Learn more about Search Results ボタン - Page 14

- You may be interested
- このAI論文は、「Vary」という新しいアプ...
- Streamlitの新しいConnections機能とイン...
- 「OLAP vs. OLTP:データ処理システムの比...
- 「アジア太平洋地域でAIスタートアップを...
- 『FastSpeech:論文の概要と実装』
- この AI ペーパーでは、X-Raydar を発表し...
- 「ChatGPTを金融業務に活用する10の方法」
- デジタル変革によって打撃を受ける可能性...
- テックの雇用削減はAI産業について何を示...
- ビジネスにおけるAIパワードのテキストメ...
- 「Amazon SageMakerを使用して、生成AIを...
- このAI研究では、LSS Transformerを発表し...
- pd.read_htmlの良い点と悪い点、そして醜い点
- YOLOV8によるANPR
- これがP-Hackingの解決策ですか?

「クロスブラウザテストが適切に実施されない場合、何が起こるか」
クロスブラウザーテストはWeb開発の重要な一部ですが、しばしば適切な注目を受けません十分なクロスブラウザーテストを行わないことは、複数のWebブラウザとデバイスが共存する時代において、オンラインアプリケーションやウェブサイトに重大な影響を及ぼす可能性がありますこの記事では、クロスブラウザーテストを適切に実施しない場合の可能性のある結果について掘り下げます

「野心的なAI規制に対する力強いプロセス:オックスフォード研究からの3ステップソリューション」
「もしアカウンタブルマネージャーやプロダクトオーナー、プロジェクトマネージャー、もしくはデータサイエンティストで、AIプロジェクトに関与している場合、Oxford ResearchはあなたをAI規制の重要な関係者として特定しました先行スタートを切りましょう…」

ファッションにおけるGenAI | Segmind Stable Diffusion XL 1.0アプローチ
イントロダクション ファッション業界も例外ではなく、消費者の変化する好みに合わせて革新の最前線に留まる方法を模索してきました。もしファッションに興味があり、ファッションフリークであるなら、安定した拡散器の能力を考慮するべきです。セグマインドAPIは、この可能性を容易にします。人工知能(AI)は、デザイナーが製品を作成し、マーケティングし、販売する方法を変えることで、ファッション界においてゲームチェンジャーとして現れました。このブログでは、ファッション業界におけるセグマインドステーブルディフュージョンXL 1.0アプローチとGenAIの意義について探求します。 学習目標 生成型人工知能(Generative Artificial Intelligence)の紹介 ステーブルディフュージョンのアイデア ファッショニスタ向けのGenAIのアプリケーションとユースケース ファッションにおけるステーブルディフュージョンの特徴と可能性 GenAI倫理の概観 この記事は、データサイエンスブログマラソンの一環として公開されました。 生成型AI 生成型人工知能は、過去に学んだ類似性を利用して、これまで存在しなかった新しいアイデアを生成するアプローチを利用するAIの分野です。たとえば、綿のキャラクターにトレーニングされた新しいカートゥーンの画像を生成するGenAIモデルが見られます。AIで行われるように新しい画像を単にカートゥーンかどうかで分類するのではなく、GenAIはトレーニングされた過去の画像を含まない新しいカートゥーン画像を生成することができます。これにより、さまざまな可能性が開かれます。この記事では、ファッショニスタがSegmindモデルを使用する可能性について考えます。 AIとファッションの交差点 先に述べたように、ファッションはクリエイティビティ、トレンド、消費者の好みによって常に進化しています。従来、デザイナーやファッションハウスは、新しいスタイルやコレクションを作成するために人間のクリエイティビティに頼ってきました。このプロセスは時間がかかり、イノベーションを制限することがあります。ここでGenAIが登場するのです。 ファッションにおける生成型AIは、強力なアルゴリズムと膨大なデータセットを活用して、ユニークで革新的なデザイン、パターン、スタイルを生成します。また、ファッションデザイナーやブランドは、クリエイティブなプロセスを効率化し、生産時間を短縮し、新しいクリエイティブなアイデアを探求することも可能にします。 SegmindステーブルディフュージョンXL 1.0の紹介 セグマインドには、さまざまなGenAIタスク用の多様なモデルがあり、そのまま使用できます。これらのモデルはウェブサイトで利用可能で、各オプションに簡単にアクセスできるように構成されています。ランディングページでは、「モデル」のナビゲーションバーからモデルのリストに移動することができます。これにより、特定のユースケースに適したモデルを簡単に見つけることができます。 SegmindステーブルディフュージョンXL 1.0モデルは、ファッショニスタ向けのアプローチを提供します。Segmindの素晴らしい点は、アプリにシームレスに統合できる無料および有料のAPIキーも提供していることです。これは、ファッションアプリ、ウェブサイト、またはプライベートファッションハウスなどになります。これらのいずれも必要ない場合は、プレイグラウンドにアクセスすることもできます。プレイグラウンドでは、プロンプトを入力し、ダウンロードのための画像を表示するために単一のボタンをクリックするだけで済みます。 このモデルにはさまざまなユースケースがありますが、この記事ではファッショニスタ向けの使用方法について探求します。 ステーブルディフュージョンXL…

