Learn more about Search Results Python - Page 14

- You may be interested
- dbtコア、Snowflake、およびGitHub Action...
- 「フラミンゴとDALL-Eはお互いを理解して...
- 「Llama 2内のストップ生成の課題」
- 大規模言語モデルにおけるより高い自己一...
- 「コーディング経験なしでAIエージェンシ...
- 患者のケアを革新するAI技術
- 偽のレビューがオンラインで横行していま...
- 最適化:ニュートン・ラフソン法の幾何学...
- 大規模言語モデルの評価:包括的かつ客観...
- 「ベクターデータベースのベンチマークに...
- 次元の呪いの真の範囲を可視化する
- コンピュータビジョンシステムは、ビデオ...
- AIに関する最高のコースは、YouTubeのプレ...
- AIと自動化
- 「総合的な指標を通じて深層生成モデルの...

「ExcelでのPython:これがデータサイエンスを永遠に変える」
「ExcelでPythonコードを実行してデータを分析し、機械学習モデルを構築し、可視化を作成することができます」
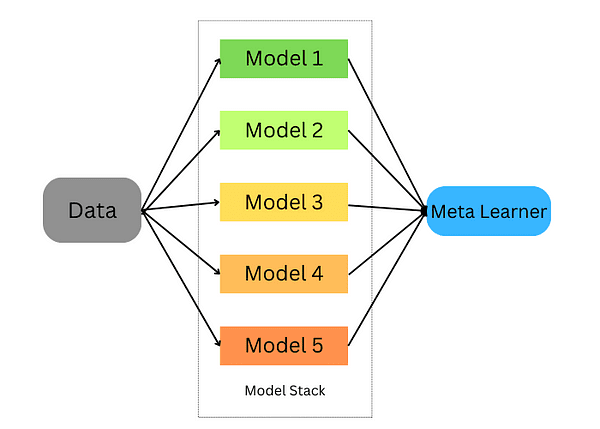
アンサンブル学習技術:Pythonでのランダムフォレストを使った手順解説
Pythonにおけるランダムフォレストの実践的な手順解説

PyCharm vs. Spyder 正しいPython IDEの選択
PyCharmとSpyderはPython開発のための2つの最も人気のあるIDEですでは、PyCharmとSpyderの直接比較を見てみましょう

このAI論文は、自律言語エージェントのためのオープンソースのPythonフレームワークである「Agents」を紹介しています
カスタマーサービス、コンサルティング、プログラミング、執筆、教育などのタスクでは、言語エージェントは人間の労力を削減することができ、人工一般知能(AGI)に向けた潜在的な第一歩となります。AutoGPTやBabyAGIなどの言語エージェントの潜在能力を示す最近のデモンストレーションは、研究者、開発者、一般の観客から多くの注目を浴びています。 経験豊かな開発者や研究者でも、これらのデモやリポジトリのほとんどは、エージェントをカスタマイズ、設定、展開するのに適していません。これは、これらのデモンストレーションが、言語エージェントの潜在能力を強調する概念実証の一環であり、徐々に開発およびカスタマイズ可能なフレームワークではないためです。 さらに、研究によると、これらのオープンソースソースの大多数は、ジョブの分解、長期記憶、ウェブナビゲーション、ツールの使用、複数エージェントの通信など、基本的な言語エージェントの機能のほんの一部しかカバーしていないことがわかっています。また、現在使用されている言語エージェントフレームワークのほとんど(もしくはすべて)は、短いタスクの説明とLLMの計画と行動能力に完全に依存しています。異なる実行間での高いランダム性と一貫性のため、言語エージェントは修正や微調整が困難であり、ユーザーエクスペリエンスが低いです。 AIWaves Inc.、浙江大学、ETH Zürichの研究者は、LLMを活用した言語エージェントをサポートするオープンソースの言語エージェントライブラリおよびフレームワークであるAGENTSを提案しています。AGENTSの目標は、言語エージェントのカスタマイズ、調整、展開を可能な限り簡単にすることです。非専門家でも利用できるようにする一方で、プログラマーや研究者にとっても拡張性のあるプラットフォームであることも重要です。ライブラリは以下のコア機能も提供しており、これらを組み合わせることで柔軟な言語エージェントのプラットフォームとなっています。 長短期記憶:AGENTSはメモリコンポーネントを組み込み、言語エージェントがスクラッチパッドを使用して短期作業メモリを定期的に更新し、VectorDBと意味検索を使用して長期記憶を保存および取得することができます。ユーザーは設定ファイルのフィールドに値を入力するだけで、エージェントに長期記憶、短期記憶、または両方を与えるかどうかを決定できます。 ウェブナビゲーションとツールの使用:外部ツールの使用とインターネットの閲覧能力は、自律エージェントのもう一つの重要な特性です。AGENTSはいくつかの一般的に使用される外部APIをサポートし、他のツールを簡単に組み込むための抽象クラスを提供しています。ウェブ検索とナビゲーションを特殊なAPIとして分類することにより、エージェントがインターネットを閲覧し情報を収集することも可能にしています。 複数エージェントの相互作用:AGENTSはカスタマイズ可能なマルチエージェントシステムとシングルエージェントの機能を許可しており、ゲーム、社会実験、ソフトウェア開発など、特定のアプリケーションに有用です。AGENTSの「動的スケジューリング」機能は、マルチエージェント間の通信において新しい機能です。動的スケジューリングにより、コントローラーエージェントが「モデレーター」として機能し、役割と最近の履歴に基づいて次のアクションを実行するエージェントを選択することができます。動的スケジューリングを使用すると、複数のエージェント間でより柔軟かつ自然なコミュニケーションが可能です。開発者は設定ファイルでコントローラーのルールを定義することで、コントローラーの動作を簡単に変更できます。 人間とエージェントの相互作用:AGENTSは単一エージェントおよびマルチエージェントのシナリオで、1人以上の人間と言語エージェントの相互作用とコミュニケーションを可能にします。 制御性:AGENTSは、標準的な作業手順(SOP)として知られる象徴的な計画を使用して、制御可能なエージェントの開発に革新的なパラダイムを提供します。SOPは、エージェントがタスクを実行する際に直面するさまざまな状況と、状態間の遷移ルールを記述したグラフです。AGENTSのSOPは、特定の活動や手順を実行する方法を詳細に指定した、手作業で記録された詳細な指示の集合です。これは現実の世界のSOPに似ています。LLMは、ユーザーが個別に変更および微調整しながらSOPを生成することができます。展開後、エージェントは各状態に対して設定された指示と基準に従って動作し、外部の世界、人々、他のエージェントとの相互作用に応じて現在の状態を動的に変更します。象徴的な計画の登場により、エージェントの振る舞いに対して細かい制御を提供し、安定性と予測性を向上させ、調整とエージェントの最適化を容易にします。 チームは、AGENTSが言語エージェントの研究者にとって研究をより容易にし、言語エージェントを活用したアプリケーションを作成する開発者にとっても便利になり、非技術的なユーザーでも独自の言語エージェントを作成および変更できるようになることを望んでいます。

