Learn more about Search Results 14 - Page 144

- You may be interested
- 「MITの学者たちは、生成型AIの社会的な影...
- データストレージの最適化:SQLにおけるデ...
- 「2023年および2024年に注目すべきトップ7...
- 「生成AIプロジェクトライフサイクル」
- 「The Research Agent 大規模なテキストコ...
- 「スマートフォンのアタッチメントが神経...
- マイクロソフトの研究者が「LoRAShear LLM...
- アップリフトモデリング—クレジットカード...
- AIはリアルなターミネーターになることが...
- 「ニューラルネットワークの多様性の力を...
- なぜすべての企業がAI画像生成器を使用す...
- 「(ベクター)インデックスの隠れた世界」
- 統計分析入門ガイド | 5つのステップと例
- フルスタック7ステップMLOpsフレームワーク
- 「Chroma DBガイド | 生成AI LLMのための...
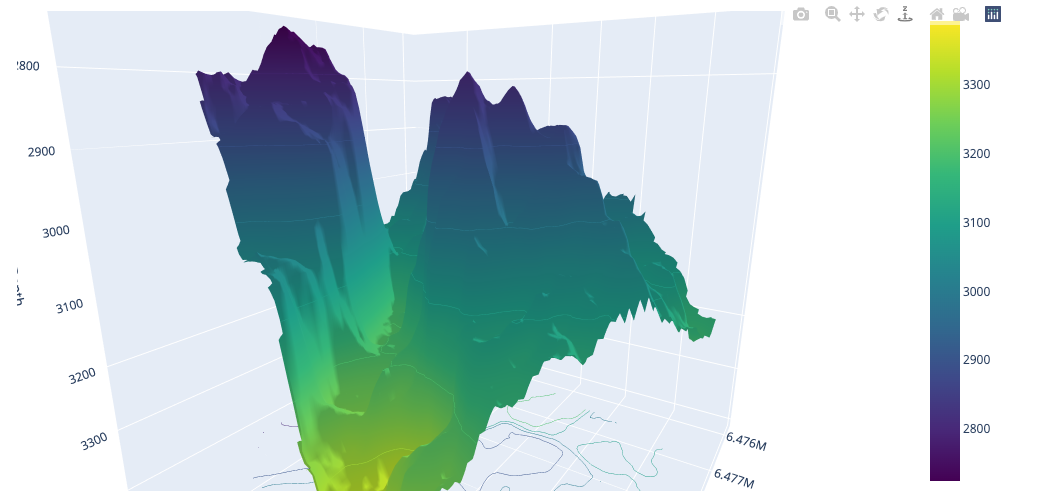
Plotlyの3Dサーフェスプロットを使用して、地質表面を視覚化する
地球科学の分野においては、地下に存在する地質層の完全な理解が不可欠です層の正確な位置と形状を知ることで、...

2023年5月のVoAGIトップ記事:Mojo Lang:新しいプログラミング言語
Mojo Lang(モジョ言語):新しいプログラミング言語 • Pandas AI(パンダスAI):生成的AI Pythonライブラリー • ChatGPTの機械学習チートシート • ChatGPTでやってはいけないことをやめて、そのユーザーの99%よりも先を行こう • データサイエンスのためのBardチートシート • 無料ChatGPTコース:OpenAIを利用する…

