Learn more about Search Results Discord - Page 14

- You may be interested
- 「マルチラベル分類:PythonのScikit-Lear...
- 2023年のトップビジネスインテリジェンス...
- 「それはすでに人間ができることを遥かに...
- あなたが作るものはあなたそのものです:...
- 「データサイエンスの面接を改善する簡単...
- 「マルチモーダルAIの最新の進歩:(ChatG...
- 「個人データへのアクセス」
- 「Daskデータフレームのパーティションサ...
- 「GitHubツールでデータサイエンスプロジ...
- 「NSFが1,090万ドルの資金を安全なAI技術...
- 「AIチャットボットが言語理解に取り組む」
- 文法AIの向上にBERTを活用する:スロット...
- 「MLパイプラインアーキテクチャのデザイ...
- 「Colabノートブックで自分のLlama 2モデ...
- 「教師なし学習シリーズ — セルフオーガナ...

AI音声認識をUnityで
はじめに このチュートリアルでは、Hugging Face Unity APIを使用してUnityゲームに最先端の音声認識を実装する方法を案内します。この機能は、コマンドの実行、NPCへの話しかけ、アクセシビリティの向上、音声をテキストに変換する必要がある他の機能など、さまざまな用途で使用することができます。 自分自身でUnityで音声認識を試してみるには、itch.ioでライブデモをチェックしてください。 前提条件 このチュートリアルでは、Unityの基本的な知識があることを前提としています。また、Hugging Face Unity APIをインストールしている必要があります。APIの設定手順については、以前のブログ記事を参照してください。 手順 1. シーンの設定 このチュートリアルでは、プレイヤーが録音を開始および停止でき、その結果がテキストに変換される非常にシンプルなシーンを設定します。 まず、Unityプロジェクトを作成し、次の4つのUI要素を持つキャンバスを作成します。 開始ボタン:録音を開始します。 停止ボタン:録音を停止します。 テキスト(TextMeshPro):音声認識の結果が表示される場所です。 2. スクリプトの設定 SpeechRecognitionTestという名前のスクリプトを作成し、空のGameObjectにアタッチします。 スクリプト内で、UIコンポーネントへの参照を定義します。 [SerializeField]…

ギャラリー、図書館、アーカイブ、博物館向けのHugging Face Hub
ギャラリー、図書館、アーカイブ、博物館のためのハギングフェイスハブ ハギングフェイスハブとは何ですか? Hugging Faceは、高品質な機械学習を誰にでもアクセス可能にすることを目指しています。この目標は、広く使われているTransformersライブラリなどのオープンソースのコードライブラリを開発すること、無料のコースを提供すること、そしてHugging Faceハブを提供することなど、さまざまな方法で追求されています。 Hugging Faceハブは、人々が機械学習モデル、データセット、デモを共有しアクセスできる中央リポジトリです。ハブには19万以上の機械学習モデル、3万3000以上のデータセット、10万以上の機械学習アプリケーションとデモがホストされています。これらのモデルは、事前学習済みの言語モデル、テキスト、画像、音声分類モデル、物体検出モデル、さまざまな生成モデルなど、さまざまなタスクをカバーしています。 ハブにホストされているモデル、データセット、デモは、さまざまなドメインと言語をカバーしており、ハブを通じて利用できる範囲を拡大するための定期的なコミュニティの取り組みが行われています。このブログ記事は、ギャラリー、図書館、アーカイブ、博物館(GLAM)セクターで働く人々がハギングフェイスハブをどのように利用して貢献できるかを理解することを目的としています。 