Learn more about Search Results ImageNet - Page 14

- You may be interested
- 「オンラインプログラムの中で第3位のデー...
- 「AI スタートアップの資金調達 9 月 1 号...
- 文法AIの向上にBERTを活用する:スロット...
- 深層強化学習の概要
- 自律運転アプリケーションのための基本的...
- Google AIは、「ペアワイズランキングプロ...
- 「コンテキストの解読:NLPにおける単語ベ...
- ロボ犬が100メートル走のギネス世界記録を...
- スタビリティAIは、コーディングのための...
- 「PPOクリッピング方式はどのように機能し...
- データから洞察力へ:KubernetesによるAI/...
- 「デベロッパー用の15以上のAIツール(202...
- ミストラルの最先端言語モデル、Mixtral 8...
- Matplotlibを使用してインフォグラフィッ...
- 「単一細胞生物学のAIのフロンティアを探...
PyTorchを使った転移学習の実践ガイド
この記事では、転移学習と呼ばれる技術を使用して、カスタム分類タスクに事前学習済みモデルを適応する方法を学びますPyTorchを使用した画像分類タスクで、Vgg16、ResNet50、およびResNet152の3つの事前学習済みモデルで転移学習を比較します
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

SRGANs:低解像度と高解像度画像のギャップを埋める
イントロダクション あなたが古い家族の写真アルバムをほこりっぽい屋根裏部屋で見つけるシナリオを想像してください。あなたはすぐにほこりを取り、最も興奮してページをめくるでしょう。そして、多くの年月前の写真を見つけました。しかし、それでも、あなたは幸せではないです。なぜなら、写真が薄く、ぼやけているからです。写真の顔や細部を見つけるために目をこらします。これは昔のシナリオです。現代の新しいテクノロジーのおかげで、私たちはスーパーレゾリューション・ジェネレーティブ・アドバーサリ・ネットワーク(SRGAN)を使用して、低解像度の画像を高解像度の画像に変換することができます。この記事では、私たちはSRGANについて最も学び、QRコードの強化のために実装します。 出典: Vecteezy 学習目標 この記事では、以下のことを学びます: スーパーレゾリューションと通常のズームとの違いについて スーパーレゾリューションのアプローチとそのタイプについて SRGAN、その損失関数、アーキテクチャ、およびそのアプリケーションについて深く掘り下げる SRGANを使用したQRエンハンスメントの実装とその詳細な説明 この記事は、データサイエンスブログマラソンの一環として公開されました。 スーパーレゾリューションとは何ですか? 多くの犯罪捜査映画では、証拠を求めて探偵がCCTV映像をチェックする典型的なシナリオがよくあります。そして、ぼやけた小さな画像を見つけて、ズームして強化してはっきりした画像を得るシーンがあります。それは可能ですか?はい、スーパーレゾリューションの助けを借りて、それはできます。スーパーレゾリューション技術は、CCTVカメラによってキャプチャされたぼやけた画像を強化し、より詳細な視覚効果を提供することができます。 ………………………………………………………………………………………………………………………………………………………….. ………………………………………………………………………………………………………………………………………………………….. 画像の拡大と強化のプロセスをスーパーレゾリューションと呼びます。