「タンパク質設計の次は何か?マイクロソフトの研究者がエボディフ:シーケンスファーストのタンパク質エンジニアリングのための画期的なAIフレームワークを紹介」
ディープ生成モデルは、新規タンパク質のインシリコ創造において、ますます有効なツールとなっています。拡散モデルは、最近の研究で、自然界で見られる実際のタンパク質とは異なる生理学的に妥当なタンパク質を生成することが示された生成モデルの一種であり、デノボタンパク質設計において比類のない能力と制御を可能にします。ただし、現在の最先端のモデルはタンパク質構造を構築するため、トレーニングデータの幅を制限し、生成をタンパク質設計空間のごく一部で行うことに制約を受けます。マイクロソフトの研究者は、進化的スケールのデータと拡散モデルの独自の条件付け能力を組み合わせることで、チューナブルなタンパク質生成をシーケンス空間で実現する汎用の拡散フレームワークであるEvoDiffを開発しました。EvoDiffは、構造的に妥当なタンパク質を多様に作り出し、可能なシーケンスと機能の全範囲をカバーすることができます。シーケンスベースの定式化の普遍性は、EvoDiffが構造ベースのモデルではアクセスできないタンパク質を構築できること、例えば無秩序なセクションを持つタンパク質や有用な構造モチーフのためのスキャフォールドを設計できることによって示されています。彼らは、EvoDiffがタンパク質工学におけるプログラマブルなシーケンスファースト設計の道を切り拓くことを期待しています。 EvoDiffは、進化的スケールのデータセットと拡散モデルを組み合わせて、シーケンスデータだけからプログラマブルなタンパク質生成のための革新的な生成モデリングシステムです。彼らは、前方プロセスがタンパク質の配列を繰り返し変更することによってタンパク質の配列を逐次的に破損させる離散的な拡散フレームワークを使用し、ニューラルネットワークによってパラメータ化された学習済みの逆プロセスが各反復で行われた変更を予測することで、タンパク質をトークンのシーケンスとしてフレーム化しているアミノ酸言語上の離散的なトークンのシーケンス。 プロテインのシーケンスは、逆メソッドを使用してゼロから作成することができます。タンパク質構造設計に従来使用されてきた連続的な拡散定式化と比較して、EvoDiffで使用されている離散的な拡散定式化は、数学的に重要な改善として際立っています。複数の配列アラインメント(MSA)は、関連するタンパク質群のアミノ酸配列の変異の保存パターンを示し、単一のタンパク質配列の進化的なリンクを捉えることができます。この進化的な情報のさらなる深さを活用するために、彼らはMSAでトレーニングされた離散的な拡散モデルを構築し、新しい単線を生成します。 チューナブルなタンパク質設計の有効性を示すために、研究者は、さまざまな世代活動のスペクトルでシーケンスとMSAモデル(それぞれEvoDiff-SeqとEvoDiff-MSA)を調査します。彼らは、EvoDiff-Seqが自然界のタンパク質の組成と機能を正確に反映した高品質で多様なタンパク質を信頼性良く生成することを示します。EvoDiff-MSAは、類似したがユニークな進化の歴史を持つタンパク質をアラインメントすることにより、新しい配列のガイド付き開発を可能にします。最後に、EvoDiffは、構造ベースの生成モデルの主要な制約を直接克服することができるIDRを持つタンパク質を信頼性良く生成し、拡散ベースのモデリングフレームワークの条件付け能力と普遍的な設計空間に基づいて、明示的な構造情報なしで機能的な構造モチーフのスキャフォールドを生成することができます。 シーケンス制約に基づいて調整可能な多様な新しいタンパク質を生成するために、研究者はEvoDiffという拡散モデリングフレームワークを提案しています。構造ベースのタンパク質設計のパラダイムに挑戦することにより、EvoDiffは、シーケンスデータから本質的に無秩序な領域を生成し、スキャフォールド構造モチーフを生成することで、構造的に妥当なタンパク質の多様性を無条件にサンプリングすることができます。タンパク質の配列進化において、EvoDiffは拡散生成モデリングの有効性を示す最初のディープラーニングフレームワークです。 作成されたシーケンスが望ましい特性を満たすように反復的に調整されるガイド付きの条件付けは、将来の研究でこれらの機能に追加することができます。EvoDiff-D3PMフレームワークは、各デコーディングステップでシーケンスの各残基のアイデンティティを編集することができるため、ガイダンスによる条件付けが働くために適しています。ただし、研究者は、OADMが一般的にD3PMよりも無条件の生成で優れたパフォーマンスを発揮することを観察しており、おそらくOADMのノイズ除去タスクの方がD3PMよりも学習しやすいためです。残念ながら、既存の条件付きLRARモデルであるProGen(54)などのOADMや他の既存の条件付きLRARモデルによって、ガイダンスの有効性が低下することが観察されています。EvoDiff-D3PMを機能目標で条件付けることによって、新しいタンパク質の配列が生成されることが期待されています。 