記事全体を読むか、最も関連のあるセクションにジャンプすることができます! ハブが何か分からない場合は、「ハギングフェイスハブとは何ですか?」から始めてください。 ハブで機械学習モデルを見つける方法を知りたい場合は、「ハギングフェイスハブの使用方法:ハブで関連するモデルを見つける方法」から始めてください。 ハブでGLAMデータセットを共有する方法を知りたい場合は、「ウォークスルー:GLAMデータセットをハブに追加する方法」から始めてください。 いくつかの例を見たい場合は、「ハギングフェイスハブの使用例」をチェックしてください。 ハギングフェイスハブで何を見つけることができますか? モデル Hugging Faceハブは、さまざまなタスクとドメインをカバーする機械学習モデルへのアクセスを提供しています。多くの機械学習ライブラリがHugging Faceハブとの統合を持っており、これらのライブラリを介して直接モデルを使用したりハブに共有したりすることができます。 データセット Hugging Faceハブには3万以上のデータセットがあります。これらのデータセットには、テキスト、画像、音声、マルチモーダルなど、さまざまなドメインとモダリティがカバーされています。これらのデータセットは、機械学習モデルのトレーニングや評価に価値があります。 スペース Hugging Face…

Hugging Faceのパネル
私たちは、PanelとHugging Faceのコラボレーションを発表できることを喜んでいます!🎉 Hugging Face SpacesにPanelのテンプレートを統合しました。これにより、Panelアプリを簡単に構築し、Hugging Face上で簡単にデプロイすることができます。 Panelは何を提供していますか? Panelは、Pythonで強力なツール、ダッシュボード、複雑なアプリケーションを簡単に構築できるオープンソースのPythonライブラリです。PyDataエコシステム、パワフルなデータテーブルなどがすぐに利用できるようになっています。高レベルのリアクティブAPIと低レベルのコールバックベースのAPIにより、探索的なアプリケーションを素早く構築することができます。また、複雑なマルチページアプリケーションや豊富な相互作用を持つアプリケーションを構築することも制限されません。PanelはHoloVizエコシステムの一員であり、データ探索ツールの連携エコシステムへのゲートウェイです。Panelは、他のHoloVizツールと同様に、NumFocusがスポンサーとなっており、AnacondaとBlackstoneからのサポートを受けています。 以下は、私たちのユーザーが価値を見出しているPanelのいくつかの注目すべき機能です。 Panelは、Matplotlib、Seaborn、Altair、Plotly、Bokeh、PyDeck、Vizzuなど、さまざまなプロットライブラリに広範なサポートを提供しています。 すべての相互作用は、Jupyterとスタンドアロンのデプロイメントで同じように機能します。Panelは、Jupyterノートブックからダッシュボードにコンポーネントをシームレスに統合することができ、データ探索と結果の共有の間でスムーズな移行を実現します。 Panelは、複雑なマルチページアプリケーション、高度な相互作用機能、大規模データセットの可視化、リアルタイムデータのストリーミングを構築することができます。 PyodideとWebAssemblyとの統合により、PanelアプリケーションをWebブラウザでシームレスに実行することができます。 Hugging FaceでPanelアプリを構築する準備はできましたか?Hugging Faceのデプロイメントドキュメントをチェックして、このボタンをクリックして旅を始めましょう: 🌐 コミュニティに参加しましょう Panelコミュニティは活気があり、サポートが充実しており、経験豊富な開発者やデータサイエンティストが知識を共有したり、助け合ったりすることを楽しみにしています。以下の方法で参加し、私たちとつながりましょう: Discord Discourse Twitter LinkedIn Github