それは、対応する低解像度の入力から画像またはビデオの高解像度バージョンを生成することを目的としています。それによって、欠落している詳細を回復し、鮮明さを向上させ、視覚的品質を向上させることができます。強化せずに画像をズームインするだけでは、以下の画像のようにぼやけた画像が得られます。強化はスーパーレゾリューションによって実現されます。写真、監視システム、医療画像、衛星画像など、さまざまな領域で多くの応用があります。 ……….. スーパーレゾリューションの従来のアプローチ 従来のアプローチでは、欠落しているピクセル値を推定し、画像の解像度を向上させることに重点を置いています。2つのアプローチがあります。補間ベースの方法と正則化ベースの方法です。 補間ベースの方法 スーパーレゾリューションの初期の日々には、補間ベースの方法に重点が置かれ、欠落しているピクセル値を推定し、その後画像を拡大します。隣接するピクセル値が類似しているという仮定を使用して、これらの値を使用して欠落している値を推定します。最も一般的に使用される補間方法には、バイキュービック、バイリニア、および最近傍補間があります。しかし、その結果は満足できないものでした。これにより、ぼやけた画像が生じました。これらの方法は、基本的な解像度タスクや計算リソースに制限がある状況に適しているため、効率的に計算できます。 正則化ベースの手法 一方で、正則化ベースの手法は、画像再構成プロセスに追加の制約や先行条件を導入することで、超解像度の結果を改善することを目的としています。これらの技術は、画像の統計的特徴を利用して、再構築された画像の精度を向上させながら、細部を保存します。これにより、再構築プロセスにより多くの制御が可能になり、画像の鮮明度と細部が向上します。しかし、複雑な画像コンテンツを扱う場合には、過度の平滑化を引き起こすため、いくつかの制限があります。 これらの従来のアプローチにはいくつかの制限があるにもかかわらず、超解像度の強力な手法の出現への道を示しました。…
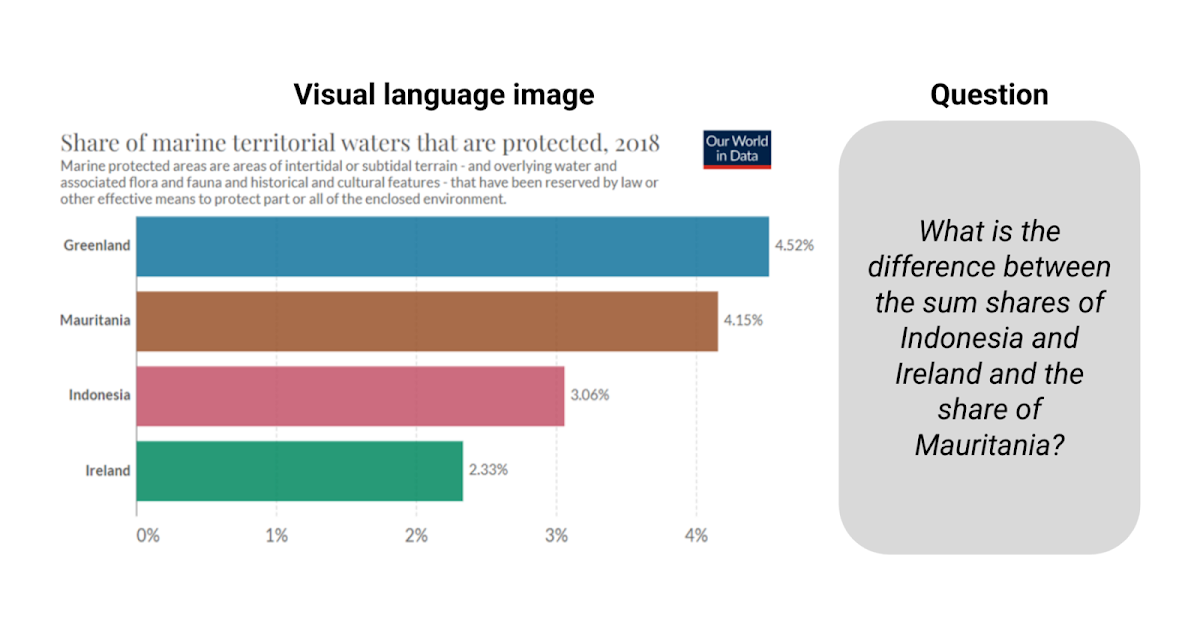
チャートの推論に基づくモデルの基盤
グーグルリサーチのリサーチソフトウェアエンジニア、ジュリアン・アイゼンシュロスによる投稿 ビジュアル言語は、情報を伝えるためにテキスト以外の絵文字を使用するコミュニケーション形式です。アイコノグラフィ、情報グラフィック、表、プロット、チャートなどの形でデジタルライフで普及しており、道路標識、コミックブック、食品ラベルなどの現実世界にも広がっています。このようなメディアをコンピュータがより理解できるようにすることは、科学的コミュニケーションと発見、アクセシビリティ、データの透過性に役立ちます。 ImageNetの登場以来、学習ベースのソリューションを使用してコンピュータビジョンモデルは大きな進歩を遂げてきましたが、焦点は自然画像にあり、分類、ビジュアルクエスチョンアンサリング(VQA)、キャプション、検出、セグメンテーションなどのさまざまなタスクが定義され、研究され、いくつかの場合には人間の性能に達成されています。しかし、ビジュアル言語は同じレベルの注目を集めていません。これは、この分野における大規模なトレーニングセットの不足のためかもしれません。しかし、PlotQA、InfographicsVQA、ChartQAなどの視覚言語イメージにおける質問応答システムの評価を目的とした新しい学術データセットが、ここ数年で作成されています。 ChartQAからの例。質問に答えるには、情報を読み取り、合計と差を計算する必要があります。 これらのタスクに対して構築された既存のモデルは、光学的文字認識(OCR)情報とその座標を大規模なパイプラインに統合することに頼っていましたが、プロセスはエラーが発生しやすく、遅く、一般化が悪いです。