダーモデル、凍結されたCLIPエンコーダー(グレーのロックシンボルで示される凍結層を持つ)、および2つの軽量トレーニング可能なモジュールで構成されています。-(i)ビジュアルプロジェクションレイヤー(オレンジ)およびボトルネックアダプタ(青)を有効にし、多モーダルドメイン適応を可能にします。私たちは、2段階のカリキュラム学習戦略を提案しています。最初に、アダプタ(青)をビジュアルトークンなしでトレーニングします。その後、ビジュアルプロジェクションレイヤー(オレンジ)を調整し、他のすべての部分を凍結したままトレーニングします。 下のプロットは、カリキュラム学習なしでは、AV-ASRモデルがすべてのデータセットでオーディオのみのベースラインよりも劣っており、より多くのビジュアルトークンが追加されるにつれてその差が拡大することを示しています。一方、提案された2段階のカリキュラムが適用されると、AV-ASRモデルは、オーディオのみのベースラインよりも遥かに優れたパフォーマンスを発揮します。 カリキュラム学習の効果。赤と青の線はオーディオビジュアルモデルであり、ゼロショット設定で3つのデータセットに表示されます(WER%が低い方が良いです)。カリキュラムを使用すると、すべての3つのデータセットで改善します(How2(a)およびEgo4D(c)では、オーディオのみのパフォーマンスを上回るために重要です)。4つのビジュアルトークンまで性能が向上し、それ以降は飽和します。 ゼロショットAV-ASRでの結果 私たちは、How2、VisSpeech、Ego4Dの3つのAV-ASRベンチマークで、zero-shotパフォーマンスのために、BEST-RQ、私たちのモデルの音声バージョン、およびAVATARを比較しました。AVFormerは、すべてのベンチマークでAVATARとBEST-RQを上回り、BEST-RQでは600Mパラメータをトレーニングする必要がありますが、AVFormerはわずか4Mパラメータしかトレーニングせず、トレーニングデータセットのわずか5%しか必要としません。さらに、音声のみのLibriSpeechでのパフォーマンスも評価し、AVFormerは両方のベースラインを上回ります。 AV-ASRデータセット全体におけるゼロショット性能に対する最新手法との比較。音声のみのLibriSpeechのパフォーマンスも示します。結果はWER%(低い方が良い)として報告されています。 AVATARとBEST-RQはHowTo100Mでエンドツーエンド(すべてのパラメータ)で微調整されていますが、AVFormerは微調整されたパラメータの少ないセットのおかげで、データセットの5%でも効果的に機能します。…

フォトグラメトリとは何ですか?
「ストリートビュー」のおかげで、現代の地図ツールを使って、レストランを調べたり、周辺のランドマークを見て方向を確認したり、道路上にいるかのような体験をシミュレーションしたりすることができます。 これらの3Dビューを作成するための技術は、フォトグラメトリと呼ばれます。つまり、画像をキャプチャして繋ぎ合わせて物理世界のデジタルモデルを作成するプロセスです。 それはまるでジグソーパズルのようで、各ピースは画像で構成されます。そして、キャプチャされた画像が多ければ多いほど、3Dモデルはより現実的で詳細になります。 フォトグラメトリの作業方法 フォトグラメトリ技術は、建築や考古学などのさまざまな産業にも応用できます。例えば、フォトグラメトリの早い例の一つは、1849年にフランスの軍人アイメ・ローセダがテラストリアル写真を使用して、パリのイノディル旅館で最初の建築調査を行ったことです。 可能な限り多くの領域や環境の写真を撮影して、チームは現場のデジタルモデルを構築して表示・分析することができます。 3Dスキャンは、シーン内のポイントの位置を測定するために構造化されたレーザー光を使用するのに対し、フォトグラメトリは実際の画像を使用してオブジェクトをキャプチャして3Dモデルに変換します。これは、良好なフォトグラメトリには良好なデータセットが必要であることを意味します。また、サイト、記念碑、または遺物のすべての領域がカバーされるように、正しいパターンで写真を撮ることが重要です。 フォトグラメトリの種類 今日、シーンを繋ぎ合わせたい場合、被写体の複数の角度から写真を撮影し、専用のアプリケーションで組み合わせてオーバーラップデータを抽出して3Dモデルを作成することができます。 3ds-scan.de提供のイメージ。 フォトグラメトリには、空中フォトグラメトリと地上フォトグラメトリの2種類があります。 空中フォトグラメトリは、カメラを空中に置いて上から写真を撮影することで、一般的には大きなサイトやアクセスが困難な場所で使用されます。空中フォトグラメトリは、林業や自然資源管理で地理情報データベースを作成するために最も広く使用されています。 地上フォトグラメトリ、またはクローズレンジフォトグラメトリは、よりオブジェクトに焦点を当てたもので、手持ちのカメラまたは三脚に取り付けたカメラで撮影された画像に頼ることが多いです。これにより、現場でのデータ収集が迅速に行われ、より詳細な画像キャプチャが可能になります。 GPUを使用したフォトグラメトリワークフローの加速 最も正確なフォトグラメトリの結果を得るには、チームは巨大な高精度のデータセットが必要です。より多くの写真を撮影すると、より正確で精密なモデルが得られます。ただし、大規模なデータセットは処理に時間がかかり、チームはファイルを処理するためにより多くのコンピュータパワーが必要です。 GPUの最新の進歩は、チームがこれを解決するのに役立ちます。NVIDIA RTXカードなどの高度なGPUを使用することで、ユーザーは処理を高速化し、より高精度なモデルを維持しながら、より大きなデータセットを入力することができます。 例えば、建設チームは、建設現場の進捗状況を示すためにフォトグラメトリ技術を頼りにすることがよくあります。一部の企業は、サイトの画像をキャプチャして仮想的なウォークスルーを作成します。しかし、パワー不足のシステムはチョッピーな視覚体験をもたらし、クライアントやプロジェクトチームとの作業セッションから注意を逸らしてしまいます。 RTXプロフェッショナルGPUの大きなメモリを使用すると、建築家、エンジニア、デザイナーは巨大なデータセットを簡単に管理して、フォトグラメトリモデルをより速く作成・処理することができます。 考古学者ダリア・ダバルは、NVIDIA RTXを使用して、遺物やサイトの高品質なモデルを作成・レンダリングするスキルを拡大しています。 フォトグラメトリは、写真のベクトル化を支援するためにGPUパワーを使用するため、何千もの画像を繋ぎ合わせる作業を加速します。そして、RTXプロフェッショナルGPUのリアルタイムレンダリングとAI機能により、チームは3Dワークフローを加速し、フォトリアルなレンダリングを作成し、3Dモデルを最新の状態に保つことができます。 フォトグラメトリの歴史と将来 フォトグラメトリのアイデアは、写真術の発明の4世紀前の15世紀末にまで遡ります。レオナルド・ダ・ヴィンチは、透視と射影幾何学の原理を開発し、フォトグラメトリの基盤となる柱を築きました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.