「PythonでChatGPTを使用する方法」
ChatGPTをPythonで強化する方法が知りたいですか?Pythonを使用してKommunicateプラットフォームのアカウントをステップバイステップで設定する方法を学びましょう

「Pythonにおけるフィボナッチ数列 | コード、アルゴリズム、その他」
イントロダクション Pythonにおけるフィボナッチ数列は、0と1で始まる数学的な数列であり、各後続の数は前の2つの数の合計となります。Pythonでは、フィボナッチ数列を生成することは、クラシックなプログラミングの演習だけでなく、再帰と反復的な解法を探求する素晴らしい方法でもあります。 F(0) = 0 F(1) = 1 F(n) = F(n-1) + F(n-2) (ただし、n > 1) フィボナッチ数列とは何ですか? フィボナッチ数列は、0と1で始まる数列であり、それぞれの数は直前の2つの数の合計です。 無料でPythonを学びたいですか? 今すぐ無料のコースを探索してください! フィボナッチ数列の数学的な式 フィボナッチ数列を計算するための数学的な式は次のとおりです: F(n) =…

「Pythonにおけるパスの表現」
Pythonでパスを適切にコーディングする方法パスを文字列で表現せず、代わりにpathlibを使用する理由を理解する方法
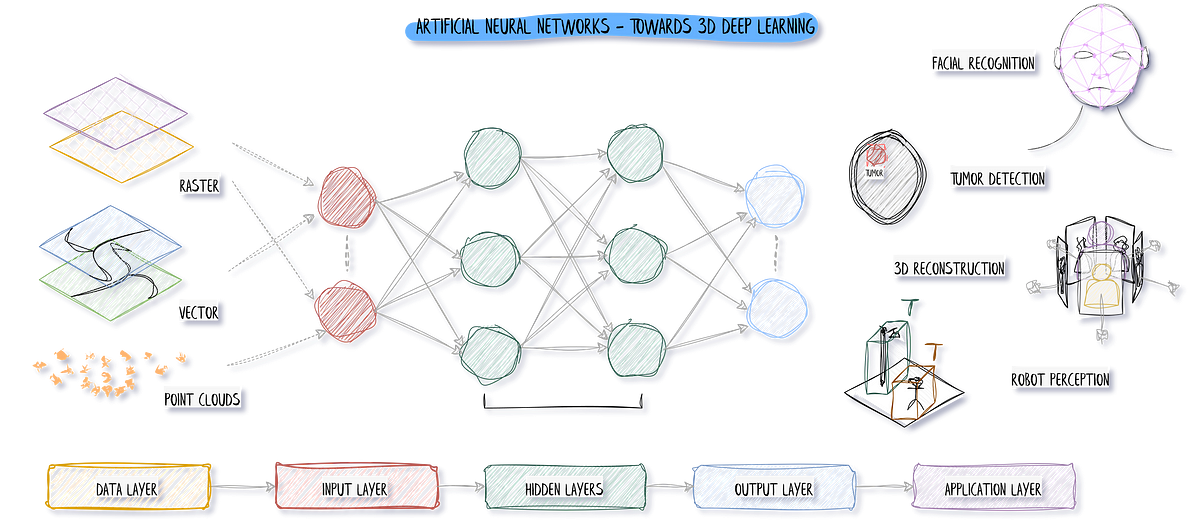
『3Dディープラーニングへの道:Pythonでの人工ニューラルネットワーク』
「人工ニューラルネットワーク(ANN)を作成して使用するための初心者向け実践ガイド:ディープラーニングアプリケーションのための基礎3Dディープラーニングの基礎」