既存の畳み込みニューラルネットワーク(CNN)またはトランスフォーマーに基づくエンドツーエンドのコンピュータビジョンモデルは、自然画像で事前にトレーニングされたモデルを簡単にビジュアル言語に適応させることができなかったため、これらの方法が広く使用されていました。しかし、既存のモデルは、棒グラフの相対高さや円グラフのスライスの角度を読み取り、軸のスケールを理解し、色、サイズ、テクスチャでピクトグラムを伝説値に正しくマッピングし、抽出された数字で数値演算を実行するなど、チャートの質問に対する課題には準備ができていません。 これらの課題に対応するために、「MatCha:数学推論とチャートディレンダリングを活用したビジュアル言語の事前トレーニングの強化」という提案を行います。 MatChaは数学とチャートを表す言葉であり、2つの補完的なタスクでトレーニングされたピクセルからテキストへの基礎モデル(複数のアプリケーションでファインチューニングできる組み込み帰納バイアスを備えた事前トレーニングモデル)です。1つはチャートディレンダリングであり、プロットまたはチャートが与えられた場合、画像からテキストモデルはその基礎となるデータテーブルまたはレンダリングに使用されるコードを生成する必要があります。数学推論の事前トレーニングでは、テキストベースの数値推論データセットを選択し、入力を画像にレンダリングし、画像からテキストモデルが回答をデコードする必要があります。また、「DePlot:プロットからテーブルへの翻訳によるワンショットビジュアル言語推論」という、テーブルへの翻訳を介したチャートのワンショット推論にMatChaの上に構築されたモデルを提案します。これらの方法により、ChartQAの以前の最高記録を20%以上超え、パラメータが1000倍多い最高の要約システムに達成します。両方の論文はACL2023で発表されます。 チャートディレンダリング プロットやチャートは、基礎となるデータテーブルとコードによって通常生成されます。コードは、図の全体的なレイアウト(タイプ、方向、色/形状スキームなど)を定義し、基礎となるデータテーブルは実際の数字とそのグループ化を確立します。データとコードの両方がコンパイラ/レンダリングエンジンに送信され、最終的な画像が作成されます。チャートを理解するには、イメージ内の視覚パターンを発見し、効果的に解析してグループ化し、主要な情報を抽出する必要があります。プロットレンダリングプロセスを逆転するには、すべてのこのような機能が必要であり、したがって理想的な事前トレーニングタスクとして機能することができます。 ランダムなプロットオプションを使用して、Airbus A380 Wikipediaページの表から作成されたチャートです。MatChaの事前トレーニングタスクは、イメージからソーステーブルまたはソースコードを回復することです。 チャート、その基礎となるデータテーブル、およびそのレンダリングコードを同時に取得することは、実践的には困難です。事前トレーニングデータを十分に収集するために、[chart、code]および[chart、table]のペアを独立して蓄積します。[chart、code]の場合、適切なライセンスを持つすべてのGitHub IPythonノートブックをクロールし、図を含むブロックを抽出します。図とそれに直前にあるコードブロックは、[chart、code]ペアとして保存されます。[chart、table]のペアについては、2つのソースを調査しました。最初のソースは、合成データで、TaPasコードベースからWebクロールされたWikipediaテーブルを手動でコードに変換します。列のタイプに応じて、いくつかのプロットオプションをサンプリングして組み合わせます。さらに、事前トレーニングコーパスを多様化するために、PlotQAで生成された[chart、table]ペアも追加します。