2023年の最高のサイバーセキュリティニュースレター
サイバーセキュリティのニュースレターは、幅広いトピックをカバーし、さまざまな読者のニーズに対応していますこの分野で先を見越したいと思っている人にとって、非常に役立ちます

SalesforceはXGen-7Bを導入:1.5Tトークンのために8Kシーケンス長でトレーニングされた新しい7B LLMを紹介します
最近の人工知能の技術的なブレークスルーにより、Large Language Models(LLMs)はますます一般的になっています。過去数年間、研究者たちは、これらのモデルを膨大な量のデータでトレーニングして、複雑な言語関連のタスクを解決するための急速な進歩を遂げてきました。これには、複雑な言語パターンの理解、連続した回答の生成などが含まれます。特に研究者や開発者の関心を引いている研究の1つは、LLMsの長文コンテンツの取り扱いにおける応用です。これらのタスクの例は、テキストの要約やコードの生成などの比較的単純なタスクから、タンパク質の構造予測や情報検索などのより複雑な問題の記述まで様々です。長いテキストのシーケンスには、段落、表、画像などさまざまな形式の情報が含まれているため、LLMsはこれらの要素を処理し理解するためにトレーニングされなければなりません。さらに、長距離の構造的依存関係を効果的に考慮することで、LLMsはテキストの異なる部分間の関連性を特定し、最も関連性の高い情報を抽出することができます。したがって、より広範な知識に触れることで、LLMsはユーザーのクエリにより正確で文脈に即した回答を提供することができます。 しかし、数多くの潜在的なユースケースにもかかわらず、MetaのLLaMAからMosaicMLのMPT LLMモデルに至るまで、ほとんどのオープンソースのLLMsは、最大2Kトークンのシーケンスでトレーニングされています。この制限は、より長いシーケンスのモデリングにおいて大きな課題を提起します。さらに、モデルのスケーリングに関する以前の研究は、固定された計算予算が与えられた場合、トークン数が多いほど小さなモデルの方が大きなモデルよりも優れたパフォーマンスを発揮することを示しています。したがって、現在の進歩と課題に着想を受けて、Salesforce ResearchはXGen-7Bを導入し、1.5兆トークンの8Kシーケンス長でトレーニングされた一連の7B LLMsにおいて画期的な成果を上げました。このモデルシリーズには、4Kシーケンス長に対応するXGen-7B-4K-Base、8Kシーケンス長に対応するXGen-7B-8K-Base、および公開用の教育データでファインチューニングされたXGen-7B-8k-Instが含まれています(研究目的のみで公開されています)。これらのLLMsの注目すべき特徴は、XGenがMPT、Falcon、LLaMAなどといった同様のサイズの最先端のLLMsと比較して、標準のNLPベンチマークで同等または優れた結果を達成することです。 この研究で使用されたXGen-7bモデルは、Salesforceの独自のライブラリJaxFormerを使用してトレーニングされました。このライブラリは、TPU-v4ハードウェアに最適化されたデータとモデルの並列処理を利用した、効率的なLLMのトレーニングを可能にします。トレーニングプロセスはLLaMAのガイドラインに従い、さらに2つの追加の調査を行いました。最初の調査は「損失スパイク」の理解に焦点を当てました。これは、トレーニング中に損失が突然一時的に増加する現象であり、明確な原因がない状態です。これらのスパイクの原因はまだ不明ですが、研究者は「順次回路の並列化」、「swish-GLUの使用」、「RMS-Normの使用」などがトレーニングの不安定性に寄与する可能性があると特定しました。2つ目の調査はシーケンス長に関連しています。自己注意の二次の計算量のため、より長いシーケンスでのトレーニングは計算コストが著しく増加するため、段階的なトレーニングアプローチが採用されました。トレーニングは最初にシーケンス長2kの800Bトークンから始まり、次にシーケンス長4kの400Bトークン、最後にシーケンス長8kの300Bトークンを対象としました。 