EvoDiffのデータ要件の最小限は、構造ベースのアプローチでは可能ではなかった、将来の応用に容易に適応できることを意味します。研究者は、EvoDiffが微調整なしでIDRを含んだインペインティングを通じて生成できることを示し、構造ベースの予測モデルや生成モデルの古典的な落とし穴を回避することができます。大規模なシーケンスデータセットの構造を取得する高コストは、ディスプレイライブラリや大規模スクリーンなどのアプリケーション固有のデータセットでEvoDiffを微調整することで解放されるかもしれない、新しい生物学的、医学的、または科学的な設計オプションの使用を妨げる可能性があります。AlphaFoldなどの関連するアルゴリズムは、多くの配列に対して構造を予測することができますが、ポイント変異には苦労し、見かけのタンパク質の構造を示す際に過信することがあります。 研究者たちは、プロテインの機能をより細かく制御するために、EvoDiffはテキスト、化学情報、または他のモダリティに基づいて条件付けることができます。将来的には、このチューナブルなプロテイン配列設計の概念は、さまざまな方法で活用されるでしょう。例えば、条件付きで設計された転写因子やエンドヌクレアーゼを使用して、核酸をプログラム的に調節することができます。生物学的製剤は、in vivoでの配送とトラフィックへの最適化が可能になります。また、酵素-基質の特異性のゼロショットチューニングは、新たな触媒の可能性を開くことができます。 データセット Uniref50は、研究者によって使用される約4200万のプロテイン配列を含むデータセットです。MSAはOpenFoldデータセットから取得されており、16,000,000のUniClust30クラスタと401,381のMSAで140,000の異なるPDB鎖をカバーしています。IDR(intrinsically disordered regions)に関する情報は、Reverse Homology GitHubから取得されました。 研究者は、スキャフォールディング構造モチーフの課題に対してRFDiffusionベースラインを使用しています。examples/scaffolding-pdbsフォルダには、条件付きでシーケンスを生成するために使用できるpdbファイルとfastaファイルがあります。examples/scaffolding-msasフォルダには、特定の条件に基づいてMSAを作成するために使用できるpdbファイルも含まれています。 現在のモデル 研究者は、離散データモダリティ上の拡散のための最も効率的な前方技術を決定するために、両方を調査しました。オーダーに関係なく自己回帰分布(OADM)の各ステップで1つのアミノ酸は一意のマスクトークンに変換されます。全体のシーケンスは、一定のステージ後に非表示になります。離散ノイズ除去拡散確率モデル(D3PM)も、特にプロテイン配列向けにグループによって開発されました。EvoDiff-D3PMの前方フェーズでは、行は遷移行列に従って突然変異をサンプリングすることで破損させられます。これは数ステップ後に均一なアミノ酸のサンプルと区別できなくなるまで続きます。いずれの場合も、回復フェーズではダメージを元に戻すためにニューラルネットワークモデルの再学習が行われます。EvoDiff-OADMおよびEvoDiff-D3PMでは、訓練されたモデルはマスクトークンのシーケンスまたは均一にサンプリングされたアミノ酸のシーケンスから新しいシーケンスを生成することができます。CARPプロテインマスク言語モデルで最初に見られた拡張された畳み込みニューラルネットワークアーキテクチャを使用して、彼らはUniRef50からの4200万シーケンスですべてのEvoDiffシーケンスモデルを訓練しました。各前方破損スキームとLRARデコーディングについて、38Mと640Mの訓練パラメータを持つバージョンを開発しました。 主な特徴 進化的なスケールのデータを拡散モデルに組み込むことで、管理可能なプロテイン配列を生成することができます。 EvoDiffは、構造的に妥当な多様なプロテインを生成し、可能なシーケンスと機能の全範囲をカバーします。 構造ベースのモデルではアクセスできない無秩序なセクションやその他の特徴を持つプロテインを生成するだけでなく、EvoDiffは機能的な構造モチーフのためのスキャフォールドも作成することができます。これにより、シーケンスベースの定式化の一般的な適用性が証明されます。 結論として、Microsoftの科学者たちは、シーケンスベースのプロテインエンジニアリングとデザインを行う際に基礎となる一連の離散拡散モデルをリリースしました。EvoDiffモデルは、構造や機能に基づいたガイド付きデザインのために拡張することが可能であり、無条件、進化によるガイド、および条件付きでプロテイン配列を作成するために直ちに使用することができます。彼らは、プロテインの言語で直接読み書きすることによって、EvoDiffがプログラマブルなプロテイン生成の新たな可能性を開くことを期待しています。