「Pythonにおける記述統計と推測統計の適用」
データサイエンスの道を進むにつれて、知っておくべき基本的な統計情報を以下に示します

「PyGraftに会ってください:高度にカスタマイズされた、ドメインに依存しないスキーマと知識グラフを生成する、オープンソースのPythonベースのAIツール」
データをグラフ構造で表現するための、ますます人気のある方法は、知識グラフ(KG)の使用です。KGは、s(主語)とo(目的語)という2つのグラフノード、およびそれらの間に存在する接続のタイプを記述する述語pからなるトリプル(s、p、o)のグループです。KGは、研究分野の主要なアイデアや関係性、およびこれらのアイデアや関係性がどのように相互作用するかを規定するスキーマ(オントロジーなど)によってしばしばサポートされます。KGが適用される多くの活動には、モデルのパフォーマンスを測定するための受け入れられた基準となるKGの数があります。 しかし、新たに提案されたモデルが一般化できるかどうかを判断するために、これら特定の主流のKGだけを使用することにはいくつかの問題があります。たとえば、ノードの分類において主流のデータセットは統計的特性、特に同質性を共有していることが示されています。そのため、同じ統計を持つデータセットが新しいモデルの評価に使用されます。その結果、共通のベンチマークデータセット以外では、パフォーマンスの向上への貢献は時折一貫性がありません。 同様に、既存のリンク予測データセットのいくつかはデータのバイアスを持っており、予測モデルが含めることができる多くの推論パターンを含んでいるため、楽観的すぎる評価パフォーマンスを示すことがあります。そのため、さまざまなデータセットが必要です。新しいモデルがさまざまなデータコンテキストでテストされるためには、研究者に異なるサイズと特性の架空のリアルなデータセットを作成する手段を提供することが重要です。一部のアプリケーションセクターでは、公にアクセス可能なKGが存在しないことが、わずかなKGに依存するよりも悪いです。 教育、法執行、医療などの分野では、現実の知識の収集や共有が不可能となるデータプライバシーの懸念が存在します。そのため、ドメイン指向のKGはこれらの地域ではほとんど利用できません。一方、エンジニア、実践者、研究者は通常、興味のある問題の特性について特定の考えを持っています。このような状況では、実際のKGの特性を模倣する合成KGを作成することが有利です。これら2つのコンポーネントはしばしば別々に扱われてきましたが、前述の問題がいくつかの試みを促し、スキーマとKGの合成ジェネレーターの構築に取り組んでいます。 ドメインニュートラルなKGは、確率ベースのジェネレーターによって生成することができます。これらのアプローチは、大規模なグラフを迅速に生成することでどれだけ効果的であるかに関わらず、データ生成の核心アイデアは基礎となる構造を考慮する必要があります。生成されたKGは、選択したアプリケーションセクターの実際のKGの特性を正確に模倣しない場合があります。一方、スキーマ駆動型のジェネレーターは、実世界のデータを反映したKGを作成することができます。ただし、彼らの知識によると、ほとんどの取り組みは既存のスキーマを使用して合成KGを作成することに焦点を当てています。スキーマとそれをサポートするKGの合成は、検討されていますが、まだ断片的な成功を収めていません。 彼らは、この問題を解決することを研究の目的としています。Université de LorraineとUniversité Côte d’Azurの研究者は、特に高度にカスタマイズ可能なドメインニュートラルなスキーマとKGを作成するためのPythonベースのツールであるPyGraftを紹介しています。彼らの研究の貢献は以下の通りです:彼らの知識によれば、PyGraftは、幅広いユーザー指定の基準に応じて非常に調整可能な新しいパイプラインでスキーマとKGを生成するために特に設計された唯一のジェネレーターです。特筆すべきは、作成されたリソースがドメインニュートラルであり、応用分野に関係なくベンチマークに適していることです。生成されたスキーマとKGは、拡張されたセットのRDFSとOWL要素を使用して構築され、DLリーズナーを使用してその論理的な整合性を保証します。これにより、詳細なリソースの記述と一般的なセマンティックウェブの標準に厳密に準拠することが可能となります。彼らは、使用の容易さのためにコードとドキュメント、および関連する例を公開しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.