H1Bビザはデータ分析の洞察に基づいて承認されますか?
はじめに H1Bビザプログラムは、優れた人材が世界中からアメリカに専門知識をもたらすための門戸を開きます。毎年、このプログラムを通じて数千人の才能ある専門家がアメリカに入国し、様々な産業に貢献し、革新を推進しています。外国労働認証局(OFLC)のH1Bビザデータの世界にダイブして、その数字の裏にあるストーリーを探ってみましょう。この記事では、H1Bビザデータの分析を行い、データから知見や興味深いストーリーを得ます。フィーチャーエンジニアリングを通じて、外部ソースから追加情報をデータセットに組み込みます。データラングリングを用いて、データを丁寧に整理して、より理解しやすく分析することができます。最後に、データの可視化によって、2014年から2016年の間におけるアメリカの熟練労働者に関する魅力的なトレンドや未知の知見が明らかになります。 外国労働認証局(OFLC)から提供されたH1Bビザデータを探索し、高度な外国人労働者をアメリカに引き付ける上での重要性を理解する。 データクリーニング、フィーチャーエンジニアリング、データ変換技術などの前処理プロセスについて学ぶ。 H1Bビザの申請の受理率や拒否率を調べ、それらが影響を与える可能性がある。 データの可視化技術に慣れて、効果的な発表やコミュニケーションを行うために。 注:🔗この分析の完全なコードとデータセットは、Kaggle上で公開されています。プロセスや分析の背後にあるコードを探索するには以下のリンクをご覧ください。H1B Analysis on Kaggle この記事は、Data Science Blogathonの一環として公開されました。 H1Bビザとは何ですか? H1Bビザプログラムは、様々な産業において専門的なポジションを埋めるために、優秀な外国人労働者をアメリカに引き付けるためのアメリカの移民政策の重要な要素です。スキル不足を解消し、革新を促進し、経済成長を牽引しています。 H1Bビザを取得するには、以下の重要なステップを踏まなければなりません。 ビザをスポンサーするアメリカの雇用主を見つける。 雇用主が外国人労働者のH1B申請を米国移民局(USCIS)に提出する。 年次枠に制限があり、申請数が受け入れ可能な枠を超えた場合は、抽選が行われる。 選択された場合、USCISは申請の資格とコンプライアンスを審査する。 承認された場合、外国人労働者はH1Bビザを取得し、米国のスポンサー雇用主で働くことができる。 このプロセスには、学士号または同等の資格を持つことなどの特定の要件を満たす必要があり、支配的な賃金決定や雇用主-従業員関係の文書化などの追加の考慮事項を乗り越える必要があります。コンプライアンスと徹底的な準備が、成功したH1Bビザ申請には不可欠です。 データセット 外国労働認証局(OFLC)が提供する2014年、2015年、2016年の結合データセットには、ケース番号、ケースステータス、雇用主名、雇用主都市、雇用主州、職名、SOCコード、SOC名、賃金レート、賃金単位、支配的な賃金、支配的な賃金源、年などのカラムが含まれます。…

ChatGPTのデジタル商品をオンラインで販売するプロンプト
ChatGPTは、オンラインでデジタル製品を販売して収益を上げたい人にとって、ありがたい存在です
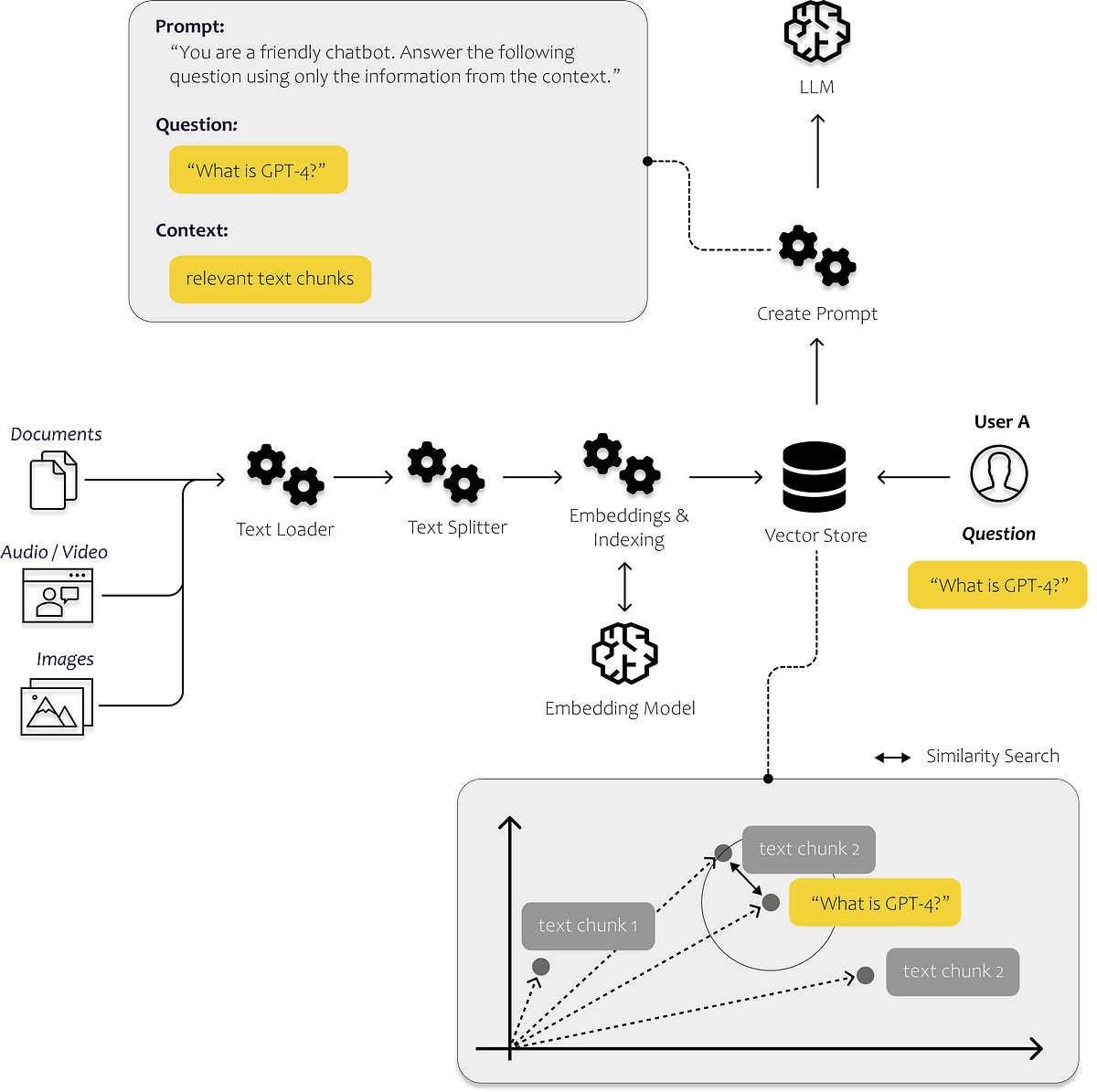
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