XGen-7b 8kモデルの長い文脈の理解能力を評価するために、研究者たちは3つの主要なタスクで評価を行いました。それらのタスクは、長い対話生成、テキストの要約、および質問応答です。研究者は、対象のタスクの難しさに基づいて、インストラクションに調整されたモデルを使用しました。長い対話生成に関しては、AMIミーティングの要約、ForeverDreaming、およびTVMegaSiteの脚本の要約の3つのタスクを評価に使用しました。すべての指標において、XGen-7B-instモデルは他のいくつかのインストラクションに調整されたモデルと比較して最高のスコアを達成し、優れたパフォーマンスを示しました。 長文の質問応答に関しては、研究者は物理学、工学、歴史、エンターテイメントなどさまざまなトピックをカバーするウィキペディアのドキュメントを基にChatGPTを使用して質問を生成しました。質問と元の文書の関連性、構成、および関連性に基づいて、256トークンのLLM生成された回答をGPT-4で評価しました。このシナリオでは、2kトークンに制限されたベースラインモデルに比べて、XGen-7B-8k-Instモデルのパフォーマンスが優れていることが示されました。テキストの要約に関しては、研究者は会議の会話と政府の報告書という2つの異なるドメインのデータセットを使用してXGen-7bモデルを評価しました。その結果、XGen-7bモデルはこれらのタスクで他のベースラインモデルを大幅に上回り、テキストの要約でも優れたパフォーマンスを発揮することが示されました。 評価により、XGen-7bモデルは、長い文脈を理解する能力に優れており、長い対話生成、質問応答、テキスト要約など、さまざまなタスクで優れた性能を発揮しました。その性能は、他の指示に調整されたモデルやベースラインモデルを上回り、広範なテキスト文脈での理解力と連続した応答生成能力を示しています。ただし、その効果的さにもかかわらず、XGenモデルには制約があることが研究者によって認識されており、バイアスが免除されず、有害な応答を生成する可能性があります。これは、他の多くのAIモデルと共有する特徴です。Salesforce Researchはまた、コードをオープンソース化して、コミュニティが研究内容を探求できるようにしています。 SF BlogとGithub Linkをチェックしてください。最新のAI研究ニュース、素晴らしいAIプロジェクトなどを共有している25k+ ML SubReddit、Discord Channel、Email Newsletterにもぜひ参加してください。上記の記事に関する質問や見落としがある場合は、お気軽に[email protected]までメールでお問い合わせください。

ベストAI画像生成器(2023年7月)
多くのビジネスの景色が人工知能によって変わりつつあり、画像作成もその一つです。 AI画像生成器は、テキストをグラフィックに変換するための人工知能アルゴリズムを使用します。これらのAIツールは、数秒で思考やアイデアを素早く視覚化するための素晴らしい手段です。 では、どのAI画像生成器が試す価値があるのでしょうか?2023年に利用可能ないくつかの優れたAI画像生成器を紹介します。 Shutterstock AI Image Generator Shutterstock AI Image Generatorは、デザインの世界において画期的な存在です。AIの力を活用することで、ユーザーは驚くべき美しいデザインを簡単に作成することができます。この素晴らしい新機能は、OpenAIとのパートナーシップによって実現しました。OpenAIはDALL-E 2技術を提供し、Shutterstockの画像とデータを使用してトレーニングされたこのソフトウェアは、完全にライセンス可能な画像を生成します。このブレイクスルーは、アート界にとって大きな意味を持ちます。他人の知的財産権を侵害することなく、AI生成のアートを使用することができるためです。倫理的なアート作品がわずか数秒でダウンロード可能な状態で用意されており、創造性を発揮するのに最適な時期です。