2番目のソースはWebクロールされた[chart、table]ペアです。Statista、Pew、Our World in Data、OECDの4つのWebサイトから合計約20,000ペアを含むChartQAトレーニングセットでクロールされた[chart、table]ペアを直接使用します。 数学的推論 MatChaに数値推論知識を組み込むために、テキスト数学データセットから数学的推論スキルを学習します。事前トレーニングには、MATHとDROPの2つの既存のテキスト数学推論データセットを使用します。MATHは合成的に作成され、各モジュール(タイプ)の質問ごとに200万のトレーニング例を含んでいます。DROPは読解型のQAデータセットで、入力はパラグラフのコンテキストと質問です。 DROPでの質問を解決するには、モデルがパラグラフを読み、関連する数字を抽出し、数値計算を実行する必要があります。私たちは、両方のデータセットが補完的であることを発見しました。MATHには、異なるカテゴリーにわたる多数の質問が含まれており、モデルに明示的に注入する必要がある数学的操作を特定するのに役立ちます。DROPの読解形式は、モデルが情報抽出と推論を同時に実行する典型的なQA形式に似ています。実際には、両方のデータセットの入力を画像にレンダリングします。モデルは答えをデコードするように訓練されます。 MATHとDROPからの例をMatChaの事前トレーニング目的に取り込むことにより、MatChaの数学的推論スキルを向上させます。入力テキストを画像としてレンダリングします。 エンドツーエンドの結果 Webサイト理解に特化した画像からテキストへの変換トランスフォーマーであるPix2Structモデルバックボーンを使用し、上記の2つのタスクで事前トレーニングを行います。MatChaの強みを示すために、表の基礎にアクセスできない質問応答や要約のためのチャートやプロットを含むいくつかの視覚言語タスクで微調整します。MatChaは、以前のモデルの性能を大幅に上回り、基礎となるテーブルにアクセスできると仮定する以前の最先端も上回ります。 以下の図では、チャートと作業するための標準的なアプローチであったOCRパイプラインから情報を取り込んだ2つのベースラインモデルを最初に評価します。最初のものはT5に基づき、2番目のものはVisionTaPasに基づきます。また、PaLI-17BとPix2Structのモデル結果を報告します。PaLI-17Bは、多様なタスクでトレーニングされた大型(他のモデルの約1000倍)のイメージプラステキスト・トゥ・テキスト・トランスフォーマーですが、テキストやその他の視覚言語の読み取り能力に限界があります。最後に、Pix2StructとMatChaのモデル結果を報告します。…

AIの10年間のレビュー
画像分類からチャットボット療法まで

2023 AIインデックスレポート:将来に期待できるAIトレンド
レポートからいくつかの要点があり、これらはAIの将来に備えるための準備をしてくれます

AWS Inferentia2は、AWS Inferentia1をベースにしており、スループットが4倍に向上し、レイテンシが10倍低減されています
機械学習モデル(MLモデル)のサイズ、特に生成AIにとって、大規模言語モデル(LLM)やファウンデーションモデル(FM)のサイズは年々急速に増加しており、これらのモデルにはより高速で強力なアクセラレータが必要ですAWS Inferentia2は、LLMや生成AIの推論のコストを下げつつ、より高いパフォーマンスを提供するように設計されましたこの[...]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.