「Amazon Comprehendのカスタム分類を使用して分類パイプラインを構築する(パートI)」
このマルチシリーズのブログ投稿の最初のパートでは、スケーラブルなトレーニングパイプラインの作成方法と、Comprehendカスタム分類モデルのためのトレーニングデータの準備方法について学びます数回のクリックでAWSアカウントにデプロイできるカスタム分類トレーニングパイプラインを紹介します
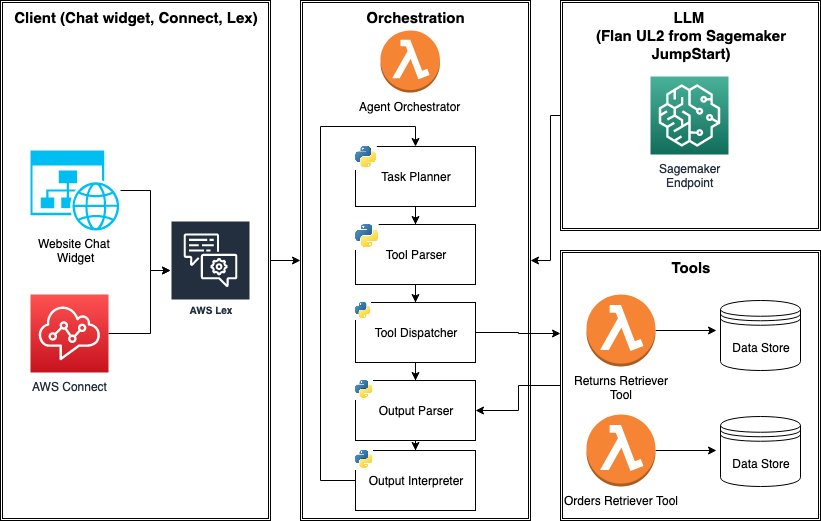
AWS SageMaker JumpStart Foundation Modelsを使用して、ツールを使用するLLMエージェントを構築し、展開する方法を学びましょう
大規模な言語モデル(LLM)エージェントは、1)外部ツール(API、関数、Webフック、プラグインなど)へのアクセスと、2)自己指導型のタスクの計画と実行の能力を持つ、スタンドアロンのLLMの機能を拡張するプログラムですしばしば、LLMは複雑なタスクを達成するために他のソフトウェア、データベース、またはAPIと対話する必要があります[...]