Shutterstockの無料トライアルオファーでは、最大10枚のAI生成画像を無料で入手できます! FotorAI Image Generator FotorAI Image Generatorは、人工知能(AI)技術を使用して新鮮な写真を作成するツールです。ユーザーはサンプル画像を入力することで、それを元に全く新しいオリジナル画像を作成します。この機能によって生成される新しい写真は、非常にリアルで高品質だと主張されており、Generative Adversarial Network(GAN)を使用して生成されます。これは、グラフィックデザインやデジタルアートのための新鮮な画像を作成するためなど、さまざまな用途で使用することができます。Fotorのプレミアムバージョンでしか利用できません。 Nightcafe Nightcafeは最高のAIテキストから画像への生成器であり、キーワードをクリエイティブでリアルな画像に変換します。最も基本的な英単語だけを使用して、希望するものを正確に表現するカスタマイズされたグラフィックを作成することができます。Nightcafeはさまざまなクリエイティブやスタイルも提供しており、一般的な画像を芸術作品に変換するためにニューラルスタイル変換を利用することもできます。Nightcafeの使いやすいソフトウェアは初心者にも非常にアクセスしやすくなっています。使いやすく魅力的なウェブサイトデザインにより、誰でもクリックひとつで画像を作成し改善することができます。作成した作品をどこか別の場所に保存する必要はありません。それは常にアカウントに保管されます。 Dream By…
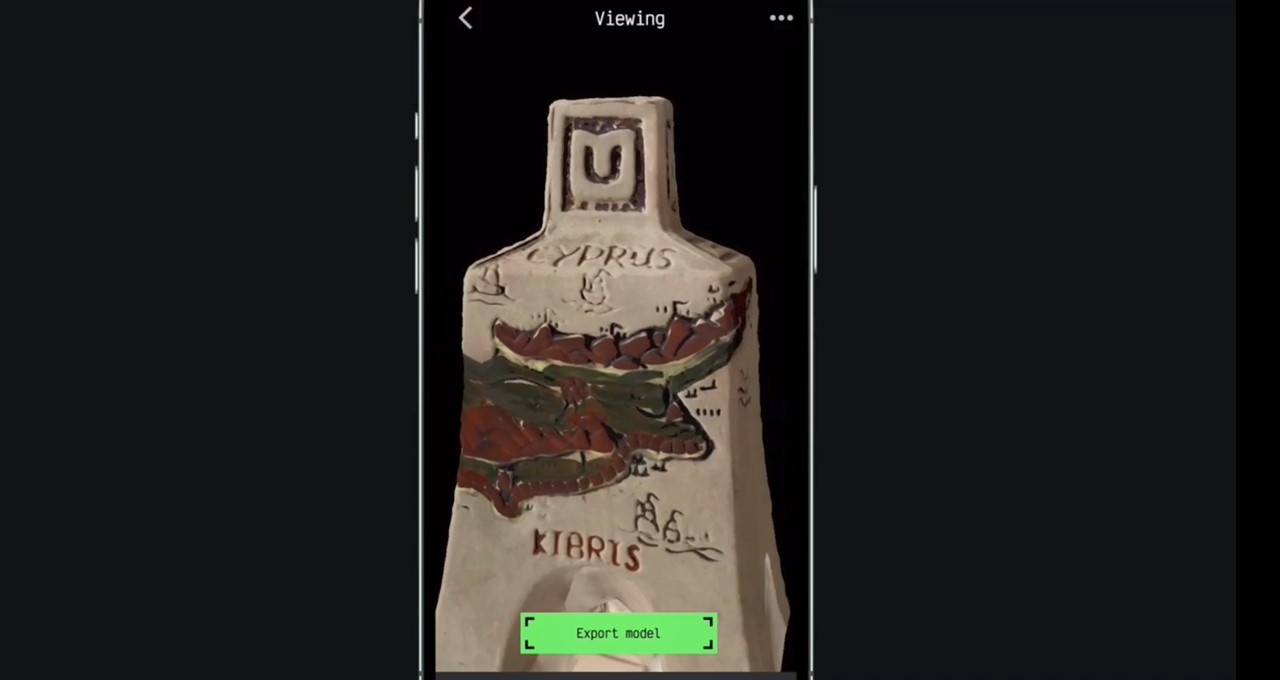
オムニヴォアに出会おう:スタートアップが開発したアプリは、スマートフォンだけでオブジェクトを3Dモデルに変換することができます
編集者注:この投稿は、NVIDIA Omniverse(Universal Scene Description、OpenUSDとも呼ばれる)上に構築された開発プラットフォームを使用して、3Dワークフローを加速し、仮想世界を作成する個々のクリエイターや開発者を紹介するMeet the Omnivoreシリーズの一部です。 拡張現実(AR)がグローバルにより普及し、アクセスしやすくなるにつれ、Kiryl Sidarchuk氏は現実世界と仮想世界の境界を消すのを手伝っています。 Kiryl Sidarchuk NVIDIA Inceptionプログラムの先進的なスタートアップのメンバーであるAR-Generationの共同創業者兼CEOであるSidarchuk氏は、自社が開発したAIベースの3DスキャナーアプリMagiScanを開発しました。 ユーザーはスマートフォンのカメラで任意のオブジェクトをキャプチャし、すばやく高品質かつ詳細な3Dモデルを作成し、ARまたはメタバースアプリケーションで使用できます。 AR-Generationは現在、MagiScanからNVIDIA Omniverseに直接3Dモデルをエクスポートする拡張機能を提供しています。これにより、デジタルコンテンツ作成ツール間で共通の言語である拡張可能なフレームワークであるUniversal Scene Description、OpenUSDにより、スピードと容易さが実現されます。 「拡張現実は日常生活の重要な一部になります」と、シドアルチュク氏は言います。 「当社のアプリをカスタマイズして、実世界のオブジェクトに基づく3Dモデルを直接Omniverseにエクスポートできるようにしました。これにより、ユーザーはARでモデルを展示し、メタバースまたはゲームに統合できます。 Omniverseの拡張機能は、人気のあるPythonまたはC++プログラミング言語を使用して、誰でもOmniverseアプリの機能を作成および拡張できるコアの構築ブロックです。 シドアルチュク氏によると、NVIDIA Inceptionのメンバーであることの利点として、簡単にアクセスできるドキュメント、NVIDIAチームからの技術的な支援、無料のAWSクレジット、AI駆動の他の企業とのネットワーキングの機会が挙げられます。AR-Generationにとって、拡張機能を構築することは簡単で便利だったとシドアルチュク氏は語りました。 リアルワールドオブジェクトからの3Dモデルのキャプチャ、クリック、および作成 シドアルチュク氏によると、MagiScanは、デザイナーが手動で行うよりも10倍速く、最大100倍のコストでオブジェクトから3Dモデルを作成できます。…