DeepMindの研究者たちは、任意のポイントを追跡するための新しいAIモデルであるTAPIRをオープンソース化しましたこのモデルは、ビデオシーケンス内のクエリポイントを効果的に追跡します
コンピュータビジョンは、人工知能の最も人気のある分野の1つです。コンピュータビジョンを使用したモデルは、デジタル画像、動画、またはその他の視覚的入力など、さまざまな種類のメディアから有意義な情報を導き出すことができます。それは、機械が視覚情報を知覚・理解し、その詳細に基づいて行動する方法を教えるものです。新しいモデルであるTracking Any Point with per-frame Initialization and Temporal Refinement(TAPIR)の導入により、コンピュータビジョンは大きく前進しました。TAPIRは、ビデオシーケンスで特定の関心点を効果的に追跡することを目的として設計されました。 TAPIRモデルの背後にあるアルゴリズムは、Google DeepMind、VGG、エンジニアリングサイエンス学科、そしてオックスフォード大学の研究者チームによって開発されました。TAPIRモデルのアルゴリズムは、2つのステージ、すなわちマッチングステージとリファインメントステージから構成されています。マッチングステージでは、TAPIRモデルは各ビデオシーケンスフレームを個別に分析し、クエリポイントに適した候補点マッチを見つけます。このステップは、各フレームでクエリポイントの最も関連性が高い点を特定することを目的としており、TAPIRモデルがビデオ全体でクエリポイントの移動を追跡できるようにするため、フレームごとにこの手順を実行します。 候補点マッチが特定されるマッチングステージには、リファインメントステージの使用が続きます。このステージでは、TAPIRモデルは、局所的相関に基づいて軌跡(クエリポイントがたどるパス)とクエリ特徴を更新し、各フレームの周囲の情報を考慮してクエリポイントの追跡の精度と正確性を向上させます。リファインメントステージにより、局所的相関を統合することで、モデルのクエリポイントの動きを正確に追跡し、ビデオシーケンスの変動に対応する能力が向上します。 TAPIRモデルの評価には、ビデオトラッキングタスクの標準化された評価データセットであるTAP-Vidベンチマークが使用されました。その結果、TAPIRモデルは、ベースライン技術よりも明らかに優れた性能を発揮しました。性能改善は、平均ジャッカード(AJ)という指標を用いて測定され、DAVIS(Densely Annotated VIdeo Segmentation)ベンチマークにおいて、TAPIRモデルは他の手法に比べてAJで約20%の絶対的な改善を達成したことが示されました。 モデルは、長いビデオシーケンスでの高速な並列推論を容易にするように設計されており、複数のフレームを同時に処理できるため、トラッキングタスクの効率を向上させます。チームは、モデルをライブで適用できるように設計し、新しいビデオフレームが追加されるたびにポイントを処理・追跡できるようにしています。256×256ビデオで256ポイントを約40フレーム/秒の速度で追跡でき、解像度の高い映画を処理できるように拡張することもできます。 チームは、ユーザーがインストールせずにTAPIRを試すことができる2つのオンラインGoogle Colabデモを提供しています。最初のColabデモでは、ユーザーが自分のビデオでモデルを実行し、モデルのパフォーマンスをテストして観察するインタラクティブな体験を提供します。2番目のデモでは、オンラインでTAPIRを実行することに焦点を当てています。また、提供されたコードベースをクローンし、モダンなGPUで自分自身のWebカメラのポイントを追跡することによって、ユーザーはTAPIRをライブで実行することができます。