「PythonでChatGPTを使用する方法」
ChatGPTをPythonで強化する方法が知りたいですか?Pythonを使用してKommunicateプラットフォームのアカウントをステップバイステップで設定する方法を学びましょう

コンテンツクリエーターに必要不可欠なChatGPTプラグイン
「CodeGenius、StoryWeaver、およびFactFinderなどの必須のChatGPTプラグインを見つけて、コンテンツ作成プロセスを向上させましょうコンテンツを向上させ、オーディエンスを魅了し、デジタルの世界で先を行くことができます」

「仮説検定とA/Bテスト」
「データに基づく意思決定の柱」

「LangchainとDeep Lakeでドキュメントを検索してください!」
イントロダクション langchainやdeep lakeのような大規模言語モデルは、ドキュメントQ&Aや情報検索の分野で大きな進歩を遂げています。これらのモデルは世界について多くの知識を持っていますが、時には自分が何を知らないかを知ることに苦労することがあります。それにより、知識の欠落を埋めるためにでたらめな情報を作り出すことがありますが、これは良いことではありません。 しかし、Retrieval Augmented Generation(RAG)という新しい手法が有望です。RAGを使用して、プライベートな知識ベースと組み合わせてLLMにクエリを投げることで、これらのモデルをより良くすることができます。これにより、彼らはデータソースから追加の情報を得ることができ、イノベーションを促進し、十分な情報がない場合の誤りを減らすことができます。 RAGは、プロンプトを独自のデータで強化することによって機能し、大規模言語モデルの知識を高め、同時に幻覚の発生を減らします。 学習目標 1. RAGのアプローチとその利点の理解 2. ドキュメントQ&Aの課題の認識 3. シンプルな生成とRetrieval Augmented Generationの違い 4. Doc-QnAのような業界のユースケースでのRAGの実践 この学習記事の最後までに、Retrieval Augmented Generation(RAG)とそのドキュメントの質問応答と情報検索におけるLLMのパフォーマンス向上への応用について、しっかりと理解を持つことができるでしょう。 この記事はデータサイエンスブログマラソンの一環として公開されました。 はじめに ドキュメントの質問応答に関して、理想的な解決策は、モデルに質問があった時に必要な情報をすぐに与えることです。しかし、どの情報が関連しているかを決定することは難しい場合があり、大規模言語モデルがどのような動作をするかに依存します。これがRAGの概念が重要になる理由です。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.