Twitterの後
問題を抱えたTwitterに挑戦するために、新しいソーシャルアプリが現れている

公共関係(PR)における10以上のAIツール(2023年)
ChatGPT 簡単に説明すると、ChatGPTは、AIによる会話型ユーザーインターフェースです。ユーザーからの入力を受け取り、分析して回答を生成します。OpenAIテクノロジーにより、マシンは書かれた言語と口頭言語の両方を理解できます。決められた回答をすることも、ユーザーに空欄を埋めるように要求することもできます。機械学習と自然言語処理を採用しているため、このテクノロジーは消費者と意味のある対話をする可能性があります。システムの柔軟性により、顧客サービス、バーチャルエージェント、チャットボットなど、さまざまな設定に適用できます。ChatGPTは、OpenAIテクノロジーを活用して、ユーザーが要求を理解し、実現するための会話型AIシステムを提供しています。 Midjourney Midjourneyは強力な機能と迅速な画像合成のため、最高の人工知能画像生成ツールの1つです。MidjourneyにSMSコマンドを送信するだけで、あとはMidjourneyが処理します。多くのクリエイティブプロフェッショナルが、Midjourneyを使用して、自分たちの仕事にインスピレーションを与える画像を生成しています。Midjourneyで作成された人工知能作品「Théâtre d’Opéra Spatial」は、20人の他の画家を抑えて、コロラド州の博覧会の美術部門で1位を獲得しました。ただし、現在のMidjourneyのホームはDiscordサーバーです。MidJourney Discordサーバーに参加し、ボットのコマンドを利用して画像を作成する必要があります。ただし、すぐに始めることができます。 Brandwatch メディアモニタリングがクライアントの優先事項である場合、Brandwatchはあなたの人工知能ソーシャルリスニングソリューションです。Brandwatchは、あなたの会社に関する書かれた言及と、ロゴや製品の視覚的表現をモニターするためにAIを使用しています。彼らの洗練されたテキスト分析ツールは、ユーザーがあなたのブランドに関するコメントが好意的、悪い、または中立的かどうかを判断することもでき、これらすべての指標を追跡することが容易になっています。 Cleanup.pictures Cleanup.picturesは、AIを搭載した写真編集アプリケーションで、写真から望ましくないオブジェクト、人、テキスト、欠陥を削除することができます。簡単に学習でき、品質を損なうことなく数秒で写真を修正することができます。写真家、広告会社、不動産業者、オンライン小売業者、テキスト、ロゴ、またはウォーターマークを取り除く必要がある人など、さまざまな人々がこのツールを利用できます。Adobe Photoshopのクローンツールとは異なり、このプログラムは、不要なテキスト、人物、オブジェクトの背後に何があるかを正確に特定することができます。任意の解像度の画像をインポートして編集することができます。無料版ではエクスポート解像度が720pxに制限されていますが、Pro版にはそのような制限はありません。 Looka Lookaは、AIによるブランドアイデンティティプラットフォームを使用して、努力を最小限に抑えて洗練されたロゴとブランドアイデンティティを作成できます。ロゴジョイの再ブランド版であるLookaは、無料で利用できます。プロセスは、人工知能を利用して素早く数百の潜在的なロゴデザインを生成するロゴメーカーから始まります。ユーザーは、レイアウトを自分好みに変更することができます。ブランドキットでは、ロゴ、色、フォントを活用して、数十、場合によっては数百の統一されたプロモーション用品を簡単かつ迅速に作成することができます。