機械学習によるストレス検出の洞察を開示
イントロダクション ストレスとは、身体や心が要求や挑戦的な状況に対して自然に反応することです。外部の圧力や内部の思考や感情に対する身体の反応です。仕事に関するプレッシャーや財政的な困難、人間関係の問題、健康上の問題、または重要な人生の出来事など、様々な要因によってストレスが引き起こされることがあります。データサイエンスと機械学習によるストレス検知インサイトは、個人や集団のストレスレベルを予測することを目的としています。生理学的な測定、行動データ、環境要因などの様々なデータソースを分析することで、予測モデルはストレスに関連するパターンやリスク要因を特定することができます。 この予防的アプローチにより、タイムリーな介入と適切なサポートが可能になります。ストレス予測は、健康管理において早期発見と個別化介入、職場環境の最適化に役立ちます。また、公衆衛生プログラムや政策決定にも貢献します。ストレスを予測する能力により、これらのモデルは個人やコミュニティの健康増進と回復力の向上に貢献する貴重な情報を提供します。 この記事は、データサイエンスブログマラソンの一部として公開されました。 機械学習を用いたストレス検知の概要 機械学習を用いたストレス検知は、データの収集、クリーニング、前処理を含みます。特徴量エンジニアリング技術を適用して、ストレスに関連するパターンを捉えることができる意味のある情報を抽出したり、新しい特徴を作成したりすることができます。これには、統計的な測定、周波数領域解析、または時間系列解析などが含まれ、ストレスの生理学的または行動的指標を捉えることができます。関連する特徴量を抽出またはエンジニアリングすることで、パフォーマンスを向上させることができます。 研究者は、ロジスティック回帰、SVM、決定木、ランダムフォレスト、またはニューラルネットワークなどの機械学習モデルを、ストレスレベルを分類するためのラベル付きデータを使用してトレーニングします。彼らは、正解率、適合率、再現率、F1スコアなどの指標を使用してモデルのパフォーマンスを評価します。トレーニングされたモデルを実世界のアプリケーションに統合することで、リアルタイムのストレス監視が可能になります。継続的なモニタリング、更新、およびユーザーフィードバックは、精度向上に重要です。 ストレスに関連する個人情報の扱いには、倫理的な問題やプライバシーの懸念を考慮することが重要です。個人のプライバシーや権利を保護するために、適切なインフォームドコンセント、データの匿名化、セキュアなデータストレージ手順に従う必要があります。倫理的な考慮事項、プライバシー、およびデータセキュリティは、全体のプロセスにおいて重要です。機械学習に基づくストレス検知は、早期介入、個別化ストレス管理、および健康増進に役立ちます。 データの説明 「ストレス」データセットには、ストレスレベルに関する情報が含まれています。データセットの特定の構造や列を持たない場合でも、パーセンタイルのためのデータ説明の一般的な概要を提供できます。 データセットには、年齢、血圧、心拍数、またはスケールで測定されたストレスレベルなど、数量的な測定を表す数値変数が含まれる場合があります。また、性別、職業カテゴリ、または異なるカテゴリ(低、VoAGI、高)に分類されたストレスレベルなど、定性的な特徴を表すカテゴリカル変数も含まれる場合があります。 # Array import numpy as np # Dataframe import pandas as pd #Visualization…

あなた全体に装着可能なロボットアシスタント
メリーランド大学の研究者が開発したCalico補助ロボットは、ユーザーの衣服に装着でき、トラックに沿って走りながら様々なタスクを実行することができます
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…
PythonからJuliaへ:基本的なデータ操作とEDA
統計計算の領域でエマージングなプログラミング言語として、Julia は近年ますます注目を集めています他の言語に優る2つの特徴があります...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.