名刺、ソーシャルメディアプロファイル、メール署名、その他のサンプルドキュメントがブランドキットに含まれています。人工知能によって動作するプラットフォームであるLookaのユーザーは、YouTube、Twitter、Facebookなど、多くのソーシャルメディアプラットフォーム上のプロフィール画像とカバー画像を変更することができます。 Canva Canvaの無料画像作成ツールを使用することで、製品マネージャーがどのように利益を得ることができるかが簡単に理解できます。ステークホルダーミーティング、製品発売などでプレゼンテーションやデッキ用の関連画像を入手することは常に難しい課題でした。時には、望んでいるものの完璧なビジョンがあるにもかかわらず、作業中のストック画像を修正する必要があります。CanvaのAIによるエディターを使用すると、コンテンツを事前に計画し、アイデアを生成し、入力に応じて完璧なグラフィックを見つけるために検索結果を調整することができます。 TLDR この最新のAI搭載Webツールは、記事、文書、エッセイ、論文などの長文を簡潔で情報量の多い段落に自動的に要約することができます。試験勉強をする学生、素早く記事を要約したい作家、生徒に長いドキュメントや章を要約する必要がある教師、新聞や雑誌の長い記事を要約する必要があるジャーナリストなど、すべての人々がこのツールを利用できます。TLDRは、広告、ポップアップ、グラフィックなどのオンライン上の邪魔な要素を取り除き、テキストの主要なアイデアを選択し、弱い議論、未サポートの推測、派手なフレーズ、無駄な注意をそらすものなど、不要な材料を除去することによって、きれいで焦点の合った読書体験を提供します。 ヒント ヒントは人工知能(A.I.)を活用した生産性ツールで、他のアプリと同期して、やるべきこと、ノート、取引、スケジュールを管理するのに役立ちます。Notion、Obsidian、Trello、ClickUp、Hubspot、Pipedrive、Google Calendar、Jiraなどのサービスが統合できます。Telegram、WhatsApp、SMSなどのお気に入りのメッセージングアプリでヒントを見つけることができます。また、ボイスメールを残すこともできます。様々なサービスに接続することで、飛行中にデータを作成、更新、引き出す能力が可能になり、ビジネスと個人の生活をシングルインターフェイスで効率的に管理することができます。ヒントの多くの潜在的な応用例は、プロジェクト管理、販売、CRM管理、ノート取り、情報管理、個人の整理などです。ヒントは、他の人気のあるサービスと統合し、A.I.を利用して、日常的なタスクの効率を改善することで、時間と労力を節約することを目的としています。 DeepL 信頼性の高い翻訳者が必要な場合は、AIを搭載したDeepL翻訳を利用してください。PDF、Word文書、PowerPointプレゼンテーションなど、31の他の言語にテキストやファイル全体を翻訳することができます。技術が言語を迅速かつ自動的に認識できるため、翻訳プロセスは短く、結果は信頼できます。DeepLには、クイック定義用の辞書や用語集もあります。DeepLは、デスクトップコンピュータ、モバイルデバイス、またはChrome拡張機能からアクセスできるため、外出先の消費者にとっては優れたツールです。DeepLは、毎日何百万人もの人々によって最も広く使用されている翻訳ツールの一つです。 Otter.AI…

このAI論文は、自律走行車のデータセットを対象とし、コンピュータビジョンモデルのトレーニングの匿名化の影響を研究しています
画像匿名化とは、プライバシー保護のために画像から機密情報を変更または削除することです。プライバシー規制に準拠するために重要ですが、匿名化はしばしばデータ品質を低下させ、コンピュータビジョンの開発を妨げます。データ劣化、プライバシーとユーティリティのバランス、効率的なアルゴリズムの作成、モラルと法的問題の調整など、いくつかの課題が存在します。プライバシーを確保しながらコンピュータビジョンの研究とアプリケーションを改善するために、適切な妥協点を見つける必要があります。 画像の匿名化に関する以前のアプローチには、ぼかし、マスキング、暗号化、クラスタリングなどの従来の方法が含まれています。最近の研究では、生成モデルを使用してアイデンティティを置き換えることにより、現実的な匿名化に焦点が当てられています。しかし、多くの方法には匿名性の正式な保証がなく、画像の他の手がかりでアイデンティティが明らかになることがあります。さまざまな影響を持つタスクによって、コンピュータビジョンモデルに与える影響を探究した限られた研究が行われています。公開された匿名化されたデータセットはまれです。 最近の研究では、ノルウェー科学技術大学の研究者が、自律型車両の文脈での重要なコンピュータビジョンタスク、特にインスタンスセグメンテーションおよび人物姿勢推定に注目しました。彼らはDeepPrivacy2に実装されたフルボディと顔の匿名化モデルの性能を評価し、現実的な匿名化アプローチと従来の方法の効果を比較することを目的としました。 記事で評価された匿名化の影響を評価するために提案された手順は次のとおりです。 一般的なコンピュータビジョンデータセットの匿名化。 匿名化されたデータを使用してさまざまなモデルをトレーニングする。 元の検証データセットでモデルを評価する。 著者らは、ぼかし、マスクアウト、現実的な匿名化の3つのフルボディと顔の匿名化テクニックを提案しています。インスタンスセグメンテーション注釈に基づいて匿名化領域を定義します。従来の方法にはマスキングアウトとガウスぼかしがあり、現実的な匿名化にはDeepPrivacy2からの事前トレーニング済みモデルが使用されます。著者らはまた、ヒストグラム均等化と潜在最適化を介してフルボディ合成のグローバルコンテキストの問題にも取り組んでいます。 著者らは、COCOポーズ推定、Cityscapesインスタンスセグメンテーション、BDD100Kインスタンスセグメンテーションの3つのデータセットを使用して匿名化されたデータでトレーニングされたモデルを評価する実験を実施しました。顔の匿名化技術はCityscapesとBDD100Kデータセットにおいてほとんど性能に差がありませんでした。しかし、COCOポーズ推定において、マスクアウトとぼかしの両方が人体との相関関係により性能の大幅な低下を引き起こしました。フルボディの匿名化は、従来の方法でも現実的な方法でも、元のデータセットと比較して性能が低下しました。現実的な匿名化はより優れていましたが、キーポイント検出のエラー、合成の制限、グローバルコンテキストの不一致により、結果が低下しました。著者らはまた、モデルサイズの影響を探究し、COCOデータセットの顔の匿名化において、大きなモデルほど性能が低下することがわかりました。フルボディの匿名化においては、標準的および多変量切り捨て法の両方が性能の向上につながりました。 結論として、この研究は、自律型車両のデータセットを使用してコンピュータビジョンモデルをトレーニングする際に匿名化が及ぼす影響を調査しました。顔の匿名化はインスタンスセグメンテーションにほとんど影響を与えず、フルボディの匿名化は性能を大幅に低下させました。現実的な匿名化は従来の方法よりも優れていましたが、本物のデータの完全な代替品ではありません。モデルのパフォーマンスを損なわずにプライバシーを保護することが重要であることが示されました。この研究は注釈に依存しており、モデルアーキテクチャに制限があるため、匿名化技術を改善し、合成の制限に対処するためのさらなる研究が求められています。自律型車両での人物の合成における課題も指摘されました。 論文をチェックしてください。最新のAI研究ニュース、クールなAIプロジェクトなどを共有する、25k以上のML SubReddit、Discordチャンネル、およびメールニュースレターに参加することをお忘れなく。上記の記事に関する質問や、何か見落としていることがある場合は、[email protected]までメールでお問い合わせください。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.